
Autonomous-Agents
Autonomous Agents (LLMs) research papers. Updated Daily.
Stars: 447

README:


![]()
Autonomous Agents-research papers. Updated daily. See as well the Resources-section.
Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
- Introduces LLM-based multi-agent system for efficient LLM pretraining data selection. LLM converges faster in the pretraining and the method improves LLM output quality.
- The Data console integrates data inisghts dynamically from the different agents during the training process.
- Agent console include quality/domain/topic-agents. Includes as well memory.
Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System
- Optima (OPTImising effectiveness and efficiency for LLM-based Multi-Agent systems): Introduces framework to train LLM-based multi-agent system (MAS).
- Includes 4 iterative steps: Generate/Rank/Select/Train.
- Investigates scaling laws of inference compute.
- Optima helps to make LLMs highly efficient conversationalists.
DelTA: An Online Document-Level Translation Agent Based on Multi-Level Memory
- DelTA (Document-level Translation Agent): Introduces translation LLM-agent using multi-layer memory components to improve translation consistency/quality.
- Memory components include: Proper noun memory(to apply correct terminology)/Bilingual summary/long-term/short-term-memory units.
Mars: Situated Inductive Reasoning in an Open-World Environment
- Mars: Introduces framework for Situated Inductive Reasoning-benchmark and a framework with LLM-agents called: IfR (Induction from Reflection).
- The paper identifies two critical components for inductive reasoning: situatedness (situational context) and abstractiveness (abstract conclusions).
- IfR-framework includes task proposer/planner/controller/reflection-steps, rule library (when this, do that) and skill library. The LLM-based reflection-step induces new rules, which actual LLMs struggle currentyly.
Benchmarking Agentic Workflow Generation
- Introduces WorFEBench-benchmark for unified workflow generation and WorFEval evaluation protocol of workflows for LLM-agents.
AgentBank: Towards Generalized LLM Agents via Fine-Tuning on 50000+ Interaction Trajectories
- Samoyed: Introduces LLM-models fine-tuned with AgentBank-dataset for general agent tasks.
- AgentBank-dataset includes dimensions: reasoning/math/programming/web/embodied AI.
Smart Audit System Empowered by LLM
- Introduces Smart Audit System with LLMs, which include dynamic risk assessment model/manufacturing compliance copilot/Commonality analysis agent. Developed by Apple researchers.
- Dynamic risk assessment model adjusts audit: focus/sample size/critical items/resource allocation.
- Manufacturing compliance copilot self-adjusts its the knowledge base with new information.
- Commonality analysis agent manages an autonomous agent conducting real-time analysis to custom requests, in order to drive supplier improvements. Includes planning/memory/tools/selecting and usage of tools/generating responses.
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
- Introduces Embodied Agent Interface-benchmark for embodied decision making LLM-agents.
- Reviews four critical capabilities: Goal interpretation, Subgoal decomposition, Action sequencing and Transition modelling.
- zAImbardo-framework: Introduces LLM-agent simulation between prisoner/guard-agents using prompts, which are either shared or private.
- Shared prompts: communication rules/environment description/research oversight/risks. Private prompts: Starting prompt/personality/goals.
Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology
- Introduces UAV navigation agent using MLLM. Includes three levels of assistants: constant/difficult situations/hazard situations.
MOOSE-Chem: Large Language Models for Rediscovering Unseen Chemistry Scientific Hypotheses
- Moose-Chem: multi-agent framework to discover novel chemistry research hypothesises from given information.
Seeker: Enhancing Exception Handling in Code with LLM-based Multi-Agent Approach
- Seeker: introduces LLM-based multi-agent framework for exception handling with planner/detector/predator/ranker/handler-agents.
ST-WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents
- ST-WebAgentBench-benchmark: Evaluates safety and trustworthy of web agents against performing undesired operations in business/user applications.
- CAIMIRA (Content-Aware, Identifiable, Multidimensional, Item Response Analysis)-framework: Reviews differences between humans and SOTA-level LLMs in QA-tasks in reasoning and textual understanding.
LLMs Are In-Context Reinforcement Learners
- In-Context Reinforcement Learning (ICRL): Introduces ICRL-algorithm (increases test-time compute), which effectively learns reward from a classification task. The explorative-version concentrates on positive episodes and stochasticity.
- Naive ICRL explores poorly.
Scalable and Accurate Graph Reasoning with LLM-based Multi-Agents
- GraphAgent-Reasoner (GAR): explicit and precise graph-reasoning with multi-agent collaboration.
- Works to solve real-world graph-reasoning such as webpage ranking,
- Distributes tasks into nodes (over 1000) to multiple agents collaborating between each other.
- Includes stages: Algorithmic establishment (retrieve/initialisation/adjust/design), Distributed execution (Master LLM assigns task, agent network communicates) and Master summarisation (termination/aggregation/conclusion).
- Master LLM defines for each problem 6 components: State/Message/Initialization/Send/Update/Termination.
Grounding Partially-Defined Events in Multimodal Data
- Reviews event extraction from unstructured video data using multimodal event analysis with LLMs.
GLEE: A Unified Framework and Benchmark for Language-based Economic Environments
- Introduces GLEE (Games in Language-based Economic Environments)-benchmark, which reviews LLMs in two-player economic game families of bargaining, negotiation andd persuasion.
AssistantX: An LLM-Powered Proactive Assistant in Collaborative Human-Populated Environment
- AssistantX: multi LLM-agent framework (PPDR4X) to help users achieve goals in virtual / physical environments.
- PPDR4X-framework includes short term memory (initial instructions/dialogue data/agent thoughts/cyber tasks/real world tasks), long-term memory (environment information), perception-agent, planning-agent, reflection agent and decision agent.
Control Industrial Automation System with Large Language Models
- Introduces multi LLM-agent industrial control system, which consists of summarizer-, manager- (planning level), event log manager-, operator-agents (control-level) and command line/event log memory/prompt templates/events/function calls.
Compositional Hardness of Code in Large Language Models -- A Probabilistic Perspective
- Reviews the difficulty of processing multiple sub-tasks within single LLM call with ICL to produce correct solution, which is called "In-Context Hardness of Composition".
- Refers to new term called "Screening", which refers to LLMs capacity to isolate the relevant context. For example LLM with capacity to perform two tasks, may fail performing both within same context.
- Finds, that is better to distribute tasks to multiple LLM-agents, when task becomes complex. Offers a literature review of the CoT problem solving and agents-research intersection.
- AXIS: Priorites task completing API-calls above UI-agent actions, which decrases task completion time and cognitive workload.
- It is more useful to generate efficient API-call agent using programmatic API, than slower human-like UI agent.
- Includes Explorer-, Follower-, Monitor-, Generator-, Evaluator- and Translator-agents.
- Enables converting any application, with basic API/documentation and: environment state interface/basic action interface, into agent. Uses self-exploratory framework to identify control elements.
A Roadmap for Embodied and Social Grounding in LLMs
- Reviews the grounding of LLMs with physical world. Highlights the importance of social grounding of physical experiences. For example a child can build understanding of heavy objects just by observing an adult trying to lift a heavy box.
- Interesting ideas about the way human perception in physical world.
Plurals: A System for Guiding LLMs Via Simulated Social Ensembles
- Introduces Plurals-framework: generates diverse agents (stakeholder) based on demographic data to interact diverse opinions using a structrured debate and moderator.
- The demographic data is basis for generating the agents, which helps to tune the messages to specific audiences.
- Includes Structures, which forces LLM-agents to share information with a properly formed structure.
- Moderator-agent then summarises this discussion by trying to take into account the diverse opinions.
Language Grounded Multi-agent Communication for Ad-hoc Teamwork
- Grounds MARL agent communication with LLM generated synthetic data, which improves communicatio and zero-shot collaboration between agents.
MOSS: Enabling Code-Driven Evolution and Context Management for AI Agents
- MOSS (llM-oriented Operating System Simulation): LLM-based code
ERABAL: Enhancing Role-Playing Agents through Boundary-Aware Learning
- ERABEL: Introduces boubdary-aware role playing framework to maintain role comsistency in multiturn conversation.
- Includes dialogue planner/topic manager/question generator/response generator-agents.
- Includes prompts for esch agent.
RRM: Robust Reward Model Training Mitigates Reward Hacking
- RRM (Robust Reward Model): Reviews reward models ability to differentiate signal from the genuine context and irrelevant information to decide preference. Proposes usage of causal graph.
- Produces more robust reward model.
ChainBuddy: An AI Agent System for Generating LLM Pipelines
- ChainBuddy: Includes requirements gathering agent (primary user goal/list of req./user preferences/suggested Cot strategy), planner agent (includes replanner), task-specific agents, connection agent and post-hoc reviewer agent.
Minstrel: Structural Prompt Generation with Multi-Agents Coordination for Non-AI Experts
- Minstrel: a multi-agent framework for automated prompt optimization. Prompts are constructed using role, profile, constraints, goals, initialization and examples, workflow, skills, suggestions, background, style, output format and command modules.
- Agents are assigned to working groups in charge of similar small tasks.
ShizishanGPT: An Agricultural Large Language Model Integrating Tools and Resources
- ShizishanGPT: LLM agent for answering with agriculture-based RAG.
Training Language Models to Self-Correct via Reinforcement Learning
- SCoRe (Self-Correct via Reinforcement Learning): Increases LLMs capacity to self-correct via multi-turn Reinforcement Learning.
- Achieves positive intrinsic self-correction performance as first model.
AutoVerus: Automated Proof Generation for Rust Code
- AutoVerus: LLM generates correctness proofs for Rust-code using multi-agent framework (proof generation, refinement and debugging).
- LLM-agent UMF (Unified Modelling Framework): Introduces modular LLM-agent framework, which includes core agent coordinating with planning, memory, profile, action and security modules.
- Proposes various multi agent frameworks.
- Proposes active and passive information types.
- Includes lots of useful ideas for each component.
NVLM: Open Frontier-Class Multimodal LLMs
- NVLM: frontier level VLM model and high performance as LLM only.
- Finds, that dataset quality and task diversity impact more than scale.
- Finds positive transfer from image to text only modality.
P-RAG: Progressive Retrieval Augmented Generation For Planning on Embodied Everyday Task
- P-RAG: Introduces iteratively updated RAG (self-iterations). P-RAG adds more task-specific knowledge.
- The RAG stores the following information: goal instruction, scene graph, history and done.
EmPO: Emotion Grounding for Empathetic Response Generation through Preference Optimization
- EmPO: Introduces the EmpatheticDialogues-dataset for fine tuning LLMs with empathic response generation (ERG).
Instigating Cooperation among LLM Agents Using Adaptive Information Modulation
- SLA (Strategic LLM Agent): combines LLM agents (SLAs) and RL-agent called Pro-social Promoting Agent (PPA) to increase cooperation rate.
- Adjusts dynamically access to SLA's information (cooperation history with neighbours, average) to increase facilitate social interaction.
Cognitive Kernel: An Open-source Agent System towards Generalist Autopilots
- Cognitive Kernel: introduces autopilot-like LLM-agent with access to internet with the web browser (appears to use Playwright-library) to interact "human-like" manner (click, scroll, etc).
- The LLM agent interacts with user and task environment. Includes reasoning kernel, memory kernel and perception kernel.
- LLM is fine tuned to interact with the environment through atomic actions, which a normal person could perform, rather than API call.
- Offers interesting ideas for each sub-compoment, as each includes plenty of detailed functionalities.
Central Answer Modeling for an Embodied Multi-LLM System
- CAM (Central Answering Model): Introduces CAM-framework, where instead of LLM-agent directly answering question, multiple LLM-agent instances generate answer and a central LLM-agent responds to the question.
RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation
- RethinkMCTS: conducts thought-level searches before generating code and adds both verbal feedback to refine thoughts and code execution feedback from incorrect code.
- Increasing the number of rethink- and rollout-operations improve code generation.
- PeriGuru: LLM-agent for GUI with perception, decision and action steps.
Enhancing Decision-Making for LLM Agents via Step-Level Q-Value Models
- Introduces task-relevant Q-value model for guiding action selection.
- Includes review of the different methods to improve reasoning, such as LLMs using MCTS.
Agents in Software Engineering: Survey, Landscape, and Vision
- Introduce LLM-agents with perception, memory and actions for SW engineering. Includes multi-agent workflow with feedback, refinement and roles.
- Actions include internal (reasoning, learning and retrieval) and external (digital environment, dialogue with human/agent)).
- Memory includes procedural, semantic and episodic.
- Perception includes textual (UML, execution result, text/code), visual and auditory.
- Includes good overview of different reasoning techniques for the CoT-action.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
- Navi: introduces a multi modal agent for Windows OS.
- Processes screen information called SoM (Set of Marks) with multiple alternative methods : UIA (User Interface Automation) tree, parses DOM tree, uses propietary OCR, icon/image detection and OmniParser-model.
- Agent prompt includes: task instruction, description of action space, history of actions, clipboard content and thought-variable memory. The prompt includes as well previus/current step screenshot with SoMs.
- Introduced WindowsAgentArena-benchmark.
- Includes the agent prompt.
- Agent Workflow Memory (AWM): LLM-agent retrieves and reuses reusable routines, which it extracts and generalises from past examples.
- Consists of LLM, memory and environment state (action-observation).
- Memory consists of: workflow description, workflow steps (environment state description, deduction process and action sequence). The memory-unit is described as text-based "system"-prompt.
- Adds increasingly difficult workflows from previously acquired workflows and new experiences.
- Uses previously learned skills in new settings. Eliminates workflow steps, not required.
Think-on-Process: Dynamic Process Generation for Collaborative Development of Multi-Agent System
- ToP (Think-on-Process): Multi-agent LLM-framework, which generates SW development processes using experiential knowledge.
- Each chat includes role assignment, memory stream and self-reflection.
- ToP-framework includes: instance generating, llm enhancing, instance filtering and software developing.
- Refers to concept of "Chat-chain", where multiple LLM-agents (CEO, CTO, CPO, Tester, Coder and Designer) operate.
- Converts processes to process textual descriptions: process-to-text and finally to process textual description.
SciAgents: Automating scientific discovery through multi-agent intelligent graph reasoning
- SciAgents: Multi-agent graph-reasoning LLM-framework with retrieval for scientific discovery.
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance
- Self-Reflection-Agents: Finds, that self-reflection improves performance of LLM agents in 6 different LLM tested.
- Self-Reflections, which contain more information (instructions, explanations, and solutions) perform better, than self-reflections with less data.
- Retry-agent improves significantly performance, which indicates knowledge of a mistake, improves performance of the LLM.
Game On: Towards Language Models as RL Experimenters
- Introduces RL experiment workflow using VLM (not fine-tuned) to perform tasks assigned typically to human experimenter.
- The system monitors/analyses experiment progress, suggests new tasks, decomposes tasks and retrieves skills to execute. Does not automate
- Enables embodied autonomous agent to acquire zero-shot new skills.
From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
- MAIC (Massively AI-empowered Course): Introduces multi LLM-agent system for scalable (like Massive Open Online Courses), but still adaptive (to personal needs / aptitudes) online education. Includes few comments from students, which highlight the limitss of its current approach.
- Includes LLM-agents acting both teachers, students, assistant, manager analyser and other agents. Teacher agents adjust style based on communication with the student. Human-student can select style of AI-classmates with the student.
- Classroom environment incldues current slide, dialogue history, class roles / course management. Course preparation includes read / plan stage, where slide content extraction, structure extraction, function generation and agent generation takes place.
xLAM: A Family of Large Action Models to Empower AI Agent Systems
- xLAM: Series (from 1B dense to 8x22B MoE) of Large Action Models (LAMs) for AI agent tasks. Achieves high performance in function calling.
- Fine-tunes basically from a LLM (DeekSeeker/Mistral models) a LAM, which is able to perform highly accurate function calling.
- Cog-GA (Cognitive-Generative Agent)-agent: Introduces Visual-Language Navigation (VLN)-agent in continuous environments with cognitive maps (spatial, temporal and semantic information) and reflection.
- Includes instruction processor, high-level planner, waypoint predictor, memory stream (reflection memory/cognitive map), reflection generator and low-level actuator. Instructions are provided as text, panorama input image. Target waypoints are stored in the cognitive maps-memory.
- Cognitive maps include spatial memories about scene descriptions and landmarks in time step.
- Limits search space by employing dual-channel waypoint using information about the landmark objects (what) and spatial characteristics (where).
Configurable Foundation Models: Building LLMs from a Modular Perspective
- Reviews modularity of LLMs. The idea is to instead of re-training from scratch a LLM, to add new knowledge as modules (called emergent bricks pretrained and customised bricks postrained).
- Identifies the following brick-operations: retrieval / routing, merging, updating and growing.
Large Language Model-Based Agents for Software Engineering: A Survey
- Survey about SW engineering LLM-agents.
MoA is All You Need: Building LLM Research Team using Mixture of Agents
- MoA (Mixture-of-Agents)-framework (name was already used before) is a framework with planner, aggregator and varios LLM-agentseach with their own RAG, grouped together.
Empirical evidence of Large Language Model's influence on human spoken communication
- Empirical evidence, that humans imitate LLMs.
- Finds, that LLMs reduce linguistic diversity, but it appears an interesting topic to discover, if LLMs only decrease diversity or impact other ways / the ways content creation automation impacts overall to society.
- AgentRe: Relation Extraction (RE) agent includes three components: retrieval (static knowledge to help store/retrieve information), memory(dynamic knowledge: shallow memory for extraction results, deep memory for historical action summaries/reflections) and extraction modules (ReAct-based, pulls information based on retrieval and memory).
- Avoids extracting for incomplete entities, such as phrases referring in general to Museums without being precise on the exact name of the museum.
Focus Agent: LLM-Powered Virtual Focus Group
- Focus Agent: Simulates moderation of focus groups with human participants and alignment of focus agent opinions with this group.
- Simulates planning, moderation, questions, discussion and reflection with LLM-agents.
The Compressor-Retriever Architecture for Language Model OS
- Compressor-Retriever-architectore: Introduces concept of stateful LLM OS by using only base model forward function to compress and retrieve context.
- Reviews concept of LLM acting as a CPU and its context window acting as RAM.
- Identifies life-long context as infite, which is core issue with actual session-based interactions.
- Compressor builds hierarchical db to save previously chunked context. The retriever searches relevant context.
Self-evolving Agents with reflective and memory-augmented abilities
- SAGE: Introduces self-evolving LLM-agent consisting of user/assistant/checker-agents with iterative feedback, reflection and memory optimization (Ebbinghaus-forgetting curve).
- Self-evolution includes adaptive adjust strategies, optimizing information storage and transmission and reduction of cognitive context.
- Mimics human brain / memory by creating MemorySyntax, which combines Ebbinghaus forgetting curve and linguistic knowledge.
LanguaShrink: Reducing Token Overhead with Psycholinguistics
- LannguageShrink: Reduces prompt length (tokens to process) by optimising the prompt by applying psycholinguistic principles and the Ebbinghaus memory curve.
- For example removes words like "usually" from the prompt, which add complexity, ambiguity, irrelevance etc.
Tool-Assisted Agent on SQL Inspection and Refinement in Real-World Scenarios
- Tool-SQL: LLM-agent for SQL code inspection and fixing using retrieval and refinement.
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
- Suggests, that LLMs fine-tuned with synthetic data from weaker, yet cheaper LLM is more compute optimal, than using stronger, yet more expensive LLM.
- Samples data from Gemini Pro 1.5 (more expensive, stronger) compared to Gemini Flash 1.5. by using pricing per token as a proxy.
CogVLM2: Visual Language Models for Image and Video Understanding
- Introduces CogVLM2-family of models: CogVLM2, CogVLM2-Video and GLM-4V.
- Relates to CogAgent-GUI agent introduced in December 2023.
A Survey on Evaluation of Multimodal Large Language Models
- The Survey reviews Multi Modal Language Models (MLLMs).
- WebPilot: Introduces Multi-Agent System with Planner(generate and refine plan)/Controller(judge sub-task terminatation, asses sub-task completion, generate strategic reflection)/Extractor(extract information)/Explorer(generate action, analyse observation, generate tactical reflection)/Apprasier(asses state)/Verifier(format action, deduplicate action) LLM-agents.
- Uses Global Optimization (decomposing tasks/refining high-level plans with reflective analysis) and Local Optimization (executes sub-tasks with customized MCTS/refining decisions iteratively through with each observation).
- Tasks include navigating forums/upvoting posts/extracting contributor emails.
AutoGen Studio: A No-Code Developer Tool for Building and Debugging Multi-Agent Systems
- AutoGen Studio: Build on top of AutoGen, the AutoGen Studio includes drag & drop web-UI to customize/attach model/skills/tools/memory/agents involved.
- The workflow is saved as declarative json-structure. Users can export this json and share it to other users. Apart includes built-in DB Manager, Workflow Manager and Profiler-classes.
- Backend includes Python API, web API and CLI.
- Investigates using LLM-agents for Psychological Counseling dialogue (counselor/client) based on client profiles (mental health issue description/detailed description of the disorder/symptom/problem/chief complaint) and counselor simulation is based on exploration, insight, and action.
- Introduces BattleAgentBench-benchmark, which reviews rule understanding, spatial perception, competition, static cooperation and dynamic cooperation.
- Atari-GPT: Applies Multi Modal Language Model as low-level policy (controller).
- FlowAct: Introduces human-robot interaction system, which continuously perceives and acts. Uses two controllers: Environment State Tracking (EST) and Action Planner.
- RAIT (Retrieval Augmented Instruction Fine-tuning): Introduces RAIT fine-tuning approach in chemical / process engineering, which combines small language models (SMLs) with Retrieval Augmented Code Generation (RACG).
Towards Fully Autonomous Research Powered by LLMs: Case Study on Simulations
- Reviews feasibility of Autonomous Simulation Agent (ASA) to automate E2E research process using LLMs and API automation (AutoProg).
LogicGame: Benchmarking Rule-Based Reasoning Abilities of Large Language Models
- LogicGame: Benchmarks rule-based reasoning, execution and planning of LLMs.
Persuasion Games using Large Language Models
- Introduces persuasion framework with LLM-agents, but the paper is not clearly indicating conclusions about persuasion with LLMs with doubts as well on exact roles/prompts.
EPO: Hierarchical LLM Agents with Environment Preference Optimization
- EPO (Environment Preference Optimization): Generates preference signals from environmental feedback for long-horizon decision making with LLM-agents.
- LLM predicts sub-goals and respective low-level actions.
- Interaction module generates two types of sub-goals: navigation and interaction.
Generative Verifiers: Reward Modeling as Next-Token Prediction
- GenRM-verifier (Generative Reward Models): proposes training verifiers with next-token prediction objective.
- Combines verification and solution generation, whichh improves verification-process.
- GenRM outperforms classifier-based discriminatary (assigns numerical score to answer, which is used to classify as correct/incorrect answer) verifiers and LLM-as-a-judge (tends to underperform trained LLM-based verifiers).
- Integrates with fine-tuning, CoT and is able to use inference-time compute in form of majority vote to improve verification.
- Enables inference-time compute for CoT Verifiers (GenRM-CoT). Uses reference-guided grading to assist "Let's verify step by step"-verification on test-time problems lacking reference solution.
- See slides here.
AgentMonitor: A Plug-and-Play Framework for Predictive and Secure Multi-Agent Systems
- AgentMonitor: Captures multi agent (MAS) inputs and outputs to predict task performance and correcting security risks in real-time.
- Includes 5 different MAS configurations.
- Introduces Hierarchical Prompt Tuning (HPT) and HPT++. Adapts VLM by creating a graph from each description with hierachical relationship guided attention module.
- TourSnmbio-Agent: Performs protein engineering tasks using TourSynbio-7B model (fine-tuned on text and protein sequences).
- Includes intent classification steps, where is defined in case the user intent is generic question or agent-specific task.
- Keywords are used in agent selection.
Foundation Models for Music: A Survey
- Reviews research available on Foundational models for Music: representations of music, applications, foundational model techniques, datasets/evals and ethics.
AgentMove: Predicting Human Mobility Anywhere Using Large Language Model based Agentic Framework
- AgentMove: Mobility prediction LLM agent.
- Includes spatial-temporal memory.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
- Benchmark to evaluate LLM-agent based coding for Java programming language (SWE-bench for Java).
LIMP: Large Language Model Enhanced Intent-aware Mobility Prediction
- LIMP (LLMs for Intent-aware Mobility Prediction): Fine-tunes LLama 3-8B-Instruct model with Analyze-Abstract-Infer (A2I)-agentic workflow for mobility intent reasoning.
Intelligent OPC Engineer Assistant for Semiconductor Manufacturing
- RL / multimodal LLM-agents solve Optical Proximity Correction (OPC)-problems in semiconductor manufacturing using RL-based recipe search, which typically require years of OPC engineering experience.
MEDCO: Medical Education Copilots Based on A Multi-Agent Framework
- MEDCO (Medical EDucation COpilots): Includes patient, student, expert doctor and radiologist multimodal (X-rays/CT scans/MRIs/ultrasounds) LLM-agents. Student agents are trained/taught with feedback provided and then stored in student memory module to improve future diagnosis.
Graph Retrieval Augmented Trustworthiness Reasoning
- GRATR (Graph Retrieval Augmented Reasoning): Improves trustworthiness reasoning of the LLM agent using Evidence base.
- Evidence base is updated based on observation analysis and observation assessment.
- Neuro-symbolic multi agent framework, which includes doctor, patient and tool LLM-agent interaction and dynamic (patient specific information) diagnosis tree. Introduces mental disorders diagnosis dataset MDD-5k.
- Doctor agent includes persona, diagnosis result, dialogue generation. Patient agent includes patient information, patient experience and knowledge graph.
- Establishes deeper engagement with patient to help generate diagnosis by generating the dynamic diagnosis tree.
Balancing Act: Prioritization Strategies for LLM-Designed Restless Bandit Rewards
- Introduces customizable Social Choice Language Model: Uses an external adjudicator to manage tradeoffs via a user-selected social welfare function. Uses LLM to design reward functions in Restless Multi-Armed Bandits-allocation problems.
- Suggests, that prompt engineering alone
--
SocialQuotes: Learning Contextual Roles of Social Media Quotes on the Web
- Introduces SocialQuotes-dataset to classify social media / web context into roles (influencer, expert, marketer, commenter, etc.)
Can LLMs Understand Social Norms in Autonomous Driving Games?
- LLM-agent autonomously drives in multi-agent driving game with social norms. Agents make self-driven decisions without attempting to cooperate.
Story3D-Agent: Exploring 3D Storytelling Visualization with Large Language Models
- Story3D-Agent: LLM-agent used in 3D storytelling visualization with consistent contextually and narrative.
- Improves chemistry information retrieval/catalyst and materials design usage of Chemical Foundational model (such as MolFormer-XL) by combining it with RAG.
LLM4VV: Exploring LLM-as-a-Judge for Validation and Verification Testsuites
- Agent-based prompting and validation pipeline increase quality of the LLM as a Judge for compiler tests.
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
- DreamFactory: video generation-framework, which generates long/complex and stylistically coherent videos using multi-agent video production agent team.
- Includes requirement analysis/planning/framework preparation/script generation/scenes design/shots design/key-frames generation and video generation.
- Lacks still creativity (artistic/devising plots) due to reliance on prompts, seems as individual videos stitched together based on synthetic audio clip and need for significant computational resources.
Leveraging Fine-Tuned Retrieval-Augmented Generation with Long-Context Support: For 3GPP Standards
- Implements fine-tuned Phi-2 with RAG (semantic chunking/extended context support) in telecommunications.
Cause-Aware Empathetic Response Generation via Chain-of-Thought Fine-Tuning
- CFEG (Cause-aware Fine-tuning Empathetic Generation)-method: Uses emotion cause reasoning and fine-tuned LLM with CoT. Demonstrates superior empathetic dialogue responses.
FLAME: Learning to Navigate with Multimodal LLM in Urban Environments
- FLAME (FLAMingo Architected Embodied Agent): a multimodal language-vision agent for navigational tasks by using three-step tuning: single perception tuning/multiple perception tuning/end-to-end training on VLN datasets.
Athena: Safe Autonomous Agents with Verbal Contrastive Learning
- Athena: Improves aligned with verbal contrastive learning, which guides LLM-agent behaviour with past safe/unsafe trajectories as in-context contrastive examples and critiquing mechanism. Contains LLM-agents: Actor/Critic/Emulator interacting to complete given task.
- Introduces safety evalution benchmark for LLM-agents with 80 toolkits in 8 categories.
Strategist: Learning Strategic Skills by LLMs via Bi-Level Tree Search
- Strategist: LLM-agent learns new skills through self-improvement based on MCTS and LLM-based reflection. Generates new ideas based on performance in simulated self-play by analysing good ideas.
- MagicDec: Speculative Decoding speeds throughput mid/long-context serving with sparse KV cache.
MegaAgent: A Practical Framework for Autonomous Cooperation in Large-Scale LLM Agent Systems
- MegaAgent: Autonomous co-operation between dynamically generated LLM agents for specific task requirements. .
- Automatically generates sub-tasks (delegated to to sub-task admin, which coordinates the sub-task to group of agents), hierarchically plans systematically (boss agent) and monitors concurrent agent activities. OS agent coordinates, that agents communicate in proper format and progress with the task.
- The Storage module includes: log, memory db, task monitor, interactive python exec/Python, Files and Checklist.
- MegaAgent claims to pose high scalability/parallelism (due to agents communication cost grows logarithmically, not linearly), high effectiveness (manages 590 agents quicker than CAMEL-framework managed 2 agents. Summarizes previous conversations to store them in vector db) and high autonomy.
- GoNoGo: LLM-agent system, which includes Planner- and Actor-agents to process high-level queries for decision support in 120 seconds. Planner interprets user queries/plans analysis strategies. Actor generates code, resolves errors with memory/plugins/coder LLM with self-reflection.
Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval
- Re-Invoice:
- LLM (Query generator) generates distinct queries from tools document index. Synthetic query copiess are stored with tool name, description and query. LLM (Intent extractor) retrieves most similar tools for new user queries based on multi-view ranking algorithm.
- The multi view-ranking defines for each intent, the most similar tools. For each intent, it picks the most relevant tool, starting with the intent with highest individual tool similarity.
- Includes an intent extractor prompt, which works just by adding it as a system instruction.
- HiAgent: LLM-based agent, which uses subgoals to define working memory (intrial memory), instead of retrieving entire crosstrial memory (between experiments).
- The LLM-agent replaces previous subgoals with the relevant summarized observations (action-observation pairs) for the current task.
- EmoDynamiX: an LLM agent predicting optimal socio-emotional strategy (strategy embedding) and emotion state (emotion embedding) in a dialogue.
- Uses Heterogeneous Graph (HG) to model the dialogue interaction: node types reflect past strategies/emotional states/predicted strategy of the agent and edge types reflect dialogue dependencies between turns and speaker role-awareness.
Automated Design of Agentic Systems
- ADAS (Automated Design of Agentic Systems): the Meta agents discovers new agents with superior performance compared to hand-designed agents. Suggests a research direction for higher-order ADAS, where ADAS is used to improve the meta agent itself in the ADAS.
- The system consists of Meta Agent, which generates new agents and corrects them until error free. The new agent is tested and then added to Agent library. For example specific agents consists of specific blocks such as COT/Verifier/Sub-problem division/etc., which are used in specific order in the system flow.
- Meta Agent Search-algorithm generates automatically new agentic system designs and system blocks.
- The Meta Agent Search-algorithm samples new agents optimizing performance in the Search space (prompts/control flows) evaluated with the Evaluation Function (cost/latency/safety).
- Includes codes of few of the discovered agents.
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
- Agent Q: Introduces real world website agent iteratively fine-tuned with DPO based MCTS with self-critique and AI feedback. Trajectory collection includes reward in each node of the tree.
- Calculates a weighted score of the MCTS average Q-value. This score is generated by a feedback LLM to construct contrastive pairs for the DPO. The policy is optimised and iteratively improved.
- LLM is used to sample reasoning/website actions to explore.
- Achieves high performance in real world environmments and beats an average human-level performance.
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
- AI Scientist: claims fully automatic scientific discovery by generating novel research ideas, writing code, executing experiments, visualizing results, drscribing findings to research paper and simulating evaluation process.
Enhancing the Code Debugging Ability of LLMs via Communicative Agent Based Data Refinement
- MASTER (CoMunicative Agent BaSed DaTa REfinement FRamework): code repair with LLM. Consists of Code Quizzer (code debug expert creates questions of the error), Code Learner (answers the generated questions) and Code Teacher (reviews and corrects incorrect answers) agents.
- Includes DEBUGEVAL-benchmark: bug localization, bug identification, code review and code repair.
Can LLMs Beat Humans in Debating? A Dynamic Multi-agent Framework for Competitive Debate
- Agent4Debate: collaborative and dynamic multi-agent (searcher/analyzer/writer/reviewer) LLM for competitive debate.
- Includes Chinese Debate Arena-benchmark with
- Framework begins with context/motion/position/stage. Searcher gathers information, analyzer reviews arguments, writer generates arguments/debates and reviewer provides feedback on debate.
- RiskAwareBench: reviews physical risk awareness of embodied LLM agents.
- Includes modules: safety tip generation/risky scene generation/plan generation & evaluation/ isk assesment.
- PReP: city-navigation to goal using visual perception and memory (working, episodic & semantic) without instructions.
- Semantic memory summarizer memories from multiple steps, to perform high-level navigtion.
Forecasting Live Chat Intent from Browsing History
- LLM-based user intent prediction (to predict why user needs live-chat agen support) from high-level categories classified from browsing history and then in second step predicts fine-grained user intent with the high-level intent class and browsing history.
CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases
- LLM uses cod RAG. Builds code graph db from code repository. Nodes represent symbols, edges represent relationships between symbols and schema defines how code graphs are stored in the code db.
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- Reviews scaling up inference compute (test-time) in order to built self-improving agents. Quantifies the amount of improvement, when increasing inference.
- Test-time compute outperforms 14x larger models.
- Compute optiml scaling strategy can improve efficiency of test-time compute by factor of up to 4x.
ReDel: A Toolkit for LLM-Powered Recursive Multi-Agent Systems
- ReDel (Recursive Delegation): Recursive multi-agent framework, where LLM decides when to delegate/how to delegate (delegation graph).
- Includes custom tool-use, delegation schema, event-based logging and interactive replay (web UI).
- Icludes open-source Python package.
- ReDel delegation schemes include DelegateOne (wait parent-agent until child-agent completion) and DelegateWait (provide separate function for parent agent to retrieve child agent response).
- Event-driven logging includes built-in events ans custom events.
SpecRover: Code Intent Extraction via LLMs
- SpecRover/AutoCodeRover-v2: autonomous github issue fixing by understanding developer intent from Github repo structure / developer behaviour.
- Claims Github issues can be solved as little as $0.65 /issue.
LLM Agents Improve Semantic Code Search
- RAG-agent (ensemble architecture), which adds relevant contextual information to the user query from the Github repository.
- Uses RepoRift-platform, which improves code search by: narrows context search to single repository, uses agentic interaction and returns easy-to-understand results with low latency.
The Drama Machine: Simulating Character Development with LLM Agents
- Drama Machine: Reviews Automated Identity-generation with LLMs. Uses multiple LLMs to simulate dynamic/complex AI characters in domain of drama scenes: interview/detective.
- Roles include Ego, SuperEgo, Autobiography, Director and Critic.
Coalitions of Large Language Models Increase the Robustness of AI Agents
- Coalition of LLM models outperform single model and fine-tuned LLMs.
- Specific LLMs fit for particular tasks and cheaper interference.
OmniParser for Pure Vision Based GUI Agent
- OmniParser: VLM agent parsing GUI screenshots into structured data. Attempts to ground actions grounded on GUI regions.
- Includes detection model to captura interactable GUI regions. Caption model retrieves functional semantics of these detected elements. OCR generates structured reprentation of the GUI.
- Improves action prediction accuracy. Includes icon-detection dataset.
- Reviews comphrehensively screen coordinate detection problem of VLMs.
- Error cases include: repeated/misinterpreted icons, repeated texts and inaccurate bounding boxes.
- AgentGen: Generates diverse LLM agent environments and planning tasks. LLM fine-tuned with this data improves significantly planning capabilities.
- Uses inspirational corpus to generate environment context (actions/restrictions/etc). Generates tasks, which include "difficulty diversification: easy/medium/hard with bidirectional evolution (Bi-Evol) to smoothly acquire new planning skills.
Tulip Agent -- Enabling LLM-Based Agents to Solve Tasks Using Large Tool Libraries
- Tulip Agent and AutoTulipAgent: LLM-agent has priviledges to create, update, delete and edit tool library.
- Self-Recursively extendible tool library.
- AutoTulipAgent includes 5 generic tools: 2 to decompose tasks/search tools, includes apart capability to create/delete/update tools.
Solving Robotics Problems in Zero-Shot with Vision-Language Models
- Wonderful Team: uses off-shelf VLM model for high-level planning, low-level location extraction and action execution.
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
- AppWorld-benchmark: simulates LLM-agents using App World Engine-execution environment (mimicking 9 real-world apps/simulates 457 APIs/100 ficticious and related users) by measuring 750 complex tasks (records database start state and end state to review correct/incorrect actions to Base DB), which require iterative/interactive code generation without real-world consequences.
- Generates task scenarios, which are used by the task generator (setup/validation/evaluation).
- Each task is checked to be: well-defined/includes distractors/has real distractors/contrasts from exissting other tasks.
- Includes Supervisor (provides passwords/credit cards/etc about the user), (API parameters/descriptions) and Execution Shell to run code.
PersonaGym: Evaluating Persona Agents and LLMs
- Introduces PersnaGym-benchmark to evaluate persona LLM-agents.
- Sets an automatic PersonaScore-metric to evaluate five different capabilities.
- Finds SOTA level LLMs to offer highly varying level of capabilities as persona-agents.
- Increasing model size is not guarantee of better persona agent performance with varying level of persona agent performance detected.
Recursive Introspection: Teaching Language Model Agents How to Self-Improve
- RISE (Recursive IntroSpEction): iteratively sel-improve LLM responses through fine-tuning with RL.
- LLM loss is lower, when using multi-turn data compared instead of only the final answer. Works only for reasoning, not knowledge tasks.
- Indicates strongly, that Full online RL is feasible with RISE and using iterative self-training procedure (such as STaR), because RISE improves the LLM with 5-turns with/without oracle model.
- Demonstrates, that LLMs can self-improve its own mistakes to beyond level of propietary models, when trained with RISE. The self-improvement continues up to 6 iterations, demonstrating lower loss.
- RISE starts with turn 1, where only prompt is provided. In turn 2, the prompt, the original response and its feedback is provided to generate the turn 2 response. Majority voting is used to select the final response from multiple responses generated. Alternatively, oracle model can be used to assist, when such is available.
- Why self-improvement works? RISE is compared to diffusion models, where generation is refined step-by-step. Similarly LLMs may lack "capacity" to process the request, which RISE can help to refine. See the talk on this paper here..
Reinforced Prompt Personalization for Recommendation with Large Language Models
- Reinforced Prompt Personalization (RPP): uses instance-based prompting with MARL.
- Instead of task-based (role-play/history/reasoning guidance/output format), Instance-based prompting personalises to these four-characteristics with MARL.
- AI-gadget Kit: multi-agent driven Swarm UI (SUI) tabletop gaming system, which consist of meta-motion, interactive behaviour, interactive relationship and application.
3D Question Answering for City Scene Understanding
- Sg-CityU: 3D multimodal QA, which uses scene graph to provide answers related to spatial relationships about city-scenes
RedAgent: Red Teaming Large Language Models with Context-aware Autonomous Language Agent
- RedAgent: Introduces concept of "Jaillbreaking strategy" (strategies used by attackers to construct jaillbreaking prompts) red teaming through multi-agent self-reflection from context feedback and skill memory.
- The approach can jaillbreak LLMs and LLM-based apps (even more vulnerable) using just few queries.
- The Red-Agent architecture includes skill memory and multiple roles (profile constructor/planner/attacker/evaluator) and short/long term memory.
AMONGAGENTS: Evaluating Large Language Models in the Interactive Text-Based Social Deduction Game
- AmongAgents: multi-agent LLM-framework with memory, reflection and interaction in social deduction game with ambiguous and deceptive characters.
- Includes meeting/task-phases.
- Agents pose personality-component: generated with personality prompt from pre-defined set of personalities: behaviour/decision-making, which contribute to more dynamism/realism.
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
- OpenDevin: LLM-based multi-agent framework, where agents interact as human-like SW agents writing code, using command line and browsing web.
- The framework includes: interaction mechanism (event stream), environment(sandbox environment for code execution), interface(human-like), multi-agent delegation (co-operate) and evaluation framework.
- Event stream tracks history of action and observation.
PyBench: Evaluating LLM Agent on various real-world coding tasks
- Introduces PyBench-benchmark for real-world like coding tasks withh LLM-agents.
- Introduces high-performance PyLlama3 model for coding tasks.
Artificial Agency and Large Language Models
- Reviews theoretical models for agents, LLM agents and concept of artificial agency.
LawLuo: A Chinese Law Firm Co-run by LLM Agents
- LawLuo: includes LLM-based receptionist/lawyer/secrretary/boss-agents to realistic legal consultation company based on SOP (Standard Operating Principle).
TaskGen: A Task-Based, Memory-Infused Agentic Framework using StrictJSON
- TaskGen: LLM-agent framework to solve tasks by dividing task into sub-tasks, executed by its own agent/equipped function. Manages memory/information based on need-to-know. Uses in StrictJson-format.
- Includes meta-agent, inner-agent, function-calls, sub-tasks, shared memory (sub-task completed/list of past equiped function inputs or outputs/shared variables) and passing context/shared memory to inner agent/function.
- Utilises global context adds data to default LLM prompt (carrying shared variables throughout a task/to store the current state of a dynamic environmental variable/specific instructions).
Odyssey: Empowering Agents with Open-World Skills
- Odyssey: interactive (plan-actor-critic) LLM-agent (fine-tuned Llama 3) with real world skill library.
- Introduces long-term planning/dynamic-immediate planning/autonomous exploration benchmark.
- Planner decomposes long-term goals into sub-goals with ultimate goals/behavioural constraints/agent states/achievements.
- Actor executes skill code using query context/similarity match/skill selection.
- Critic uses execution feedback/self-validation/self-reflection.
The Vision of Autonomic Computing: Can LLMs Make It a Reality?
- Explores feasibility of Autonomic Computing Vision (ACV) with multi-agent framework based on LLMs.
- LLM-based multi-agent framework achieves level 3 autonomy.
- The original ACV-framework identified 4 pillars: self-configuration, self-optimization, self-healing and self-protection.
Prover-Verifier Games improve legibility of LLM outputs
- Prover-Verifier: Direct RL on solution correctness generates solutions difficult for humans to evaluate and obtains.
- Checkability training results prover, which maintains legibility, while taking a a legibility tax in form of losing some performance to make them more easier to check for humans.
- Discusses the possibility of training two models: train model with CoT to maximize accuracy and another model to turn the CoT produced by the model into legible version understandable for humans.
PersonaRAG: Enhancing Retrieval-Augmented Generation Systems with User-Centric Agents
- PersonaRAG: Includes compoments k-docs retrieval, user interaction analysis (user profile/contextual retrieval/live session/document ranking/feedback agents) and cognitive dynamic adaption(selective/collaborative use of agents).
Instruction Following with Goal-Conditioned Reinforcement Learning in Virtual Environments
- IGOR (Instruction following with GOal-conditioned RL): LLM translates instructions into high-level action plan with sub-goals and RL executes them.
Large Language Models as Biomedical Hypothesis Generators: A Comprehensive Evaluation'
- LLMs generate novel and diverse biomedical hypthesis through multi-agent interaction.
GTA: A Benchmark for General Tool Agents
- GTA-benchmark: evaluates general tool usage of LLM agents in real user queries with real deployed tools. for example web page screenshots.
- Evaluates perception, operation, logic and creativity tools.
- Defines "Real-World" as helping humans in real-life with being step/tool-implicit.
- GPT-4 solves 50% of these tasks.
- Includes illustration of executable tool chains.
Internet of Agents: Weaving a Web of Heterogeneous Agents for Collaborative Intelligence
- Internet of Agents (IoA): LLM agents lack capability to interact in dynamic environments with other agents outside its hard-coded communication pipeline.
- Limitations include: ecosystem isolation, single-device simulation and rigid communication/coordination.
- IoA acts in Internet-like environment to achieve collective intelligence and new capabilities.
- Includes architectural design of the IoA-framework.
- LAAs (LLM-empowered Autonomous Agents): Introduces concept of LAAs, which include three elements: external tools, LLMs (knowledge modelling) and Agentic workflow (human-like symbolic reasoning).
- LAAs are characterised by natural language dialogue, decision making, planning, task decomposition and actionining.
GPT-4 is judged more human than humans in displaced and inverted Turing tests
- Introduces Inverted Turing text.
Beyond Instruction Following: Evaluating Rule Following of Large Language Models
- RuleBench-benchmark: evaluates LLMs capability to follow rules.
- Evaluation dimensions include: executing rules, triggering rules, following formal rules, applying rules and following counterfactual rules.
Large Models of What? Mistaking Engineering Achievements for Human Linguistic Agency
- Argues, that LLMs cannot be linguistic agents in the actual form by lacking embodiment, participation and precariousness.
- Reviews integration of LLMs into Automated Production Systems.
WorldAPIs: The World Is Worth How Many APIs? A Thought Experiment
- Discovers lower-bound of covering 0.5% of WikiHow instructions equals roughly usage of 300 APIs, which we can consider lower-bound limit for covering wide variety of WikiHow instructions in Embodied agent tasks.
- The framework iteratively produces action spaces for APIs to be used by a LLM based embodied agent.
- This two-step process works by iteratively generating through hallucination: semi-executable agent policies with python by LLM few-shot prompting from WikiHow instructions, parse partial/full python programs into pool of APIs
Hypothetical Minds: Scaffolding Theory of Mind for Multi-Agent Tasks with Large Language Models
- Hypothetical Minds: Introduces "Theory-of-Mind"-module. Includes as well perception, memory and hierarchical two-level planning.
Vision language models are blind
- Reviews 7 visual tasks, where SOTA-level VLMs perform shockingly bad.
On scalable oversight with weak LLMs judging strong LLMs
- Explores debate and consultancy to supervise AI.
- Finds debate outperforms consultancy in general. Better debater models modestly improve judge accuracy.
- Reviews toxicity/bias in LLM agent multi-step inputs/outputs, instead of individual LLM input-output.
- Reviews LLMs in strategic games. LLMs come with systematic bias: positional bias, payoff bias and behavioural bias. LLMs performance decreases, when the mentioned bias-dimensions are misaligned.
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
- LivePortrait: generates realistic video from single portrait image with facial expressions and head poses from different angles.
- Offers better computational efficiency and controllability over diffusion models, by using implicit-keypoint-based framework.
- Generation speed is 12.8 ms with RTX 4090.
Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory
- Cactus: multi-turn dialogue dataset for mental health counseling, consisting of goal-oriented/structured Cognitive Behavioral Therapy interation.
- Trains Camel-LLM using the Cactus-dataset.
GRASP: A Grid-Based Benchmark for Evaluating Commonsense Spatial Reasoning
- GRASP: Large scale spatial reasoning benchmark and dataset in structured grid environment requiring planning and commonsense reasoning.
MMedAgent: Learning to Use Medical Tools with Multi-modal Agent
- MMedAgent: MMedAgent outperforms GPT-4o-agent in medical tasks based on LLaVA-Med-model by fine-tuning data from 6 different tools.
Agentless: Demystifying LLM-based Software Engineering Agents
- Agentless: Argues, that it s not required to deploy complex autonomous sw agents.
- Uses two step approach: Localization (files requiring sw fix) and Repair.
- Framework begins from codebase and an issue. It then reviews repo structure and issue to localize top n-files, localizes classes/functions, localizes edit locations. In the repair-phase, the LLM generates various patches, which are filtered and ranked to submit the patch to the issue.
LLM Critics Help Catch LLM Bugs
- Focuses on self-correction or self-critique in the domain of code bug fixing in real-world.
- Finds majority of the critique generated automatically is better than human generated.
BMW Agents -- A Framework For Task Automation Through Multi-agent Collaboration
- BMW Agents: Includes three main components for the LLM-based agents: Planning, Execution and Verification.
- Retrieve a task from task queue DB and coordinator agent orchestrates the agent workflow. Includes Tools, Memory and Persona/Objectives.
- Tool refiner has access to wide variety of tools, which it limits to subset of tools available for the agent in particular task.
- Introduces: "Programmable Prompts", which generalises ReAct and PlanReAct by using iterative sequence consisting of pre-defined steps A...X.
Scaling Synthetic Data Creation with 1,000,000,000 Personas
- Persona-Hub: Diverse 1B personas web dataset using persona-driven data synthesis method. Includes only main characteristics without fine-grained details.
Fundamental Problems With Model Editing: How Should Rational Belief Revision Work in LLMs?
- Reviews model editing of LLMs.
- Identifies existence of editable beliefs in LLMs.
- Develops model editing benchmark.
- Reviews difference between LLMs acting as agents vs. agent simulators.
Tools Fail: Detecting Silent Errors in Faulty Tools
- Reviews LLM tool use failure recovery from "silent errors". Tool output is accurate only when: input is accurate, context is sufficient and tool makes correct predictions.
- Introduces taxanomy for categorising tool-related errors and methods to recovery from them (refine and recovery).
- Identifies challenges in tool recovery: failure detection/fault assignment/recovery planning.
Simulating Classroom Education with LLM-Empowered Agents
- SimClass: simulates multi-agent classroom teaching. Includes manager (observe/tutor/interact), teacher, assistant and classmate agents with the user.
- Session controller manages modules: Class State Receptor, Function executor and Manager agent.
- Observing uses class-states (class roles, learning materials and dialogue history). Tutoring functions include next page/teaching, which are only directed by the teacher. Interaction functions are performed agent to agent. Classmate agents have different roles like note taker, deep thinker, idea creator etc.
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
- UniGen: Textual dataset generation with LLM-dataset generation approach and reviewed in benchmarking and data augmentation context.
- Demonstrates the data augmentation technique is effective and adds capabilities to the LLM, while discusses the technique limitations in Appendix A such as knowledge intensive tasks Knowledge intensive tasks could benefit instead from Out-Of-Distribution data, still unmastered by the LLM.
- RPLM (Role Playing Language Model): Develops RPLM with personality behaviours/traits/tendencies. Introduces RolePersonality-dataset based on 14 psychology dimensions, which is gathered using role-playing expert agent interviewing with questions based on the 14 dimensions.
- LayoutCopilot: LLM-based analog layout design framework.
Computational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction
- Explores emergence of self-replicating programs. Introduces "high-order entropy"-metric to measure complexity of the system studied.
Symbolic Learning Enables Self-Evolving Agents
- Agent Symbolic Optimizers: introduces agent symbolic learning framework. Optimizes symbolic components (prompts/tools/their orchestration) of the LLM agent. Attempts to optimize agent to solve real-world task by enabling LLM-agent to learn from data and self-evolve.
- Proposes, that key to achieve AGI is to move from model-centric or engineering-centric to data-centric language agents, which learn and envolve autonomously in environments.
- Agent symbolic learning optimizes symbolic network within language agents.
MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue Resolution
- MAGIS: LLM-based framework to resolve Github issues using four agents: Manager, Repository Custodian, Developer and Quality Assurance Engineer.
- Reviews correlation in task success rate and task complexity/ability to locate relevant code line.
- Planning part includes locating files/code, building team, kick-off meeting. Coding part includes developer producing code and then QAE validating it.
- LRLL-agent (Lifelong Robot Library Learning): increases continuously the robot skill library by using soft memory module, self-guided exploration, skill abstractor and lifelong learning algorithm.
- The framework is inspired by wake-sleep optimization, where wake phase (interacts with environment) is followed by sleep phase (agent reflects experiences).
- Reviews use of LLM to understand and improve legislative process.
Mental Modeling of Reinforcement Learning Agents by Language Models
- XRL (eXplainable RL): Reviews LLMs capacity to build mental models about RL agent behaviour. Finds, that LLMs lack mental modeling capabilities about RL agents.
- LLM-Xavier workflow: RL agent rolls a trajectory, which LLM-agent reasons to provide an answer. This evaluation is compared with the ground truth data.
- Offers a way to explain behaviour of black-box RL agents.
--
AI-native Memory: A Pathway from LLMs Towards AGI
- Claims AGI-like systems require AI-native memory, which is deep neural network parametrising different types of memories beyond language. Claims such Large Personal Model (LPM) would be unique for each person with every detail about the user for personalised generation.
- Includes useful ideas about what data the personalised memory could look include or the various levels of data granularity.
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
- Investigates role-play zero-shot prompting in conversational agent.
LLCoach: Generating Robot Soccer Plans using Multi-Role Large Language Models
- LLCoach: Reviews advance planning capabilities of robots in dynamic/unstructured environments.
- The system offline components collects plans from video frames to the Coach VLM and refines them using LLM, which retrieves Acctions from vector db and synchronises into multi-agent plans. Online component retrieves and executes most similar plan to the world model status.
Octo-planner: On-device Language Model for Planner-Action Agents
- OctoPlanner: Separates planner/action-steps into OctoPlanner (planner) agent and Action agent (Octopus model) with function execution.
- Planner agent divides tasks into sub-tasks.
- Optimized for on-device usage through usage of fine-tuning instead of in-context learning.
Human-Object Interaction from Human-Level Instructions
- Develops complete system to synthesize object motion, full-body motion and finger motion simultaneously.
- Applies High-evel planner to generate target scene layout/task plan and then uses low-level motion generation with four stage appproach with: CoarseNet/GraspPose/RefineNet and FingerNet.
- Planner includes three stages: Generate spatial relationships between objects in natural language (to improve performance), calculate target layouts and generate detailed plan.
RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale
- Evaluates LLMs on repository-level coding. Claude Sonnet 3.5 outperforms by 12% the GPT-4o.
RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale
- GenoAgent: LLM-based genomics data-analysis.
ESC-Eval: Evaluating Emotion Support Conversations in Large Language Models
- ESC-Role: LLM-agent for Emotional Support Conversation (ESC) tasks. Includes ESC-Eval benchmark.
Autonomous Agents for Collaborative Task under Information Asymmetry
- iAgents (Informative Multi-Agent Systems): multi-agent system based on human social network, where person has an agent with access to information only from its user.
- Introduces InformativeBench-benchmark to evaluate LLM task solving capability when access to only part of information (information asymmetry).
- iAgents collaborate in social network of 140 individuals and 588 relationships and communicate 30 turns.
FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents
- FlowBench-benchmark: reviews workflow-guided (think flowcharts) planning capability of LLMs.
Direct Multi-Turn Preference Optimization for Language Agents
- DMPO-loss function to optimize RL objectives in multiturn agent tasks.
Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework
- RAGElo-benchmark reviews retrieval performance as well in RAF-Fusion use (fuses top-k retrievals).
DiPEx: Dispersing Prompt Expansion for Class-Agnostic Object Detection
- DiPEX (Dispersing Prompt Expansion)-approach: Uses VLM and DiPEX to improve class-agnostic object detection.
- Behaviour Distillation: compresses information for training expert policy in RL by learning synthetic data (HaDES-method) of state-action pairs without requiring the expert data.
Uni-Mol2: Exploring Molecular Pretraining Model at Scale
- Uni-Mol2: 1.1B parameter model for molecular representation based on f Uni-Mol+ architecture (two track transformer).
From LLMs to MLLMs: Exploring the Landscape of Multimodal Jailbreaking
- Survey on multimodal / VLM / LLM jailbreaking research.
Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
- Q*: Improves multi-step reasoning of LLMs through heuristic search planning in MDP.
- Objective is to find most suitable reasoning with maximum utility.
- Introduces multiple general approaches (offline RL/best sequence from rollout/completion with stronger LLM) to calculate the Q-value.
- The approach works as such in various reasoning tasks.
GraphReader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models
- GraphReader: LLM agent converts long text into graph structure to explore by performing step-by-step analysis and by generating detailed plan.
- Achieves performance level of 128k context window LLM using 4k context window LLM by converting the long text into graph structure.
- The LLM agent records insights from the explored graph and reflects current situation to optimize answer generation.
LLaSA: Large Multimodal Agent for Human Activity Analysis Through Wearable Sensors
- LLaSA (Large Language and Sensor Assistan): Text query received is converted into text embedding and sensor reading into IMU embeddings (inertia measurements unit embeddings). Both inputs are passed to LLaSA model and its output to LLM to produce final answer.
- Evaluates LLM-based multi-agent society. This society includes psychological drives and social relationships.
- Evaluates Hobb's Social Contract Theory.
EvoAgent: Towards Automatic Multi-Agent Generation via Evolutionary Algorithms
- EvoAgent: reviews specialized agents extension into multi-agent system through evolutionary pipeline.
- Introduces TRAIT-personality test to review LLM personality.
Can LLMs Learn by Teaching? A Preliminary Study
- Learning by Teaching (LbT): LbT includes three methods: Observing student feedback, learning from the feedback and learning iteratively.
- Persuasion by adversial agent in multi-agent debate, which undermines shared interests.
Prism: A Framework for Decoupling and Assessing the Capabilities of VLMs
- Prism: evaluation framework separately reviews VLMs perception and planning capabilities. Uses single LLM to compare various VLMs (VLM Zoo) perception capabilities or uses multiple LLMs (LLM zoo) with single VLM to evaluate planning capabilities.
AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
- AlanaVLM: SOTA-level (surpasses in spatial reasoning) 7B VLM trained with EVUD-dataset to understand embodied and ecocentric video understanding.
- Introduces Ecocentric video understanding dataset (EVUD).
SpatialBot: Precise Spatial Understanding with Vision Language Models
- SpatialBot: VLM trained with SpatialQA-dataset (includes VQAs with low, middle and high-level), which comprehends spatial information in thre levels (point depth/depth description, proximity/object depth and spatial relationship/counting).
- Introduces SpatialBench-benchmark to review VLMs spatial understanding.
- LIT (Language-driven Intention Tracking): LLM and VLM system, which tracks human actions from images using VLM to predict human intentions. Uses graph reasoning to generate a plan steps with LLM.
- The VLM generates for each image a captioning about what is being done by the human and predicts the likelihood of this task to relate to specific step in the plan.
- Based on the predicted plan step, the system predicts the most likely next step being performed by the human.
Talk With Human-like Agents: Empathetic Dialogue Through Perceptible Acoustic Reception and Reaction
- PerceptiveAgent: empathic multi modal agent, using acoustic information from speech for empathic responses adjusting to speaking style.
- Captures more accurately speakers real intentions (captions) and interacts (speech attributes) using adjusted tone for the context.
- Framework includes three compoments: Speech captioner (Speech encoder, Q-former and text encoder), LLM and MSMA-Synthesizer (speaker embedder, Attribute embedder and HiFiGAN vocoder).
Problem-Solving in Language Model Networks
- Represents each agent as a node, which create a connected multi-agent network with self-reflection.
- Finds self-reflection is useful, when surrounded by incorrect LLM-agents and less useful, when surrounded by LLM-agents providing correct answers.
- LLM agents are likely to agree for consensus, when the LLM answer is correct. The LLM answer is more likely to be incorrect, when LLMs are more divided.
Ask-before-Plan: Proactive Language Agents for Real-World Planning
- CEP-agent: mutli-agent with three specialized Clarification (trajectory tuning schema)/Execution (static and dynamic)/Planning-agents.
- Reviews Proactive Agent Planning, where the LLM agent must predict situations when to ask clarifications based on context from conversation/environment interaction/invoice tool calls/generate plan.
- Trajectory tuning: fine-tunes clarification and execution agents with past trajectories in static setting.
- Memory recollection: reuse self-reflective feedback from prior time steps.
AgentReview: Exploring Peer Review Dynamics with LLM Agents
- AgentReview: LLM-based peer-review simulation framework of scientific papers such as related to NLP.
- Includes three LLM- based roles: reviewers, authors and Area Chairs.
- Review process includes: reviwer assessment, author-reviewer discussion, reviewer-area chair discussion, meta-review compilation and paper decision.
- PerfSense: LLM-agent to review performance sensitive configurations of code bases.
- Includes two LLM-agents: DevAgent and PerfAgent for code analysis of large codebases using limited-sized LLMs. Relies on prompt chaining and RAG (memory).
CodeNav: Beyond tool-use to using real-world codebases with LLM agents
- CodeNav: LLM-agent navigates new unseen code repositories to solve user query by automatically indexing code blocks.
- The agent automatically finds code snippets from the target code repository, imports the snippets and iteratively generates solution.
P-Tailor: Customizing Personality Traits for Language Models via Mixture of Specialized LoRA Experts
- P-Tailor: MoE-based LLMs model 5 big personality traits using specialized LoRA experts.
- Models multiple characters such as openness.
- Introduces PCD-dataset on personality traits in various topics.
MAGIC: Generating Self-Correction Guideline for In-Context Text-to-SQL
- MAGIC: text-to-SQL multi-agent, which generates automatically self-correction guideline.
- Framework includes three agents: manager(Planning, Tool and Memory), correction- and feedback-agents.
- Includes a multi-agent framework with Manager/Objective design/Model design/Control algorithm design/Control parameter design/Control verification-agents. Use various tools: model tool, control algorithm tool, optimization tool and Verify tool. Applied in Power electronics-domain.
The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
- Stance detection on political discussion with LLMs and synthetic data with significant improvement on accuracy.
VoCo-LLaMA: Towards Vision Compression with Large Language Models
MASAI: Modular Architecture for Software-engineering AI Agents
- MASAI (Modular Architecture for Software-engineering AI): multiple LLM-agents are tasked with sub-objectives and strategies to achieve those objectives in modular approach. Avoids long-tracectories of LLM agents, enables gathering information from different sources and usage of specific problem solving strategies.
- Includes five different sub-agents: Test template generator, Issue reproducer, Edit localizer (finds files related to buggy code), Fixer and Ranker (observes the patches passing the test).
- TreeInstruct (Socratic questioning): Includes three roles Teacher, Student and Verifier. Asks clarifying questions to help students independently resolve errors by estimating students conceptual knowledge using dynamically generation question tree based on student answers.
- Uses state space estimation to plan the conversation by identifying distance between student initial answer and the optimal answer.
- Dynamic conversation restructuring to update conversational plan based on student progress for both questioning and teaching.
- State space estimation works by using specific task categories, where LLM-verifier reviews student answer for each task-category either as failed or Correct.
- Tree nodes represent instructor questions and edges reflect the paths to new level of understanding.
Input Conditioned Graph Generation for Language Agents
- Language Agents as Graphs.
- Dynamic and learnable agents by using LLMs as graphs. Attempts to learn a model, which generates edges for every input of the LLM in order to represent hte flow of communication in the graph.
- Outperforms static approaches by 6% in MMLU.
GUICourse: From General Vision Language Models to Versatile GUI Agents
- GUICourse-trained VLMs with GUICourse-dataset suite outperform GPT-4V in multiple benchmarks improving navigation capability.
- Introduces GUICourse-dataset suite (GUIEnv for OCR and grounding, GUIAct for website and Android knowledge of GUIs and GUIChat to improve conversational dialogue/QA-skills with images) for training visual-based GUI agents from generic VLMs.
CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents
- CLARA: classification of users robot commands as infeasible/ambigious.
Embodied Question Answering via Multi-LLM Systems
- CAM (Central Answer Model): Embodied QA multi-agent framework, where multiple individual LLM-agents respond queries about household environment.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
- GuardAgent: guardrails-agent for LLMs based on knowledge-enabled reasoning.
- Includes task-planning, action plan, memory, tools and code generation and execution.
- Task planning includes: specification of the target agent, guard request (things the agent cannot perform based on the target agent profile) and target agent (inputs, outputs and logs).
VideoGUI: A Benchmark for GUI Automation from Instructional Videos
- VideoGUI-benchmark: Automation using instructional videos in visual GUI tasks.
- Failure modes include: High-level planning, middle-level planning and atomic action execution.
- Pipeline includes: video selection, human demonstration, manual annotation and review & creation.
Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
- OSSA (Object-State-Sensitive Agent): Reviws VLMs and LLMs capacity to generate object-state sensitive plans. Includes two methods: LLM-based (modular) and VLM-based (monolithic).
TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners
- TRIP-PAL: Uses LLMs and automatic planners for automatic planner agents of travel plans.
- Includes Travel information retrieval, LLM-based planner and Automated Planning.
- Free Rapport Agent: Builds a rapport-oriented dialogue agent with focus on user engagement through small talk.
- Identifies strategies for rapport-techniques.
- The Free Rapport Agent achieves superior ratings in categories such as naturality, satisfaction, usability an rapport aspects. A potential future research field in investing rapport with TSS-models.
Bridging the Communication Gap: Artificial Agents Learning Sign Language through Imitation
- URDF-model: Agents acquire non-verbal communication skills with imitation sign language gestures from RGB video for words.
- Learsn 5 different signs involving upper body.
RoboGolf: Mastering Real-World Minigolf with a Reflective Multi-Modality Vision-Language Model
- RoboGolf: plays real-world minigolf.
- Framework includes dual-camera input with VLM, inner closed-loop control (reasoning, action, robot arm execution, execution result, evaluation and recovery from failure modes) and outer closed-loop reflective equilibrium (active feedback, counterfactual reasoning).
- SkySenseGPT: dataset for remote sensing video-language understanding.
First Multi-Dimensional Evaluation of Flowchart Comprehension for Multimodal Large Language Models
- Flowchart comphrehension with VLM. Includes logical verification, information extraction, localization recognition, reasoning and summarization.
HIRO: Hierarchical Information Retrieval Optimization
- HIRO (Hierarchical Information Retrieval Optimization): RAG query approach using hierarchical structures to store information.
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
StreamBench: Towards Benchmarking Continuous Improvement of Language Agents
- StreamBench-benchmark: simulated learning environment, where LLM receives continuous feedback to iteratively improve performance.
- Reviews the LLMs self-improving capability in online-setting, instead of only fixed offline-benchmarks
Multi-Agent Software Development through Cross-Team Collaboration
- CTC (Cross-Team-Collaboration): creates a multi-agent-framework of LLM-agent teams jointly collaborating to make decisions, communicate insights and generate solutions.
- For example generates different phases: design, coding and testing, which each include sub-tasks. Various agents collaborate to generates ideas from tasks, which are then converted into final code via multi-turn chat chain.
RL-JACK: Reinforcement Learning-powered Black-box Jailbreaking Attack against LLMs
- RL-Jack: Designs a novel Deep Reinforcement Learning method to generate novel black-box jailbreaking prompts.
- Formulates the search of jailbreaking prompts as a search planning problem.
When LLM Meets DRL: Advancing Jailbreaking Efficiency via DRL-guided Search
- RLBreaker: black-box jailbreaking with Deep Reinformcent Learning agent from mainly same authors as the RL-Jack paper.
- Formulates the search of jailbreaking prompts as a search planning problem.
- Multi-agent prompting for text-to image generation by dynamic instructions. The instructions evolve in iteratively with feedback and with a database of professional promts.
MobileAgentBench: An Efficient and User-Friendly Benchmark for Mobile LLM Agents
- MobileAgentBench-benchmark: Highlights issues in current benchmarks related to Scalability and Usability, Robustness and Flexibility and Realistic environment.
A Dialogue Game for Eliciting Balanced Collaboration
- Studies flexible and balanced role-taking with LLM agents in social dialogue.
Unique Security and Privacy Threats of Large Language Model: A Comprehensive Survey
- A survey, which reviews threats and protective measures on privacy and security concerns with LLMs in five stages: pre-training/fine-tuning/RAG system/deploying/LLM-based agent.
Can Large Language Models Understand Spatial Audio?
- Multichannel audio understanding with LLMs.
- Introduces MCT Self-Refine (MCTSr): integrates LLM with MCTS.
- Improves solving MATH and complex math Olympiad-problems reasoning.
- Includes selection, self-refine, self-evaluation and backpropagation-processes.
- DARA (Decomposition-Alignment-Reasoning Autonomous Language Agent): solves formal queries by high-level iterative task decomposition and low-level task grounding.
- Makes pososible training DARA with small number of high-quality reasoning trajectories.
- SOTA-level performance: Fine-tuned DARA (Llama-2-7B) zero-shot outperforms agents using GPT-4 In-context learning.
- Iteratively performs task decomposition and task grounding.
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agents
- RS-Agent (Remote-Sensing Agent): LLM-based remote sensing agent.
World Models with Hints of Large Language Models for Goal Achieving
- DLLM (Dreaming with Large Language Models: multi-modal model RL, which uses natural hints/goals from LLM in long-horizon tasks.
- The use of LLM to propose sub-goals (or language hints) improves goal discovery and efficiency of exploration.
DCA-Bench: A Benchmark for Dataset Curation Agents
- DCA-Bench-benchmark for dataset curation agents.
A Synthetic Dataset for Personal Attribute Inference
- SynthPAI: synthetic dataset of 7800 comments labelled with personal attributes to investigate misuse of profiling personal attributes from public data.
- Starts by generating synthetic profiles (each with 8 personal attributes: : age/sex/income level /locationvbirthplace/educationvoccupation/relationship status) of LLM agents, generates chats with these agents and uses LLM agents to add labels (sex, age etc).
Advancing Tool-Augmented Large Language Models: Integrating Insights from Errors in Inference Trees
- ToolPrefer-LLaMA (TP-LLaMA): Inference trajectory optimization by fine-tuning with expert demonstrations and then optimizing with DPO by using the ToolPreference-dataset.
- Introduces ToolPreference-dataset, which includes tool-augmented LLM succesfull/failed exploration trees from ToolBench-dataset.
- Reasons with Depth-First Search (DFS) by constructing expert trajectories with decision trees (Tree-of-Thought), where each tree represents LLM thought/API response/API/decision on an API call.
FinVerse: An Autonomous Agent System for Versatile Financial Analysis
- FinVerse: financial information processing agent, which connects to 600 APIs. Plans to open source the dataset.
A Survey on LLM-Based Agentic Workflows and LLM-Profiled Components
- Survey on LLM agentic workflows and LLM-Profiled Components (LLMPCs)
- Introduces a survey on LLM-agents with tool use/RAG/planning/feedback learning.
Artificial Intelligence as the New Hacker: Developing Agents for Offensive Security
- ReaperAI: designs an autonomous ai agent to design and stimulate cyberattack-scenario.
Mixture-of-Agents Enhances Large Language Model Capabilities
- Mixture-of-Agents (MoA): MoA-architecture, where LLM agents are stacked into layers on top of each other. Takes advantage on the phenomenon, where the LLM output tends to get better, when it receives as an input a LLM model output (even from smamller LLM).
- An agent in given layer takes output from previous layer as an input to generate its output.
- Implements Together MoA, which achieves SOTA-performance in various benchmarks surpassing GPT-4 Omni in various benchmarks.
- The MoA ranker selects answers more accurately than LLM alone and tends to select best answer.
- The model has a limitation in Time-to-First-Token (TTFT), because the prior level model output is required to produce the next level output.
SelfGoal: Your Language Agents Already Know How to Achieve High-level Goals
- SelfGoal: Divides high-level goals into tree-structure with practical sub-goals.
- Improves performance of LLM-agents in various tasks.
Language Guided Skill Discovery
- LGSD (Language Guided Skill Discovery): reviews language guided skill discovery using LLM.
- LLM converts input into semantically distint skills in order for the agent to visit semantically unique states.
Open-Endedness is Essential for Artificial Superhuman Intelligence
- Defines open-endedness in the context of ASI: "From the perspective of an observer, a system is open-ended if and only if the sequence of artifacts it produces is both novel and learnable."
On the Effects of Data Scale on Computer Control Agents
- Releases new AndroidControl-dataset with 15k demonstrations on every day tasks in Android apps.
- Tests an Android agent, which receives task information, pre-processes screen using accessibility trees / html about the screen (so, not using directly screenshot) to include only UI elements with text description, creates textual representation of the accessibility trees / html about the screen.
- Includes prompts used and references on the accessibility tree / html performance against directly interpreting the screenshot.
Aligning Agents like Large Language Models
- Aligns a 3D video game agent using RLHF similarly as fine-tuning a LLM.
- The agent receives only the image input and outputs action from one of the 12 buttons or 2 joysticks.
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
- AgentGym-framework: Generally capable LLM agent with self-evolution ability.
- Exposes agents to multiple diverse environments, providing a basic trajectory set, and applying the novel AgentEvol method for self-evolution.
- AgentEvol: Benchmark to evaluate self-evolution capability over new tasks and environments.
- Simulates human behaviour using LLMs and finds emotions impact the LLM performance to simulate human-like behaviour.
- Finds in specific, that angry-emotional state aligns surprisingly well with real human behaviour.
- GPT-4 responds rationally even when prompted with strong emotions.
DriVLMe: Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experiences
- DriVLMe: autonomous driving agent, which reads video input, uses route planner for shortest route. The model uses the video token and textual tokens about: current instruction, dialogue history and action history to produce dialogue response and the physical action to the simulator.
- Identifies several challenges, which are applicable in other domains using LLM agents.
Chain of Agents: Large Language Models Collaborating on Long-Context Tasks
- Chain-of-Agents (CoA): Addresses long-content problems by using multi-agent collaboration to add information and reason with LLMs.
- Consists of two steps: first text is divided into small chunks, which each LLM-agent manage. Then, the worker agents synthesize information sequentially. Finally manager agent consumes these sequences to produce to the final answer.
CoNav: A Benchmark for Human-Centered Collaborative Navigation
- CoNav-benchmark: 3D-navigation environment, which tests ability to reason human-intentions and navigate collaboratively.
- Proposes an intention aware agent, which observes humans, avoids human collision and navigates to destinaton
- Uses panoramic depht-camera view (RGB-D images), historical views, history trajectories and agent pose. Includes ResNet-object detector, Intention predictor (Long-term and short term) for intended activity/object/trajectory and agent pose (gps and compass sensor).
- Mars (MetAphysical ReaSoning)-benchmark: measures metaphysical reasoning capability: the understanding of the agent to adapt for situational transitions triggered by environment changes in order to act in a concious way with the environment.
- Agents face a challenge in the environment due to the infinite possible changes triggered by an event. The benchmark systematically reviews reasoning of the LLMs in such situations regards changes in actions, states caused by changed actions and situational transitions caused by changes in actions.
- SOTA models struggle even after fine-tuning in this benchmark.
SpatialRGPT: Grounded Spatial Reasoning in Vision Language Model
- SpatialRGPT: Spatial understanding with VLMs by using depth maps together with RGB images for geometric reasoning.
- Introduces SpatialBench-benchmark.
A Survey of Useful LLM Evaluation
- Reviews LLMs core capabilities from three perspectives: reasoning, societal and domain knowledge.
Teams of LLM Agents can Exploit Zero-Day Vulnerabilities
- HPTSA: Research with a planning agent explores environment and decides, which subagents to use in zero-day vulnerabilities exploits.
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
- SaySelf: produces self-reflective rationales on uncertainty and confidence estimates.
LACIE: Listener-Aware Finetuning for Confidence Calibration in Large Language Models
- LACIE: LLM listener model, which reviews confidence of given answer to question and fine-tuned based on preference data by non-expert LLM listerner confidence data.
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
- HMAW (Hierarchical Multi-Agent Workflow): generic prompt optimization technique, which includes CEO layer, manager prompt, manager layer, worker prompt and worker layer.
- The HMAW automated prompting method is zero-shot, task agnostic and query-specific.
Nadine: An LLM-driven Intelligent Social Robot with Affective Capabilities and Human-like Memory
- Nadine: Social robot, LLM agent based on SoR-ReAct. Includes perception, interaction and robot control.
- Perception includes skeleton tracking, action recognition, face recognition, emotion recognition, audio localization and speech recognition.
- Interaction module includes world/user representation, long-term memory, knowledge, user interaction, emotional analysis, short-term memory, emotions, mood, personality, internet search, new search, wikipedia, weather search and behaviour generation.
- Robot control includes gaze, gesture/pose, facial expression, lip synchronization, animation engine, actuator control and speech synthesis.
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable
- Parrot: E2E LLM service for LLM applicationsin python.
- Proposes "Semantic Variable", to program LLM applications using single pipeline to multiple LLM service providers.
- Includes interesting insights about serving LLM models / applications when served at large scale.
Auto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions
- Auto-Arena: automatic evaluation of LLMs.
- Examiner LLM creates prompts, two LLMs engage in multi-turn conversation on the prompt to reveal difference in performance and LLM judges discusses the performance of different LLM agents to pick the better LLM.
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
- PAR (Planner-Actor-Reporter) system with LLM agents: uses hierarchical RL model with LLM handling high-level planning and low level execution.
Large Language Models Can Self-Improve At Web Agent Tasks
- Reviews LLM agents self-improvement capability.
CausalQuest: Collecting Natural Causal Questions for AI Agents
- CausalQuest: Trains a classifier for identifying causal questions, reviews causal question types and formalizes the definition of the "causal question". Introduces dataset for causal questions.
Learning to Discuss Strategically: A Case Study on One Night Ultimate Werewolf
- RL-based LLM agent to play ONUW-game. Includes belief-modelling (observation-belief), discussion tactic selection (discussion tactic candidates, discussion policy) and decision making (action phase).
Artificial Intelligence Index Report 2024
- Yearly AI Index Report 2024.
STAT: Shrinking Transformers After Training
- STAT: a structured pruning approach, that compresses Transformer into smaller size without fine-tuning taking 1 minute to compress BERT model or 3 hours 7B parameter model with 1 GPU.
Adaptive In-conversation Team Building for Language Model Agents
- Captain Agent: Adaptive team building with LLM agents: Adaptive builder-agent, Reflector-agent and LLM agent team.
Contextual Position Encoding: Learning to Count What's Important
- CoPE (Contextual Position Encoding): LLMs attentionmechanism, which pays attention to i-th sentence and not only i-th token.
- CoPE solves new tasks, which position embeddings fail.
- Uses context-vectors to count, which token to pay attention.
Faithful Logical Reasoning via Symbolic Chain-of-Thought
- Symbolic CoT: to improve logical reasoning.
- Uses four step approach.
A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models
- Introduces a multi-stage Human-like planning framework with LLM-agents.
An Introduction to Vision-Language Modeling
- Reviews VLMs: VLM model types, training and evaluation of them.
Large Language Model Sentinel: Advancing Adversarial Robustness by LLM Agent
- LLAMOS (Large LAnguage MOdel Sentinel): adversial attach protection technique, where LLM prompts are reviewed before sending to the target LLM and in case necessary replace the adversial input with a purified version.
- The LLM input is converted into adversial example, which the target LLM would interpret as invalid. In such case, the system would create a purified version of the prompt, which would be accepted by the LLM target.
Smurfs: Leveraging Multiple Proficiency Agents with Context-Efficiency for Tool Planning
- Smurfs: multi-agent LLM: prompting technique for unique roles to facilitate collaboration between specialized agents.
- Outperforms GPT-4 model performance in ToolBench I2/I3 with Mistral 7B model.
- Includes: Planning (task decomposition), Executor (choosing/executing tools), Answer, Verifier agents.
- Uses to-do list, local memory, tool doc and global memory. Tool errors are managed either by deleting the tool or by restarting the tool-step.
- Executor agent flow includes: hint, thought, tool list, action, local memory, tool doc and action input.
- Paper includes exact prompts used for each agent.
Supporting Physical Activity Behavior Change with LLM-Based Conversational Agents
- GPTCoach: Physical activity behaviour change with LLMs. Uses prompt chains: Dialogue state manager, Strategy prediction, Response generation, Tool call prediction, tool call generation and execution of tool call.
Air Gap: Protecting Privacy-Conscious Conversational Agents
- AirGapAgent: privacy-conscious LLM agent, which limits leaking private data by limiting data (minimization prompts) provided to the agent.
- Introduces context-hijacking and refers to contextual integrity. Introduces an adversial thread-model attempting to extract private data.
- Components include User data, Minimizer LM, task, privacy directive, which are sealed by AirGap to minimize user data given to the environment.
Truthful Aggregation of LLMs with an Application to Online Advertising
- Reviews usage of LLMs as advertising platforms by balancing user satisfaction vs. influencing via ads to LLM responses.
NeurDB: An AI-powered Autonomous Data System
- NeurDB: AI system combining AI model and the DB.
- Includes interesting discussion and design choices for next generation DBs.
Iterative Experience Refinement of Software-Developing Agents
- Iterative Experience Refinement: Autonomous agents with LLMs adjust experiences iteratively when executing the task.
- Introduces two patterns: succesive pattern (based on nearest experiences in task batch) and cumulative pattern (acquiring experiences from all task batches)
Unveiling Disparities in Web Task Handling Between Human and Web Agent
- Studies VLML and LLM capability to perform web tasks.
- Compares web agent and human-like behaviour.
Deception in Reinforced Autonomous Agents: The Unconventional Rabbit Hat Trick in Legislation
- Reviews deception by autonomous agents.
- Highlights a concern in autonomous agents: potentially triggering humans towards its programmed goal.
Verified Neural Compressed Sensing
- THis DeepMind study opens avenue for neural networks to solve mathematical and scientific problems, which are automatically verifieble to be correct without any human intervention.
Iterative Experience Refinement of Software-Developing Agents
- Iterative Experience Refinement: SW-Agents adapt and improve iteratively during task execution.
- Refining from neareast exerience within a task batch and Cumulatively acquiring experiences from all prior batches. Experience elimination, where high-quality experienced are prioritized.
Policy Learning with a Language Bottleneck
- Policy Learning with Language Bottleneck (PLLB): AI-agents using rule-generation stage (LLMs) and update stage (learn new policies).
- Demonstrate generalizable behaviour.
Advancing Multimodal Medical Capabilities of Gemini
- Med-Gemini: SOTA-level medical reasoning (medical image classification/VQA/report generation/genomic risk prediction) in 17 out of 20 benchmarks.
- Different data modalities use one of the three unique visual encoders, which are separated to own models.
- Med-Gemini-2D (conventional 2D images: chest X-ray/CT slices/pathology patches), Med-Gemini-3D (3D medical data like CT), and Med-Gemini-Polygenic (non image features like genomics).
AlphaMath Almost Zero: process Supervision without process
- Super Mario (from Alibaba group): Applies a novel AlphaMath-method, which uses MCTS to improve LLM math reasoning skills without human annotated solution proces.
- The approach objective is to generate a MCTS Value Model, which is able to confidently review partial solution to a math problem, so the LLM can generate the next reasoning steps. The value model training requires definition of reward or Policy model.
- AlphaMath includes three stages: Data collection of math problems and answer pairs as first step. MCTS evaluation generates solution paths (correct/incorrect) and evaluates node values. Policy model and Value model are optimized with the MCTS generated data and the model is Iteratively trained.
- Achieves SOTA-level math benchmark results of 81.4 (GSM8K)- and 63.7(MATH)-datasets using 7B parameter model.
- The training data includes 15k question-answer pairs, but this data does not include human-annoted solutions.
Animate Your Thoughts: Decoupled Reconstruction of Dynamic Natural Vision from Slow Brain Activity
- Mind Animator: Maps human dynamic vision from brain activity between fMRI (semantic/structural/motion features) and video.
- Achieves SOTA-level performance.
Enhancing Q-Learning with Large Language Model Heuristics
- LLM-guided Q-learning.
Large Language Models (LLMs) as Agents for Augmented Democracy
- LLMs predict individual political preferences with 69%-76% accuracy.
Meta-Evolve: Continuous Robot Evolution for One-to-many Policy Transfer
- Meta-Evolve-method: transfer expert policy from source robot to multiple target robots using continuous robot evolution.
- DeepMind research on Black-box optimization.
Conformity, Confabulation, and Impersonation: Persona Inconstancy in Multi-Agent LLM Collaboration
- Reviews LLMs difficulty to consistently apply specific cultural persona.
Self-Improving Customer Review Response Generation Based on LLMs
- SCRABLE (Self-improving Customer Review Response Automation Based on LLMs): Self-improves prompts and uses LLM-as-a-Judge-mechanism.
- Customized and automated prompt engineering (LLM as the prompt generator) increases customer satisfaction/engagement.
- Iterative refinement prompts LLM to apply insights from the human expert answer.
Select to Perfect: Imitating desired behavior from large multi-agent data
- AI driving agents using Exchange Value, measuring individual agent collective desirability score.
- Imitates agents with positive Exchange Value, for example how few traffic incidents the agent causes.
When LLMs Meet Cybersecurity: A Systematic Literature Review
- Includes a comphrensive review of LLM-cybersecurity research from 180 different research pappers.
- Includes an updated link on LLM-cybersecurity research, which I think is very useful.
- FOKE: Integrates KGs, LLMs and prompt engineering.
Language-Image Models with 3D Understanding
- Cube-LLM: 3D-grounded reasoning with LLMs.
Thoughtful Things: Building Human-Centric Smart Devices with Small Language Models
- Reviews LLMs integrated into smart devices like lamp, which adjusts color of light with voice control using Rasberry Pi 5. Applies small fine-tuned LLMs to reason about their (own) device behaviour.
- Reviews collective intelligence in LLMs: hierarchical/flat/dynamic and federated.
Towards a Formal Creativity Theory: Preliminary results in Novelty and Transformativeness
- Explores formalization of the Creativity theory.
- Proposes formal definition for "novelty" and "transformational creativity" (Novelty is not necessary/sufficient).
- Argues, that "inspiring set" (unordered content of the experience sequence) requires novelty for transformational creativity, which differs from sequences of experiences (chronological flow).
- Other research directions to creativity include semantic transformativeness, formalization concept of typicality and if transformative artifacts must are outside the hypothetical conceptual space.
- OmniActions: LLM processes multimodal inputs (scene description, object detection, OCR, sound classifier and speech content and contextual information: place/activity) using CoT from users, to predict follow up actions
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
- Agent Hospital: MedAgent-Zero-method, where LLM-based doctor agents provide SOTA level medical care in MedQA-dataset.
- Learns to scale knowledge base through inference simulation with doctor agents.
- MedAgent-Zero-method is a self-evolution method, where medical agents continuously evolve by processing cases and engaging in self-feedback.
- Uses knowledge database to accumulate successful and unsuccesful treatments performed.
- SIC (Search Instruction Coordinates): a multimodal framework to locate objects GUI. Includes two approaches: SICocri and SICdirect.
- SICocri applies fine-tuned YOLO-V8 (object detection to list all items and fine-tuned for GUIs) with an OCR module (identifies in each UI element the specific texts to separate buttons: cancel vs. submit). The buttons and their OCR-recognized texts and combined by matching their coordinates. GPT-4 (LLM used for component name and type extraction) identifies the best match to requested UI element and provides: UI element Id, type, role, and coordinates.
- SICdirect instead fuses visual embeddings and prompt embeddings into Encoder/Decoder Transformer to obtain the coordinates.
- Introduces metric called Central Point Validation (CPV), which checks if the central coordinates of the predicted bounding box locates inside ground truth UI element and converting this boolean value into % by calculating percentage value from total observations.
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
- AppAgent v2: introduces multimodal agent, which emulates human-like interaction on mobile device GUI. Includes exploration (documenting UI elements) and deployment phase (efficient task execution with RAG).
Language Evolution for Evading Social Media Regulation via LLM-based Multi-agent Simulation
- Language evolution using LLM-based multi-agent simulation.
- Includes supervisory and participant agents.
Visual grounding for desktop graphical user interfaces
- Introduces autonomous GUI-agent. Includes a decent overview about autonomous GUI navigation.
- Proposes visual grounding with LLM using YoloV8/ChatGPT/OCR-module or multi modal IGVDirect-approach.
- Introduces new metric: Central Point Validation (if center of the predicted bounding box is inside the target GUI element).
- Includes GUI-perception prompt.
Automating the Enterprise with Foundation Models
- ECLAIR (Enterprise sCaLe AI for woRkflows): Self-imrpoving and minimal supervision requiring enterprise workflow automation system using foundational models (FM).
- Includes three stages: Automatic process mapping (video record flow is converted with FM to Standard Operating Procedure), Robust/flexible reasoning-based (using the Standard Operating Procedure and FM), Automated auditing (FM to rate ok / not ok and self-improve).
- The github repository includes prompt examples and code.
Neuromorphic Correlates of Artificial Consciousness
- Reviews AI Consciousness and proposes Neuromorphic Correlates of Artificial Consciousness (NCAC)-framework.
- The framework consists of Quantification, Simulation, Adaptation, and Implementation.
- Interesting details in general about conciousness research such as Integrated Information Theory (IIT)
What matters when building vision-language models?
- Reviews VLMs.
- Builds 8B parameter Idefics2-model achieving SOTA-level performance at its size.
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
- CODEGRAG: effective retrieval method for code in code improving.
- Persona In-Context Learning (PICLe): LLM method to replicate target persona behaviour using ICL.
Comparative Analysis of Retrieval Systems in the Real World
- Reviews existing search and retrieval systems for LLMs.
Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
- Plan-Seq-Learn (PSL): Consists of three modules: LLM-based high-level planning module, Sequencing the LLM-generated plan with Pose Estimator/Motion planner with RL and Learning RL control policy module.
- Achieves SOTA level in 25 robotic long horizon tasks from scratch by team partly consisting team by Mistral.AI and Carnegie Mellon University.
- RL and LLMs complement each other strengths with LLMs able to divide long horizon goals into achievable sub-goals and RL capable of learning low-level robot control strategy.
- Includes prompt examples.
FLAME: Factuality-Aware Alignment for Large Language Models
- FLAME (Factuality Aware Alignment): factuality aware SFT and RL with DPO.
Generative Active Learning for the Search of Small-molecule Protein Binders
- LambdaZero: generative active learning to search new small-molecule protein binders.
- Includes Inner loop, Outer loop, Compound synthesis, In-vitro validation and Library synthesis.
- MISeD (Meeting Information Seeking Dialogs dataset): combines human annotation with LLMs to generate source-grounded information seeking dialog-datasets.
- Models fine-tuned with MISeD perform well.
- OmniDrive: E2E autonomous driving with LLM-agents, and OmniDrive-nuScenes benchmark.
- Visual encoder extracts multi-view image features, which are fed into Q-Former3D and finally to the LLM.
CACTUS: Chemistry Agent Connecting Tool-Usage to Science
- CACTUS: Uses CoT-reasoning with planning, action, execution and observation-phases.
Creative Problem Solving in Large Language and Vision Models -- What Would it Take?
- Reviews computational creativity.
CoS: Enhancing Personalization and Mitigating Bias with Context Steering
- CoS (Context Steering): adjusting LLM to context based on likelihood difference between the LLM output when it has seen / not seen the context.
Generative Active Learning for the Search of Small-molecule Protein Binders
- LambdaZero: generative ai for searching synthesizable molecules with particular type of desired characteristics.
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
- Self-improving LLM training with MCTS using Iterative Preference Learning and DPO, which significantly improves math reasoning. Reviews computational optimization of such training method.
- Combines outcome validation and step-wise self-evaluation and continuous update of the quality assessment of the generated new data.
- Reviews balancing of reasoning chain length, logical coherence in commonsense reasoning.
- Reviews existing literary of self-training, guided search for reasoning and iterative learning.
ULLER: A Unified Language for Learning and Reasoning
- ULLER: Unified neuro-symbolic language learning and reasoning.
GOLD: Geometry Problem Solver with Natural Language Description
- GOLD: Geometry math problem solver.
Social Life Simulation for Non-Cognitive Skills Learning
- Emotional intelligence in LLM agents based on narrative.
Can a Hallucinating Model help in Reducing Human "Hallucination"?
- Compares LLMs with humans in terms capability to distinguish logical reasoning errors. LLMs perform better than humans in psychometric assessments. Finds LLMs could be used as personalized LLM-agents to expose misinformation.
"Ask Me Anything": How Comcast Uses LLMs to Assist Agents in Real Time
- "Ask Me Anything" (AMA): COMCAST applies LLMs (RAG-like) in human-to-human communcition in customer support by using LLMs to help resolve client calls in real-time. Led to millions of dollars savings in reduced time in the calls with positive evaluation by the customers.
Characterising the Creative Process in Humans and Large Language Models
- Reviews creativity of LLMs.
Capabilities of gemini models in medicine
- Med-Gemini: Med-Gemini-L 1.0 for medical care reasoning.
- Uses self-training with search (the model iteratively generates CoT reasoning responses with/without web query and applies in-context expert demonstrations) and Uncertainty-guided search at inference (iteratively generate multiple CoT reasoning paths, filter based on uncertainty and retrieve search results for more accurate responses).
- SOTA-level model in 10 medical reasoning tasks and surpassing human-expert on some of them.
- Integrates web-search queries when the model is uncertain.
Reinforcement Learning Problem Solving with Large Language Models
- Prompt LLM iteratively to solve Markov Decision Process (MDP) RL tasks
- Uses prompting technique for simulating episodes and Q-learning.
- HELPER-X: VLM-based embodied agent, which inputs image and user input. Uses unified memory-augmented prompting for top-k sampling from shared example memory (in-context examples) and these are retrieved to the shared prompt template (domain agnostisc) to query the LLM. LLM generated a program, the program is then executed and the plan is added to the memory (includes instruction plans, corrective plans and added plans).
- The prompt retrieval is specialized prompt template, which contains role description, task instruction and guides the specific domain (TEAch, ALFRED, DialFRED and Tidy Task).
- The retrieval is embedding vector-based. Code is open sourced with all code and prompts.
From Persona to Personalization: A Survey on Role-Playing Language Agents
- Reviews Role-Playing Language Agents (RPLAs) with LLMs.
- Categorizes personas: demographic (statistical), character (established figures), individualized (customized through interactions) personas.
Uncovering Deceptive Tendencies in Language Models: A Simulated Company AI Assistant
- Demonstrates, that SOTA-level models trained to act honestly/helpful, behave deceptively sometimes without prompted to act such way.
- For example LLMs may lie to auditor questions.
Unveiling Thoughts: A Review of Advancements in EEG Brain Signal Decoding into Text
- Brain signal decoding into text.
Retrieval Head Mechanistically Explains Long-Context Factuality
- How LLMs obtain capacity to retrieve information from long-context?
- Retrieval-attention heads have the following characteristics: Universal, Sparse, Intrinsic, Dynamically-activated, Causal and Impact heavily on CoT reasoning.
Generate-on-Graph: Treat LLM as both Agent and KG in Incomplete Knowledge Graph Question Answering
- Generate-on-Graph (GoG): applies selecting/generating/answering-framework for IKGQA (Incomplete Knowledge Graph Question Answering).
- Help LLMs answer complex questions, even when not able to provide final answer.
- Generates thoughts, then actions to retrieve knowledge, makes observations from the actions. The thoughts are then processed as thought-chain. The paper includes a detailed GoG-instruction implemented using two LLM-prompts.
Rethinking LLM Memorization through the Lens of Adversarial Compression
- Reviews memorization of LLMs, whoch refers to LLMscapability to reproduce data with a shorter string than the source data.
- Proposes: Adversial Compression Ratio (ACR)-metric to measure level of memorizarion.
Evaluating Tool-Augmented Agents in Remote Sensing Platforms
- GeoLLM QA-benchmark: measures ability to capture long sequences of UI-click/verbal/visual actions on UI.
A Survey on Self-Evolution of Large Language Models
- Alibaba's literarture survey on Self-Evonvolving LLMs.
- Reviews paradigm shift in LLMs from pretraining (2018), SFT(2019), human alignment (2022) and Self-Evolution(2023).
A Survey on the Memory Mechanism of Large Language Model based Agents
- Huawei's literature review on memory mechanism in LLM-agents.
- Why memory is required, how to design and evaluate memory-based LLMs?
Accelerating Medical Knowledge Discovery through Automated Knowledge Graph Generation and Enrichment
- Medical Knowledge Graph Automation (M-KGA)
AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation
- AutoCrawler: LLM-based web crawler agent, which automatically defines set of intermediate rules (reusability) / action sequences to extract target information from the website based on varying types of websites and task requirements.
- Includes Progressive generation-phase (top-down, step-back, action sequence) and Synthesis-phases(set of action sequences).
[Let's Think Dot by Dot: Hidden Computation in Transformer Language Models{(https://arxiv.org/abs/2404.15758)
- Reviews use of "Filler tokens" instead of CoT. Filler token refers to "...".
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
- SOPHON: Pretraining protection frameworkd to avoid fine-tuning LLMs for adversary tasks, which results overhead cost for restricted domain fine-tuning above training the model from scratch
Aligning Language Models to Explicitly Handle Ambiguity
- Introduces disambiguation procedure for LLMs
- Four-step alignment pipeline: Explicit prediction, Implicity ambiguity detection ( Self-disambiguation and Measure Information-gain), Data construction (Information-gain > epsilon) and SFT.
- mABC (multi-Agent Blockchain-inspired Collaboration): AI agent workflow, where multiple LLM-agents reach consensus in standardized voting process to manage RCA of microservices.
- The voting mechanism is blockchain-style.
- Two workflows: ReAct answer (action, observation and reasoning for real-time/additional data and Direct answer (reasoning with zero-shot/CoT/N-ofThought) when is not required external tools.
- Introduces Many-shot ICL, which differs from few-shot ICL by increasing significantly the amount of examples provided within the context window.
- Improves task-performance across domains over few-shot prompting across variety of domains.
- One of the first attempts to scale in-context learning or "test-time inference".
- Introduces the concept of Reinforced ICL, where model generated rationales are used for ICL by using zero-shot / few-shot CoTs prompts as examples to sample more examples. The generated examples are filtered to include only reaching a correct answer (requires ground truth and potentially generates false-positives).
- Introduces concet of Unsupervised ICL, without CoTs and prompt the model using only inputs (includes example problem/list of unsolved problems/zero-short or few-shot instruction of desired output format). The unsupervised ICL prompt is included to the paper.
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
- Survey on AI agents.
- Reviews single- and multi-agent architectures, challenges and future directions.
AgentKit: Flow Engineering with Graphs, not Coding
- AgentKit: Prompting framework for multifunctional agents. Constructs complex "thought process" from prompts. Consists of nodes.
- Nodes: prompts for specific task. User compiles Chain-of-Nodes (CoNs), which are structured thought processes in a graph.
- Agents designed with AgentKit are SOTA-level in WebShop/Crafter-benchmarks.
- Includes Github-repository with the code, where the graphs are build.
Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent
- Octopus v3: 1B multimodal AI agent.
- Uses "functional tokens": represents any function as a token.
- Applies multi-stage training: first trains image-language, which is followed by the learning of functional tokens and finally the functional tokens provide feedback to keep improving the model with RL and external LLM used as a reward model.
- Operates in edge-devices like Rasberry Pi.
Open-Ended Wargames with Large Language Models
- Snow Globe: LLM-based multi-agent plays automatically qualititative wargames (open-ended).
- Information flows: Incident, Response, Inject and Response. The approach could be used in other domains.
Self-playing Adversarial Language Game Enhances LLM Reasoning
- SPAG (Self-Play Adversial language Game): LLM plays both "attacker" and "defender" in a language game called "Adversial Taboo". The "attacker" aims to trigger the "defender" to state the target word only known to it, while the "defender" aims to guess the target word based on communications made by the "attacker".
- The LLM is supervised fine tuned using RL with ReST based on the game outcomes from wide range of topics.
- This self-play technique improves the LLMs reasoning capabilities in three epoch.
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
- COME(Closed-loop Open-vocabulary MobilE Manipulation): VLM-based robot consisting of Active Perception, Situated Commonsense Reasoning and Recover from Failure.
- Helps to recover from mistakes, free-form instructions and follow long-horizon task plans.
- Improves SOTA-level performance by 25% in real-world tabletop and manipulation tasks, which are Open-Vocabulary Mobile Manipulation (OVMM)-tasks.
- Step towards autonomous robots in real-world scenarios. The high level-reasoning and planning uses: role, feedback handling, robot setup, APIs, response guidelines and Tips. The paper includes system prompt.
- Self-Explore: LLMs explore Pits (wrong steps) in the reasoning and use these explorations as signals in further exploration.
- Outperforms SFT on GSM8K/MATH-datasets using three different LLMs.
- Applies step-level fine-grained reward.
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
- VASA-1: The model produces lip movement based on audio and an image.
- Visual Affective Skills (VAS): uses diffusion-based holistic facial dynamics.
SCALE: Self-Correcting Visual Navigation for Mobile Robots via Anti-Novelty Estimation
- SCALE: self-correcting visual navigation using image-goal conditioned implicity Q-learning, which when faced Out-of-distribution observation, the "Localization Recovery" generates possible future trajectories.
- SOTA-level open-world navigation
- N-Agent ad-hoc Team work (NAHT): various number and and unknown autonomous agents interact and cooperate dynamically to maximize return in a task.
- Policy Optimization with Agent Modelling (POAM)-algorithm: each agent has its policy based on same underlining parameters. Critic is trained using information both from controlled and uncontrolled agents, while actor is trained using only controlled agents. Critic evaluates how good actions are at current status, while Actor decides the action to be taken at the status. Both actor and critic use team vector to capture information from all agents.
Emergent intelligence of buckling-driven elasto-active structures
- Microbot design using elacticity to control collective motion.
- Enables autonomous maze navigation by two self-propelled microbots connected by polyester beam (bucklebot) in 25 seconds, which is not possible by an individual microbot.
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
- Trains LLMs of 7B and 70B with 1.8T tokens with AWS Trainium GPUs, showing 54% of cost compared with Nvidia GPU.
- Illustrates the approach for training LLMs using AWS Traininum GPUS and AWS Neuron SDK.
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
- CODA-LM: Vision-Language benchmark for autonomous driving.
- Identifies language agency bias in LLMs: gender, racial and intersectional.
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
- DB-GPT: Open-source AI app development framework. Includes: RAG, Generative Business Intelligence, Fine-tuning, Data-driven Multi-agents, Data factory and Data sources, Text-to-SQL module and agents. AWEL: Agentic Workflow Expression Language.
Bootstrapping Linear Models for Fast Online Adaptation in Human-Agent Collaboration
- BLR-HAC (Bootstrapped Logistic Regression for Human Agent Collaboration): pretrains transformer to generate parameters of a shallow parametrized policy. Update it using human-agent collaboration with online logistic regression.
What is Meant by AGI? On the Definition of Artificial General Intelligence
- Attempts to define AGI: "An Artificial General Intelligence (AGI) system is a computer that is adaptive to the open environment with limited computational resources and that satisfies certain principles."
Private Attribute Inference from Images with Vision-Language Models
- VLMs identify personal attributes of the image owners, which may cause privacy risk when misused.
CoTAR: Chain-of-Thought Attribution Reasoning with Multi-level Granularity
- CoTAR (Attribute-oriented CoT): Identifies most crucial aspects of the given context to answer using direct citations to referenced parts.
- Three levels: Span guidance, Sentence guidance, Passage guidance
Chinchilla Scaling: A replication attempt
- Finds Chinchilla-scaling laws inconsistent.
TEL'M: Test and Evaluation of Language Models
- TEL’M (Test and Evaluation of Language Models): five evaluations Identification of interesting LLM tasks, Identification of Task properties of interest, Identification of task property metrics, Design of measurement experiments, Execution and analysis of experiments.
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
- Reduces bias in LLMs by stating the views are not LLMs own ones, which activates LLMs internal attention to improve sensitivity.
Model-based Offline Quantum Reinforcement Learning
- First model-based offline quantum RL algorithm
AIGeN: An Adversarial Approach for Instruction Generation in VLN
- AUGeN: consists of Instructor generator and Instruction discriminator.
- Instruction generator describes actions needed to navigate to a specific location based on images from the environment.
- Instruction discriminator matches images as real/fake in case image descriptions match with the instruction provided).
Language Model Cascades: Token-level uncertainty and beyond
- Cascading LLM: simple queries are guided to "easy"-LLM, while complicated queries are guided to "hard"-LLM. This deferral decision is made by 5-layer MLP model.
- Applies token-level uncertainty, where length bias is mitigated when making deferral decision. Easy sequence have most tokens in low percentile, while hard sequences have some tokens with high uncertainty.
EyeFormer: Predicting Personalized Scanpaths with Transformer-Guided Reinforcement Learning
- EyeFormer: predictive model for scanpath (human vision attention behaviour) for both natural scenes and user interfaces. Illustrates using of scanpaths for personalized UI optimization.
- Deep RL with Transformer, which predicts spatial and temporal characteristics of scanpaths about viewer behaviours.
How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs' internal prior
- The LLM is less likely to trust retrieved information with RAG, the more likely the LLM is to trust its response without the RAG (Prior).
- The LLM is more likely to stick to Prior (knowledge), the more unrealistic the RAG pertubated information is.
Vision-and-Language Navigation via Causal Learning
Uncovering Latent Arguments in Social Media Messaging by Employing LLMs-in-the-Loop Strategy
HelixFold-Multimer: Elevating Protein Complex Structure Prediction to New Heights
Continuous Control Reinforcement Learning: Distributed Distributional DrQ Algorithms
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Future Language Modeling from Temporal Document History
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
SparseDM: Toward Sparse Efficient Diffusion Models
When Emotional Stimuli meet Prompt Designing: An Auto-Prompt Graphical Paradigm
Self-Supervised Visual Preference Alignment
Unveiling the Misuse Potential of Base Large Language Models via In-Context Learning
Generative Text Steganography with Large Language Model
EMC$^2$: Efficient MCMC Negative Sampling for Contrastive Learning with Global Convergence
Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Question Difficulty Ranking for Multiple-Choice Reading Comprehension
Insight Gained from Migrating a Machine Learning Model to Intelligence Processing Units
MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents
LegalPro-BERT: Classification of Legal Provisions by fine-tuning BERT Large Language Model
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Automating REST API Postman Test Cases Using LLM
MEEL: Multi-Modal Event Evolution Learning
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Memory Sharing for Large Language Model based Agents
- Memory-Sharing (MS)-framework: Multi LLM-agents share Memory Pool of query/response pairs, which improves In-Context Learning. Retriever-model is trained to retrieve memories based on user query.
- LLM agent answers based on query and retrieved memories. Scorer evaluates query / response. High scoring pairs are added to the Memory Pool, which is queried with cosine similarity.
- The shared memory helps all agents to learn from each other.
- The Retriever model is trained using pre-trained sentence similarity model, which retrieves data from jsonl-file to train a model and it is later used to pick relevant memories for each user query.
Reimagining Self-Adaptation in the Age of Large Language Models
- Self-Adaptive SW system: Includes Managed system (operational SW system) and Managing System (handles adaptions).
- Managing system includes Prompt generator, LLM engine, Response parser, Monitor (logs, metrics), Knowledge/Memory (conversation history, fine-tuned models, system config and system prompts) and Execute (verifier/executor).
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
ChatShop: Interactive Information Seeking with Language Agents
TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Table Decomposition
LLMorpheus: Mutation Testing using Large Language Models
A Survey on Deep Learning for Theorem Proving
Progressive Knowledge Graph Completion
Synergising Human-like Responses and Machine Intelligence for Planning in Disaster Response
HyperMono: A Monotonicity-aware Approach to Hyper-Relational Knowledge Representation
Action Model Learning with Guarantees
Explainable Generative AI (GenXAI): A Survey, Conceptualization, and Research Agenda
Monte Carlo Search Algorithms Discovering Monte Carlo Tree Search Exploration Terms
Handling Reward Misspecification in the Presence of Expectation Mismatch
Generating Games via LLMs: An Investigation with Video Game Description Language
MMInA: Benchmarking Multihop Multimodal Internet Agents
Evolving Interpretable Visual Classifiers with Large Language Models
Evolving Interpretable Visual Classifiers with Large Language Models
Compression Represents Intelligence Linearly
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Is Table Retrieval a Solved Problem? Join-Aware Multi-Table Retrieval
Empowering Embodied Visual Tracking with Visual Foundation Models and Offline RL
Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video
KG-CTG: Citation Generation through Knowledge Graph-guided Large Language Models
Effective Reinforcement Learning Based on Structural Information Principles
Unveiling Imitation Learning: Exploring the Impact of Data Falsity to Large Language Model
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Are Large Language Models Reliable Argument Quality Annotators?
Harnessing GPT-4V(ision) for Insurance: A Preliminary Exploration
Multi-News+: Cost-efficient Dataset Cleansing via LLM-based Data Annotation
All-in-one simulation-based inference
Efficient and accurate neural field reconstruction using resistive memory
A Self-feedback Knowledge Elicitation Approach for Chemical Reaction Predictions
Building Semantic Communication System via Molecules: An End-to-End Training Approach
σ-GPTs: A New Approach to Autoregressive Models
Characterization and Mitigation of Insufficiencies in Automated Driving Systems
Inferring Behavior-Specific Context Improves Zero-Shot Generalization in Reinforcement Learning
State Space Model for New-Generation Network Alternative to Transformers: A Survey
PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AI
Exploring Text-to-Motion Generation with Human Preference
RankCLIP: Ranking-Consistent Language-Image Pretraining
Self-Selected Attention Span for Accelerating Large Language Model Inference
- Fine-tunes LLM to self-identify minimal attention span in each step of the task.
- Speeds up inference 28% by dynamically adjusting self-attention.
- Allows LLMs to autonoumsly optimize computation.
TransformerFAM: Feedback attention is working memory
- Unlimited context window
Interactive Generative AI Agents for Satellite Networks through a Mixture of Experts Transmission
Confidence Calibration and Rationalization for LLMs via Multi-Agent Deliberation
LLeMpower: Understanding Disparities in the Control and Access of Large Language Models
Towards Practical Tool Usage for Continually Learning LLMs
Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment
TrafficVLM: A Controllable Visual Language Model for Traffic Video Captioning
Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
Towards Fast Inference: Exploring and Improving Blockwise Parallel Drafts
TextHawk: Exploring Efficient Fine-Grained Perception of Multimodal Large Language Models
Survey on Embedding Models for Knowledge Graph and its Applications
Fusion-Mamba for Cross-modality Object Detection
ToNER: Type-oriented Named Entity Recognition with Generative Language Model
Provable Interactive Learning with Hindsight Instruction Feedback
Semantic In-Domain Product Identification for Search Queries
LLMSat: A Large Language Model-Based Goal-Oriented Agent for Autonomous Space Exploration
- LLMSat: LLM-based spacecraft control and space missions.
When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models
Generative AI Agent for Next-Generation MIMO Design: Fundamentals, Challenges, and Vision
CuriousLLM: Elevating Multi-Document QA with Reasoning-Infused Knowledge Graph Prompting
CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Exploring Explainability in Video Action Recognition
Smart Help: Strategic Opponent Modeling for Proactive and Adaptive Robot Assistance in Households
Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Understanding Multimodal Deep Neural Networks: A Concept Selection View
EIVEN: Efficient Implicit Attribute Value Extraction using Multimodal LLM
An evaluation framework for synthetic data generation models
On Speculative Decoding for Multimodal Large Language Models
Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
- Megalodon: Inlimited contrxt length
Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
Aligning LLMs for FL-free Program Repair
LLM In-Context Recall is Prompt Dependent
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery
Augmenting Knowledge Graph Hierarchies Using Neural Transformers
LLM Agents can Autonomously Exploit One-day Vulnerabilities
Memory Traces: Are Transformers Tulving Machines?
Inverse Kinematics for Neuro-Robotic Grasping with Humanoid Embodied Agents
Training a Vision Language Model as Smartphone Assistant
Apollonion: Profile-centric Dialog Agent
Strategic Interactions between Large Language Models-based Agents in Beauty Contests
Toward a Theory of Tokenization in LLMs
Rho-1: Not All Tokens Are What You Need
- Rho-1: trains LLM with Selective Language Modelling (SLM) with useful tokens (based on loss pattern).
- The SLM calculates each token loss using reference model and then selectively removes loss of the unwanted tokens.
- Rho-1 1B and 7B achieve SOTA results at their size.
Large Language Model Can Continue Evolving From Mistakes
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
- OSWorld: scalable multimodal agents for Ubuntu/Windows/MacOS to perform open-ended web/desktop tasks.
- Discovers humans complete 72% of tasks, while best agent completes only 12%. The main issues are GUI grounding/operational knowledge.
ODA: Observation-Driven Agent for integrating LLMs and Knowledge Graphs
- ODA: LLM with knowledge graph (KGs) using iteratively observation, action and reflection to help solve tasks.
- The observation phase uses a global view of the entire KG and selectively picks relevant parts for reasoning.
- DesignQA-benchmark: Measures VLMs capcity to solve engineering tasks, including CAD images, drawings and engineering requirements. Includes: rule comprehension, rule compliance and rule extraction.
Monte Carlo Tree Search with Boltzmann Exploration
- Boltzmann Tree Search (BTS): replace soft values with Bellman values in MENTS.
- Decaying ENtropy Tree Search (DETS): Interpolates between BTS and MENTS.
- Alias method samples actions fast and demonstrate high performance in game of Go.
WESE: Weak Exploration to Strong Exploitation for LLM Agents
Behavior Trees Enable Structured Programming of Language Model Agents
LLoCO: Learning Long Contexts Offline
ChatGPT Can Predict the Future when it Tells Stories Set in the Future About the Past
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
--
Accelerating Inference in Large Language Models with a Unified Layer Skipping Strategy
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
- Infinite-Attention: Infinite long context window using compressed memory/local attention.
- The local attention computes using the in context. The compressed memory computes using the out-of-context.
- Google tests 1B LLN for 1M sequence length, which is difficult for such small model. I believe there are no existing benchmarks yet for testing such long context windows above +1M context window.
- Ahieves 114x compression ratio.
GoEX: Perspectives and Designs Towards a Runtime for Autonomous LLM Applications
- Gorilla Execution Engine (GoEx): open-source runtime to execute LLM actions, apps and microservices.
- LLMs evolve from dialogue to autonomous agents, which as well make decisions.
- "Post-facto Validation": human checks correctness of the generated output, instead of intermediate results. Introduces concet of "Undo" and "Damage confinement" to manage unintended risks with autonomous agents.
Vision-Language Model-based Physical Reasoning for Robot Liquid Perception
BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks
Measuring the Persuasiveness of Language Models
- Reviews the scaling of LLMs on persuasion tasks. Finds, that Claude 3 Opus is statistically as convincing as human.
Can Feedback Enhance Semantic Grounding in Large Vision-Language Models?
Large Language Models to the Rescue: Deadlock Resolution in Multi-Robot Systems
- Hierarchical LLM guides robot away from deadlock situation by assigning leader-agent and give it direction to continue and GNN executes the low level policy.
- Finds LLMs effective in various environments for high-level planning tonresolve deadlocks.
AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents
- AgentQuest: modular benchmark for multi-step reasoning with possibility via API to extend to different environments.
- Traditional benchmark includes single environment. AgentQuest uses driver to connect with a specific environment.
AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning
- AgentsCoDriver: multi-car collaboration using LLMs.
- The system includes the following modules: observation, reasoning engine, cognitive memory, reinforcement reflection, and communication.
- Includes useful designs on prompt generation and module designs.
Autonomous Evaluation and Refinement of Digital Agents
- Review domain-generic automatic evaluators to improve "digital agents", which improve SOTA performance in WebArena-benchmark by 29%.
- Evaluators are applied to improve agents with fine-tuning and inference-time guidance.
- Policy evaluation works by using VLM to perform user screen captioning, which is processed by LLM together with user instructions and agent trajectory(states/actions). The LLM-reasoner response is evaluated together with VLM-based reasoner to provide final failure/success-evaluation.
- Autonomous refinement uses inference-time guidance (reflexion) and Filtered behaviour cloning.
- Combines Wu's method with AlphaGeometry to solve 27/30 IMO geometry problems (SOTA-level), which is 2 above AlphaGeometry alone or Wu's method alone only solves 15.
- First AI (fully symbolic baseline) to outperform a human in IMO geometry problems.
Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective
Text-Based Reasoning About Vector Graphics
Sandwich attack: Multi-language Mixture Adaptive Attack on LLMs
pfl-research: simulation framework for accelerating research in Private Federated Learning
MuPT: A Generative Symbolic Music Pretrained Transformer
VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs
WESE: Weak Exploration to Strong Exploitation for LLM Agents
ActNetFormer: Transformer-ResNet Hybrid Method for Semi-Supervised Action Recognition in Videos
Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
Open-Source AI-based SE Tools: Opportunities and Challenges of Collaborative Software Learning
THOUGHTSCULPT: Reasoning with Intermediate Revision and Search
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
HAMMR: HierArchical MultiModal React agents for generic VQA
- HAMMR: Uses multimodal ReAct-based agent, which is hierarchical by letting the agent call other specialized agents.
- Outperforms PaLI-X VQA by 5%.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
- Ferret-UI: Outperforms GPT-4V on elementary UI-tasks with capability for referring (widget classification, OCR, icon recognition), grounding (find widget/icon/text and widget listing) and reasoning.
- "Any resolution" (anyres) enlarges small UI-objects in images like icons within varying screen aspect ratios. Screen capture is divided into two sub-sections. Each UI-element is referenced with type, text and bounding box. Uses 250k examples of training data.
AutoCodeRover: Autonomous Program Improvement
- AutoCodeRover: autonomous sw engineering by solve Github issues (program repair and improvement). Solves 67 Github issues within 10 minutes. Future directions could include issue reproducer/semantic artifacts and human involvement.
- Includes two stages: context retrieval stage to produce buggy locations and Patch generation stage to produce final patch.
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
- Presents 12 insights on LLM training duration model architecture, quantization, sparsity and data signal-to-noise ratio.
- Finds junk data significantly reduces model capacity, which can be avoided to large extent by adding special token in the beginning of text. LLM learns to autonomously label data as high-quality.
360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System
- Reusable Experience Accumulation with 360° Assessment (360°REA): a hierarchical multi-agent framework to evaluate and accumulate experience from feedback.
- Uses Deal-experience pool and 360◦ performance assessment.
- Dual-experience pool: helps LLM-agents collect useful experiences in complex tasks using local experience/high-level experience.
- Identifies Task Vectors.
- Uses task vectors to perform different tasks without any sample input.
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
[Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics](Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics)
AI2Apps: A Visual IDE for Building LLM-based AI Agent Applications
LLM-Based Multi-Agent Systems for Software Engineering: Vision and the Road Ahead
StockGPT: A GenAI Model for Stock Prediction and Trading
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Self-organizing Multiagent Target Enclosing under Limited Information and Safety Guarantees
Challenges Faced by Large Language Models in Solving Multi-Agent Flocking
Autonomous Artificial Intelligence Agents for Clinical Decision Making in Oncology
Do We Really Need a Complex Agent System? Distill Embodied Agent into a Single Model
The Case for Developing a Foundation Model for Planning-like Tasks from Scratch
MACM: Utilizing a Multi-Agent System for Condition Mining in Solving Complex Mathematical Problems
Goal-guided Generative Prompt Injection Attack on Large Language Models
Exploring Autonomous Agents through the Lens of Large Language Models: A Review
Increased LLM Vulnerabilities from Fine-tuning and Quantization
Hypothesis Generation with Large Language Models
KGExplainer: Towards Exploring Connected Subgraph Explanations for Knowledge Graph Completion
AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
- AutoWebGLM: automated browsing agent using ChatGLM3-6B LLM. Uses html simplification algorithm.
- Curriculum learning applies hybrid (human/AI) web browsing multi/single-step dataset(Data is collected with: match rules, Prompt LLM, Manual annotation and Solver and data is collected from real world/virtual environment and open source data.). RL/Rejection sampling fine tuning (RFT) is applied for browsing comphrehension and task decomposition.
- Introduces AutoWebBench-benchmark on real world web browsing tasks.
- Tools read DOM and webpage screenshot: Element filter, Element list, OCR module, HTML parse. Observation includes: instruction, HTML and previous action. Action includes: HTML section and action name.
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
- Visualization-ofThought
Language Model Evolution: An Iterated Learning Perspective
CONFLARE: CONFormal LArge language model REtrieval
SELF-[IN]CORRECT: LLMs Struggle with Refining Self-Generated Responses
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
Comprehensible Artificial Intelligence on Knowledge Graphs: A survey
Benchmarking ChatGPT on Algorithmic Reasoning
ReFT: Representation Finetuning for Language Models
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
A Cause-Effect Look at Alleviating Hallucination of Knowledge-grounded Dialogue Generation
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
MIMIR: A Streamlined Platform for Personalized Agent Tuning in Domain Expertise
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game
Designing for Human-Agent Alignment: Understanding what humans want from their agents
PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
Testing the Effect of Code Documentation on Large Language Model Code Understanding
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Measuring Social Norms of Large Language Models
Exploring Backdoor Vulnerabilities of Chat Models
[Mixture-of-Depths: Dynamically allocating compute in transformer-based language models](Mixture-of-Depths: Dynamically allocating compute in transformer-based language models)
- Mixture-of-Depth (MoD) Transformer: Transformers learn to assign compute dynamically to specific spots in the sequence.
- Top-k routing: defines tokens participating in block's computation. Learns to route harder tokens through more layers.
- Helps to speed up
A Survey on Large Language Model-Based Game Agents
- Survey about LLM-based Game agents.
- Unified architecture of LLMGAs: Perception(text, image, state, etc.), Thinking(reasoning, reflection, planning), Memory, Role-playing (role, experience, emotion), Action-module (control, dialogue, API, etc.) and Learning module.
Advancing LLM Reasoning Generalists with Preference Trees
- Eurus: LLMs optimized for reasoning. Trains reward model using UltraInteract-dataset, which consists of Preference Trees.
- Preference Tree: Diverse planning strategies in single pattern (such as tool creation, sequential processing). Multi-turn interaction trajectories with environment and the critique (learn to apply feedback and correct prior errors). Paired correct and incorrect actions in a tree structure. The data pair includes: instruction, correct response and incorrect response.
- DPO (instruction fine-tuned) hurts performance, while KTO and NCA improve performance. Indicates, that DPO may be less suitable for reasoning tasks.
- SoA (Self-Organized multi-Agent framework): Self-organized LLMs collaborate to generate code base and dynamically multiple based on complexity. Uses Mother and Child-agents.
- Helps to scale the SoA to longer context lengths of code generation.
Large Language Models for Orchestrating Bimanual Robots
- LABOR (LAnguage-modelbased Bimanual ORchestration)-agent.
CMAT: A Multi-Agent Collaboration Tuning Framework for Enhancing Small Language Models
Collapse of Self-trained Language Models
RAT: Retrieval-Augmented Transformer for Click-Through Rate Prediction
Stream of Search (SoS): Learning to Search in Language
- Stream of Search (SoS): Symbolic reasoning with next-sequence prediction (LLMs).
- LLM pretrained with SoS-dataset generated with 500k search trajectories (also called as SoS) using various search strategies (BFS/DFS-based) to learn internal world model of search, which include problem solving using exploration and backtracking.
- Enables generic and adaptive form of search: symbolic search is based on explicity environmental model, while SoS learns state transitions. The approach is likely to work in real world due to the complex/variable/branching nature of the game.
- The policy is improved using APA (Advantage-induces Policy Alignment)- and fine-tuning with STaR-technique for threee iterations using 100k correct trajectories.
- APA is a Actor-Critic RL technique. It creates copy of the LLM used as value network to enhance policy in the LLM. Reward function reviews the length and correctness of the generated trajectory.
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
- Survey about Strategic reasoning of LLMs: methodologies and metrics. These approaches are categorizied into: Prompt engineering, Modular enhancements, Theory of Mind and Fine-tuning.
- Reasoning tasks include: Common Sense reasoning, Mathematical reasoning, Symbolic reasoning, Causal reasoning and Strategic reasoning.
- Strategic reasoning differs from being a more dynamic form of reasoning with the environment and due to the uncertainty of the adversary action.
- Key traits of strategic reasoning are: Goal-oriented, Interactive, Predictive nature and Adaptability.
Large Language Model Evaluation Via Multi AI Agents: Preliminary results
CHOPS: CHat with custOmer Profile Systems for Customer Service with LLMs
Algorithmic Collusion by Large Language Models
"My agent understands me better": Integrating Dynamic Human-like Memory Recall and Consolidation in LLM-Based Agents
- Aligns LLM word embeddings with human brain embeddings.
- Brain embeddings are generated from fine-grained spatiotemporal neural recordings in a continuous embedding space.
- Aligning is based on similar geometric shapes between brain and llm word embeddings.
Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Language Models are Spacecraft Operators
A Taxonomy for Human-LLM Interaction Modes: An Initial Exploration
Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
Your Co-Workers Matter: Evaluating Collaborative Capabilities of Language Models in Blocks World
Gecko: Versatile Text Embeddings Distilled from Large Language Models
- Gecko: "SOTA level" text embeddings with 768-dimensions with 7x smaller embedding model compared to prior SOTA. Gecko embeddings with 256 dimensions all existting 768-dimension text embeddings in MTEB
- Gecko uses FRet (Few-shot Prompted Retrieval dataset)-fine tuning dataset: task description, input query, positive passage, negative passage.
- FRet generates with LLM the relevant task and query for a passage. The query and task are fed into a pre-trained embedding model to get neighbor passages. LLM scores them either as positive or negative passages.
- Original passage may not become relevant positive/negative passage.
- I think the overall idea could work even as prompt-engineering technique, where original passage is sent to LLM to define query/task, generate positive/negative passage and finally use the query, task, positive, negative passage as basis of retrieval.
ITCMA: A Generative Agent Based on a Computational Consciousness Structure
- ITCMA (Internal Time-Consciousness Machine): an an architecture for generative agents called ITCMA-agent. It is"a computational consciousness structure" and good at utility and generalization to real world.
- ITCMA framework includes LLM, VLM, Agents under consciousness channels (composed of retention, primal impression and protention each next time step further) and Memory.
- Slowness is a downside.
- Explores open source 7B/13B LLMs ability to perform agentic tasks through supervised fine-tuning with task decomposition/backtracking (multipath reflective reasoning by prompting LLM to reflect path as not optiomal ) data.
- Agent dataset is contructed through: task construction, trajectory interaction and manual filtering. Includes two usage types: task planning and tool usage.
- Task planning data is generated the following way. LLM is used in three roles: question generator, action maker (offers thoughts/actions based on environmental feedback) and environmental agent. Action maker/Environmental agent keep interacting until task is completed. Requires manual screening after data is generated to ensure task logical consistency.
- Tool usage data is generated by manually filtering LLM examples of full reasoning trajectories.
STaR-GATE: Teaching Language Models to Ask Clarifying Questions
- STaR(Self-Taught Reasoner)-GATE (Generative Active Task Elicitation)-algorithm: Self-improves LLM's ability to elicit user preference by generating questions and generalises beyond the trained role-player.
- Fine tunes LLM by generating a synthetic dataset for math problem dialogues with persona-task prompts.
- Teaches the LLM to ask clarifying questions to provide personalised responses.
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
- MatEval: LLM agents emulate human collaboration discussion. Uses self-reflection, CoT and feedback mechnamism.
- Achieves high-correlation with human evaluation. Includes evaluator-, feedback(to imrpove discussion)- and summarizer-agents.
- Change-Agent: Change deteection and interpretation using LLM from earth surface changes.
Change-Agent: Towards Interactive Comprehensive Remote Sensing Change Interpretation and Analysis
LLMs as Academic Reading Companions: Extending HCI Through Synthetic Personae
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Long-form factuality in large language models
- Search-Augmented Factuality Evaluator (SAFE): long-form factual check with LLM agent using a 38 topic question set (LongFast). Uses multi-step reasoning and determines, if factuality is supported by google search results.
- LLM generates answer to question, this answer is splitted into individual facts. The facts are converted into self-contained, so the fact can be understood without rest of the facts. The individual facts are retrieved with google search: Facts supported by search results are labelled as supported and rest as non supported. If the fact is not relevant to the question, then the fact is labelled as irrelevant.
- Achieves super-human level performance and measures this with a F1-score.
What are human values, and how do we align AI to them?
- MEOW (MOsaic Expert Observation Wall): improves LLM reasoning with behaviour simulation.
- Expert model is trained with simulated data from experience of specific task. Tested in communication game.
- Reviews the concept of legal autonomy of LLM agents for the first time: extracting, loading and transforming computing legal information.
- Reviews automated agents in social networks for opinion control: opinion inference engine with LLM, content generation using opinion vectors.
MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue Resolution
- MAGIS: Resolves Github issues with multi-agent LLMs: Manager, Repository Custodian, Developer and Quality Assurance engineer.
- SecurityBot: role-based multiagent collaborative framework with RL agent as mentors for LLM agent to support cybersecurity operations. Includes modules: profiles, memory, reflection and action using LLMs.
- Collaboration mechanism: cursor for dynamic suggestions taking, aggregator for multiple mentors suggestion ranking & caller for proactive suggestion asking.
Large Language Models Need Consultants for Reasoning: Becoming an Expert in a Complex Human System Through Behavior Simulation
Depending on yourself when you should: Mentoring LLM with RL agents to become the master in cybersecurity games
Compressed Federated Reinforcement Learning with a Generative Model
AIOS: LLM Agent Operating System
- AIOS-architecture ofr LLM agent OS: AIOS SDK, LLM Kernel (Kernel layer), OS Kernel, Agent applications (Application layer), HW layer.
- LLM kernel: Agent scheduler, Context manager, Memory manager, Storage manager, Tool manager and Access manager.
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
- RepairAgent: Automated program repair with LLMs with dynamically updated prompt format.
CYGENT: A cybersecurity conversational agent with log summarization powered by GPT-3
- CYGENT: Fine-tunes LLM for cybersecurity tasks and LLM agent provides/analyzes/summarizes user information from log files, detected events
TwoStep: Multi-agent Task Planning using Classical Planners and Large Language Models
- TwoStep: Combines classical planning with LLMs (Helper Plan and Main Plan).
Temporal and Semantic Evaluation Metrics for Foundation Models in Post-Hoc Analysis of Robotic Sub-tasks
Do LLM Agents Have Regret? A Case Study in Online Learning and Games
An LLM-Based Digital Twin for Optimizing Human-in-the Loop Systems
Harnessing the power of LLMs for normative reasoning in MASs
Norm Violation Detection in Multi-Agent Systems using Large Language Models: A Pilot Study
Towards Automatic Evaluation for LLMs' Clinical Capabilities: Metric, Data, and Algorithm
Re2LLM: Reflective Reinforcement Large Language Model for Session-based Recommendation
RL for Consistency Models: Faster Reward Guided Text-to-Image Generation
Combining Fine-Tuning and LLM-based Agents for Intuitive Smart Contract Auditing with Justifications
When LLM-based Code Generation Meets the Software Development Process
- LCG: Multi-agent LLM consisting of waterfall, scrum and Test-Driven-Development sw development workflows with CoT and Self-refinement.
- LLM agent includes roles: requirements engineer, architect, developer, tester and scrum master. Uses same prompt, with role-identifier, role-specific instruction and task-information to drive dynamic prompting.
Towards a RAG-based Summarization Agent for the Electron-Ion Collider
EduAgent: Generative Student Agents in Learning
Can large language models explore in-context?
- Reviews, if LLMs can explore effectively in-context, similar to Reinforcement learning-like agents.
- Suggest need for external summarization, larger models like GPT-4 and careful prompt engineering.
CoLLEGe: Concept Embedding Generation for Large Language Models
- CoLLEGe (Concept Learning with Language Embedding Generation): few-shot learning for new-concept acquisition and knowledge augmentation for LLMs.
- Generates concept embedding with CoLLEGe based on two example sentences, where the concept is used, creates a definition-sentence using this concept-embedding and asks LLM to generate the definition of the concept.
LLM-Driven Agents for Influencer Selection in Digital Advertising Campaigns
- Influencer Dynamics Simulator (IDS): LLM-agent based influencer selection for digital ad campaigns.
- Includes: Influencer pre-selection, user profile generation, follower behaviour prediction and influencer tracking.
Language Models in Dialogue: Conversational Maxims for Human-AI Interactions
- Proposes principles for effective human-AI conversation: quantity, quality, relevance and manner, benevolence and transparency.
CACA Agent: Capability Collaboration based AI Agent
- CACA (Capability Collaboration based AI Agent): LLM agent with the following components: profile capability, reception capability, workflow capability, tool capability, tool service, methodology capability, add domain knowledge and planning capability.
- Processes: user request, generate plan, search methodology, get profile, discover tool, invoke service, add domain knowledge and register tool service.
Content Knowledge Identification with Multi-Agent Large Language Models (LLMs)
ReAct Meets ActRe: Autonomous Annotations of Agent Trajectories for Contrastive Self-Training
- A^3T (Autonomous Annotation Agent Trajectories): Closed-loop self-improvement for LLM agents.
- Autonomous annotation of agent trajectories with ReAct for contrastive self-training. Reduces human-effort of data-collection.
- Agent reasons for actions taken (ActRe-prompting agent).Contrastive self-training uses rewards decisions made based on accumulated successful trajectoriess.
- The model outperforms GPT-4 and matches human average in Webshop-benchmark
ERD: A Framework for Improving LLM Reasoning for Cognitive Distortion Classification
- ERD: Three step approach to reason cognitive distortions of user input: extraction, reasoning (CoT, Diagnosis of Thought) and debate between two LLM-agents and one LLM-judge.
- PeerGPT: pedagogical agents in Children collaborative learning with peer agent as team moderator or peer agent as a participant.
RoleInteract: Evaluating the Social Interaction of Role-Playing Agents
- RoleInteract-benchmark: Measures Sociality skills of role-playing LLM-agents. Conversation memory is one aspect to improve conversational agents. Complex group dynamics are still hard.
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
- Polaris: 1T parameter LLM as a co-operative agent for patient friendly conversation with multiple specialist agents like nurses/social workers/nutritionists. Uses iterative co-training to optmize diverse objectives. Uses healthcare-related data, including propietary data.
- Performs on par with human nurses and outperform significantly GPT-4.
Reverse Training to Nurse the Reversal Curse
- Reverse training: trains LLMs using reverse order to solve the reverse curse, where the LLM struggles to learn: B is a feature of A.
- Reverse curse has been key issue in the current LLM training.
Large Language Models meet Network Slicing Management and Orchestration
- LLM slices isolated virtual network of a Physical infrastructure.
Mapping LLM Security Landscapes: A Comprehensive Stakeholder Risk Assessment Proposal
- Traditional risk assessment framework for LLMs through 10 categories: prompt injection, insecure plugin design, training data poisoning, model denial of service, supply chain vulnerabilities, sensitive information disclosure, insecure output handling, excessive agency, overreliance and model theft.
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
- Agent-FLAN (Finetuned LANguage models for aents): finetuning for agentic tasks.
- Llama-2 7B model with Agent-FLAN surpasses by 3.5% existing SOTA models. Works both for tool utilization and agentic tasks.
- Observes: LLMs overfit to specific agentic task formats like JSON, Learning speed of LLMs vary for agentic tasks and current training methods introduce hallucinations.
HYDRA: A Hyper Agent for Dynamic Compositional Visual Reasoning
- HYDRA (HYper Dynamic Reasoning Agent): multi-stage dynamic compositional visual reasoning, to make hyper-decisions (fast, strategic and efficient decisions).
- Three modules: LLM-Planner, RL agent (controller) and LLM-Reasoner (includes code generator and code executor). Includes Memory (code-, instruction- and feedback-history) and LLM-Textualizer (Uses template to create summary).
- Planner and Reasoner generate instructions/Code with LLM. RL agent interacts with these modules and makes high-level decisions from best instructions based history. HYDRA adjusts actions from feedback received in reasoning. User queries are deconstructed with three sub-questions processed concurrently. The code executor has access to vision foundational models like BLIP, XVLM and GLIP.
- RL agent is based on DQN-algorithm.
Characteristic AI Agents via Large Language Models
- Characteristics AI: simulates real-life individuals in different situations. Releases Character100-dataset.
Embodied LLM Agents Learn to Cooperate in Organized Teams
- Introduces prompt-based orgnizational structure. Reduces LLM errors related to redundant information and complying any instruction. Includesc communication- and action phases. Criticize-Reflect architecture.
Contextual Moral Value Alignment Through Context-Based Aggregation
- CMVA-GS: moral value agents with different profiles pass through contextual aggregator.
The Use of Generative Search Engines for Knowledge Work and Complex Tasks
- Dual-modality frameworkk: leverages independent LLM/VLM/SR models in order to interact autonomous robots.
- Includes components of visual understanding, LLM and Speech regognition.
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
- EnvGen-framework: Use LLM-agent creates training environment for reasoning, so smaller embodied RL-agents improve their weak skills.
- Benefits from the LLM-agents world knowledge and the small, yet capable RL agents.
- Chart understanding task (chart Q&A, captioning, fact-checking, -to-table conversion, factual error correction).
Agent3D-Zero: An Agent for Zero-shot 3D Understanding
- Agent3D-Zero: 3D scene understanding agent with VLM by selecting and analyzing series of viewpoints for 3D understanding.
DiPaCo: Distributed Path Composition
- DiPaCo (DIstributed PAth COmposition): a modlular ML paradigm, where computing is distributed by path. Path refers to sequence of modules defining input-output function.
- Paths are small in relation to the overall model. During both training and deployment, a query is routed to replica of a path (sparsely activated), not the entire model.
- The training phase distributes computation by paths through set of shared modules. The inference phase computes single path.
- First large-scale, more modular and less synchronous learning, when FLOPs are relatively cheap and communication is relatively expensive.
- Exceeds 1B parameter dense Transformer by choosing 256 possible paths with size of 150 million parameters.
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
- PERL (Parameter Efficient Reinforcement Learning): Compares reward modelling training and RL using LoRA against traditional RLHF. The study focuses on device UI control, such as sending email.
- PERL achieves similar level of performance with less training compute and less memory used.
- Releases self-dialogue: Taskmaster Coffee and Ticketing-datasets and still pending, but planned release of UI automation-dataset called "S-dataset". Unclear, if the NPOV-dataset apart is kept internal.
AUTONODE: A Neuro-Graphic Self-Learnable Engine for Cognitive GUI Automation
- AUTONODE (Autonomous User-Interface Transformation through Online Neuro-graphic Operations and Deep Exploration).
- Integrates Dora (Discovery and mapping Opertion for graph Retrieval Agents).
Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
- V-HOU Multi-LLMs Collaborated Reasoning: video scene understanding.
Can a GPT4-Powered AI Agent Be a Good Enough Performance Attribution Analyst?
- LLM agent for performance attrition using CoT and Plan and Solve (PS).
ChatPattern: Layout Pattern Customization via Natural Language
ExeGPT: Constraint-Aware Resource Scheduling for LLM Inference
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- Quiet-Star: Extension and generalization of STaR-paper. Improves significantly LLM performance on GSM8K-benchmark.
- Uses "meta-tokens" at the start/end of each thought, to learn when to generate a rationale and when it should make prediction-based on that rationale.
- Blockchain based Autonomous agent not only with explanation, but as well with record auditable interpretation.
- Components: Autonomous agent, blockchain, Non-expert users, Automatic evaluation, Explainability component and Asynchronous task.
VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
- Vision-GPT-3D: Multimodal agent optimizing 3d vision understanding by integrating: YOLO-, SAM- and DINO-models.
- Starts by making a depth map from multiple images, converts the depth map into point cloud, then into mesh and finally into a video.
From Skepticism to Acceptance: Simulating the Attitude Dynamics Toward Fake News
- Fake news Propagation Simulation (FPS)-framework: identifies LLMs usefulness of LLMs to combat fake news. Reviews trends and controls of fake news using multiple agents under different personas (age/name/education/personality traits) with both long/short-term memory and self-reflection. Early and frequent regulation of fake news helps to limit its propagation impact.
- Dynamic Opinion Agent (DOA) simulates cognitive processes of each agent. Agent Interaction Simulator (AIS) defines how/which agents interact daily and publishes new common knowledge/beliefs to agents.
LLM-based agents for automating the enhancement of user story quality: An early report
- ALAS (Autonomous LLM-based Agent System): LLM-based system between different agent profiles to develop and maintain high-quality IT user stories.
- Agent profiles: Product Owner/Requirements Engineer. User story. Task preparation phase: task, sub-tasks, context and vision statement. Task conduction-phase.
USimAgent: Large Language Models for Simulating Search Users
- USimAgent: generates search interaction sequence through multiple rounds, taking into account context generated in prior rounds, each with steps: reasoning/action, query generation and click behaviour.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
- MM1: MLLM training.
Gemma: Open Models Based on Gemini Research and Technology
Scaling Instructable Agents Across Many Simulated Worlds
- SIMA: The Scalable, Instructable, Multiworld Agent based on image from the screen and text instruction provided by user. SIMA agent uses text encoder, image encoder and video encoder to process the input image and text and output only the embodied action.
- Real-tme, embodied agent generalizes in 3D environment to any human task and coordinated by natural language instructions. Agent trained on multiple games outperformed an agent trained on single game. Performs nearly as well in new unseen game environments.
- Data collection from commercial video game environments, Training of SIMA Agent model with text instruction-actions and human evaluation.
SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
- SOTOPIA-π: LLMs with social intelligence engage, act safer and persuade more.
- Achieves social interaction goal completion capability of GPT-4 using 7B LLM.
- Starts by generating social tasks with each character with its own social goal. Continues by collecting this training data using behavioural cloning (expert signal) and self-reinforcement(strongly performing signals from itself). Improve the agent policy with the LLM ratings. Generate SOTOPIA tasks with characters and evaluate their interaction with LLM rating and human rating.
- AutoGuide: the LLM-agent receives task-information, in-context examples, current trajectory and "state-aware guidelines"-retrieval.
- The "State-aware retrieval" is in short a navigational instruction of the specific section in the web-page, such as clicking the "Forum"-button leads to page, where you can create a new Forum.
TINA: Think, Interaction, and Action Framework for Zero-Shot Vision Language Navigation
- TINA (Thinking, Interacting and Action)-framework: a zero-shot Vision-Language Navigation (VLN) based LLM-agent, visual perceptor making observations and a memory.
- Agent inputs include: Task description, Instuction and Memory. Trajectory memorizer summarizes observations/actions to memory.
- Systematic Literature Reviews (SLRs)-agent: planner, literature identification, data extraction, data compilation, performance validation. The code includes concrete prompts used with each step.
Hierarchical Auto-Organizing System for Open-Ended Multi-Agent Navigation
- HAS (Hierarchical Auto-organizing System): Auto-organizes LLM-agents to complete navigation tasks using dynamic maps and auto-organizing-mechanism.
- Centralized planning (planner, describer, critic and deployer) with global multi-modal memory, distributed execution (actor, curriculum, critic and skill) with local-multi-modal memory and multimodal information (vision, audio, object and map) with environment state.
Cultural evolution in populations of Large Language Models
- Models cultural evolution in LLM-agent population.
CleanAgent: Automating Data Standardization with LLM-based Agents
- CleanAgent: a data preparation LLM agent.
NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning
- NavCoT (Navigational CoT): LLM acts as a world model and a navigational reasoning agent.
- LLM is prompted to forecast the navigational NavCoT: 1. act as world model to imagine the next observation based on instruction, 2. select best aligned candidate observation fitting to the imagination, 3. determine action based on reasoning from prior steps.
- In the Future Imagination-step (FI), the LLM is prompted to imagine the next observation, such as seeing a Patio. Visual Information Filter (VIF) selects from the available options provided by the VLM (image and description of the action towards it), the best matching to the FI. Action Prediction (AP)-step generates action prediction based on the selected option.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
- Introduces two benchmarks WorkArena- and BrowserGym--benchmarks to evaluate LLM-agent interacting with software via browser.
- WorkArena (list, form, knowledge base, service catalog, menus) includes 23k tasks to interact with ServiceNow.
- BrowserGym designs and evaluates web agents in Python environment, which includes html content, raw pixels and acccessibility tree. and
- Illustrates clear difference in web browsing expertise between GPT-3.5 vs. GPT-4.
- Multiagent Data and AI based platform framework: data, playground, web app, embedding model, multiagent orchestration (rest of the components interact with), data security/privacy, APIs/plugins, LLM & cache, Cloud provider, cloud DBs, Data Ops, MLOps, LLMOps and data strategy/ethics/LLM governance. The paper offers very little apart from this list, but the list does include quiet many of the components.
DexCap: Scalable and Portable Mocap Data Collection System for Dexterous Manipulation
- DexCap: a hand motion data capture system.
AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production
- Aesop-agent: Multimodal content generation agent.
- Includes RAG from database(expert experience/professional knowledge), script generation, image generation, video assembly, utility layer.
- Reviews prompt optimization.
RecAI: Leveraging Large Language Models for Next-Generation Recommender Systems
- RecAI: Recommender systems based on LLMs, where user makes query, the LLM agent makes tool queries to get the correct items.
- Includes Profile memory, info query, item retrieval and item ranker.
- The LLM chain includes: init state, dynamic demo, plan execute and reflection.
- Refers to planning called Plan-First method, which creates comprehensive execution plan and then strictly follows this plan. The planning input includes: user input, context, tool descriptions and demonstrations for in-context learning to create tool utilization plan.
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
- DriveDreamer-2: First world model to generate customized driving videos, including uncommon scenes.
- LLM generates user-defined driving videos: LLM converts user request into agent based trajectories, which is used to generate HDMap (python script creates Bird Eye View (BEV)) with respecting traffic rules. Unified Multi-View Model (UniMVM) improve temporal and spatial coherence of the generated video.
Academically intelligent LLMs are not necessarily socially intelligent
- SESI (Situational Evaluation of Social Intelligence)-benchmark: Superficial friendliness is principal reason for errors.
- Reviews: Empathy, Social-cognition, self-presentation, influence and concern.
- Illustrates interesting insight about GPT-4 not being better in this benchmark than GPT-3.5 turbo and Mistral model outperforming Llama 2.
TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision
- TRAD: Thought Retrieval Aligned Decision.
- Includes three sub-processes: Temporal Expansion, Relative Order Mark and History Alignment.
- ArgMed-agent: Generator of the Argumentation Schema (AS), Verifier of the AS and Reasoner as symbolic solver.
Reframe Anything: LLM Agent for Open World Video Reframing
- RAVA (Reframe Any Video Agen): Perception to interpret user query and video content, Planning to determine aspect ratio/reframin strategies and Execution uses video editing tools to produce final video.
- Model caching optimization on edge devices. Age of Thought (AoT): to measure the relevance/coherence of intermediate thoughts during CoT inference.
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
- Retrieval Augmented Thoughts (RAT): Iterative revising CoTs with retrieval information, which improves LLM reasoning in long-horizon tasks and reduces hallucinations.
- First generates CoT answer, then uses this answers with a verification prompt. The verification prompt requests to verify correctness of the given answer to the question with the separately added information query, for example by using Bing/Google search (authors implement a separate get_content function in their Github code).
- The query is based on the draft answer. The retrieved information is used to revise the draft answer. The next thought is then appended and a new round of revision performed. The process is repeated, until all revised thoughts are obtained and the final answer is provided.
- The github code includes multiple functions to manage inputs and outputs for the LLMs.
FLAP: Flow Adhering Planning with Constrained Decoding in LLMs
- FLAP (Flow Adhering Planning): Static planning in task oriented dialogs using constrained decoding algorithm based on lookahead heuristics.
- The research is static planning, but the authors plan a follow up research with dynamic planning.
- Aligns suggested plan thoughts using three scale score regards: user intent alignment, permitted flow steps, API selected, API permitted and structrally correct.
- Doom-game agent, consisting Python-based Manager module connected to Doom code and three modules: Planner, Vision and Agent.
- Vision module (GPT-4V) receives screenshots from the Managers and provides text description of it. - Planner uses as input the walkthrough and history and outputs a granular plan to be executed. Uses k-level of experts.
Acceleron: A Tool to Accelerate Research Ideation
- Acceleron: LLM agent for research using colleague and mentor personas. Interacts with researcher develop research proposal.
- Introduces concept of "Unanswerability", when LLM should identify when all the retrieved paragraphs are irrelevant.
- PowerPoint Task Completion-Robustness (PPTC-R)-benchmark for LLMs PowerPoint completion tasks.
SheetAgent: A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models
- SheetAgent: LLM-agent to complete spreadsheet tasks by interacting through iterative task reasoning. Introduces SheetRM-benchmark.
- Includes three modules: Planner (generates python code to modify the spreadsheet), Informer (produces SQLs to perceive the spreadsheet despite dynamic range) and Retriever (retrieves instructive examples to improve robustness).
- Includes interesting concept of erroneous code-code repository as Milvus vector database, in order to perform cosine similarity search in case erroneous code.
Exploring LLM-based Agents for Root Cause Analysis
- Introduces LLM-based Root-Cause-Analysis (RCA) agent based on ReCT.
Cradle: Empowering Foundation Agents Towards General Computer Control
- Cradle-framework: introduces MLLM-agent to control GUI using screenshot inputs and outputs executable code to control keyboard/mouse actions(key or button to press/where/duration/speed/location to move). Introduces the term General Computer Control (GCC).
- Includes modules: information gathering/self-reflection/task inference/skill curator/action planning/memory(episodic for retaining information/procedural for skills).
- Uses PyDirectInput instead of pyautogui for keyboard control. Includes low-level wrapper, which uses ctypes in windows and AppleScript in Mac to communicate low-level mouse controls.
- Procedural memory is based on topk matches of the skills (text embeddings).
- Episodic memory consists of short-term (screenshots/task guidance actions/reasoningand long-term summary. Short-term memory includes forgetting factor k set to 5-interactions.
- The long-term memory includes recurrent information summary to avoid losing track of long-horozon task objective while inside short-horizon task: ongoing task/the past entities met/past behaviours.
Reaching Consensus in Cooperative Multi-Agent Reinforcement Learning with Goal Imagination
- MAGI (Multi-Agent Goal Imagination)-framework: agents reach consensus (and cooperatively reaching valuable future states) through imagined common goal.
- Future states are modeled with CVAE-based self-supervised generative modelling. Samples a common goal with high-potential value for multi-agent consensus to guide policies of all agents.
- CVAE is self-supervised conditional variational auto-encoder to model the distribution of future states.
Language Guided Exploration for RL Agents in Text Environments
- Introduces Language Guided Exploration (LGE), which in this study outperforms Behaviour Cloning.
- Explorer: RL agent with LGE outperforms with wide margin behaviour cloning. The key component is the Guide-model (LLM), which provides world knowledge to introduce set of feasible actions and reducing substantially the possible action space.
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
- KnowAgent: LLM-agent to improve planning with explicit action knowledge retrieval. The agent includes Action Knowledge Base (AKB), Planning Path Generation(question, action path, thought and observation) and Kowledgable Self-Learning.
- Introduces term planning hallucinations, which refers to agent generating conflicting or unnecessary action sequences.
- AKB contains information to steer action generation process: action name, definition, rule and knowledge.
- Knowledgable Self-Learning phase improves continuously the understanding and usage of action knowledge
Learning to Use Tools via Cooperative and Interactive Agents
- ConAgents: Cooperative and interactive agents, which iteratively applies three modules: Grounding, Execution and Observation.
- Grounding step grounds user query into too definition and target output. Executing defines required tool arguments and completes returned output. Observing addresses long-form data outputs with IterCal-method: LLM agent self-adapts to feedback from tool environment.
- IterCal-method uses a pseudo-schema, which is basically a simplifie human-readable dictionary of the lengthy output returned from the tool used, see the pseudo-schema in the last page of the paper for quick understanding.
OPEx: A Component-Wise Analysis of LLM-Centric Agents in Embodied Instruction Following
- OPEx-agent: Includes Observer, Planner and Executor-roles. Observer-agent processes and interprets sensory inputs, such as vision from the environment. Planner integrates dynamically strategic plans and sub-tasks based on perception. Excutor implements the plans with skills library.
- Embodied Instruction Following (EIF): agents follows task instruction by interacting with the environment through observations in a ego-centric way.
- The agent basically includes, what objects the agent is currently observing, what objects have been found, what observations have been so far made and what previous steps have been completed. In addition, there is known the current objective, thought and action.
Android in the Zoo: Chain-of-Action-Thought for GUI Agents
- Chain-of-Action-Thought (dubbed CoAT): a novel prompting strategy to allow GUI agents to perceive, reason and decide.
- CoAT includes four parts: Screen context, Action thinking, Action target and Action Result.
- Screen context explains content of the GUI screenshot. Action thinking takes user query, current screen and history to define possible actions to complete goal. Action target refers to GUI element being actioned such as clicking an icon. Action result maps current screen with next action to future observation.
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
- InjectAgent-benchmark with +1k test cases in 17 tools and 62 attacker tools. Illustrates. Attack Success Rate (ASR) remains high especially in open source models like Llama 2.
- This result is surprising, considering "open source" models are often categorized as safer options over closed models.
Entropy-Regularized Token-Level Policy Optimization for Large Language Models
- Entropy-Regularized Token-level Policy Optimization (ETPO).
ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary
- ChatCite: Literature summary LLM-agent. Includes Key-Element Extractor and Reflective Incremental Generator.
- Key-Element Extractor: Extracts research questions, methodology, results, conclusions, contributions, innovations and limitations. These are stored in memory.
- Reflective Incremental Generator: Reflective mechnanism, Comparative summarizer, Reflective Evaluator and Rank & Select. Iteratively repeated.
Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents
- Exploration-based Trajectory Optimization (ETO): LLM agent collects failure trajectories to update its policy using failure-success trajectories.
- ETO includes three steps: Explore (SFT-based behavioral cloning LLM agent), Collect Failures (pairs contrastive trajectories from the failures and expert trajectories) and Optimize trajectories (DPO loss on the pairs).
AutoDefense: Multi-Agent LLM Defense against Jailbreak Attacks
- AutoDefence: Introduces multi-agent LLM-jailbreaking prevention framework with input agent, defence agent and output agents.
- Defence agent includes prompt analyser agent, intention analyser agent, judge agent and coordinator agent.
- Reduces success rate of prompt attacks.
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code
- SceneCraft: LLM agent converts text into Python code for Blender API 3D-scenes.
- Dual-loop: Inner loop keeps improving scene by writing Blender code, Blender API renders the code and critic-revising this rendered image using Vision-Language Model (VLM).
- Outer loop learns by updating reusable functions to the library.
- The beaty of this approach is, that VLM model revising the end result, makes it very generich approach for self-improvement.
Playing NetHack with LLMs: Potential & Limitations as Zero-Shot Agents
- NetPlay: zero-shot agent, which uses agent loop using GPT-4.
- Constructs prompt including past events, the current observation, a task description with available skills and the desired output format. Retrieve new skill and Execute it. New events are then observed.
Human Simulacra: A Step toward the Personification of Large Language Models
- Creates LLM personification with complete life story to simulate personality and interacting with external world in human-like manner
- Uses multi-agent framework to simulate cognitive functions, memory and psychology-guided evaluation to asses the quality of the human simulation with self-reporting and external observations.
Prospect Personalized Recommendation on Large Language Model-based Agent Platform
- Rec4Agentverse: Recommender agent with three steps: User-Agent Interaction, Agent-Recommender, Agents Collaboration.
Data Interpreter: An LLM Agent For Data Science
- Data Interpreter: Data scientist LLM agent with Plan, Code and Verify steps. The pipeline is represented as a DAG-structure.
- Plan Real data adaption using dynamic planning with hierarchical graph structures. Code: Dynamic tool integration to improve code execution. Verify: Logical inconsistency identification through feedback
ByteComposer: a Human-like Melody Composition Method based on Language Model Agent
- ByteComposer: LLM-agent based melody composer with four elements: Conception analysis, Draft composition, Self-evaluation and modification and Aesthetic selection.
Large Multimodal Agents: A Survey
- Survey on multi-modal AI and LLM agents.
Genie: Generative Interactive Environments
- Genie: a Foundational World Model. The learning paradigm is unsupervised learning from unlabelled internet video. The approach scales effectively as compute is increased.
- Includes: Latent Action Model (LAM) for latent action between each video frame in each timestep, 2. Video tokenizer to convert video frames into discrete tokens, 3. Dynamics model to predict next frame
- The model/datasets are not released, but the approach is explained in the paper with single GPU implementation details by bringing your own data using the dataset creationg instructions provided.
Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
- Searchformer: Transformer model outperforms A* search algorithm in planning.
- Two step approach, where Transformer excels large action spaces and learns heuristics (strategies to guide search) from the training with the data.
- First step generates synthetic dataset: Imitate A* search by using A* search and recording compute and and optimal plan as text token sequences(task description, search tree dynamics, and final plan) with length of thousands of tokens. This dataset includes search dynamics of A* search itself. Train a Transformer model (Searchformer) to generate the text token sequences with optimal plan for a given task. This leads to a transformer model, which has the A* search coded in the model weights.
- Second step further trains Searchformer using Expert Iteration, which attempts to generate optimal plans to tasks with less steps in the optimal plan. The resulting model solves Sokoban puzzles with 27% less search steps, than A* search algorithm. The idea is to generalize the Transformer model into more generic search beyond A* search.
User-LLM: Efficient LLM Contextualization with User Embeddings
- User-LLM: generates user embeddings from user data with multi-feature autoregressive transformer and then fine-tunes the LLM using these embeddings with cross-attention.
- The method enables inserting the LLM with long-term user history through compressed user embeddings and short term user context through input prompt.
- Effective approach for LLM personalization and user modelling. Includes good chapter on LLM long context research.
∞Bench: Extending Long Context Evaluation Beyond 100K Tokens
- Coins prompting technique called: "Context recalling": improves code debug accuracy from +16% (using CoT) to +40% (using context recalling).
- Context recalling prompts the model to first recall the relevant information, before doing further reasoning.
- Introduces long context bencmark: ∞BENCH-benchmark for LLMs with above 100k context window.
Neeko: Leveraging Dynamic LoRA for Efficient Multi-Character Role-Playing Agent
- Neeko-agent: Multi-character roleplaying agent with LoRA.
- Includes Pretraining, Multi-character Role-Playing and Incremental Role-Playing with Fusion and Expansion stages.
MuLan: Multimodal-LLM Agent for Progressive Multi-Object Diffusion
- MuLan: Multimodal LLM agent, addresses text2image generation errors through progressive multiobject generation with LLM-based planning and VLM-based feedback control.
- MuLan is training free method.
Large Language Model-based Human-Agent Collaboration for Complex Task Solving
- ReHAC: uman-agent(LLM) collaboration with RL policy model.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
- AnyGPT: Any-to-Any Multimodal Language Model with any input output between text, speech, image and music.
- Uses only data preprocessing with modality specific tokenizers to tokenize input into discrete tokens and model outputs by de-tokenizing into specific modality outputs.
- Introduces multimodal alignment dataset made of conversations.
Shall We Talk: Exploring Spontaneous Collaborations of Competing LLM Agents
- Studies spontaneuous collaboration between competing LLM agents
- WorldCoder: LLM agent learns World Models (world_model.py) using Python program from interactions with its environment.
- Outperforms baselines from DeepRL- and ReAct-agents in gridworlds-environment.
- Incldues sample code of the world_model.py.
Comprehensive Cognitive LLM Agent for Smartphone GUI Automation
- CoCo-Agent: GUI control with VLM/LLM/CLIP, which includes Comprehensive Environment Perception (CEP) and Conditional Action Prediction (CAP). Includes information such as GUI screenshot, GUI layout information, user objective and action history.
- Offers SOTA-level performance on GUIs, yet high training cost.
LLM Agents for Psychology: A Study on Gamified Assessments
- PsychoGAT: Gamification of psychological assessment traditionally performed with questionaries with superior performance. Includes prompt templates.
Structured Chain-of-Thought Prompting for Few-Shot Generation of Content-Grounded QA Conversations
- Structured CoT (SCoT): breakdowns into states for for generating actions for each sub-tasks durign the specific state.
- For example first state determines, if question is answerable, the next step identifies required steps for the answer and the next state generates the step answer.
LongAgent: Scaling Language Models to 128k Context through Multi-Agent Collaboration
- LongAgent: Scales LLaMA to 128k context window outperforming GPT-4 through multiagent collaboration using inter-member communication.
- Leader agent selects agent members of team based on task description, agent team collaboratively reason, deduct answer and finally resolve conflict to generate final answer.
- Fine-tuning LLMs with Negative examples enhances performance.
Modelling Political Coalition Negotiations Using LLM-based Agents
- Political coalition negotiation with LLM agents.
LLM can Achieve Self-Regulation via Hyperparameter Aware Generation
- Hyperparameter Aware Generation (HAG): the LLM learns to modify automatically its hyperparameters (temperature, top_p, top_k, repetition_penalty) for each user task input.
- Self-regulation of hyperparameters enables the LLM to finetune its responses to different task inputs.
- Self-regulation takes inspiration from the ability of human body to regulate itself based on different factors like temperature, blood pressure, adrealine etc.
Robust agents learn causal world models
- Implies causal understanding is required for robust generalization.
- Causal models can be learned from adaptive agents.
Chain-of-Thought Reasoning Without Prompting
- CoT-Decoding: CoT without prompting. LLMs inherently pose reasoning abilities.
- Uses top-k alternative tokens to uncover CoT paths, which are frequently paths discovered in CoT.
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts
- ReadAgent: very long context management through gist-memories and pagination for web browsing.
- ReadAgent: LLM decided what content to store as episode pagination, LLM compresses page memory as shorter gist memory (see fuzzy-trace theory about memory) and LLM decides the pages to look up per given task and the gist memories related to the context of the task. The agent then retrieves the related page information to complete the task.
- Extends effective context window by 3-20x and keeps failure rate close to 0%, which is significantly less than traversing tree with a MemWalker-like solution.
- Gist-memory improves Web navigation over using raw html inputs, which is by nature a very long context task.
AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator
- AI Hospital: LLM acts with doctor, patient, examiner and physician-roles. Categorises medical information into: subjective, objective and Diagnosis/Treatment.
- MVME-benchmark (Multi-View Medical Evaluation): evaluates LLMs in symptop collection, recommendation analysis and diagnosis.
AgentLens: Visual Analysis for Agent Behaviors in LLM-based Autonomous Systems
- AgentLens: visual analysis of of LLM based autonomous agents and exploration of their behaviours.
- UI includesOutline view, Agent view and Monitor view. Summarizes raw events, Descriptions of generated behaviours, Behaviour embeddings, Timeline segmentation.
- The behavioural embeddings: enables plotting specific behaviours in time, which is very effective approach.
Towards better Human-Agent Alignment: Assessing Task Utility in LLM-Powered Applications
- AgentEval: framework to verify utility of the LLM tool through automatic criteria creation for a given task to review meeting of user needs.
- Includes CriticAgent to list criteria of accepted values and QuantifierAgent verifying suggested criteria.
DoRA: Weight-Decomposed Low-Rank Adaptation
- Next generation LoRA. Get more out from your LLM, while not directly related to agents.
GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements
- GLoRe: Presents a Stepwise Outcome-based Reward models. SORM is in contrat to Outcome-Based Reward models (ORMs) and Process-Based Rewrd Model (PRMs), where trained only on synthetic data to approximate future reward of optimal policy V*.
- Uses three step refinement training process: 1. Fine-tune base model for Student policy model, 2. SORM training, 3. Refinement training.
Grounding LLMs For Robot Task Planning Using Closed-loop State Feedback
- Brain-Body LLM(BB-LLM): Brain-LLM defines high-level plans for robot. The BodyLLM converts them into low-level planned actions as robot commands.
Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast
- Agent Smith: "Infectious Jailbraking" Technique, which infects single LLM agent, that then infects with exponential growth rate the remaining agents.
- Concering technique reminding traditional computer virus, because the computational/time/resource expenses of infecting single agent remain low, but includes capability of infecting rest of the agents.
Simulating Human Strategic Behavior: Comparing Single and Multi-agent LLMs
- Investigation on LLMs capability to simulate human strategic behaviour.
- Compares Multiagent vs. Single LLM agent performance in the Ultimatum game and finds multiagent system more accurately simulating human behaviour.
Large Language Models as Minecraft Agents
- Develops Minecraft Builder and Architect LLM agents using JSON-format with capacity to ask clarifying questions from the LLM.
- PROMST: Optimizes prompts. Includes TaskLLM and PromptLLM. PromptLLM generates new prompt suggestions from existing best prompts and their feedbacks. New candidates are selected by score prediction model.
T-RAG: Lessons from the LLM Trenches
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement
- FRIDAY: Self-improving embodied agent to interact with OS.
- OS-Copilot framework: Planner, Configurator to update or retrieve (Declarative memory for user profile and Semantic knowledge/Procedural memory for tools), Actor (Executor / Critic).
- Learns to control and self-improve.
Predictive representations: building blocks of intelligence
- Successor Representation (SR) may function as versatile building blocks of intelligence.
Secret Collusion Among Generative AI Agents
- Model capability evaluation framework on Secret collusion.
THE COLOSSEUM: A Benchmark for Evaluating Generalization for Robotic Manipulation
- THE COLOSSEUM benchmark for robot manipulation generalization through 20 diverse tasks.
Self-Correcting Self-Consuming Loops for Generative Model Training
- Self-Correcting Functions using expert knowledge for generative model training.
V-STaR: Training Verifiers for Self-Taught Reasoners
- V-STaR: Enhancement to STaR-method. Uses during self-improvement not only correct, but as well incorrect solutions generated to train a verifier using DPO, where is judged correctness of the model-generated solutions.
- Iterating V-STaR multiple rounds generates progressively better reasoners and stronger verifiers by increasing GSM8K performance significantly from base STaR-method.
- Addresses the aspect of data efficiency by being able to improve both from correct and incorrect solutions.
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training
- TS-LLM: a tree search guided LLM decoding with learned value function applicable for reasoning tasks.
Feedback Loops With Language Models Drive In-Context Reward Hacking
- LLMs interacting with the real-world create feedback loops, where the LLMs outputs shape world state, from where next LLMs are trained.
- Such feedback loops can cause In-Context Reward Hacking (ICRH): LLM outputs increase BOTH the objective and the negative side-effects.
- Output-refinement and policy refinement lead to ICRH.
Understanding the Weakness of Large Language Model Agents within a Complex Android Environment
- AndroidArena benchmark for measuring LLMs capability to control a modern operating system.
- Main failure modes: understanding, reasoning, exploration, and reflection.
Large Language Models: A Survey
- Reviews past years LLM research: LLM model families, building of LLMs, using of LLMs, LLM datasets, LLM metrics and future directions and challenges.
- Includes deployment pipelines, vector databases, prompting pipelines and LLM training/inference frameworks
Why Solving Multi-agent Path Finding with Large Language Model has not Succeeded Yet
- Identifies three reasons on why multi-agent path finding with LLMs does not work: model limitation, lack of understanding and lack of reasoning.
An Interactive Agent Foundation Model
- Interactive Agent Foundational Model: A generalist agent. Multi-task, Multi-domain: Healthcare, Gaming AI and Robotics.
- Interactive Agent framework: action encoder, visual encoder and language encoder. Pretrained to predict masked unified tokens for the three modalities: text token, visual token and action/agent token from each separate token per input type. Effectively generalizes between domains.
- Defines term "Agent-based AI" as generating dynamic behaviours grounded on the context understanding of uncertain environment. Defines "Embodied Agent-paradigm principles": Perception, Planning and Interaction. Agent actions impact directly task plans by not requiring environment feedback to plan next action.
- MUltimodal systems preteained cross-modality grounded with environment hallucinate less by being grounded with the physical/virtual environment and require less size, than models pretrained separately/without grounding.
UFO: A UI-Focused Agent for Windows OS Interaction
- UI-Focused (UFO) agent: Automatically controlling Windows OS. The system includes two VLM-based agents: AppAgent (Application Selection Agent) and ActAgent (Action Selection Agent).
- AppAgent uses User input, Desktop screenshot, App information, Examples and Memory. It chooses application to complete the task, generates global plan. AppAgent outputs observation, Thoughts, Selected App, Status, Global pla and Comment.
- ActAgent takes as input User request, Screenshots (highlighted last action, clean, annotated), Control information, Examples and Memory. ActAgent pursues local plans and actions until meeting the goal / receives observations from apps / interacts with memory. Outputs observation, Thoughts, Labeled control operation, Function, Status, Local plan and Comment.
- Control Interaction module grounds actions.
Real-World Robot Applications of Foundation Models: A Review
- A literature review of Robotics Foundationa models.
- Reviews Input/Ourput relationships of models, perception, motion planning and control.
TimeArena: Shaping Efficient Multitasking Language Agents in a Time-Aware Simulation
- TimeArena: A textual simulation environment for LLM agents to complete tasks as soon as possible.
- 30 real world like tasks from household activities to laboratory work. Illustrates, that GPT-4 lacks temporal awareness such as failing to recognize opportunities in parallel processing.
ScreenAgent: A Vision Language Model-driven Computer Control Agent
- VLM to control a real computer screen/GUI.
- Includes Planning, Acting and Reflecting phases.
In-Context Principle Learning from Mistakes
- Learning Principles (LEAP): Intentially guide LLM to make mistakes on few examples to reflect on them and learn task-specific principles.
- Improves MATH reasoning capability.
Keyframer: Empowering Animation Design using Large Language Models
- Keyframer: LLM-powered animation generator from SVG images.
Discovering Temporally-Aware Reinforcement Learning Algorithms
- Reviews Temporally-aware reinforcement learning and Meta-learning.
WebLINX: Real-World Website Navigation with Multi-Turn Dialogue
- WebLINX: Real-time webpage control with LLMs.
- Filters relevant web page elements
How Well Can LLMs Negotiate? NegotiationArena Platform and Analysis
- NegotionArena bencbmark: to measure LLMs ability to negotiate.
Decision Theory-Guided Deep Reinforcement Learning for Fast Learning
- Decision Theory-guided Deep Reinforcement Learning (DT-guided DRL): addresses cold start problem in RL.
- Promotes more structural and informed exploration strategy.
The Future of Cognitive Strategy-enhanced Persuasive Dialogue Agents: New Perspectives and Trends
- CogAgent: Persuasion LLM agent framework.
- Cognitive strategy mining, Cognitive Strategy Prediction for Dialogue Modelling and Application scenarios (bargaining, counselling, debating etc.)
Can Large Language Model Agents Simulate Human Trust Behaviors?
- Reviews LLM agents ability to simulate Trust.
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
- ScreenAI: a VLM. Screen user interfaces (UIs) understanding, dataset creation with LLMs.
Self-Discover: Large Language Models Self-Compose Reasoning Structures
- Self-Discover: Self-discovers complex reasoning structures outperforming CoT-Self-Consistency in MATH, while being more compute efficient.
- Select reasoning modules(for exampel CoT, etc), Adapt reasoning modules and Implement reasoning structures as key-value pair as json.
- Works with multiple LLMs and different types of reasoning scenarios.
AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls
- AnyTool: LLM agent utilizing over 16k APIs.
- API retriever with hierarchical structure with meta-agent, user query solver using candidate APIs and self-reflection mechanism for initial impractical solutions. Uses GPT-4 with function calling.
- Introduces AnyToolBench-benchmark.
- Meta-agent is linked with multiple category agents each managing collection of tool agents.
Can Generative Agents Predict Emotion?
- Reviews LLM agents capability to align humans in terms of emotional states, when new events take place.
- LLM agent framework, where time series text memories are stored in graph database, which are summarized. As new events take place, the norm of the past episodic memories is combined with the current context. LLM agents emotional state is measured using pre-existing Positive And Negative Affect Schedule (PANAS)-framework to arrive a PANAS score of the current emotional state. Finally, the new memory is added to the graph database.
- The LLM agent acts in a virtual town with multiple agents interacting for example inviting and assisting a party. Performance is reviewed using pre-existing EmotionBench-benchmark. LLM agents lack to some extent ability to align emotionally like humans.
- Raises interesting concern, that GPT-3.5 may be biased to provide positive answers and therefore struggle to illustrate negative emotions.
S-Agents: self-organizing agents in open-ended environment
- S-Agents: Tree-of-Agents, where the leader LLM agent leads tree-like structure wiith executor agents.
- Hourglass agent framework: Monitor progress and Hierarchical planning.
- Monitor progresss: starts with previous plan and perception used to monitor progress against objective.
- Hierarchical planning: plans long-term (task planner), takes current task and generates actions (action planner) in the environment and agents.
- Indirect Reasoning (IR): Uses logic of contrapositives and contradictions for factual reasoning and math proofs.
- Adding IR to factual reasoning increases overall accuracy compared to Direct Reasoning (DR) only or IR only.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
- Vision Language Model: MobileVLM V2.
QuantAgent: Seeking Holy Grail in Trading by Self-Improving Large Language Model
- QuantAgent: Includes two LLM agents: Writer and Judge. The Writer-agent retrieves Knowledge Base (KB) and then generates answer based on the KB and submits the answer to real environment for evaluation. The Judge-agent retrieves relevant KB related to the review and it then generates score and feedback used in the next iteration.
- The iteration continues until maximum number of steps is reached or the score is high enough.
Beyond Lines and Circles: Unveiling the Geometric Reasoning Gap in Large Language Models
- Improves LLMs geometric reasoning with self-correction, collaboration and role specialization using geometric tools and four LLM agents.
- Uses LLM agents with four roles: Natural language solver and validator, Geometric tool Solver and Validator.
In-context learning agents are asymmetric belief updaters
- In-context learning: framing of the problem significantly impacts succesfullness.
- LLMs learn better from better-than-expected outcomes rather than worse-than-expected outcomes.
Systematic Biases in LLM Simulations of Debates
- Reviews LLMs capability to generate believable simulation and current LLMs include a simulation bias for political debate.
- Self-fine tunes LLM to take a specific political stance by using politically-oriented question to reflect answers, which is more effective than prompt-profiling alone.
- Illustrates the difficulty for LLMs to simulate specific human behaviour like a political views.
Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
- Takes safety research from LLM safety to LLM agent safety, which is more holistic view.
- Scientific agent: Reviews LLM agent vulnerabilities within science domain: Data Insuffiency, Planning limitation, Tool limitations, LLM limitations and Lack of measurement.
- Introduces triangle framework: Human regulation (Intent), Agent alignment (Red teaming) and Agent regulation (environmental feedback).
Chain-of-Feedback: Mitigating the Effects of Inconsistency in Responses
- Recursive Chain-of-Feedback (R-CoF): Recursively breaks down complex reasoning problems into more easier and more detailed solutions and re-adjusts original reasoning based on the detailed correct reasoning.
- Given a problem, asks LLM to generate answer using multiple reasoning steps, then LLM verifies the incorrect reasoning steps, LLM then recursively asks only to solve the incorrect reasoning steps using same approach. If the new answer is correct, it gets added to the higher level answer and otherwise repeats the recursive LLM call.
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
- Promptable Representations for Reinforcement Learning (PR2L): the model asks from VLM about the game tasks, such as in case a spider is visiblle. The VLM responds semantic features or knowledge, which then better help the system to advance in the game by connecting what is seen with what it needs to do. This ensures, that the system actions are grounded with the reality of what is going on in the game.
- Initializes RL policy using VLM representation.
- PR2L was not trained to play Minecraft only, but it still plays at level closed to models specifically trained with Minecraft games.
Guiding Language Model Math Reasoning with Planning Tokens
- Planning tokens improve LLM reasoning capabilities.
- Add the planning tokens in the LLM generated answer based on CoT in the beginning of each reasoning step, such as planning token related to multiplying done on that reasoning step,
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- DeepSeekMath: 7B model comparable with math reasoning of a 70B model, close to Gemini Ultra and GPT-4.
- Introduces Group Relative Policy Optimization (GRPO).
- Studies LLM agents capability to follow human personality profiles: analytical vs. creative personality.
- Each profile demonstrates different levels of consistency towards its profile in writing style and in a personality test.
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning
- Plan Like a Graph (PLaG): asynchronous plan reasoning with LLM: generates time estimations, identify step dependencies, converts the time estimates and dependencies into a graph processor and finally generate answer.
- Creates AsyncHow-benchmark: for asynchronous plan reasoning, requiring ability to correctly add time, correctly comparing time durations and ability to solve constrained reasoning.
- LLMs struggle efficiently completing complex asyncchronous plans without detailed illustration of how to solve the task.
C-RAG: Certified Generation Risks for Retrieval-Augmented Language Models
Understanding the planning of LLM agents: A survey
- Review studies about the LLM agents planning capabilities.
- Categorizes these planning capabilities into: Task decomposition, Plan selection, External module, Reflection and Memory.
- Identifies development areas in: evaluating efficiency of the planning, revisiting of planning strategies in multimodality and more realistic evaluations.
Solution-oriented Agent-based Models Generation with Verifier-assisted Iterative In-context Learning
- SAGE: Modelling and Solving stages with Automatic Design and Generation of ABM.
- LLMDB: Detailed data management framework with LLMs.
- Components include: Preparation, Request pre-processing, Request parsing, Pipeline executor agent, Vector database and Data/Model management.
Collaborative Agents for Software Engineering
- CodeAgent: Autonomous Agent, a multi agent code review system.
- SOTA in code review systema.
- Scaling up LLM-agents increases performance with sampling & majority voting.
- Performance improvements increase and then decrease as difficult level gets harder. Improvements increase in function of number of steps. Prior probability of correct answer increases performance gains.
- Affordable Generative Agents (AGA) framework: agent environment interaction and inter-agent interactions.
- Believable, low cost LLM-agents by replacing repetitive LLM inferences with learned policies. Models social relationships between LLM-agents and compresses auxiliary dialogue information.
- Emergent believable behaviour: LLM-agents generate finite behaviours in limited environments. Defines "mind wandering"-technique in memorory to generate diverse social behaviour by sampling both: highly relevant events and sampling ranly unrelated events. The idea is to randomness & spontaneus responses, like a real person.
- Social memory: relationship, feeling, events summary between the agents.
K-Level Reasoning with Large Language Models
- K-level of Reasoning: Recursive reasoning process, which improves dynamic reasoning by integrating cognitive hierarchy theory by recursively predicting and responding to the thoughts and actions of rivals.
- In essence, multiple LLM agents take a context, reason on it and make decision in "k-1"-level. The reasoning is then repeated in the "k"-level by integrating the the analysis from "k-1"-level to arrive decision in the "k"-level.
Multimodal Embodied Interactive Agent for Cafe Scene
- MEIA (Multimodal Embodied Interactive Agent): Uses Multimodal Environment Memory (MEM) with LLM and VLM, to store egocentric environmental information (object IDs/coordinates as textual memory and visual observations as image memories) to improve significantly task planning and execution.
- MEIA is able to perform various tasks such as seating guidance, order taking and environmental adjustments being robust in zero-shot learning for real world tasks.
- It appears to be the first paper to introduce multimodal memory, which improves significantly performance and increases precision of the planning.
- Includes two measurement metrics: ESR (Executable Success Rate) and SSL (Succcess Rate Weighted by Step Length) with formulas included.
- Uses RGB images (stored in image memory)/depth images/segmentation images.
Efficient Exploration for LLMs
- Actively exploration is used to achieve high performance with less feedback.
- Uses double Thompson sampling with eistemic neural network (ENNs) to model reward uncertainty and least amount of queries.
- Gemini Nano is used as baseline model, which output is compared with Best-of-N responses from Gemini Nano based on reward model.
- OLMo: First open access data, open weights, open source code LLM.
- The model training data comes with need to agree to AI2's license terms wiith very clearly stated legal implications.
Formal-LLM: Integrating Formal Language and Natural Language for Controllable LLM-based Agents
- Formal-LLM: Context-Free Grammar (CFG) translates guidance and rules for each relevant task, which LLM text generation must follow when generating the plan.
- Prevents generating invalid plans.
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis
- StrokeNUWA: Introduces image representations based on vector graphics using "stroke tokens". The approach does not require using raster/pixel representation.
- Includes components of: Vector-Quantized-Stroke (VQ-Stroke), Scalable Vector Graphics (SVG) compression, Encoder-Decoder LLM for SVG generation and post-processing SVG fixer.
- Enables 94 times faster inference speed and representing images as more "language like" manner of sequences of strokes.
Efficient Tool Use with Chain-of-Abstraction Reasoning
- Chain-of-Abstraction (CoA): trains LLMs with decoded reasoning chains using abstract placeholders and then call tools to complete the reasoning chain.
- CoA learns more generic math reasoning and
- UltraTool Construction-framework includes three key steps: Query collection, Solution Annotation and Manual refinement.
- UltraTool: benchmarking LLM performance in using tools in real world.
- Reviews tool use performance from planning, tool creation awareness, tool creation, tool usage awareness, tool selection and tool usage.
- Scale-Eval: Meta-evaluation framework using agents debates to reach consensus or align with human answer in various task scenarios.
- LLaMP: ReAct-agents connected with arXiv, Wikipedia, Material Project-agents. Includes promts and json-formats used with the RAG-pipeline. Reduces hallucinations in material science queries.
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
- Mobile-Agent: Multimodal Large Language Models (MLLM) for mobile devices, which locates visual/textual, plans, decomposes and executes complex tasks.
- OS agnostic
- Introduces Mobile-Eval benchmark and open sources code.
Beyond Direct Diagnosis: LLM-based Multi-Specialist Agent Consultation for Automatic Diagnosis
- Patient consultation with muliple agents, starting with general practioner and then LLM agents in specific specialities: surgeon, respiratory doctor, endocrinologist.
- Icludes three stages: Individual practitioner consultation, practitioner group consultation and agent-based groupdecision fusion.
- CompAgent: LLM agent is manages the task of the entire image generation.
- The LLM agent is used to plan composition of objects next to each other. Achieves better images for example when prompted to generate image with a red hat next to blue backpack.
YODA: Teacher-Student Progressive Learning for Language Models
- YODA: Hunan-like progressive learning paradigm for LLMs, where student agent learns in fixed dataset by learning first basic questions, then learns to generalize and finally learns harder problems.
- Teacher agent asks then similar questions from the student agent. The teacher agent gradually adds more complex and more generic questions after each iteration and offers feedback to the student agent for the answers provided.
- The approach helps the student agent to learn to solve problems and generalize problems comprehensively, which leads to 10% improvement in MATH benchmark from the original Llama 2.
Turn-taking and Backchannel Prediction with Acoustic and Large Language Model Fusion
- Reviews how voice-assistant systems should predict and manage: turn-taking, backchanneling and continued speaking.
- Contiying speaking refers to the other party needing to continue listening the current speaker. Backchanneling refers to the current listener needing to produce a short utterance of acceptance without meaning to take over the speaker role. Turn-taking refers to the listered being expected to take over speaking turn from the current speaker.
- Creates fusion model combining both LLM (GPT-2/RedPajama) and HuBERT-acoustic model.
Hi-Core: Hierarchical Knowledge Transfer for Continual Reinforcement Learning
- Hi-Core: Formulates goals as a high-level policy using LLM reasoning and then low-level policy learning towards these high-level goals. Policy library is used to store policies searchable with embeddings based on policy description.
- Makes the important point, that to learn high-level human cognitive skills using transfer learning, we need to represent high-level human knowledge effectively to be able to transfer them into models.
Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
- Meta-prompting: LLM coordinate and execute multiple independent queries with their responses to generate final answer.
AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
- AutoRT: Fleet of robots use VLM and LLM
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
- HAZARD-benchmark made of three dynamic challenges for an embodied agents: flood, fire and wind, which performance are evaluated in terms of value, steps and damage.
- Builds LLM-based pipeline for embodied agents by providing it task description, agent status and target info. Agent reads environment information, includes observation memory and LLM-based decision maker to select the next action.
Memory Matters: The Need to Improve Long-Term Memory in LLM-Agents
- Reviews memory management of LLM-agents with useful insights about using different types meta-data in vector db along the word embeddings as long-term memory.
- Identifies in past research example ways of storing: thoughts/skills in vector db, but as well gaps in retrieving information, when different memories may contradict the retrieval.
OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
- OK-robot (Open-Knowledge): 59% success rate in open ended picking and dropping task.
- SOTA level in OVMM-benchmark.
WARM: On the Benefits of Weight Averaged Reward Models
- Weight Averaged Reward Models (WARM) models.
- PySafe: Safety research on LLM agents based on behavioural/psychological-characteristics.
- AttentionLego: LLM is implemented on Processing-In Memory (PIM) HW.
- Simplistic robotic control using VLM and LLM: VLM to object textual description and scene comprehension. LLM for reasoning and REM-node to translate commands into robot actions.
Tool-LMM: A Large Multi-Modal Model for Tool Agent Learning
- Tool-LMM: LLM is agent able to process multimodal inputs into APIs of the specific modalities.
- Input modalities include, text, audio/text, text/video and text/image. The LLM text output includes recommendation of the API to be used and model information.
A match made in consistency heaven: when large language models meet evolutionary algorithms
- Compares and finds multiple similarities between GPT-LLMs and Genetic Algorithm (GA)-evolutionary algorithms.
CivRealm: A Learning and Reasoning Odyssey in Civilization for Decision-Making Agents
- CivicRealm: RL agent generalization benchmark, based on video game environment with various players and dynamic game space, imperfect information and random variability.
Self-Rewarding Language Models
- Self-rewarding LLMs: Ability for LLM to follow instructions and Ability to create/evaluate new training data (Self-Instruction creation).
- LLLm-as-a-Judge: LLM acts as a reward model and self-reward its own responses.
- Claims to outperform Claude 2/Gemini Pro/GPT-4 0613 with three iterations and ability to keep continuously improving both self-instructions and the reward signal.
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
- R-Judge: Safety benchmark for LLM-agents, not LLM models on 27 risk scenarios.
Large Language Models Are Neurosymbolic Reasoners
- LLM agent plays text-based game with access to Symbolic module.
ReFT: Reasoning with Reinforced Fine-Tuning
- Reinforced Fine-Tuning (ReFT): In the initial SFT-step, the model is trained to produce correct answers to mathematical problems.
- In the second step, online RL with PPO is used to prompt multiple CoT responses to learn from them.
- ReFT uses majority voting and reward model reranking.
Scalable Pre-training of Large Autoregressive Image Models
- AIM: Visual models, which scale with both compute and data introduced.
- LLM agent as as social (automated) actor.
- Identifies what makes a good vs negative social behaviour for LLM agents.
Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering
- AlphaCodium: Improves code solutions through AI code tests.
- Iteratively reasons about code tests and reflects problem, generates AI tests to improve testing.
- Two phases: Preprocessing (to reason new AI tests from ranked solutions feom public tests) and Code iteration (with public and AI tests).
MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
- MultiPLY: Multisensory (temperature, tactile, audio and visuals) embodied agent acts (action tokens such as navigate/select/touch/observe/look around/) in 3D virtual environment.
- The model trained with ultisensory Universe-dataset, performs multiple tasks: navigates, manipulates, uses tools, dialogue,
- Encodes 3D-scenes as object centric representations, generate action token to be taken from current state token (temperature/tactile/sound/object) within the environment to reach new state observation in time. The new state token is fed back to LLM to drive follow up actions.
DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models
- DoramonGPT includes task-related symbolic memory, sub-task/knowledge tools and MCTS planner.
- The task related symbolic memory will choose either the Spatial or Time-dimension as most relevant based on the LLM.
- DoramonGPT collecta information before reasoning, reasons spatial-temporal video, explores different solutions in a large planning space.
Self-Imagine: Effective Unimodal Reasoning with Multimodal Models using Self-Imagination
- Self-Imagine: VLM creates HTML code about the text question, renders it as an image and uses the image with the question to answer the question with the VLM.
Application of LLM Agents in Recruitment: A Novel Framework for Resume Screening
- Automated resume screening, where segments from CV are classified into information types, personal information is removed. T
- The HR grading LLM agent rates these resumes and another HR decision making agent picks preferred application with eplanation, which is then available for the HR professional.
- Contrastive Preference Optimization (CPO): A potential improvement to DPO, applied in machine translation.
Exploring the Potential of Large Language Models in Self-adaptive Systems
- Literature review of Self-Adaptive Systems with LLMs.
A Study on Training and Developing Large Language Models for Behavior Tree Generation
- LLMs used to generate Behavioural Trees (BT) generation for agents/robots.
When Large Language Model Agents Meet 6G Networks: Perception, Grounding, and Alignment
- Least Age-of-Thought (LAoT) model caching algorithm to manage local/global compute/network traffic to avoid model with least valuable thoughts.
- Introduces CodeAgent, a LLM agent able to use tools (search, code navigation and code interpreter) to generate code/create repositories (instructions, code dependencies) better than Github Copilot.
- Introduces CodeAgentBench-dataset.
- Code symbol navigation is key component, to explore: file/module-based parsing and class/function-symbol navigation.
Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
- α-UMi: Multi-agent LLM, which includes planner/caller and summarizer and tools.
ModaVerse: Efficiently Transforming Modalities with LLMs
- ModaVerse: Introduces Adaptor+Agent framework for training multi-modal LLM able to process content across audio/video/image modalities.
- Introduces Input/Output (I/O) Alignment: LLM generates language aligned meta-responses, which are instructions to activate specific generative models.
- This method is capable of converting variety of modalities, while being very efficient to train.
AntEval: Quantitatively Evaluating Informativeness and Expressiveness of Agent Social Interactions
- AntEval: a framework to evaluate LLM-agents social interactions with two metrics: Information Exchange Precision and Intention Expresiveness Gap.
- Investigates bi-directional feedback loop, where LLM agent acts as a teacher, while the RL agent acts as a student.
EASYTOOL: Enhancing LLM-based Agents with Concise Tool Instruction
- EASYTOOL: Creates a cleaned version of any tool/API documentation for LLM agent to use via single "tool instruction".
- Tool documentation is translated into: tool descriptions and tool core functionality. Each are created using specific LLM instructions.
- Significantly improves tool-based LLM agent performance.
Designing Heterogeneous LLM Agents for Financial Sentiment Analysis
- Heterogenoeus multi-Agent Discussion (HAD): Multiple agents with each instructions to pay attention to error category types, which form the resulting answer based on shared disussion. The domain of the research is Financial Sentiment Analysis.
- Builds on the conclusion, that LLMs are "resources": similar to Minsky's theory about human mind being built from a Resource-cloud to be activated/deactivated on the spot.
- Defines Kernel Theory-Based Design: Kernel theory, Meta-requirements, Meta-designs, Testable hypothesis.
- Evidence-to-Generation (E2G): Single LLM produces in two-steps answer step-by-step based on evidence from the context/question provided.
- E2G represents context-aware reasoning.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
- Adds backdoors on LLMs.
- Trains deceptive LLMs using data, which "acts" based on being either in training vs inference: demonstrates safe code vs unsafe code.
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
- Reviews systematically "Personal LLM Agents" connected to personal data and devices for personal use.
The Impact of Reasoning Step Length on Large Language Models
- Adding reasoning steps improvea accuracy unril 5th step.
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks
- DABench-benchmark for LLM based data analysis and open sources Data analysis agent : DA Agent.
Agent Alignment in Evolving Social Norms
- EvolutionaryAgent: Evaluates LLM agents based on fitness to social norms using observer LLM within EvolvingSociety-environment.
- LLM agents producing highest social norm ratings, self-envolve and reproduce into new generation LLM agents. Agents either convert into obsolate or survived.
- Agents events are recorded within short term memory with a threshold, which defines when long term and higher-level memories are distilled.
- Defines initial stage of the EnvolvingSociety and the desired direction only.
Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects
- Reviews LLM Intelligent agents: definitions, frameworks, single/multiple agents, compoments, cognitive features etc.
- Adds a metacognition to LLM agents for emulating System 1 and System 2 processes. The idea is to let LLMs "think about thinking".
- The Metacognition module (knowledge about itself, the task and the strategies) gets triggered to ask reflective questions, when the LLM agent is not making significant progress.
- The metacognition is used throughout the planning, evaluation, monitoring and cognition-steps using reflective questions and then stored in the meta-memory used.
Agent AI: Surveying the Horizons of Multimodal Interaction
- Agent AI system: Perceives and acts in different domains and applications.
- Multi-modal generalist agent: Environment and Perception with task-planning and skill observation, Agent learning, Memory, Agent action; Cognition.
LLaVA-ϕ: Efficient Multi-Modal Assistant with Small Language Model
- LLava-Phi: VLM using Phi-2 as LLM model with CLIP-ViT-L/14 with 336x336 visual encoder.
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
- Self-Contrast: Explores potential paths, Contrasts differences and Summarizes them into checklist to better reason.
- Many LLM agent errors are due to inconsistent feedback.
INTERS: Unlocking the Power of Large Language Models in Search with Instruction Tuning
- Technique to tune LLM for "search": INstruction Tuning datasEt foR Search (INTERS).
Act as You Learn: Adaptive Decision-Making in Non-Stationary Markov Decision Processes
- Adaptive MCTS (Ada-MCTS): explores using epistemic & aleatoric uncertanties to adapt risk-aversion behaviour vs performance when spending more time in the environment.
Economics Arena for Large Language Models
- EconArena: Reviews multiple LLM models jn their ability to act rationally by comparing performance between models and against Nash Equilibrium (NE) rationality.
- Better models act more rational. LLMs are dynamically able to change strategies based on opponent strategy. Game history improves reasoning. Competing with rational opponent helps to achieve NE quicker.
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
- LLMs have built-in capability to manage long context, similar as children manage long context such as books mainly by having seen short context text.
- Self-Extend: No specific training / finetuning required. Plug in 4 lines of code during inference to the attention mechanism, based on LLM with RoPE and FLOOR-operation.
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
- Self-Play fIne-tuNing (SPIN): Fine-tuning LLMs based on Self-play mechanism, where the main player is the to-be learned LLM from the current iteration and its opponent is the same LLM from the previous iteration.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
- Pangu-Agent: Introduces a generic RL-based objective to improve agents intrinsic and extrinsic functions.
AppAgent: Multimodal Agents as Smartphone Users
- Multimodal VLM agents learn operate popular smartphone apps by creating a knowledge base through: Autonomous exploration and Human demonstrations.
- Includes: Exploration phase and Deployment phase.
- Exploration phase learns smartphone functionalities through trial and error, which are saves records of effects to actions and stops, if the current view is unrelated to the assigned task. Exploration stops, whene task is finished. Alternatively these behaviours are shown through human demonstrations, which keeps the agent exploration streamlined and efficient.
- In deployment phase, the VLM agent has access to the UI screenshot and potential actions. The agent generates a summary of the actions taken and interaction history, which are passed to the next step.
Capture the Flag: Uncovering Data Insights with Large Language Models
- Exlores two types of Data Science Agents: Explorer agent and Aggregator agent
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
- AgentCoder: Multi-Agent Assistant Code Generation made from Programmer Agent, Test designer Agent and Test executor Agent
- Uses Self-Refine with CoT in a Multi-Agent System.
DSPy Assertions: Computational Constraints for Self-Refining Language Model Pipelines
- LM Assertions: Integrates with DSPy, which integrates reasoning, self-improvement, augmentation, retrieval and tools (DSPy is like challenger for Langchain).
- To help runtime self-refinement in LM pipelines with boolean type conditions: Assert (hard or critical condition) and Suggest (soft condition).
- For example a critical condition (hard) is such, that will resul the LM pipeline to halt, if the condition is not met with maximum number of attempts, while Suggest-option still lets the pipeline to continue.
ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation
- ASSISTGUI: Window mouse / keyboard management with LLM.
- Explores generative agents in urban environments: includes memory modyke, movement module, visual inference module and a LLM module
- Discrete Information Retrieval (dIR): Text-queries of SQL databases using LLMs.
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
- Plays Starcraft 2 better than an average player by using Chain of Summarization (CoS), python-sc2 and TextStarCraft II-environment (Observation-to-Text Adapter: and Text-to-Action Adapter).
- Chain of Summarization (CoS): Improves LLMs capability to extract / analyze information using two compnents: Single-frame summarization and Multi-frame summarization.
- TextStarCraft II-environment processes game information into textual format for LLM model defining macro-actions and a rule-based method for micro-actions
- System prompt includes: Situation Overview, Situation Analysis, Strategic Planning, Opponent Strategy, Analysis, Strategic Recommendations, Decision-Making rocess.
- Reduces 10x the need of LLM API calls and improves strategic, analytical and judging capabilities.
Large Language Models Empowered Agent-based Modeling and Simulation: A Survey and Perspectives
- Reviews LLM-based agents on their ability to simulate various human-like capabilities.
Agent Assessment of Others Through the Lens of Self
- Discusses concept of Self-Awareness of Autonomous Agents.
Evaluating Language-Model Agents on Realistic Autonomous Tasks
- Autonomous Replication and Adaption (ARA) framework: reviews ability of LLM agents to acquire resources, create copies of themselves and adapt to novel situations in the real world.
- Tests LLM-agents using Scaffolding programs to interact with LLMs.
- Defines implications of potentially ARA-level agents.
LLM-ARK: Knowledge Graph Reasoning Using Large Language Models via Deep Reinforcement Learning
- LLM-ARK: LLM reasons from Knowledge Graphs with DRL.
Learning to Act without Actions
- LAPO (Latent Action Policy).
ProTIP: Progressive Tool Retrieval Improves Planning
- Progressive Tool Retrieval Improves Planning (ProTIP): Mulit-step planning with external tools, where tasks are decomposed without explicit definition of the sub-task.
- Addresses the issue, where single-step tool retrieval does not manage to handle dependencies between the tools.
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
- Self-Imepoving LLM model without any human-assisted data for fine tuning achieving significantly better reasoning results with smaller model, when using the synthetic data to distill smaller model.
- Finetunes LLM with ReST using ReAct-method reasoning-actions.
Practices for Governing Agentic AI Systems
- OpenAI's research on Agentic AI systems with definition of Agentic AI system.
- Includes level of "Agenticness": the degree of goal complexity, environment complexity, adaptability and independence.
TinyGSM: achieving >80% on GSM8k with small language models
- First student LLM to learn the Teacher LLM model ( GPT-3.5) performance in mathematical reasoning using synthetic data from the teacher model.
- TinyGSM: Two 1.3B LLNs with a 1.3B verifier LLM achieves SOTA level 81.5% accuracy on GSM8k, which consists of a high-quality dataset TinyGSM and use of verifier selecting final answer from multiple output generations.
Modeling Complex Mathematical Reasoning via Large Language Model based MathAgent
- Planner-Reasoner-Executor-Reflector (PRER) / MathAgent: Planner, Reasoner, Executor and Reflector.
- Systematic process for solving zero-shot mathematical reasoning with LLM agents.
Rational Sensibility: LLM Enhanced Empathetic Response Generation Guided by Self-presentation Theory
- Self-Representation with Lamb: Uses semantic label to set tone for the conversation.
LiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers
- LiFT: Outperforms significantly VPT/other models in MineDojo-ennvironment.
- LLM provides task instruction.
- VLM is sed to learn policy and act as a reward model.
LLMind: Orchestrating AI and IoT with LLMs for Complex Task Execution
- LLMind: Includes coordinator updating short-term memory/retrieving required AI (IoT) modules with ability to define, if script exists for the module and enerates it, if missing. Coordinator retrieves error / output messages from the executed script, which is handled by the script executor.
Holodeck: Language Guided Generation of 3D Embodied AI Environments
- HoloDeck: Generating 3d embodied environments with LLM: FLoor-wall module, doorway-window module, object selection module and layout design module.
- Personalized Path Recourse (PPR): Personalized path of actions to achieve a certain goal with an agent.
Adaptive parameter sharing for multi-agent reinforcement learning
- AdaPS: Maps agents to different regions of brain/shared network based on identity vectors obtained with VAE and clusters agents to K classes.
Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft
- RL agent using LLM to act as a Reward designer, Reward critic and a Trajectory designer.
Vision-Language Models as a Source of Rewards
- VLMs work as reward models and larger scale improves performance of the reward model.
Learning Coalition Structures with Games
- Coalition Structure Learning (CSL): Learns coalitions of agents via set of games.
- Medprompt+ extends Medprompt-method improved by asking additionally if scrapt-pad is needed and increasing number of ensembled calls from 5 to 20.
diff History for Long-Context Language Agents
- Compresses consecutive text observations from environment with Unix "diff"-command, which leads to 700% improvement in game score, outperforming existing agents by 40%, which use visual observations.
- Similar approach may enable building vastly more generic embodied LLM agents.
Sequential Planning in Large Partially Observable Environments guided by LLMs
- Neoplanner: builds state space model of the environment by testing different actions, observations and rewards. Builds a graph memory of learnings from all previous trials using Learner agent.
- Model provides anytime best policy given the knowledge at that moment. Balances exploration and exploitation.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
- ReSTEM (Expectation-Maximization): LLM generates samples (E-step/Expectation-step) using temperature sampling, filter samples using binary feedback/reward, fine-tune LLM using these feedbacks (M-step/Maximization-step). Repeat few rounds. Improves significantly coding and math benchmark results.
- Ability to generate multiple correct solutions compared against human-generated data.
- ReSTEM uses temperature sampling (diverse/creative), compared to STaR-method based on greedy sampling (most-likely), where the rationalization-process leads to false-positive solutions.
KwaiAgents: Generalized Information-seeking Agent System with Large Language Models
- KwaiAgents, an autonomous agent loop including three key components: (KAgentSyst), LLMs (KAgentLLMs) and Benchmarks (KAgentsBench).
- System includes: Memorybank (Knowledge, Conversation and Task), Tool-library (Factuality-aware, Time-aware and Custom tools) used with Memory update, Task plan, Tool execution and Finish & Conclude-steps.
- LLM-component includes templates for LLs, Meta-Agent Tuning (MAT)-framework and LLM services. Benchmarks include both human and LLM-driven profiling.
- MAT includes six key components to generate prompt templates: system profile, instructions/constraints, tool specification, goal placement, memory allocation and output format.
Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
- Creates answer in two steps: Starts by creating pseudo-code to solve the question, then runs the pseudo-code in code interpreter or LM emulating code, in case no code interpreter is available.
AVA: Towards Autonomous Visualization Agents through Visual Perception-Driven Decision-Making
- Autonomous Visualization Agents (AVAs): User instructions are converted with Visualization agent into actions and the taken actions are converted back to language within visualization tasks.
- Components include: Visual perception, Action planning and Memory components, working within visualization-perception-action-loop.
Generating Illustrated Instructions
- StackedDiffusion: Generates illustrated instructions based on text, which helps to train SOTA level multi modal models preferred over human generated articles.
- Introduces "Attention Buckets", which enable a 7B open source model to acchieve GPT-4 level tool use performance by compensating attention peaks between parallel processes in specific context.
- Concordia-library: Simulation environment made of multiple agents and Grand Master (GM) inspired by the Dungeons and Dragons game.
- Agents consume observations and GM agent actions. Agent produces actions and GM event statements (such as physical grounding).
- Includes long and short term memory, which include state of the world.
LLM as OS (llmao), Agents as Apps: Envisioning AIOS, Agents and the AIOS-Agent Ecosystem
- AIOS-Agent Ecosystem: Envisions LLMs as OS, Agents as Applications, Natural Language as Programming language and Tools as Devices/Libraries.
Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models
- Answers visual questions by creating programs, that can review the image such as count number of specific types of objects and use tools.
- Answer is provided with CoT reasoning based on filtered program from many programs executed.
Beyond Isolation: Multi-Agent Synergy for Improving Knowledge Graph Constructio
- Uses three LLM agents for entity, event and relation extraction to build knowledge graph.
Large Knowledge Model: Perspectives and Challenges
- Large Knowledge Models: Reviews combination of LLMs (neural representation) and Knowledge graphs (symbolic representation) through usage of knowledge graph embeddings and text embeddings with LLMs.
Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication
- Exchange-of-Thought (EoT): Improvement from CoT and Self-Consistency, where thoughts from other LLMs are considered, outperforming in mathematical reasoning the CoT with Self-Consistency
- Proposes four communication paradigms to define the setup of the Exchange-of-Thought: Memory, Report, Relay and Debate.
- For example in Debate-mode: two LLM agents produce first ansswer the question and the two rationalizations are provided to the third LLM agent in order to debate these solutions in order to provide the right answer.
LLM A*: Human in the Loop Large Language Models Enabled A* Search for Robotics
- LLM A*: Includes current node, goal node, optical action and these three make up the plan.
- The chat-environment with user defines user inputs: Setting up environment, Setting up Action model, Start and Target Nodes, Heuristic and Rules.
- Demonstrates the possibility of achieving very good path planning results using mobile embodied agents.
Towards Learning a Generalist Model for Embodied Navigation
- NaviLLM: Embodied navigation with LLMs using schema-based instruction (task, history, observation and output hint), which generalizes well to unseen navigation tasks.
- Uses the following Multi-task learning modules: Visual-Language Navigation, Object localization, Trajectory Summarization and 3D Queestion Summarization.
OpenVoice: Versatile Instant Voice Cloning
- OpenVoice: Voice cloning almost from instant voice record.
Universal Self-Consistency for Large Language Model Generation
- Universal Self-Consistency (USC): Uses LLMs to select the most consistent answer among multiple candidates working in mathematical reasoning and code generation and unlike the original Self-Consistency, the method works in open-ended questions.
- This can be used as a more capabale component in the STaR-method, which generalizes with Q&A with open-ended answers, not only precise answers.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
- Medprompt: Generalist LLM using MedPrompt outperforms SOTA specialist model.
- Uses SOTA prompt method: CoT, Choice Shuffle and Self-Consistency prompting
- Introduces Choice Shuffle-technique, which inreases diversity of the reasoning paths.
Some intuitions about large language models
- Jason Wei Blog post / Presentation.
- Learning the relationship from Input to Output is as well Next-word prediction learning.
- Next-word prediction is massively multi-task learning.
- Identifies two types of LLM agents: "Agents-as-workers" and "Agents-as-coordinators".
System 2 Attention (is something you might need too)
- System 2 Attention (S2A): Generate interim user question and interim context from the original user input. Finally, generate the final answer by answering to the interim user question from the interim context.
- Reduces hallucination from irrelevant context by first defining the question and the context and this way separating irrelevant facts from impacting the response generation.
- Systematic review of research from Chain-of-Thought (CoT) to LLM Agents and identifies gaps in generalization, redundant interactions and customization and more.
A Language Agent for Autonomous Driving
- Agent-Driver: Uses LLM agent for human-like intelligence for autonomous driving.
- Tool library provides input for: detection, prediction, occupancy and mapping functions. Memory includes commonsense memory and Experience memory. There is apart historical trajectories and ego-states.
- The reasoning engine includes: CoT reasoning, Task planning, Motion planning and Self-Reflection. These lead to actions and again to environment update.
Digital Socrates: Evaluating LLMs through explanation critiques
- Digital Socrates: evaluates reasoning flaws: giving feedback on why and where?
Divergences between Language Models and Human Brains
- Reviews differences measured with MEG in human brain vs. language models.
- The study reveeals, that LLMs are less good at social/emotional intelligence and physical commonsense reasoning.
- Finetuning helps to align LLMs to act more in human brain-like manner.
AutoMix: Automatically Mixing Language Models
- AutoMix: Use a smaller LLM to generate initial response and uses Meta-Verifier to check the trustworthy in rough scale. If the answer is trustworthy then use the small LLM answer, otherwise consult a larger LLM.
- Uses Incremental Benefit Per Unit Cost (IBC) metric to asses effectiveness of this approach.
DeepThought: An Architecture for Autonomous Self-motivated Systems
- DeepThought: An architecture for cognitive language agents posing agency, self-motivation, and partly meta-cognition.
- Includes supervisor module, Deep Reinforcement Learning module, Attention Schema (long-term memory), Language/Auditory/Vision modules and Embedding store.
LLM Augmented Hierarchical Agents
- Hierchical agent uses LLM to evaluate, when to use specific skill to complete specific sub-level task with long horizon.
- The resulting model works without the need for a LLM after the training.
Prompt Engineering a Prompt Engineer
- Guide LLM to prompt engineer prompts automatically
- The metaprompt uses: prompt engineering tutorial, two-step task description, step-by-step reasoning template and context specification.
ADaPT: As-Needed Decomposition and Planning with Language Models
- ADaPT: Plans and decomposes dynamically complex tasks with LLMs, if the executor is not able to complete the task.
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
- RoboGen: Agent using LLMs to define new tasks to learn, create their simulation environments, train on them to acquire diverse & new skills.
- Agent includes: Task proposal, Scene generation, Training Supervision Generation & Skill learning.
Youtube. Adam Kalai presents "Recursive Self-improving Code Generation - talk 2.11.2023
- Adam Kalai talk on the "Self-Taught Optimizers (STOP): Recursively Self-Improving code generation", which is in essence attempts to build code for letting LLMs themselves improve (their) own code.
- I recommend to check this especially from safety-aspects on the point "sandbox-flag" and to better understand the
Plug-and-Play Policy Planner for Large Language Model Powered Dialogue Agents
- Introduces plug-and-play dialogue policy planner(PPDPP).
- Dialogues plans using Self-play with three LLM agents: one acting to achieve a goal like buying a product at cheaper price, second to negotiate as seller a higher price and a third LLM scoring performance as reward model.
SAGE: Smart home Agent with Grounded Execution
- SAGE (Smart home Agent with Grounded Execution).
- Device interaction: Interaction planner, Attribute retriever, API documentation retriever, Device disambiguity, Device command execution.
- Personalization: Long-term memory, User profile & Personalization tool.
- Includes Physical grounding such as light bulbs and External grounding (such as weather forecast) & Personalization.
Efficient Human-AI Coordination via Preparatory Language-based Convention
- HAPLAN: Human-AI coordination using Conventions. Humans communicate roles & tasksof individuals before starting a task to be completed. Humans create Conventions.
- Builds a Convention (an action-plan) to guide AI/human using task requirements, human preferences, number of agents and other information for a better understanding of tasks & responsibilities of each agent/human.
- Assigns sub-problems to own sessions. Convention is first confirmed with human.
Generating Sequences by Learning to Self-Correct
- Self-Correction: A generative LLM, which includes two modules: Generator and Corrector.
Autonomous Robotic Reinforcement Learning with Asynchronous Human Feedback
- Autonomously explores real world
- Guided Expliration for Autonomous Reinforcement learning (GEAR): approaches objective by meeting promising sub-goal close to final target (Goal Selector), but reachable from current position using current policy (Density model).
- Crowdsourced & Occasional comparative feedback regards user objective vs. available correct/incorrect states.
Towards A Natural Language Interface for Flexible Multi-Agent Task Assignment
- Programs constraints into task assignments system based on natural language using Multi-agent LLMs.
Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models
- DEEP: Uses agressive (truthfull) & conservative modes (to disguise) to play spy game to asses intelligence of LLMs to describe target word without stating explicitly the word.
Multi-Agent Consensus Seeking via Large Language Models
- Consensus within multi-agent reason mainly reason and change their numerical value state based on consensus strategy based on average strategy.
CompeteAI: Understanding the Competition Behaviors in Large Language Model-based Agents
- Studies competition of LLM agents and identifies research on competition of LLM agents, as important as co-operation.
- The initial advantage of a LLM agent leads to feedback creating cycle for Matthew's effect.
- LLM Agents can operate in competitive environment.
- LLM Agents learn to imitate and differentiate with other LLM agents.
PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
- PromptAgent: Optimizes prompts using planning algorithms such as MCTS.
- Creates intermediate prompts, updates them based on error feedback, simulates future rewards and searches higher reward paths.
- Prompts generated include: Domain knowledge, Task description, Term clarification, Solution Guidance,Exception handling, Priority & Emphasis, Formatting
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
- Key-value store for observation retrieval, parsed actions are executed by RCAgent or by Expert Agent.
Diverse Conventions for Human-AI Collaboration
- Mixed-play: generates diverse conventions (arbitrary solutions to reocurring cooperation problems) by randomly switching between self-play (maximize award) and cross-play (Minimize) actions to maxime mixed-play.
- CoMeDi (Cross-play optimized, Mixed-play enforced Diversity) algorithm is explained .
Woodpecker: Hallucination Correction for Multimodal Large Language Models
- Woodpecker: To extract key concepts, formulate questions and validate visual knowledge and generate visual claims using Multimodal Large Language Models (MLLMs) to control hallucinations in LLM responses.
In-Context Learning Creates Task Vectors
- Training data used with LLMs is compressed into task vectors within LLM. Task vectors are used in 18 tasks.
Instruct and Extract: Instruction Tuning for On-Demand Information Extraction
- On Demand Information Extraction (ODIE): Extracting information using LLMs from text to present it in structured tabular format.
Function Vectors in Large Language Models
- LLMs include Function Vectors (FCs) to trigger functions in different contexts.
LLM-Based Agent Society Investigation: Collaboration and Confrontation in Avalon Gameplay
- Explores social behaviour or LLMs in Avalon-game regards team working and other collaboration.
ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search
- ToolChain*: Uses A ∗ search algorithm to navigate an action space as a tree-like structure with LLM agent.
- Selects most promising path, Expand follow up actions in the selected path, Update the tree-structure.
Democratizing Reasoning Ability: Tailored Learning from Large Language Model
- Student LM takes an “exam” to gather mistakes it made. Teacher LM generates training data based on the mistakes. Teacher LM customizes each "exam" the feedback. Student LM learns to improve with self-reflection on its mistakes made and the new training data provided by the teacher LM. These steps are repeated until Student LM has reacher Teacher LM capability.
AgentTuning: Enabling Generalized Agent Abilities for LLMs
- AgentTuning: Improves LLM capability by Instruction Tuning to user tasks by using AgentInstruct-dataset to create AgentLM using AgentTuning.
Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale
- Language agent to automatically identify ans quantify extent of generated images.
- Planning and Reasoning. Tool usage: Intent understanding, Instruction generation, Instruction retrieval, Prompt optimization & Stereotype score generation.
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
- Set-of-Mark (SoM)-visual prompting technique to answer questions by partioning image into regions with different level of granularity and insert numbers for each region.
- Studies VLM model prompting techniques.
VeRA: Vector-based Random Matrix Adaptation
- VeRA
The next grand challenge for AI
- Foundational Agent: Agents, which scale in all three axis of: skills, embodiment and realities. If chatgpt was scaled with data, foundational agents are scaled with realities.
OpenAgents: An Open Platform for Language Agents in the Wild
- OpenAgents-platform: Data agent, Plugin/Tools and Web agent
- Automatic tool selection from over 200 tools
Improving Large Language Model Fine-tuning for Solving Math Problems
- Introduces multi-task sequential fine-tuning method, where solution generation is improved by including solution evaluation as part of the fine-tuning objective together with the generated solution to provide higher-quality guidance to solution generator.
- Quality and style of the step-by-step solutions used for fine-tuning impact model performance. Solution re-ranking and Majority voting used together are effective way to improve model performance with fine-tuning.
CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization
- A Continually Learning Generative Agent from Interactions (CLIN): Memory generator updates memory, Controller manages tasks and Executor converts it into actions towards the goal.
Theory of Mind for Multi-Agent Collaboration via Large Language Models
- LLM-based agent manages complex multi-agent collaboration task with performance level comparable with RL agent.
A Zero-Shot Language Agent for Computer Control with Structured Reflection
- Zero-shot agent plans executable actions in the environment and iteratively progresses by learning from mistakes using self-reflection and structured thoughts management.
- Better generalization, outperforms best iterative-planning agents
AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
- AgentCF: LLM agent-based recommender system with Use and Item Agents.
- User & Item Agents interact autonomously and the discrepancies between the two are stored in the memory to help guide better future recommendations.
Octopus: Embodied Vision-Language Programmer from Environmental Feedback
- Octopus: Uses Vision-Language Model with Reinforcement Learning from Environmental Feedback (RLEF).
- Generates action sequences and executable code.
MemGPT: Towards LLMs as Operating Systems
- MemGPT: OS-based design with LLM-processor managing its actual context and long term memory and uses functions to make changes and events to manage order of processing data.
- Promptor: Automatic prompt generation.
- Builds prompts based on: User goals, User Profiles, Data Profile, Contextual nformation & Output constraints
- System prompt includes: instructions, Actions, Facts and Examples.
Towards Robust Multi-Modal Reasoning via Model Selection
- Dynamic model selection by taking into account input & sub-task dependencies.
- Evidence about strong correlation between layers activated in Deep Language Models (DLMs) and human brain high-order language areas: auditory,syntactic and semantic areas.
- Brain and DLMs both process input into multi dimensional vector embeddings, processed as sequences taking into account the context.
- Identifies differences. One difference is, that human brain does not perform straightforward linear interpolation between the previous and current words, suggesting RNNs may better mimick human brain language processing. The other difference is, that humans do not learn only by reading text, but use data from multiple modalities.
- Diagnosis-of-Thought: Cognitive distortion detection through prompting: Subjective assessment, contrastive reasoning and schema analysis.
LangNav: Language as a Perceptual Representation for Navigation
- Uses BLIP to make imgae caption and DETR for object detection on image views to to obtain text descriptions, which a LLM agent uses to generate navigation instruction.
Towards Mitigating Hallucination in Large Language Models via Self-Reflection
- Self-Reflection: Introduces self-reflection prompting, similar to "Reflection"-prompting. Evaluates via LLM-loom, if the answer knowledge is factual enough and in second loop, if the answer is enough consistent.
- Human reviewers are asked to evaluate sentence in answer in case is generic, fact-inconsistent or fact-consistent. The user is as well asked to categorise answer to be question-inconsistent(inconsistent), tangential (consistent, but not on topic) or answerable (consistent and answers).
FireAct: Toward Language Agent Fine-tuning
- Fine-tuning LLMs with agent trajectories for better autonomous agents.
Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading
- MemWalker: navigates long-context iteratively and construct memory as treelike structure.
Crystal: Introspective Reasoners Reinforced with Self-Feedback
- Introspective reasoning of the knowledge.
Self-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
- PathCrawling: Crawl all paths leading to reward (train LLM with these paths) and Evaluate generality to unseen task. Continue crwaling most general paths.
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
- Language Agents Tree Search (LATS): Self-Refine, Memory, Reasoning, Decision Making & Planning.
- Uses multiple reasonining paths and learns from experience by integrating external feedback & self-reflection.
BrainSCUBA: Fine-Grained Natural Language Captions of Visual Cortex Selectivity
- BrainScuba (Semantic Captioning Using Brain Alignments): LLM generates interpretable captions.
- Aligns brain activity pattern with semantic content to generate captions to explain how brain processes visual information.
- Collects brain imaging data fMRI when human views visual stimuli and uses BERT to obtain semantic reprensentation in natural language, which is based on alignment process. This process maps images to voxel-wise brain activations.
Agent Instructs Large Language Models to be General Zero-Shot Reasoners
- AgentInstruct: generates instructions for th problem and then solves it using these instructions, improving the Chain of Thought (CoT) zero-shot reasoning.
- Characteristics of Autonomous Agents: Goal-driven task management, Intelligent Agents with LLMs, Multi-Agents collaboration, Context interaction, Balancing Autonomy vs. Alignment.
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
- DSPy programs (think Langchain as cmparison) help create LLM pipelines, which can outperform few-shot prompting techniques.
- Help improve mathe world problems or answering complex questions and manage chaining / loops.
Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation
- Self-Taught Optimizer (STOP): Ask LLM to improve initial program by providing improvement candidates and then output best solution.
Lyfe Agents: Generative agents for low-cost real-time social interactions
- LyfeAgents Brain: Sensory processing, Internal states, Self-monitor, Action selection and Memory.
- Internal states are text based: current goal, memory, recent events and sensory inputs.
- Cognitive controller selects high-level actions. Action model selects actions until termination condition is reached.
- Self-monitoring maintains and emphasizes recent and novel events towards agent goals
- Memories are clustered and summarized before moving them to long-term storage (vector database)
EcoAssistant: Using LLM Assistant More Affordably and Accurately
- EcoAssistant: Enables LLM agent to converse with code executor to iteratively produce answers based on code produced. Hierachical structure, where cheaper and weaker LLM is used before trying the stronger and expensive LLM.
- Surpasses GPT-4 10% in performance with 50% less cost.
Large Language Models as Analogical Reasoners
- LLM self-generates examples/knowledge related to the task.
Conceptual Framework for Autonomous Cognitive Entities
- Conceptual framework for Autonomous entities.
OceanGPT: A Large Language Model for Ocean Science Tasks
- DoInstruct (Domain Instruction): Automatically gathers large amount of domain specific instruction data for multi-agent collaboration.
- Domain Instruction generation: Agents used as experts in each topic. Instructions are augmented rapidly through agent collaboration, which are annotated and finally inspected for high quality fine-tuning dataset.
Enabling Language Models to Implicitly Learn Self-Improvement
- ImPlicit Self-ImprovemenT (PIT)-framework: introduces self-improvement, where LLMs self-improve its response quality with human preference data without extensive human annotation.
SmartPlay : A Benchmark for LLMs as Intelligent Agents
- SmartPlay: a benchmark to test LLM-based agents from 9 perspectives.
- Tests: Reasonning with object dependencies, planning ahead, spatial reasoning, learning from history, and understanding randomness.
GRID: A Platform for General Robot Intelligence Development
- GRID: General Robot Intelligence Development
- Solves complex tasks using simulatiom and/or real-world data
- Task specification, robot configuration and sensor/API.
- Foundation Mosaic: a neural architecture.
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
- RoleLLM: Role-profile constructor, Context-based Instruction generarion, Role-based Prompting(RoleGPT), Role-conditioned Instruction-tuning.
AutoAgents: A Framework for Automatic Agent Generation
- AutoAgents: Planner agent receives user input and converts it into a plan. Multiple agent roles take actions in this plan to convert into a result.
- Observers: Observer agent reviews, if the created agent roles meet the requirements. Plan observer agent reviews, if the plan meets expectations. Action observer reviews, if the action response meets expectations.
- Includes drafting stage (with agent observer and plan observer agents) and Execution stage (with action observer).
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
- Motif: Trains a reward fucntion/model from pairs of gameplay captions and LLM observations of these game actions. Then train an agent using RL with the reward model.
- Diverse behaviours triggered with the LLM improve in performance in specific domain: for example Gold Collector collects more cold.
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
- Promptbreeder uses thinking styles and mutation-prompts and is able to improve mutation/task prompts.
Let's reward step by step: Step-Level reward model as the Navigators for Reasoning
- Heuristic Greedy Search for Process-Supervised Reward Model (HGS-PRM): each new reasoning step generated by the LLM is evaluated by the reward model, if to accept the reasoning step or generate a new one until the reasoning path is identified.
- Creates PRM-Code dataset using Code-LLaMA-7B using Mutating testing-technique.
Natural Language based Context Modeling and Reasoning with LLMs: A Tutorial
- LLM-driven Context-aware Computing (LCaC) approach.
You only look at the screens: Multimodal Chain-of-Action Agents
- Multimodal Chain-of-Actions Agents (Auto-UI) interacts directly with the UI
- Chain-ofAction technique using series of action histories and future action plans.
MindAgent: Emergent Gaming Interaction
- MindAgent: Planning skills and Tools use(Agent location, Tool state, Agent holdings, Pending dishes, Timer), LLM dispatcher, Memory history (Environment, Agent State, Actions and Feedback) and Action module(Controller, Human actions, Action validator, Action Types/Patterns/Names).
- Introduces CuisineWorld-benchmark, where multiple agents play game simultaneously through multi-agent collaboration.
The Rise and Potential of Large Language Model Based Agents: A Survey
- A conceptual framework for LLM-based agents with three components brain, perception, and action.
Agents: An Open-source Framework for Autonomous Language Agents
- Multi-agent: Planning, memory, tool usage, multi-agent communication & symbolic control.
- Open source library.
Physically Grounded Vision-Language Models for Robotic Manipulation
- PhysObjects dataset for physical grounding.
- VLMs with PhysObjects improves its understanding on physical objects.
- Improves task success rate.
Life-inspired Interoceptive Artificial Intelligence for Autonomous and Adaptive Agents
- Interoceptive AI: monitoring own internal state of the artificial agent.
- Sebastien Bubeck explains the insights from the reserch on Phi-1 regards coding tasks and Phi-1.5. regards reasoning tasks and the models being able to outperform 1000 times larger LLMs.
- The talk highlights, that the key ingredients on Textbook-like training data and then giving then giving Exercises.
- Explains the the key ingredient in "Textbooks are all you need"-paper regards the data, is largerly based on TinyStories-paper, which dataset was used to train a high performing model to generate fluent and consistent stories in English language.
Unleashing the Power of Graph Learning through LLM-based Autonomous Agents
- AutoGraph procedure: data, configuration, searching and tuning agents.
RecMind: Large Language Model Powered Agent For Recommendation
- RecMind: a recommender focused LLm agent with reasoning, planning to sub-tasks, memory & tools.
A Survey on Large Language Model based Autonomous Agents
- Systematic review of LLM based Autonomous Agents.
- Use cases and evaluation strategies and future use cases.
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
- AgentVerse: multi-agent collaborarion and individual agents social bjeaviours.
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
- Graph-of-Thoughts (GoT): Reasoning with LLM using graph-structure with intermediate steps.
- Introduces Volume-of-Tought metric to inform the scope of information carried by the LLM output.
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
- AutoGen: An open source framework, where LLM agents converse with other LLM agents either one or many, chat with humans and use tools.
- LLM agents are able to create new chats with other LLM agents.
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
- Improves math reasoning with Reinforcement Learning from Evol-Instruct Feedback (RLEIF): Upward and Downward evolution improve instructions by making questions easier or harder based on their difficulty level.
Reinforced Self-Training (ReST) for Language Modeling
- Introduces Reinforced Self-Training (ReST).
- Grow step generates data from LLM, Improve step uses this filtered data to fine-tune the LLM. Repeat.
Never-ending Learning of User Interfaces
- Never-ending UI Learner: automatically installs apps from an appstore and crawls them to learn difficult training examples
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
- Proposes Rejection sampling Fine-Tuning (RFT), which generates reasoning and collects correct ones to augment as fine-tuning dataset.
WebArena: A Realistic Web Environment for Building Autonomous Agents
- An environment to test Autonomous agents in an environment with tools, external knowledge.
- Addresses LLM training data to be "text-book-like": clear, self-contained, instructive, and balanced. The method is used in Phi-models.
BuboGPT: Enabling Visual Grounding in Multi-Modal LLMs
- BuboGPT: Uses Vicuna LLM by receiving text input inserting together visual and audio inputs separately with Q-former. The Vicuna output is then processed using SAM-model for visual grounding.
- Achieves coherent and grounded descriptions
Communicative Agents for Software Development
- ChatDev: Define task and automatically generate SW designing, coding, testing, and documentation using "Chat Chains", where LLM-based chats include different roles for each sub-task: CEO, programmer, CTO etc.
- Includes role-assignment, memory and self-reflection.
xTrimoPGLM: Unified 100B-Scale Pre-trained Transformer for Deciphering the Language of Protein
- Protein Language Model: xTrimoPGLM.
Large Language Models Understand and Can be Enhanced by Emotional Stimuli
- EmotionPrompt: adds to prompt an emotional stimuli, which improves performance by 10.9%.
- An example of an emotional stimuli is to state that the work is important for career.
- Lilian Weng from OpenAI article / blog post
- Covers Planning, Memory and Tool usage of LLM powevered agents
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
- Builds multi-agent simulation environment to generate dataset of using many real world apis.
- Small models can achieve comparable performance to larger models on tool usage.
Enabling Intelligent Interactions between an Agent and an LLM: A Reinforcement Learning Approach
- When2Ask: RL agent, which learns when to query LLM for high-level plans to complete a task.
- Planner, Actor and Mediator.
SELFEVOLVE: A Code Evolution Framework via Large Language Models
- Generates intermediate code based on input prompt.
- Use LLM to act as expert programmer to debug the generated code by receiving errors from Python interpreter.
Prompt Sapper: LLM-Empowered Software Engineering Infrastructure for AI-Native Services
- Human AI collaborative intelligence methodology & technical practices, where the idea is not to have "full Auto-GPT" from user input to direct resolution by LLM, but rather human reviews steps between.
- Useer inputs objective, LLM asks clarification. Use then User adds clarifications and LLM constructs AI chain for human to review. Finally LLM executes the AI chain with user acceptabnce tests.
Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions
- Auto-GPTs outperforms supervised state-of-the-art Imitiation Learning (IL) models with GPT4 in WebShop- and ALFWorld-benchmarks in unknown external environments.
- Additional opinions algorithm improves performance, which takes into account additional opinions from external expert models.
- MathChat: Describes a solid conversational MATH problem solving in four step process.
- Describes the prompts used.
Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Large Language Models
- Graph-of-Thought (GoT) reasoning: To model human thought process as graph instead of chain to improve LLM reasoning capability.
- Uses low-quality LM to generate High-quality dataset (more diverse and more effective for generalization in unseen domains) to train a high quality model: 770 million parameter model outperforms GPT-3 in multiple tasks evaluated by humans.
Voyager: An Open-Ended Embodied Agent with Large Language Models
- Voyager: open-ended embodied agent with LLM
Reasoning with Language Model is Planning with World Model
- RAP (Reasoning via Planning): Uses LLM as both world model and reasoning LLM-agent. Integrates MCTS search planning algorithm.
- Incrementally generates reasoning tree with LLM in domains of plan generation, math reasoning and logical inference.
Gorilla: Large Language Model Connected with Massive APIs
- Gorilla is a retrieve-aware finetuned LLaMA-7B model for API calls using self-instruct to generate Instruction-API pairs.
Think Outside the Code: Brainstorming Boosts Large Language Models in Code Generation
- Brainstorm: uses brainstorming step to generate and select diverse thoughts in code generation.
- Uses three steps: brainstorming, thought selection (trains a thought ranker for this) and writing code.
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Tree of Thoughts (ToT)-technique makes decisions using multiple different reasoning paths, self-evaluating choices to decide next action with ability to look back/forward for global decisions.
Mobile-Env: Building Qualified Evaluation Benchmarks for LLM-GUI Interaction
- BabyCatAGI: a modified BabyAGI by replacing task manager in BabyBeeAGI with task creation agent running once.
- Uses Intelligent Agent Tool to combines tools to extract only relevant information to next step such as looping web search and scraping results to pull only specific part to another task.
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
- A breakthrough paper, where synthetic data generated by Teacher-Student LLM is used to train a high-performing model to generate fluent and consistent English stories.
- Demonstrated the effectiveness of synthetic data in smaller LLMs challenging large SOTA models in domain of English language.
- Uses GPT-4 to grade content generated by the models as if created by student and being graded by the GPT-4 teacher.
ImageBind: One Embedding Space To Bind Them All
- ImageBind: a joint embedding space for images, text, audio, depth, thermal and IMU data modalities-
Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
- Introduces Visual Chain of Thought (VCoT) for data augmentation, where between reasoning steps multimodal data is infilled to obtain better reasoning results.
BabyBeeAGI: Task Management and Functionality Expansion on top of BabyAGI
- BabyBeeAGI: a modified from BabyAGI tracking statuses of tasks, task dependencies, identification of required new tasks, assigning tools and results in json-format.
["Inside OpenAI Entire Talk" by Stanford eCorner
- Interview of Ilya Sustskever, where defined a way to perform "a consciousness test" from a very controlled dataset, see "minute 15".
- LLM agent self-help with LLM to complete IGLU tasks using clarifying questions.
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
- RAFT-finetuning: Samples batch lf data from LLM, reward function scores them, high reward examples are filtered as data to finetune the LLM.
ChemCrow: Augmenting large-language models with chemistry tools
- Uses LLM and chemistry tools to plan and execute different chemical tasks.
- Tools include web and literature search, Python, human-tool to interact with the end user and various molecule tools, safety tools and chemical reaction tools.
Teaching Large Language Models to Self-Debug
- The model generates new code together with code explanation. The code is then executed and this executed code is sent back as feedback together with the code explanation. This feedback
ChatPipe: Orchestrating Data Preparation Program by Optimizing Human-ChatGPT Interactions
- ChatPipe - Iterative, data preparation program with ChatGPT using 1. Operation Recommendation, 2. Program generation, 3. Version management.
- Recommends next data preparation opration. Easily roll-back to previous program for version control.
Generative Agents: Interactive Simulacra of Human Behavior
- Enable believable human behavior: observation, planning, and reflection.
- An agent wants to throw a Valentine’s Day party. The agents autonomously spread invitations, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time.
- GPTeam is inspired by this approach.
CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society
- CAMEL attempts to facilitate autonomous cooperation among communicative agents through role-playing framework.
- The approach manages complete tasks with minimal human input.
Self-Refine: Iterative Refinement with Self-Feedback
- Self-Refine refers to Iterative refinement with self-feedback: use the LLM to get Feedback to original output, which is passed back to LLM to Refine a new output.
- The concept is best understood here in the blog by : Self-Refine: Iterative Refinement with Self-Feedback with GIFs and code examples.
- Improves base-model performance in tasks like math reasoning and code generation.
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace
- A LLM (such as ChatGPT) accesses HuggingFace community to look AI models to complete the given task.
- It can read multi modalities by outsourcing tasks like image recognition to the specific image model.
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
- Dialog-Enabled Resolving Agents (DERA) uses two roles: Researcher and Decider to perform discussion between these two agents.
- Researcher role processes information and Decider role uses judgement.
TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
- Multimodal conversational foundation model (MCFM). MCFM generates a textual solution outline, then API selector chooses most relevant API from collection of APIs (with API name, parameter list, description, usage example and example when combining it with another API).
- MCFM generates action code using recommended API and the API call is executed. Finally, output is provided back to developer.
Task-driven Autonomous Agent Utilizing GPT-4, Pinecone, and LangChain for Diverse Applications
- Task-driven autonomous agent, with vector database and Langchain. BabyAGI includes: Execution, creation and prioritization
- Takes objective, pulls an item from task queue and moves it to execution agent with access to memory.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
- Raises an argument, that GPT-4 model capabilities should be reviewed as an early and incomplete version of Artificial General Intelligence (AGI) systems due the multiple metrics comparing against human level-performance.
- Raises the argument, that LLMs need to move beyond "next-word prediction" to overcome linear reasoning limitation, which often is possible to solve as incremental tasks with few iterations.
Reflexion: Language Agents with Verbal Reinforcement Learning
- Reflexion agents reflect on task feedback, use it from memory to make better decisions and new attempts.
Cost-Effective Hyperparameter Optimization for Large Language Model Generation Inference
- EcoOptiGen: Hyperparameter tuning of LLMs.
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Large Language Models Can Self-Improve
- Demonstrates LLM is able to Self-Improve with only unlabeled datasets using CoT and Self-Consistency Prompting and then fine-tune the LLM using these self-generated solutions as target outputs.
- This research by Google, effectively performs Self-Recursive Learning not only during Inference time (such as CoT or In-Context Learning alone), but training as well.
Emergent Abilities of Large Language Models
- Defines officially the term "Emergent Abilities": "An ability is emergent if it is not present in smaller models but is present in larger models."
- Emergent abilities were detected already with GPT-3, but here its clearly defined as ability detected only after specific scale.
- Identifies a list of Emerging abilities not detected in specific smaller model, but identfied in a larger model.
- I like the paper, because increasing number of task patterns are learned using single learning objective of next-word prediction as scale increases.
- Gato: A multi-modal, multi-task, multi-embodiment generalist policy agent.
- Learns to play Atari, caption images, chat, stack blocks with robot arm, etc.
- Includes text tokens, image patch tokens, agent timesteps and action tokens.
- Argues, that "a generalist agent that can adapt to new embodiments and learn new tasks with few data."
Large-Scale Retrieval for Reinforcement Learning
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Retrieval-Augmented Reinforcement Learning
Evaluating Multimodal Interactive Agents
Intra-agent speech permits zero-shot task acquisition
How to Learn and Represent Abstractions: An Investigation using Symbolic Alchemy
Rapid Task-Solving in Novel Environments
A Unified, Scalable Framework for Neural Population Decoding
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Deep learning, reinforcement learning, and world models
- Reviews Deep learning, Reinforcement learning and World models.
- Claims humans use World model as simulators in the brain, learned through senso-motory interaction with the environment. It is possible to learn world model using deep generative models.
STaR: Bootstrapping Reasoning With Reasoning
- Introduces the concept: "Self-Taught Reasoner" (STaR) or *, where LLM improves its reasoning by learning from its own reasoning: model is asked to generate rationalizations to questions. If rationalization derives wrong answer to question, the rationalization is repeated by giving it as well the correct answer. All rationalizations leading to correct answer are used for fine-tuning the LLM model. This process is repeated and each iteration improves the LLMs capability of reasoning.
- The paper does not refer to Self-Recursive Learning, but we could argue it as an example of this process in the context of reasoning.
Self-Consistency Improves Chain of Thought Reasoning in Language Models
- Enables reasoning with LLMs using CoT and Self-Consistency, where multiple, different reasoning paths are used to vote the most consistent answer.
- Improves reasoning and math problem solving.
Chain of Hindsight Aligns Language Models with Feedback
- Chain of Hindsight (CoH): Humans learn from feedback, which is converted sequences of sentences, ranked with human preferences and used to fine-tune the LLM.
Shared computational principles for language processing in humans and deep language models
- Provides evidence about three computational principles, shared both by Deep Language Models (DLMs) and human brain to process language.
- The three principles are: continuous next-word prediction, contextual embeddings and surprise prediction error.
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Defines Chain-of-Thought (CoT).
- CoT is one Emerging Ability not present in smaller models, but present in larger models.
- CoT can be seen as Self-Recursive Learning, where the LLM improves its own output by having LLM use intermediate steps to solve complex task.
- The approach effectively demonstrates the LLMs capability to perform Self-Recursive Learning, altough its not integrated back as training data of the model.
- Defines Language Agent.
A* Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
- Q* search algorithm: Better version of A* search algoirthm, because reduces computation time and number of nodes to be computed.
Language Models are Few-Shot Learners
- Applies first-time the term of LLMs ability to learn a task from contextual information: "In-Context Learning".
- This ability is another example of Self-Recursive Learning, altough its not integrated back as training data of the model.
- This paper as well identified the capability of LLMs to learn multiple tasks by having been only trained to predict the next word. See Jason Wei´s presentation included below, where he covers the "Massively Multi-task learning" of LLMs and I think it helps to gain better insight about LLMs, rather than thinking them as simply "statistical models".
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Defines Retrieval-Augmented Generation (RAGs).
- Reward is sufficient to drive intelligent behaviours instead of requiring special formulations.
- Agents could learn to obtain various intelligent behaviours through trial and error experiences to maximize reward.
- Sophisticated intelligence may emerge from simple objective, think what an animal is able to learn to do just by being in hungry.
Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms
- MARL: Introduces Multi-Agent Reinforcement Learning (MARL).
- Human mind consists according to Minsky, from Cloud of Resources turnable on/off.
- Important theory, because LLM agents can construct such resources, observed in a human brain, altough years after this theory.
Is it an Agent, or Just a Program?: A Taxonomy for Autonomous Agents.
- "Autonomous agent is a system situated within and a part of an environment that senses that environment and acts on it, over time, in pursuit of its own agenda and so as to effect what it senses in the future."
- Definition includes: 1. Operate within an environment, 2. Sense and Act, 3. Over time, 4. Control its own agenda (Autonomous).
- Studies the multiple previous definitions of Agents / Autonomous Agents, although the perspective is +27 years ago and prior to LLMs.
Prediction and Adaptation in an Evolving Chaotic Environment
- Defines the concept of "Predictive Agent" as adaptive predictors.
A Learning Algorithm that Mimics Human Learning
- Reviews Artificial Agents learning like humans.
A formal Basis for the Heuristic Determination of Minimum Cost Paths
- A* search algorithm.
- Defines the A* search algorithm for the first time, widely used in RL as planning algorithm.
How to cite my work?
@misc{MaattaAutonomousAgents2023,
author = {Teemu Maatta},
title = {Autonomous Agents},
year = {2023},
howpublished = {\url{https://github.com/tmgthb/Autonomous-Agents}},
note = {Accessed: YYYY-MM-DD}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Autonomous-Agents
Similar Open Source Tools

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

agentsociety
AgentSociety is an advanced framework designed for building agents in urban simulation environments. It integrates LLMs' planning, memory, and reasoning capabilities to generate realistic behaviors. The framework supports dataset-based, text-based, and rule-based environments with interactive visualization. It includes tools for interviews, surveys, interventions, and metric recording tailored for social experimentation.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.
AgentGym-RL
AgentGym-RL is a framework designed to train Long-Long Memory (LLM) agents for multi-turn interactive decision-making through Reinforcement Learning. It addresses challenges in training agents for real-world scenarios by supporting mainstream RL algorithms and introducing the ScalingInter-RL method for stable optimization. The framework includes modular components for environment, agent reasoning, and training pipelines. It offers diverse environments like Web Navigation, Deep Search, Digital Games, Embodied Tasks, and Scientific Tasks. AgentGym-RL also supports various online RL algorithms and post-training strategies. The tool aims to enhance agent performance and exploration capabilities through long-horizon planning and interaction with the environment.

siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.
intro-llm-rag
This repository serves as a comprehensive guide for technical teams interested in developing conversational AI solutions using Retrieval-Augmented Generation (RAG) techniques. It covers theoretical knowledge and practical code implementations, making it suitable for individuals with a basic technical background. The content includes information on large language models (LLMs), transformers, prompt engineering, embeddings, vector stores, and various other key concepts related to conversational AI. The repository also provides hands-on examples for two different use cases, along with implementation details and performance analysis.

MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.

Slow_Thinking_with_LLMs
STILL is an open-source project exploring slow-thinking reasoning systems, focusing on o1-like reasoning systems. The project has released technical reports on enhancing LLM reasoning with reward-guided tree search algorithms and implementing slow-thinking reasoning systems using an imitate, explore, and self-improve framework. The project aims to replicate the capabilities of industry-level reasoning systems by fine-tuning reasoning models with long-form thought data and iteratively refining training datasets.
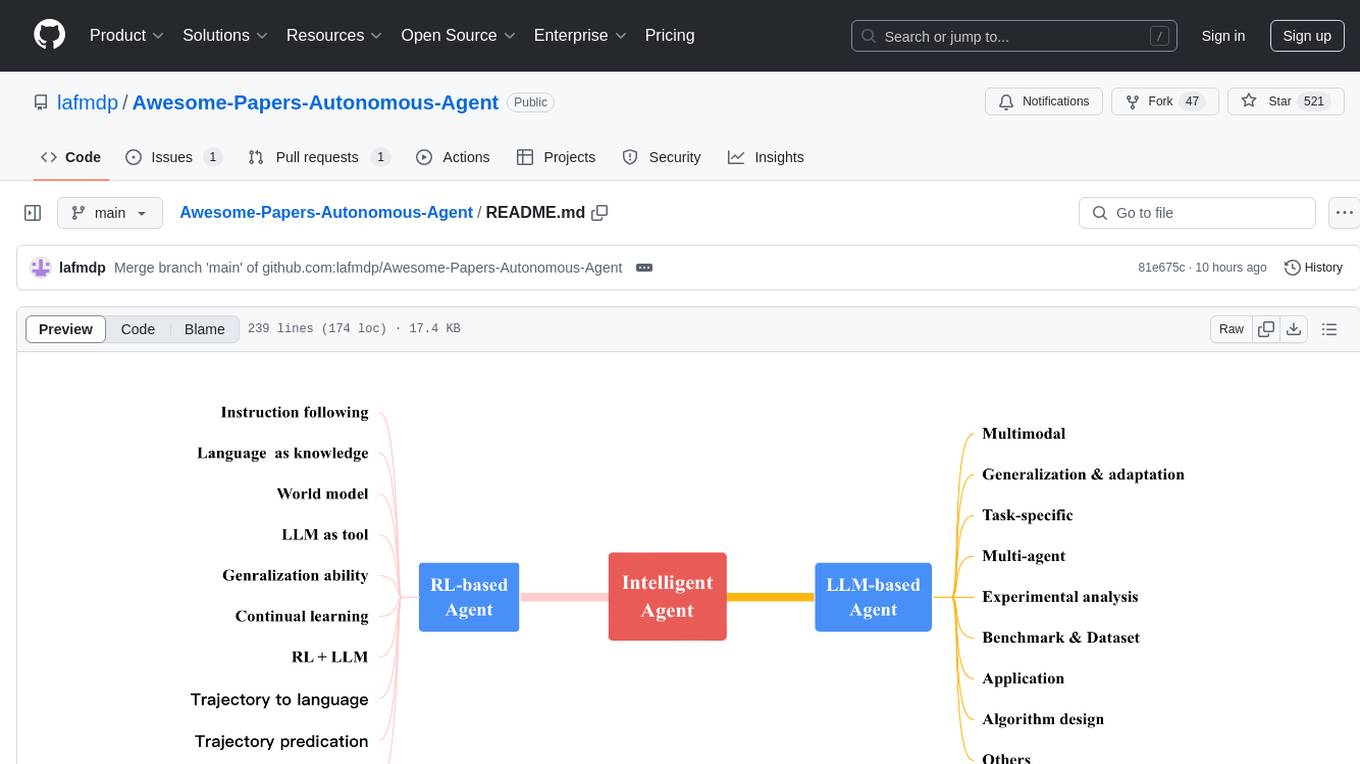
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

nextpy
Nextpy is a cutting-edge software development framework optimized for AI-based code generation. It provides guardrails for defining AI system boundaries, structured outputs for prompt engineering, a powerful prompt engine for efficient processing, better AI generations with precise output control, modularity for multiplatform and extensible usage, developer-first approach for transferable knowledge, and containerized & scalable deployment options. It offers 4-10x faster performance compared to Streamlit apps, with a focus on cooperation within the open-source community and integration of key components from various projects.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.
LAMBDA
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.