
buffer-of-thought-llm
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
Stars: 341
Buffer of Thoughts (BoT) is a thought-augmented reasoning framework designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). It introduces a meta-buffer to store high-level thought-templates distilled from problem-solving processes, enabling adaptive reasoning for efficient problem-solving. The framework includes a buffer-manager to dynamically update the meta-buffer, ensuring scalability and stability. BoT achieves significant performance improvements on reasoning-intensive tasks and demonstrates superior generalization ability and robustness while being cost-effective compared to other methods.
README:
This repository contains the official implementation of our Buffer of Thoughts (BoT) framework. Affiliation: Peking University, UC Berkeley, Stanford University
- [x] Release initial code of BoT, supporting GPT-4 and Llama3-70B [2024.6.6]
- [x] Update the code for smaller LLMs (e.g., Llama3-8B) [2024.6.24]
- [ ] Release meta-buffer and buffer-manager
- [ ] Extending BoT to more applications
We introduce BoT, a novel and versatile thought-augmented reasoning approach designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). Specifically, we propose a meta-buffer to store a series of high-level thoughts, referred to as thought-templates, distilled from problem-solving processes across various tasks. For each problem, we retrieve a relevant thought-template and adaptively instantiate it with specific reasoning structures to conduct efficient reasoning. To ensure scalability and stability, we also propose a buffer-manager to dynamically update the meta-buffer, thus enhancing its capacity as more tasks are solved. We conduct extensive experiments on 10 challenging reasoning-intensive tasks, achieving significant performance improvements over previous state-of-the-art (SOTA) methods: 11% on Game of 24, 20% on Geometric Shapes, and 51% on Checkmate-in-One. Further analysis demonstrates the superior generalization ability and robustness of our BoT, while requiring only 12% of the cost of multi-query prompting methods (e.g., tree/graph of thoughts) on average. Notably, we find that our Llama3-8B + BoT has the potential to surpass Llama3-70B model.
 |
| Overview of our BoT |
| Task/Method | GPT-4 | PAL | ToT | Meta Prompting | BoT (Ours) |
|---|---|---|---|---|---|
| Game of 24 | 3.0 | 64.0 | 74.0 | 67.0 | 82.4 |
| MGSM (avg) | 84.4 | 72.0 | 86.4 | 84.8 | 89.2 |
| Multi-Step Arithmetic | 84.0 | 87.4 | 88.2 | 90.0 | 99.8 |
| WordSorting | 80.4 | 93.2 | 96.4 | 99.6 | 100.0 |
| Python Puzzles | 31.1 | 47.3 | 43.5 | 45.8 | 52.4 |
| Geometric Shapes | 52.6 | 51.2 | 56.8 | 78.2 | 93.6 |
| Checkmate-in-One | 36.4 | 10.8 | 49.2 | 57.0 | 86.4 |
| Date Understanding | 68.4 | 76.2 | 78.6 | 79.2 | 88.2 |
| Penguins | 71.1 | 93.3 | 84.2 | 88.6 | 94.7 |
| Sonnet Writing | 62.0 | 36.2 | 68.4 | 79.6 | 80.0 |
For now, we release our demo version of BoT based on three different benchmarks:
- The Game of 24 from Yao et al., 2023
- Checkmate-in-One from the BIG-Bench suite (BIG-Bench authors, 2023)
- Word Sorting from BIG-Bench Hard (Suzgun et al., 2023; BIG-Bench authors, 2023)
For each task, we choose one thought template sampled from our meta-buffer library. Stay tuned for our complete meta-buffer library update!
First, set up the environment:
git clone https://github.com/YangLing0818/buffer-of-thought-llm
cd buffer-of-thought-llm
conda create -n BoT python==3.9
pip install -r requirements.txtOur BoT is easy to use. Just run:
python run_benchmarks.py --task_name 'gameof24' --api_key 'input your API key here if you want to use GPT-4' --model_id 'the model ID of GPT-4 or the path to your local LLM'Here, --task_name could be one of gameof24, checkmate, wordsorting.
The --api_key is required if you want to use GPT-series; if not, you can skip it.
The --model_id should be the model ID of GPT-series like gpt-4o, gpt-4-turbo, or the path to your local LLM if you do not set --api_key.
The data for these three tasks are located in the /benchmarks directory.
The results generated during the experiment are stored in the /test_results directory.
Run the command below to validate the test results of our BoT:
python validate_results.py --task_name 'gameof24' --test_path 'The path to the .jsonl file you want to validate'This will print out the accuracy of the selected task on your relevant .jsonl file.
@article{yang2024buffer,
title={Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models},
author={Yang, Ling and Yu, Zhaochen and Zhang, Tianjun and Cao, Shiyi and Xu, Minkai and Zhang, Wentao and Gonzalez, Joseph E and Cui, Bin},
journal={arXiv preprint arXiv:2406.04271},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for buffer-of-thought-llm
Similar Open Source Tools
buffer-of-thought-llm
Buffer of Thoughts (BoT) is a thought-augmented reasoning framework designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). It introduces a meta-buffer to store high-level thought-templates distilled from problem-solving processes, enabling adaptive reasoning for efficient problem-solving. The framework includes a buffer-manager to dynamically update the meta-buffer, ensuring scalability and stability. BoT achieves significant performance improvements on reasoning-intensive tasks and demonstrates superior generalization ability and robustness while being cost-effective compared to other methods.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.
Streamline-Analyst
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
FuzzyAI
The FuzzyAI Fuzzer is a powerful tool for automated LLM fuzzing, designed to help developers and security researchers identify jailbreaks and mitigate potential security vulnerabilities in their LLM APIs. It supports various fuzzing techniques, provides input generation capabilities, can be easily integrated into existing workflows, and offers an extensible architecture for customization and extension. The tool includes attacks like ArtPrompt, Taxonomy-based paraphrasing, Many-shot jailbreaking, Genetic algorithm, Hallucinations, DAN (Do Anything Now), WordGame, Crescendo, ActorAttack, Back To The Past, Please, Thought Experiment, and Default. It supports models from providers like Anthropic, OpenAI, Gemini, Azure, Bedrock, AI21, and Ollama, with the ability to add support for newer models. The tool also supports various cloud APIs and datasets for testing and experimentation.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
SimAI
SimAI is the industry's first full-stack, high-precision simulator for AI large-scale training. It provides detailed modeling and simulation of the entire LLM training process, encompassing framework, collective communication, network layers, and more. This comprehensive approach offers end-to-end performance data, enabling researchers to analyze training process details, evaluate time consumption of AI tasks under specific conditions, and assess performance gains from various algorithmic optimizations.
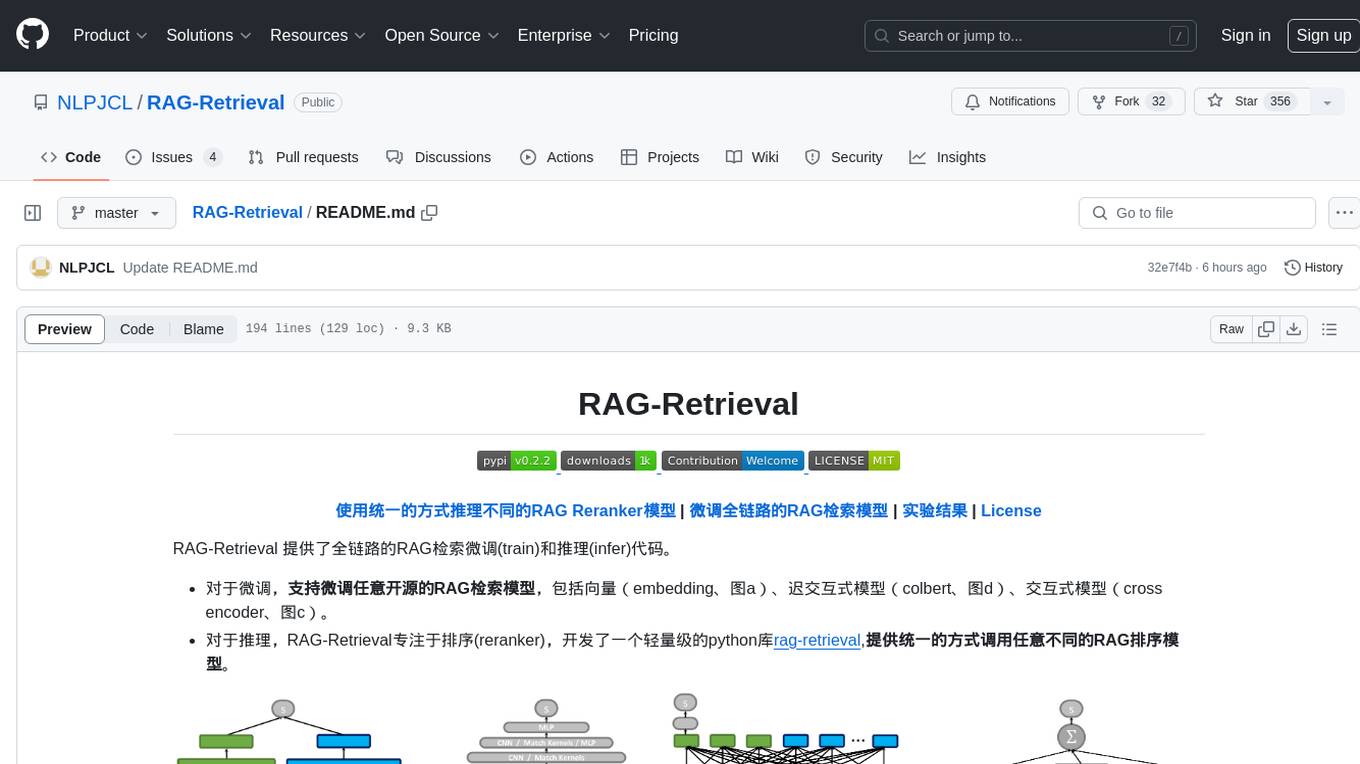
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
unoplat-code-confluence
Unoplat-CodeConfluence is a universal code context engine that aims to extract, understand, and provide precise code context across repositories tied through domains. It combines deterministic code grammar with state-of-the-art LLM pipelines to achieve human-like understanding of codebases in minutes. The tool offers smart summarization, graph-based embedding, enhanced onboarding, graph-based intelligence, deep dependency insights, and seamless integration with existing development tools and workflows. It provides a precise context API for knowledge engine and AI coding assistants, enabling reliable code understanding through bottom-up code summarization, graph-based querying, and deep package and dependency analysis.

EvoAgentX
EvoAgentX is an open-source framework for building, evaluating, and evolving LLM-based agents or agentic workflows in an automated, modular, and goal-driven manner. It enables developers and researchers to move beyond static prompt chaining or manual workflow orchestration by introducing a self-evolving agent ecosystem. The framework includes features such as agent workflow autoconstruction, built-in evaluation, self-evolution engine, plug-and-play compatibility, comprehensive built-in tools, memory module support, and human-in-the-loop interactions.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.