
CompressAI-Vision
CompressAI-Vision helps you design, test and compare Video Compression for Machines pipelines. Compression methods can be either pulled from custom AI-based modules from CompressAI or traditional codecs such as H.266/VVC.
Stars: 81
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).
README:
![]()
CompressAI-Vision helps you to develop, test and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors.
It currently focuses on two types of pipeline:
-
Video compression for remote inference (
compressai-remote-inference), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. -
Split inference (
compressai-split-inference), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all thepipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).

-
Detectron2 is used for object detection (Faster-RCNN) and instance segmentation (Mask-RCNN)
-
JDE is used for Object Tracking
A complete documentation is provided here, including installation, CLI usage, as well as tutorials.
To get started locally and install the development version of CompressAI-Vision, first create a virtual environment with python==3.8:
python3.8 -m venv venv
source ./venv/bin/activate
pip install -U pip
The CompressAI library providing learned compresion modules is available as a submodule. It can be initilized by running:
git submodule update --init --recursive
To install the models relevant for the FCM (feature compression):
First, if you want to manually export CUDA related paths, please source (e.g. for CUDA 11.8):
bash scripts/env_cuda.sh 11.8
Then, run:, please run:
bash scripts/install.sh
For more otions, check:
bash scripts/install.sh --help
NOTE 1: install.sh gives you the possibility to install vision models' source and weights at specified locations so that mutliple versions of compressai-vision can point to the same installed vision models
NOTE 2: the downlading of JDE pretrained weights might fail. Check that the size of following file is ~558MB. path/to/weights/jde/jde.1088x608.uncertainty.pt The file can be downloaded at the following link (in place of the above file path): "https://docs.google.com/uc?export=download&id=1nlnuYfGNuHWZztQHXwVZSL_FvfE551pA"
To run split-inference pipelines, please use the following command:
compressai-split-inference --help
Note that the following entry point is kept for backward compability. It runs split inference as well.
compressai-vision-eval --help
For example for testing a full split inference pipelines without any compression, run
compressai-vision-eval --config-name=eval_split_inference_example
For remote inference (MPEG VCM-like) pipelines, please run:
compressai-remote-inference --help
Please check other configuration examples provided in ./cfgs as well as examplary scripts in ./scripts
Test data related to the MPEG FCM activity can be found in ./data/mpeg-fcm/
After your dev, you can run (and adapt) test scripts from the scripts/tests directory. Please check scripts/tests/Readme.md for more details
Code is formatted using black and isort. To format code, type:
make code-format
Static checks with those same code formatters can be run manually with:
make static-analysis
To produce the html documentation, from docs/, run:
make html
To check the pages locally, open docs/_build/html/index.html
CompressAI-Vision is licensed under the BSD 3-Clause Clear License
Fabien Racapé, Hyomin Choi, Eimran Eimon, Sampsa Riikonen, Jacky Yat-Hong Lam
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CompressAI-Vision
Similar Open Source Tools
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.
CALF
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
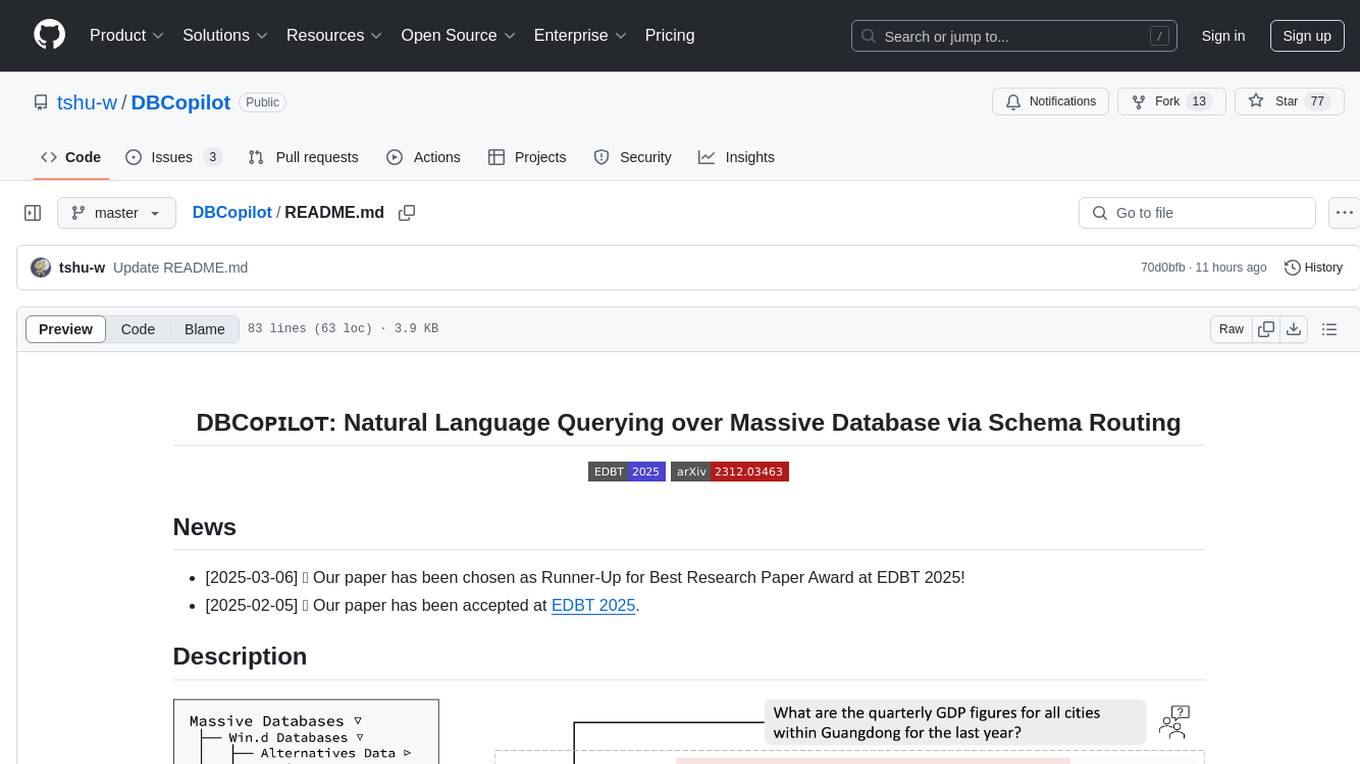
DBCopilot
The development of Natural Language Interfaces to Databases (NLIDBs) has been greatly advanced by the advent of large language models (LLMs), which provide an intuitive way to translate natural language (NL) questions into Structured Query Language (SQL) queries. DBCopilot is a framework that addresses challenges in real-world scenarios of natural language querying over massive databases by employing a compact and flexible copilot model for routing. It decouples schema-agnostic NL2SQL into schema routing and SQL generation, utilizing a lightweight differentiable search index for semantic mappings and relation-aware joint retrieval. DBCopilot introduces a reverse schema-to-question generation paradigm for automatic learning and adaptation over massive databases, providing a scalable and effective solution for schema-agnostic NL2SQL.
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.
inspect_evals
Inspect Evals is a repository of community-contributed LLM evaluations for Inspect AI, created in collaboration by the UK AISI, Arcadia Impact, and the Vector Institute. It supports many model providers including OpenAI, Anthropic, Google, Mistral, Azure AI, AWS Bedrock, Together AI, Groq, Hugging Face, vLLM, and Ollama. Users can contribute evaluations, install necessary dependencies, and run evaluations for various models. The repository covers a wide range of evaluation tasks across different domains such as coding, assistants, cybersecurity, safeguards, mathematics, reasoning, knowledge, scheming, multimodal tasks, bias evaluation, personality assessment, and writing tasks.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.
chatlas
Chatlas is a Python tool that provides a simple and unified interface across various large language model providers. It helps users prototype faster by abstracting complexity from tasks like streaming chat interfaces, tool calling, and structured output. Users can easily switch providers by changing one line of code and access provider-specific features when needed. Chatlas focuses on developer experience with typing support, rich console output, and extension points.
For similar tasks
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).
TokenPacker
TokenPacker is a novel visual projector that compresses visual tokens by 75%∼89% with high efficiency. It adopts a 'coarse-to-fine' scheme to generate condensed visual tokens, achieving comparable or better performance across diverse benchmarks. The tool includes TokenPacker for general use and TokenPacker-HD for high-resolution image understanding. It provides training scripts, checkpoints, and supports various compression ratios and patch numbers.
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.