
Whisper-TikTok
From AI tools to TikTok video creation using FFMPEG, Microsoft Edge read aloud and OpenAI Whisper model
Stars: 148
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.
README:
- Introduction
- Video (demo)
- How it works?
- Web App (Online)
- Streamlit Web App
- Local Installation
- Dependencies
- Web-UI (Local)
- Command-Line
- Usage Examples
- Additional Resources
- Code of Conduct
- Contributing
- Upcoming Features
- Acknowledgments
- License
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Harnessing the capabilities of OpenAI's Whisper model, Whisper-TikTok effortlessly generates an accurate transcription from provided audio files, laying the foundation for the creation of mesmerizing TikTok videos through the utilization of FFMPEG. Additionally, the program seamlessly integrates the Microsoft Edge Cloud Text-to-Speech (TTS) API to lend a vibrant voiceover to the video. Opting for Microsoft Edge Cloud TTS API's voiceover is a deliberate choice, as it delivers a remarkably natural and authentic auditory experience, setting it apart from the often monotonous and artificial voiceovers prevalent in numerous TikTok videos.

https://github.com/MatteoFasulo/Whisper-TikTok/assets/74818541/68e25504-c305-4144-bd39-c9acc218c3a4
Employing Whisper-TikTok is a breeze: simply modify the video.json. The JSON file contains the following fields:
-
series: The name of the series. -
part: The part number of the video. -
text: The text to be spoken in the video. -
outro: The outro text to be spoken in the video. -
tags: The tags to be used for the video.
Summarizing the program's functionality:
Furnished with a structured JSON dataset containing details such as the series name, video part number, video text and outro text, the program orchestrates the synthesis of a video incorporating the provided text and outro. Subsequently, the generated video is stored within the designated
outputfolder.
Details
The program conducts the sequence of actions outlined below:
- Retrieve environment variables from the optional .env file.
- Validate the presence of PyTorch with CUDA installation. If the requisite dependencies are absent, the program will use the CPU instead of the GPU.
- Download a random video from platforms like YouTube, e.g., a Minecraft parkour gameplay clip.
- Load the OpenAI Whisper model into memory.
- Extract the video text from the provided JSON file and initiate a Text-to-Speech request to the Microsoft Edge Cloud TTS API, preserving the response as an .mp3 audio file.
- Utilize the OpenAI Whisper model to generate a detailed transcription of the .mp3 file, available in .srt format.
- Select a random background video from the dedicated folder.
- Integrate the srt file into the chosen video using FFMPEG, creating a final .mp4 output.
- Upload the video to TikTok using the TikTok session cookie. For this step it is required to have a TikTok account and to be logged in on your browser. Then the required
cookies.txtfile can be generated using this guide available here. Thecookies.txtfile must be placed in the root folder of the project. - Voila! In a matter of minutes, you've crafted a captivating TikTok video while sipping your favorite coffee ☕️.
There is a Web App hosted thanks to Streamlit which is public available, just click on the link that will take you directly to the Web App.
Whisper-TikTok has undergone rigorous testing on Windows 10, Windows 11 and Ubuntu 23.04 systems equipped with Python versions 3.8, 3.9 and 3.11.
If you want to run Whisper-TikTok locally, you can clone the repository using the following command:
git clone https://github.com/MatteoFasulo/Whisper-TikTok.gitHowever, there is also a Docker image available for Whisper-TikTok which can be used to run the program in a containerized environment.
To streamline the installation of necessary dependencies, execute the following command within your terminal:
pip install -U -r requirements.txtIt also requires the command-line tool FFMPEG to be installed on your system, which is available from most package managers:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (<https://brew.sh/>)
brew install ffmpeg
# on Windows using Chocolatey (<https://chocolatey.org/>)
choco install ffmpeg
# on Windows using Scoop (<https://scoop.sh/>)
scoop install ffmpegPlease note that for optimal performance, it's advisable to have a GPU when using the OpenAI Whisper model for speech recognition. However, the program will work without a GPU, but it will run more slowly. This performance difference is because GPUs efficiently handle fp16 computation, while CPUs use fp32 or fp64 (depending on your machine), which are slower.
To run the Web-UI locally, execute the following command within your terminal:
streamlit run app.py --server.port=8501 --server.address=0.0.0.0To run the program from the command-line, execute the following command within your terminal:
python main.py Whisper-TikTok supports the following command-line options:
python main.py [OPTIONS]
Options:
--model TEXT Model to use [tiny|base|small|medium|large] (Default: small)
--non_english Use general model, not the English one specifically. (Flag)
--url TEXT YouTube URL to download as background video. (Default: <https://www.youtube.com/watch?v=intRX7BRA90>)
--tts TEXT Voice to use for TTS (Default: en-US-ChristopherNeural)
--list-voices Use `edge-tts --list-voices` to list all voices.
--random_voice Random voice for TTS (Flag)
--gender TEXT Gender of the random TTS voice [Male|Female].
--language TEXT Language of the random TTS voice(e.g., en-US)
--sub_format TEXT Subtitle format to use [u|i|b] (Default: b) | b (Bold), u (Underline), i (Italic)
--sub_position INT Subtitle position to use [1-9] (Default: 5)
--font TEXT Font to use for subtitles (Default: Lexend Bold)
--font_color TEXT Font color to use for subtitles in HEX format (Default: #FFF000).
--font_size INT Font size to use for subtitles (Default: 21)
--max_characters INT Maximum number of characters per line (Default: 38)
--max_words INT Maximum number of words per segment (Default: 2)
--upload_tiktok Upload the video to TikTok (Flag)
-v, --verbose Verbose (Flag)
If you use the --random_voice option, please specify both --gender and --language arguments. Also you will need to specify the --non_english argument if you want to use a non-English voice otherwise the program will use the English model. Whisper model will auto-detect the language of the audio file and use the corresponding model.
- Generate a TikTok video using a specific TTS model and voice:
python main.py --model medium --tts en-US-EricNeural- Generate a TikTok video without using the English model:
python main.py --non_english --tts de-DE-KillianNeural- Use a custom YouTube video as the background video:
python main.py --url https://www.youtube.com/watch?v=dQw4w9WgXcQ --tts en-US-JennyNeural- Modify the font color of the subtitles:
python main.py --sub_format b --font_color #FFF000 --tts en-US-JennyNeural
- Generate a TikTok video with a random TTS voice:
python main.py --random_voice --gender Male --language en-US- List all available voices:
edge-tts --list-voicesContributed by @duozokker
reddit2json is a Python script that transforms Reddit post URLs into a JSON file, streamlining the process of creating video.json files. This tool not only converts Reddit links but also offers functionalities such as translating Reddit post content using DeepL and modifying content through custom OpenAI GPT calls.
reddit2json is designed to process a list of Reddit post URLs, converting them into a JSON format that can be used directly for video creation. This tool enhances the video creation process by providing a faster and more efficient way to generate video.json files.
Here is the detailed README for reddit2json which includes instructions for installation, setting up the .env file, example calls, and more.
Please review our Code of Conduct before contributing to Whisper-TikTok.
We welcome contributions from the community! Please see our Contributing Guidelines for more information.
- Integration with the OpenAI API to generate more advanced responses.
- Generate content by extracting it from reddit https://github.com/MatteoFasulo/Whisper-TikTok/issues/22
- We'd like to give a huge thanks to @rany2 for their edge-tts package, which made it possible to use the Microsoft Edge Cloud TTS API with Whisper-TikTok.
- We also acknowledge the contributions of the Whisper model by @OpenAI for robust speech recognition via large-scale weak supervision
- Also @jianfch for the stable-ts package, which made it possible to use the OpenAI Whisper model with Whisper-TikTok in a stable manner with font color and subtitle format options.
Whisper-TikTok is licensed under the Apache License, Version 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Whisper-TikTok
Similar Open Source Tools
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.

FunClip
FunClip is an open-source, locally deployed automated video clipping tool that leverages Alibaba TONGYI speech lab's FunASR Paraformer series models for speech recognition on videos. Users can select text segments or speakers from recognition results to obtain corresponding video clips. It integrates industrial-grade models for accurate predictions and offers hotword customization and speaker recognition features. The tool is user-friendly with Gradio interaction, supporting multi-segment clipping and providing full video and target segment subtitles. FunClip is suitable for users looking to automate video clipping tasks with advanced AI capabilities.
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
LLPlayer
LLPlayer is a specialized media player designed for language learning, offering unique features such as dual subtitles, AI-generated subtitles, real-time OCR, real-time translation, word lookup, and more. It supports multiple languages, online video playback, customizable settings, and integration with browser extensions. Written in C#/WPF, LLPlayer is free, open-source, and aims to enhance the language learning experience through innovative functionalities.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.
ova
Outrageous Voice Assistant is a fully-local voice assistant demo with a simple FastAPI backend and HTML front-end. It showcases running AI models locally without sending data to the internet. The tool captures user audio, transcribes it, processes it through language models, and generates a text-to-speech response, all locally. It includes voice cloning capabilities and aims to demonstrate the ease of setting up a local AI system on affordable hardware, while raising ethical considerations. The project is a proof-of-concept for educational and experimental purposes, emphasizing the potential risks of voice cloning technology.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.
Loyal-Elephie
Embark on an exciting adventure with Loyal Elephie, your faithful AI sidekick! This project combines the power of a neat Next.js web UI and a mighty Python backend, leveraging the latest advancements in Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) to deliver a seamless and meaningful chatting experience. Features include controllable memory, hybrid search, secure web access, streamlined LLM agent, and optional Markdown editor integration. Loyal Elephie supports both open and proprietary LLMs and embeddings serving as OpenAI compatible APIs.
For similar tasks
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
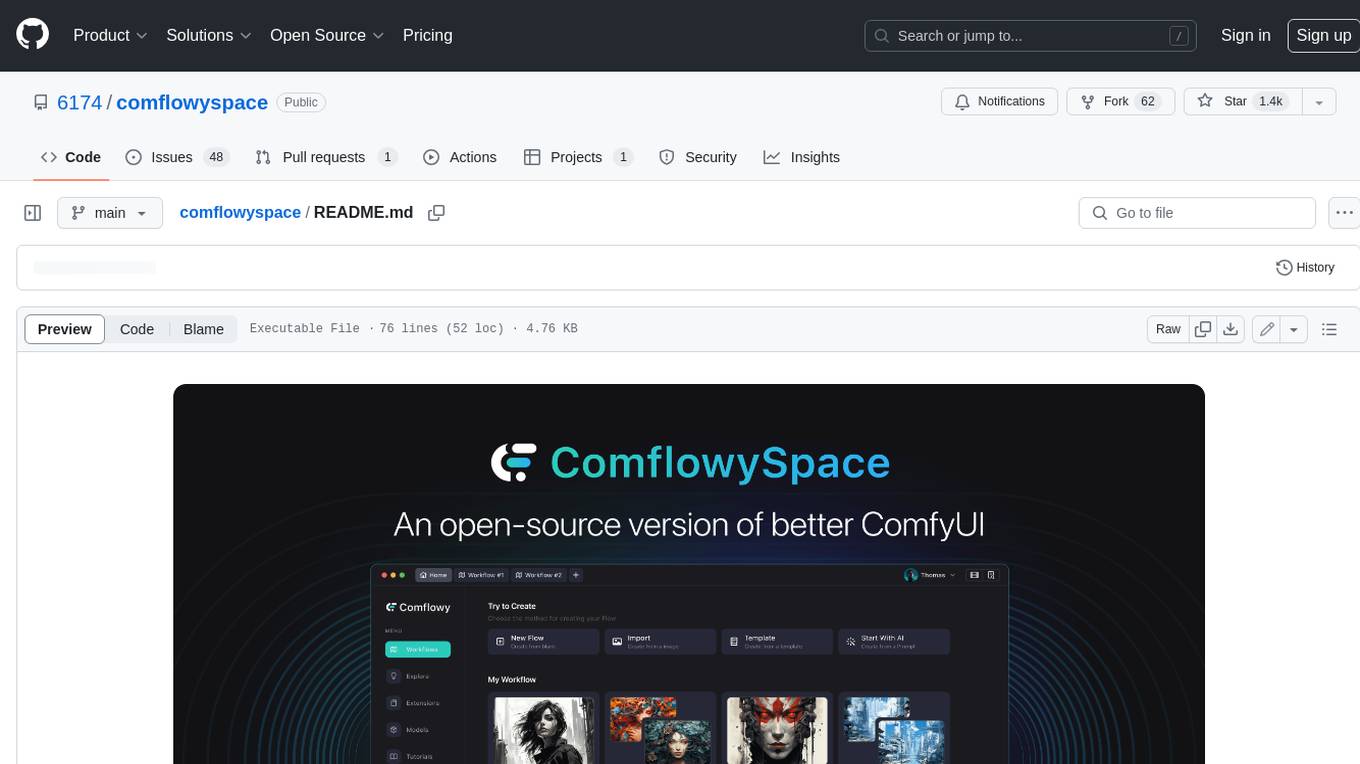
comflowyspace
Comflowyspace is an open-source AI image and video generation tool that aims to provide a more user-friendly and accessible experience than existing tools like SDWebUI and ComfyUI. It simplifies the installation, usage, and workflow management of AI image and video generation, making it easier for users to create and explore AI-generated content. Comflowyspace offers features such as one-click installation, workflow management, multi-tab functionality, workflow templates, and an improved user interface. It also provides tutorials and documentation to lower the learning curve for users. The tool is designed to make AI image and video generation more accessible and enjoyable for a wider range of users.
Rewind-AI-Main
Rewind AI is a free and open-source AI-powered video editing tool that allows users to easily create and edit videos. It features a user-friendly interface, a wide range of editing tools, and support for a variety of video formats. Rewind AI is perfect for beginners and experienced video editors alike.
MoneyPrinterTurbo
MoneyPrinterTurbo is a tool that can automatically generate video content based on a provided theme or keyword. It can create video scripts, materials, subtitles, and background music, and then compile them into a high-definition short video. The tool features a web interface and an API interface, supporting AI-generated video scripts, customizable scripts, multiple HD video sizes, batch video generation, customizable video segment duration, multilingual video scripts, multiple voice synthesis options, subtitle generation with font customization, background music selection, access to high-definition and copyright-free video materials, and integration with various AI models like OpenAI, moonshot, Azure, and more. The tool aims to simplify the video creation process and offers future plans to enhance voice synthesis, add video transition effects, provide more video material sources, offer video length options, include free network proxies, enable real-time voice and music previews, support additional voice synthesis services, and facilitate automatic uploads to YouTube platform.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.