Best AI tools for< Process Speech >
20 - AI tool Sites
AI Wedding Toast
AI Wedding Toast is an advanced AI tool designed to simplify the process of creating unique and memorable wedding speeches. With the help of artificial intelligence, users can generate personalized wedding speeches effortlessly, ensuring a heartfelt and impactful moment on the special day. The tool guides users through sharing important details and stories, generating speech drafts, and providing easy on-platform editing for a stress-free experience. AI Wedding Toast offers professional-grade speechwriting assistance, personalized wedding speeches, and a seamless process to craft speeches that leave a lasting impression.
Speechimo
Speechimo is an AI-powered text-to-speech tool that transforms written content into high-quality audio with human-like voices. It offers a user-friendly interface, premium voices, and efficient voice generation, making it a valuable asset for content creators across various platforms. With Speechimo, users can enhance their videos, audiobooks, podcasts, and e-learning materials, elevating the overall quality of their content creation process.
InteliConvo®
InteliConvo® is a state-of-the-art AI-powered speech analytics and automation platform that enables businesses to process and analyze recorded customer conversations. It provides valuable insights into customer buying patterns, intents, sentiments, and feedback, which can be utilized to automate workflows, improve team performance, accelerate sales, enhance debt collections, boost customer experience, and ensure compliance. The platform offers features like multilingual support, flexible deployment options, hot lead identification, debt default prediction, brand building insights, and compliance monitoring.
Smart Media Cutter
Smart Media Cutter is an AI-powered tool designed for video and podcast creators to streamline the editing process. It offers fast and accurate lossless cutting of video and audio, transcription-aided editing, multi-track transcriptions, advanced speech denoiser, and wide support for common media formats. The tool runs on desktop platforms like Windows and macOS, with plans tailored for individual creators, small production companies, and enterprise clients. Smart Media Cutter ensures privacy by keeping all AI features offline on the user's computer.
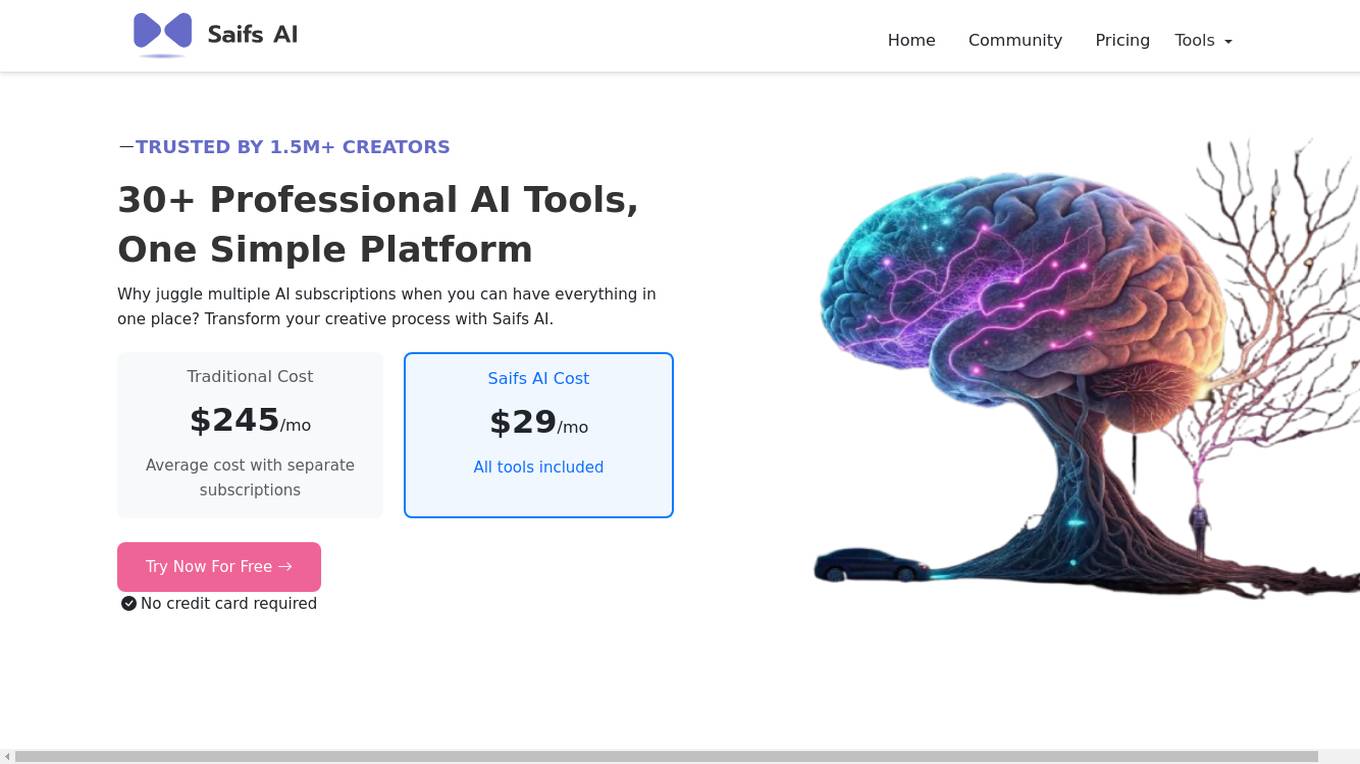
Saifs AI
Saifs AI is a comprehensive AI-powered platform that offers a wide range of tools for content creation and manipulation. With over 30 professional AI tools available on a single platform, Saifs AI aims to streamline the creative process for users by providing intuitive interfaces, AI-powered suggestions, and smart automation features. Trusted by over 1.5 million creators and companies worldwide, Saifs AI leverages elite AI models to deliver high-quality output in areas such as video, image, text, and audio generation. The platform caters to creators looking to save time, reduce costs, and scale their creative output with consistent results and growth analytics.
TakeNote
TakeNote is a cutting-edge speech-to-text AI that transforms audio and video into documents, boosting productivity and enhancing meeting experiences. Its advanced AI models provide exceptional accuracy, approaching human-level robustness and accuracy in English speech recognition. TakeNote AI empowers teams to transcribe meetings into accurate transcripts, generate precise summaries, analyze sentiment, and identify speakers, all while ensuring high levels of security and data protection.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
Verbit Go
Verbit Go is an AI-powered transcription and captioning platform that automates the process of converting audio and video files into text. It utilizes advanced speech recognition technology to provide accurate and efficient transcriptions, making it ideal for professionals in various industries such as legal, media, education, and more. Verbit Go offers a user-friendly interface, customizable settings, and secure cloud storage for easy access to transcribed content. With its AI capabilities, Verbit Go significantly reduces the time and effort required for transcription tasks, improving productivity and workflow efficiency.
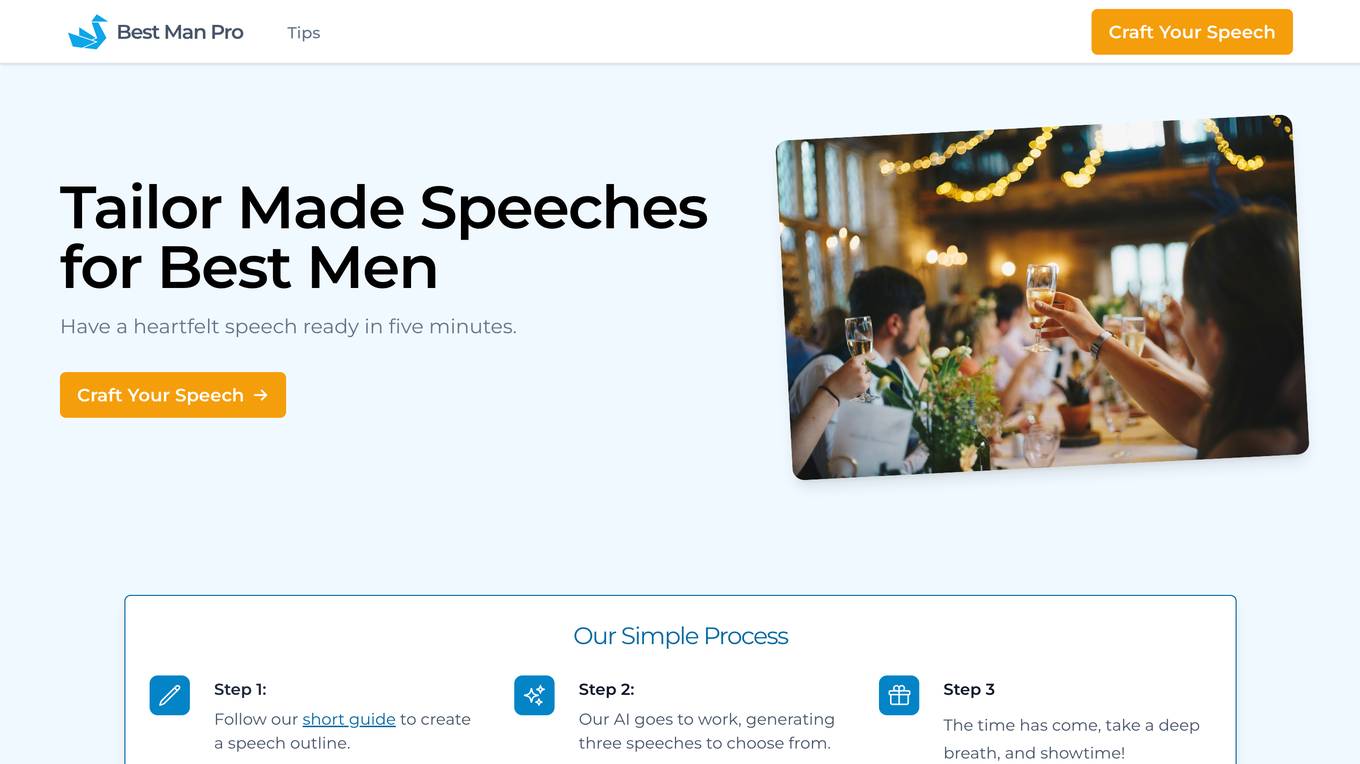
Best Man Pro
Best Man Pro is an AI-powered tool that helps users craft memorable best man speeches. With its simple three-step process, users can create a speech outline, generate three speech options to choose from, and refine their speech to perfection. The tool provides guidance and assistance throughout the process, ensuring that users can deliver a speech that is both heartfelt and polished. Best Man Pro is designed to help users overcome writer's block and create a speech that is tailored to their unique style and the occasion.

Toastful
Toastful is an AI-powered wedding speech generator that helps users create personalized, memorable speeches for their special day. With its cutting-edge AI engine, Toastful guides users through a simple process of providing information about themselves, the couple, and sharing stories. The AI then crafts a unique speech that captures the essence of the relationship and the occasion. Toastful's speeches are highly personalized, tailored to the audience, and designed to captivate listeners. The platform offers a user-friendly interface, making it easy for anyone to create a heartfelt and meaningful speech, even those who may not be confident in their writing abilities.
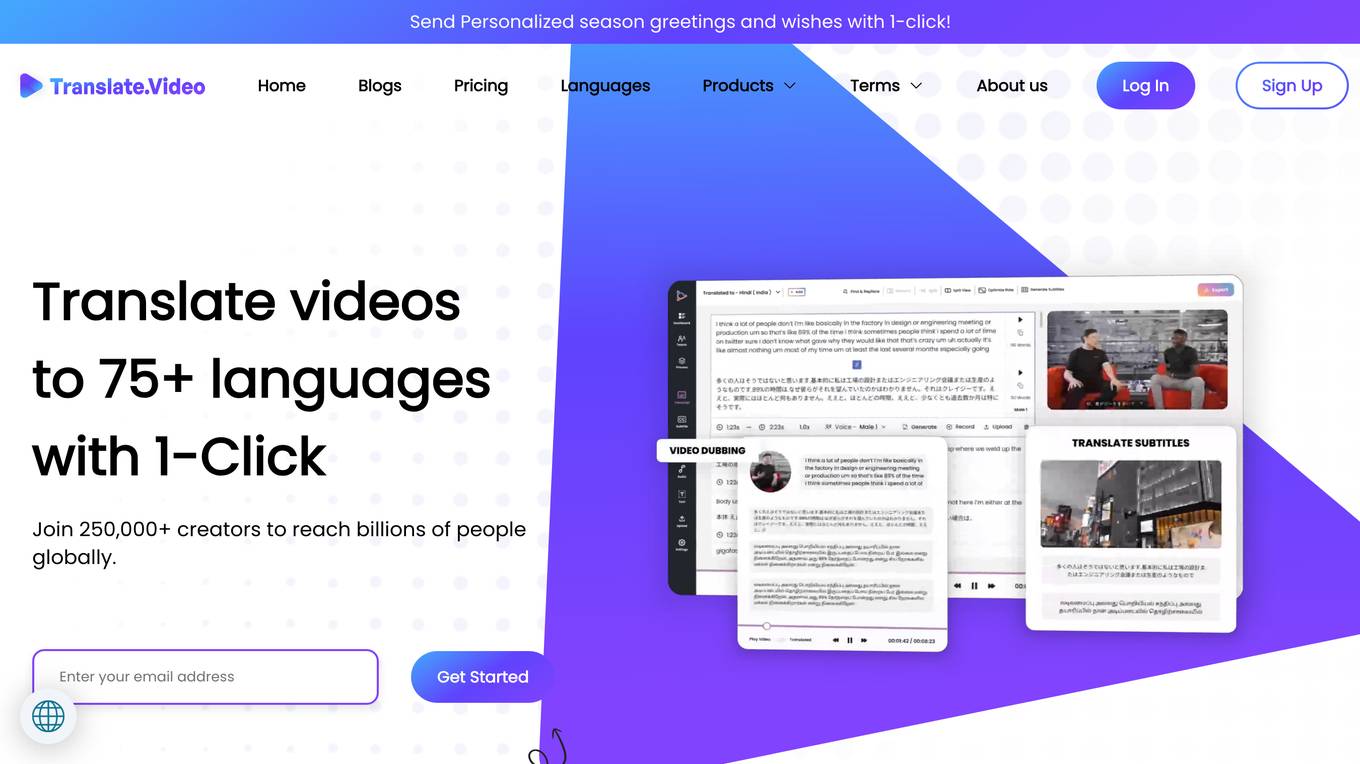
Translate.Video
Translate.Video is an AI multi-speaker video translation tool that offers speaker diarization, voice cloning, text-to-speech, and instant voice cloning features. It allows users to translate videos to over 75 languages with just one click, making content creation and translation efficient and accessible. The tool also provides plugins for popular design software like Photoshop, Illustrator, and Figma, enabling users to accelerate creative translation. Translate.Video is designed to help creators, influencers, and enterprises reach a global audience by simplifying the captioning, subtitling, and dubbing process.
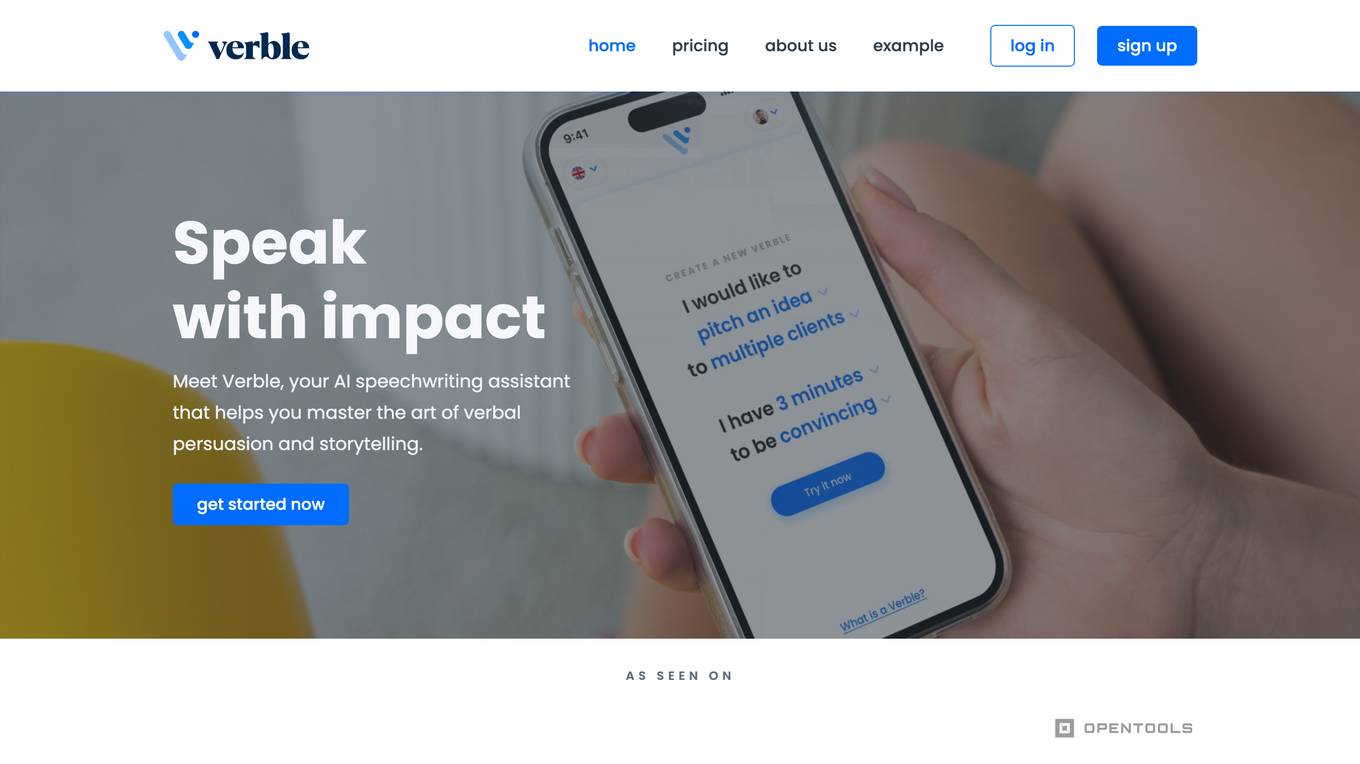
Verble
Verble is an AI speech-writing assistant that helps users master the art of verbal persuasion and storytelling. With over 7500 speeches written, Verble guides users through the process of creating impactful speeches for various occasions, from business pitches to wedding speeches. The tool offers a chat feature to kickstart the speech preparation, creates organized drafts based on user input, and provides smart editing techniques inspired by renowned speakers. Verble aims to empower individuals to share their stories effectively and confidently, offering a user-friendly interface and innovative speaker techniques.

babs.ai
babs.ai is an AI-powered job matching platform that connects talent with opportunities. It leverages intelligent matching algorithms to streamline the recruitment process and ensure a seamless experience for both job seekers and employers. The platform caters to a wide range of job roles and industries, making it a versatile solution for all types of users.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
VidAU
VidAU is an AI-driven video and audio generation platform that simplifies the content creation process from conception to production. It offers a range of tools such as AI Video Face Swap, AI Video Translator, AI Avatar Video, Subtitles Translate, and Subtitles Removal. Users can generate engaging videos in batches within minutes by entering product URLs or descriptions. The platform caters to marketing content, multi-language video production, instructional videos, and TikTok videos, with features like AI-generated avatars, voice cloning, and subtitles translation. VidAU has been endorsed by various users for its ability to enhance video content, boost engagement, and drive sales across different industries.
WikeAI
WikeAI is an all-in-one AI platform that provides access to top AI models such as GPT-4, Claude3, Mistral, and Llama2. It offers professional-level cross-model integration, allowing users to experience powerful language understanding, speech synthesis, and visual generation technology without switching between multiple systems. WikeAI simplifies the process of using AI for content writing by generating blog articles, product descriptions, social media ads, and more in seconds. The platform offers different pricing plans tailored to various user needs, from casual users to language creators.
Unify
Unify is an AI tool that offers a suite of generators including AI Video Generator, AI Image Generator, AI Music Generator, and AI Chat. It leverages artificial intelligence to create various types of content such as videos, images, music, and chat interactions. Unify simplifies the content creation process by providing automated tools powered by AI technology, enabling users to generate high-quality multimedia content effortlessly.
DupDub
DupDub is an all-in-one content creation platform that helps users generate compelling content, bring content to life with human-like voices, capture still images and watch them come alive with realistic speech and emotions, enhance videos like a pro, and get inspired feedback from users across diverse industries.
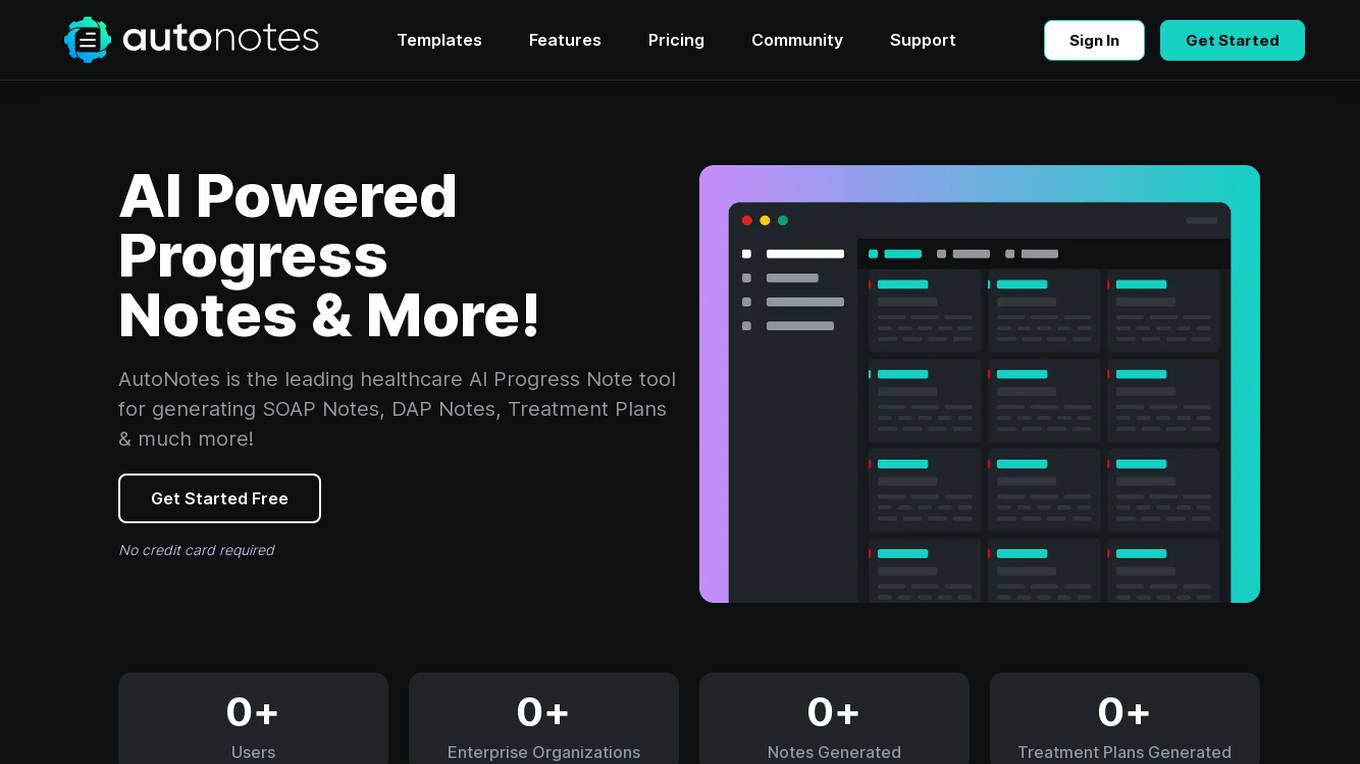
AutoNotes
AutoNotes is a leading healthcare AI Progress Note tool that offers AI-powered clinical documentation templates for generating SOAP Notes, DAP Notes, Treatment Plans, and more. It provides a user-friendly interface for therapists and healthcare professionals to create detailed and customizable clinical notes efficiently. With features like summarizing sessions, editing and downloading notes, and simple pricing plans, AutoNotes aims to streamline the documentation process in healthcare settings. The platform also offers advanced features like template customization, secure document storage, and dictation for voice-to-text conversion. Users can benefit from the platform's customization options, seamless integration with workflows, and responsive customer support.
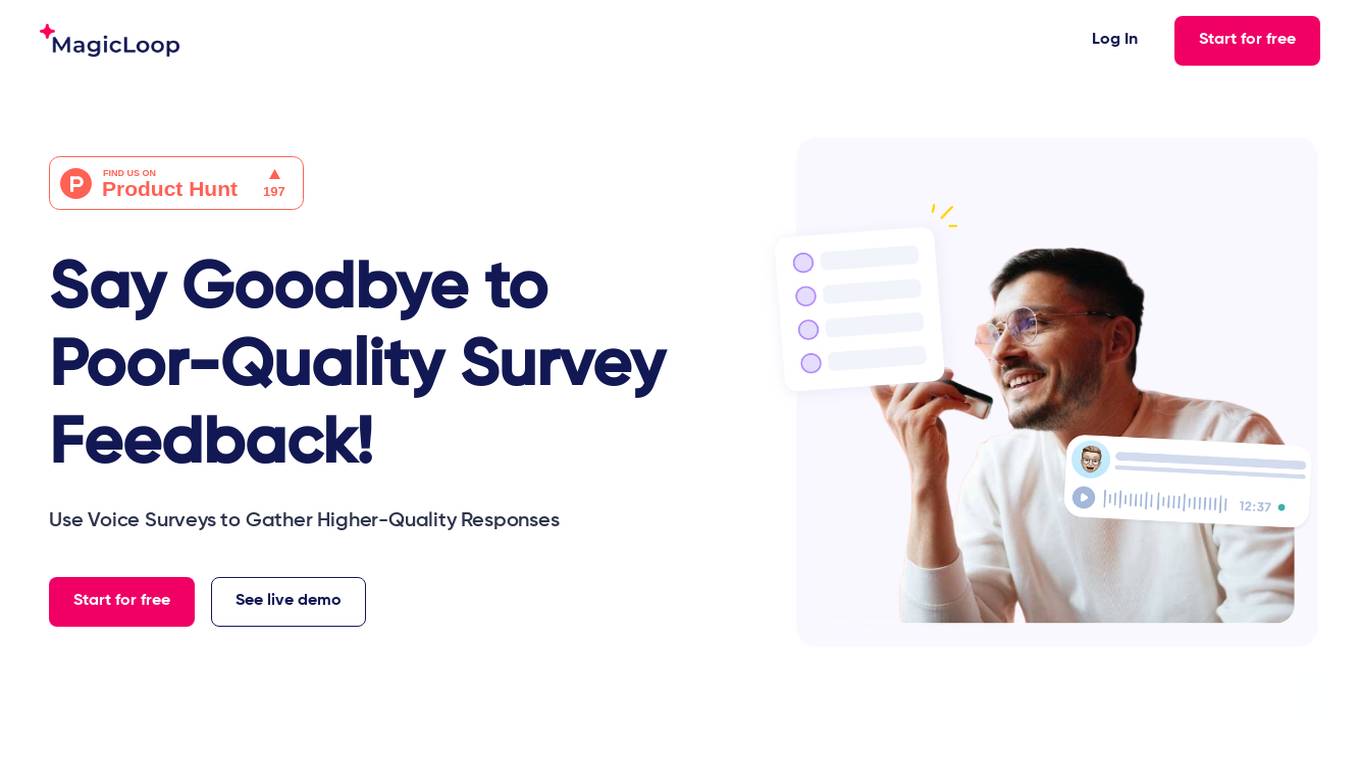
MagicLoop
MagicLoop is a voice survey tool designed to enhance customer feedback by replacing written feedback with spoken responses. It allows users to gather higher-quality responses through voice surveys, capturing emotions, tones, and nuances for a deeper understanding of participants' feelings and intentions. The tool aims to improve participant engagement and provide detailed insights by encouraging genuine responses. MagicLoop offers a modern approach to surveys, addressing the limitations of traditional methods and providing tailored solutions for various use cases such as user research, satisfaction surveys, NPS, feedback collection, market research, and data monitoring. With features like AI analysis, speech-to-text transcription, and custom branding, MagicLoop streamlines the process of generating insights from voice recordings.
2 - Open Source AI Tools

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
20 - OpenAI Gpts
Process Map Optimizer
Upload your process map and I will analyse and suggest improvements
Process Engineering Advisor
Optimizes production processes for improved efficiency and quality.
Customer Service Process Improvement Advisor
Optimizes business operations through process enhancements.

R&D Process Scale-up Advisor
Optimizes production processes for efficient large-scale operations.
Process Optimization Advisor
Improves operational efficiency by optimizing processes and reducing waste.


Manufacturing Process Development Advisor
Optimizes manufacturing processes for efficiency and quality.


Trademarks GPT
Trademark Process Assistant, Not an Attorney & Definitely Not Legal Advice (independently verify info received). Gain insights on U.S. trademark process & concepts, USPTO resources, application steps & more - all while being reminded of the importance of consulting legal pros 4 specific guidance.

Prioritization Matrix Pro
Structured process for prioritizing marketing tasks based on strategic alignment. Outputs in Eisenhower, RACI and other methodologies.

👑 Data Privacy for Insurance Companies 👑
Insurance providers collect and process personal health, financial, and property information, making it crucial to implement comprehensive data protection strategies.

ScriptCraft
To streamline the process of creating scripts for Brut-style videos by providing structured guidance in researching, strategizing, and writing, ensuring the final script is rich in content and visually captivating.