
Streamline-Analyst
An AI agent powered by LLMs that streamlines the entire process of data analysis. 🚀
Stars: 301
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.
README:
Languages / 语言选择: English | 中文
Streamline Analyst 🪄 is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates all the tasks such as data cleaning, preprocessing, and even complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless.
Here's how it simplifies your workflow: just select your data file, pick an analysis mode, and hit start. Streamline Analyst aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. It's built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency🚀, and to execute high-performance modeling with the best strategies🔮.
Try Our Live Demo Here: Streamline Analyst
When utilizing GPT-4 turbo, the cost for each comprehensive end-to-end API request is roughly $0.02.
Your data's privacy and security are paramount; rest assured, uploaded data and API Keys are strictly for one-time use and are neither saved nor shared.
Looking ahead, we plan to enhance Streamline Analyst with advanced features like Natural Language Processing (NLP), neural networks, and object detection (utilizing YOLO), broadening its capabilities to meet more diverse data analysis needs.
Demo link available at: Streamline Analyst
- Target Variable Identification: LLMs adeptly pinpoint the target variable
- Null Value Management: Choose from a variety of strategies such as mean, median, mode filling, interpolation, or introducing new categories for handling missing data, all recommended by LLMs
- Data Encoding Tactics: Automated suggestions and completions for the best encoding methods, including one-hot, integer mapping, and label encoding
- Dimensionality Reduction with PCA
- Duplicate Entity Resolution
- Data Transformation and Normalization: Utilize Box-Cox transformation and normalization techniques to improve data distribution and scalability
- Balancing Target Variable Entities: LLM-recommended methods like random over-sampling, SMOTE, and ADASYN help balance data sets, crucial for unbiased model training
- Data Set Proportion Adjustment: LLM determines the proportion of the data set (can also be adjusted manually)
- Model Selection and Training: Based on your data, LLMs recommend and initiate training with the most suitable models
- Cluster Number Recommendation: Leveraging the Elbow Rule and Silhouette Coefficient for optimal cluster numbers, with the flexibility of real-time adjustments
All processed data and models are made available for download, offering a comprehensive, user-friendly data analysis toolkit.
| Classification Models | Clustering Models | Regression Models |
|---|---|---|
| Logistic regression | K-means clustering | Linear regression |
| Random forest | DBSCAN | Ridge regression |
| Support vector machine | Gaussian mixture model | Lasso regression |
| Gradient boosting machine | Hierarchical clustering | Elastic net regression |
| Gaussian Naive Bayes | Spectral clustering | Random forest regression |
| AdaBoost | etc. | Gradient boosting regression |
| XGBoost | etc. |
| Classification Metrics & Plots | Clustering Metrics & Plots | Regression Metrics & Plots |
|---|---|---|
| Model score | Silhouette score | R-squared score |
| Confusion matrix | Calinski-Harabasz score | Mean square error (MSE) |
| AUC | Davies-Bouldin score | Root mean square error (RMSE) |
| F1 score | Cluster scatter plot | Absolute error (MAE) |
| ROC plot | etc. | Residual plot |
| etc. | Predicted value vs actual value plot | |
| Quantile-Quantile plot |
Streamline Analyst 🪄 offers an array of intuitive visual tools for enhanced data insight, without the need for an API Key:
- Single Attribute Visualization: Insightful views into individual data aspects
- Multi-Attribute Visualization: Comprehensive analysis of variable interrelations
- Three-Dimensional Plotting: Advanced 3D representations for complex data relationships
- Word Clouds: Key themes and concepts highlighted through word frequency
- World Heat Maps: Geographic trends and distributions made visually accessible
To run app.py, you'll need:
- Python 3.11.5
-
OpenAI API Key
- OpenAI: Note that the free quota does not support GPT-4
- Install the required packages
pip install -r requirements.txt
- Run
app.pyon your local machine
streamlit run app.py
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Streamline-Analyst
Similar Open Source Tools
Streamline-Analyst
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.
shandu
Shandu is an advanced AI research system that automates comprehensive research processes using language models, web scraping, and iterative exploration to generate well-structured reports with citations. It features intelligent state-based workflow, deep exploration, multi-source information synthesis, enhanced web scraping, smart source evaluation, content analysis pipeline, comprehensive report generation, parallel processing, adaptive search strategy, and full citation management.
LLM-on-Tabular-Data-Prediction-Table-Understanding-Data-Generation
This repository serves as a comprehensive survey on the application of Large Language Models (LLMs) on tabular data, focusing on tasks such as prediction, data generation, and table understanding. It aims to consolidate recent progress in this field by summarizing key techniques, metrics, datasets, models, and optimization approaches. The survey identifies strengths, limitations, unexplored territories, and gaps in the existing literature, providing insights for future research directions. It also offers code and dataset references to empower readers with the necessary tools and knowledge to address challenges in this rapidly evolving domain.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.
veScale
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.
heurist-agent-framework
Heurist Agent Framework is a flexible multi-interface AI agent framework that allows processing text and voice messages, generating images and videos, interacting across multiple platforms, fetching and storing information in a knowledge base, accessing external APIs and tools, and composing complex workflows using Mesh Agents. It supports various platforms like Telegram, Discord, Twitter, Farcaster, REST API, and MCP. The framework is built on a modular architecture and provides core components, tools, workflows, and tool integration with MCP support.
obsidian-llmsider
LLMSider is an AI assistant plugin for Obsidian that offers flexible multi-model support, deep workflow integration, privacy-first design, and a professional tool ecosystem. It provides comprehensive AI capabilities for personal knowledge management, from intelligent writing assistance to complex task automation, making AI a capable assistant for thinking and creating while ensuring data privacy.
abi
ABI (Agentic Brain Infrastructure) is a Python-based AI Operating System designed to serve as the core infrastructure for building an Agentic AI Ontology Engine. It empowers organizations to integrate, manage, and scale AI-driven operations with multiple AI models, focusing on ontology, agent-driven workflows, and analytics. ABI emphasizes modularity and customization, providing a customizable framework aligned with international standards and regulatory frameworks. It offers features such as configurable AI agents, ontology management, integrations with external data sources, data processing pipelines, workflow automation, analytics, and data handling capabilities.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. It processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. The tool includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models. It offers a GUI for managing local LLaMA.cpp servers, customizable settings, and advanced search utilities. ERAG supports multi-model collaboration, iterative knowledge refinement, automated quality assessment, and structured knowledge format enforcement. Users can generate specific knowledge entries, full-size textbooks, or datasets using AI-generated questions and answers.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. This tool processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. It includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models.
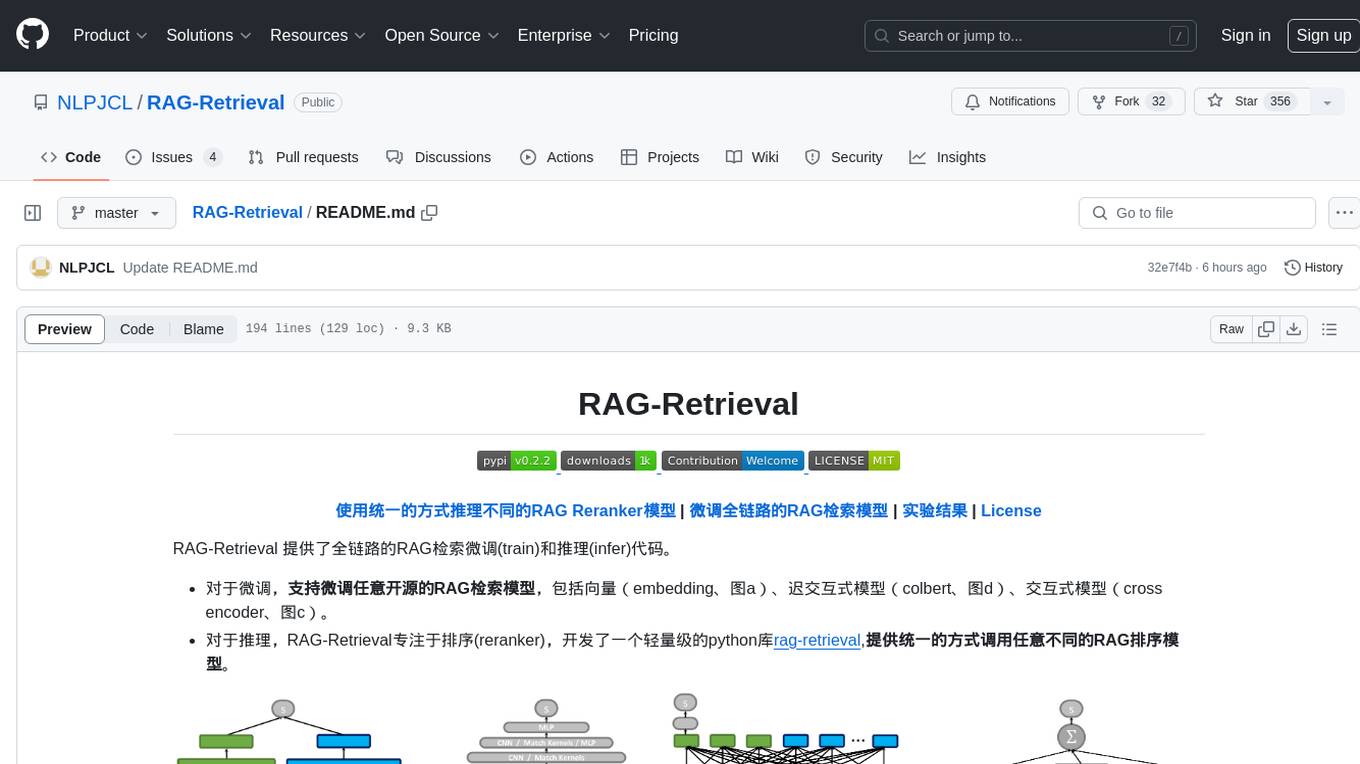
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs
Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.
databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide