
Atom
[MLSys'24] Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Stars: 208
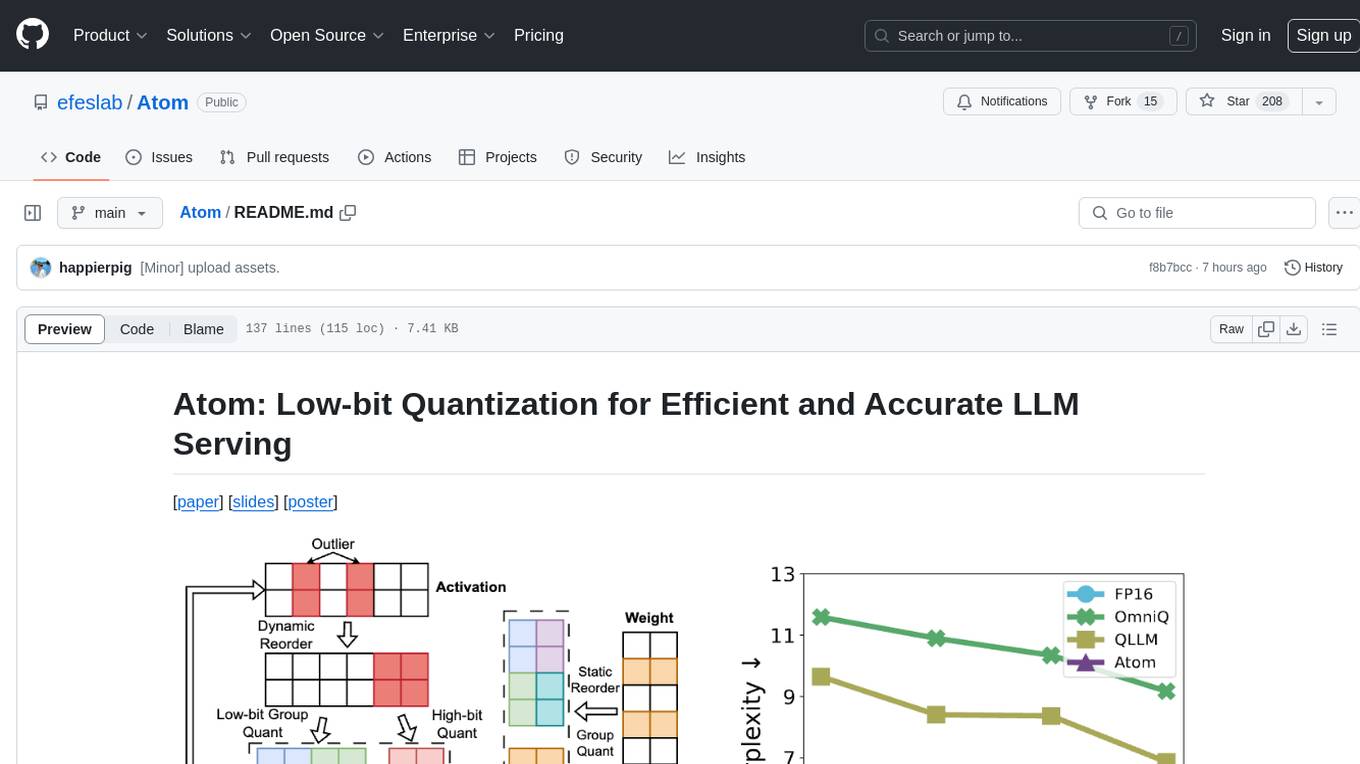
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
README:

Atom is an accurate low-bit weight-activation quantization algorithm that combines (1) mixed-precision, (2) fine-grained group quantization, (3) dynamic activation quantization, (4) KV-cache quantization, and (5) efficient CUDA kernels co-design.
This codebase utilizes lm_eval to evaluate perplexity and zero-shot accuracy. Code segments from SmoothQuant, GPTQ, and SparseGPT are integrated to reproduce results. Our kernels are modified based on previous version of FlashInfer and tested by NVBench. Serving framework Punica is integrated to evaluate end-to-end throughput and latency. We also use BitsandBytes for new data-type evaluations (e.g., FP4). We thank the authors for their great works.
The current release features:
- Simulated quantization for accuracy evaluation.
- Perplexity and zero-shot accuracy evaluation
- Kernel benchmark & End-to-end evaluation
To do:
- [x] Release code for reproducing results.
- [x] Release code for end-to-end throughput evaluation.
- [x] Add FP4 accuracy evaluation for both weight and activation quantization.
- [x] Add support for Mixtral models.
- [ ] Optimize kernel for different GPUs.
- [ ] Full inference workflow in real production scenario.
The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance.
To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to 7.73× compared to the FP16 and by 2.53× compared to INT8 quantization, while maintaining the same latency target.
- Run in container. Mount models.
docker pull nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04
docker run -it --gpus all -v /PATH2MODEL:/model nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04 /bin/bash
- Clone this repo (Make sure you install Git, and Conda)
git clone --recurse-submodules https://github.com/efeslab/Atom
cd Atom
- Prepare environment
cd model
conda create -n atom python=3.10
conda activate atom
pip install -r requirements.txt
- Compile kernels benchmarks (Optional): Install gcc-11 and CMake (>= 3.24)
apt install software-properties-common lsb-release
apt-get update
curl -s https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | gpg --dearmor - | tee /etc/apt/trusted.gpg.d/kitware.gpg >/dev/null
apt-add-repository "deb https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main"
apt update
apt install cmake
cd /PATH_TO_ATOM/kernels
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt-get update
apt install -y gcc-11 g++-11
mkdir build && cd build
cmake ..
make -j
Before running this command, please download Llama model from Hugging Face website first. We recommend downloading from Deca-Llama.
We provide several scripts to reproduce our results in the paper:
To run our W4A4 perplexity evaluation, please execute
bash scripts/run_atom_ppl.sh /Path/To/Llama/Model
To get our W4A4 zero shot accuracy on common sense tasks, please execute
bash scripts/run_atom_zeroshot_acc.sh /Path/To/Llama/Model
To run our ablation study on different quantization optimizations, please run
bash scripts/run_atom_ablation.sh /Path/To/Llama/Model
You can also customize your own quantization setup by modifying the parameters. Check model/llama.py to see the description of each parameter.
python model/llama.py /Path/To/Llama/Model wikitext2 \
--wbits 4 --abits 4 --a_sym --w_sym \
--act_group_size 128 --weight_group_size 128 --weight_channel_group 2 \
--reorder --act_sort_metric hessian \
--a_clip_ratio 0.9 --w_clip_ratio 0.85 \
--keeper 128 --keeper_precision 3 --kv_cache --use_gptq \
--eval_ppl --eval_common_sense
We evaluate Atom on a RTX4090 GPU. Results below are executed in cu113 docker container. Note that current kernels are only optimized for RTX4090.
To get INT4 GEMM kernel result, please execute:
cd kernels/build
./bench_gemm_i4_o16
Check column Elem/s to see the computation throughput of the kernel (Flop/s).

Other kernel of Atom can be evaluated similarly, for e.g., ./bench_reorder. We conduct kernel evaluation on baselines as well. Please check baselines/README.md to reproduce results.
To reproduce end-to-end throughput and latency evaluation, please check e2e/README.md.
We evaluate Atom's accuracy on serveral model families including Llama, Llama-2, and Mixtral, with data types of INT4 and FP4.
-
WikiText2, PTB and C4 datasets on Llama family:

-
WikiText2 perplexity on Llama-2 and Mixtral:

- Atom achieves up to 7.7x higher throughput with similar latency than
FP16with a fixed GPU memory under serving scenario.
If you find this project is helpful to your research, please consider to cite our paper:
@inproceedings{MLSYS2024_5edb57c0,
author = {Zhao, Yilong and Lin, Chien-Yu and Zhu, Kan and Ye, Zihao and Chen, Lequn and Zheng, Size and Ceze, Luis and Krishnamurthy, Arvind and Chen, Tianqi and Kasikci, Baris},
booktitle = {Proceedings of Machine Learning and Systems},
editor = {P. Gibbons and G. Pekhimenko and C. De Sa},
pages = {196--209},
title = {Atom: Low-Bit Quantization for Efficient and Accurate LLM Serving},
url = {https://proceedings.mlsys.org/paper_files/paper/2024/file/5edb57c05c81d04beb716ef1d542fe9e-Paper-Conference.pdf},
volume = {6},
year = {2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Atom
Similar Open Source Tools
Atom
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
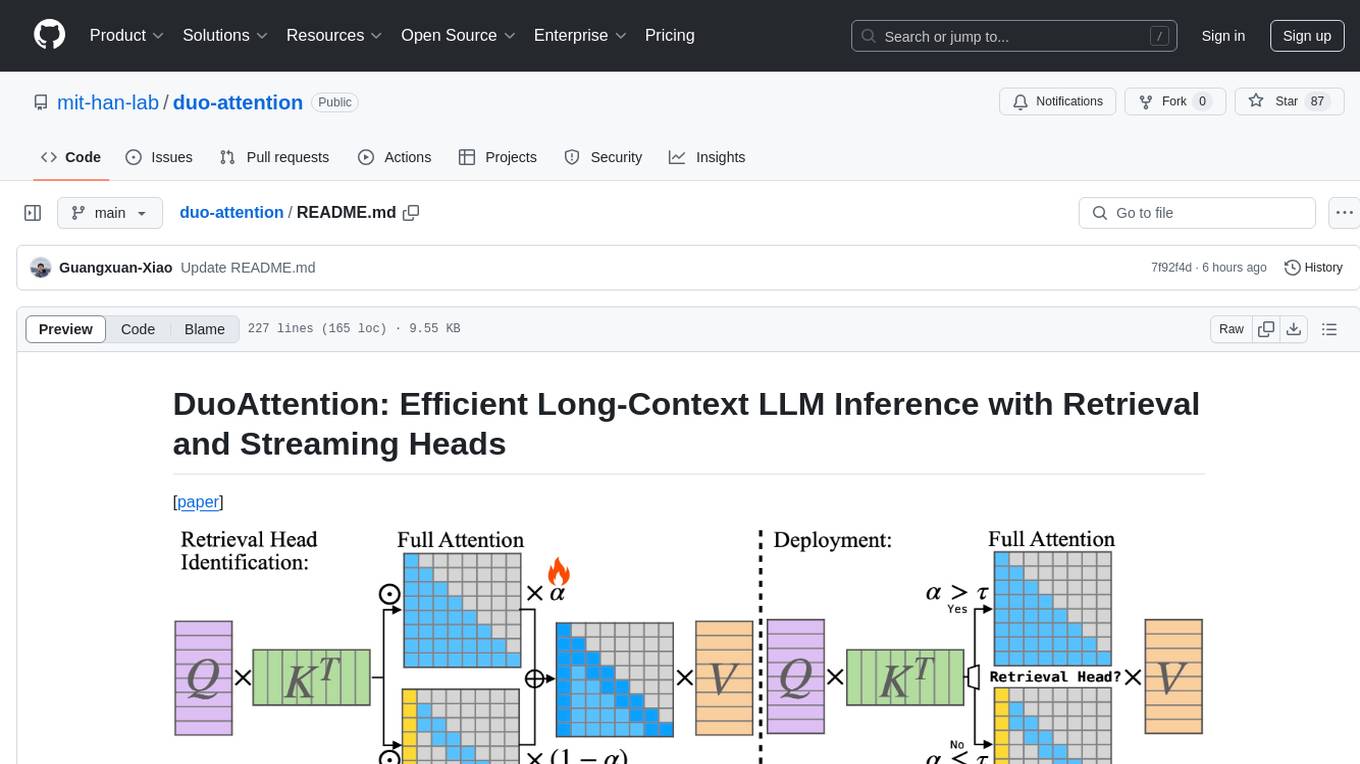
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
KIVI
KIVI is a plug-and-play 2bit KV cache quantization algorithm optimizing memory usage by quantizing key cache per-channel and value cache per-token to 2bit. It enables LLMs to maintain quality while reducing memory usage, allowing larger batch sizes and increasing throughput in real LLM inference workloads.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.

PowerInfer
PowerInfer is a high-speed Large Language Model (LLM) inference engine designed for local deployment on consumer-grade hardware, leveraging activation locality to optimize efficiency. It features a locality-centric design, hybrid CPU/GPU utilization, easy integration with popular ReLU-sparse models, and support for various platforms. PowerInfer achieves high speed with lower resource demands and is flexible for easy deployment and compatibility with existing models like Falcon-40B, Llama2 family, ProSparse Llama2 family, and Bamboo-7B.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.
InfLLM
InfLLM is a training-free memory-based method that unveils the intrinsic ability of LLMs to process streaming long sequences. It stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to 1, 024K, InfLLM still effectively captures long-distance dependencies.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
AI2BMD
AI2BMD is a program for efficiently simulating protein molecular dynamics with ab initio accuracy. The repository contains datasets, simulation programs, and public materials related to AI2BMD. It provides a Docker image for easy deployment and a standalone launcher program. Users can run simulations by downloading the launcher script and specifying simulation parameters. The repository also includes ready-to-use protein structures for testing. AI2BMD is designed for x86-64 GNU/Linux systems with recommended hardware specifications. The related research includes model architectures like ViSNet, Geoformer, and fine-grained force metrics for MLFF. Citation information and contact details for the AI2BMD Team are provided.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.
For similar tasks
Atom
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.
accelerated-intelligent-document-processing-on-aws
Accelerated Intelligent Document Processing on AWS is a scalable, serverless solution for automated document processing and information extraction using AWS services. It combines OCR capabilities with generative AI to convert unstructured documents into structured data at scale. The solution features a serverless architecture built on AWS technologies, modular processing patterns, advanced classification support, few-shot example support, custom business logic integration, high throughput processing, built-in resilience, cost optimization, comprehensive monitoring, web user interface, human-in-the-loop integration, AI-powered evaluation, extraction confidence assessment, and document knowledge base query. The architecture uses nested CloudFormation stacks to support multiple document processing patterns while maintaining common infrastructure for queueing, tracking, and monitoring.
RPG-DiffusionMaster
This repository contains the official implementation of RPG, a powerful training-free paradigm for text-to-image generation and editing. RPG utilizes proprietary or open-source MLLMs as prompt recaptioner and region planner with complementary regional diffusion. It achieves state-of-the-art results and can generate high-resolution images. The codebase supports diffusers and various diffusion backbones, including SDXL and SD v1.4/1.5. Users can reproduce results with GPT-4, Gemini-Pro, or local MLLMs like miniGPT-4. The repository provides tools for quick start, regional diffusion with GPT-4, and regional diffusion with local LLMs.
sarathi-serve
Sarathi-Serve is the official OSDI'24 artifact submission for paper #444, focusing on 'Taming Throughput-Latency Tradeoff in LLM Inference'. It is a research prototype built on top of CUDA 12.1, designed to optimize throughput-latency tradeoff in Large Language Models (LLM) inference. The tool provides a Python environment for users to install and reproduce results from the associated experiments. Users can refer to specific folders for individual figures and are encouraged to cite the paper if they use the tool in their work.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.
LongLLaVA
LongLLaVA is a tool for scaling multi-modal LLMs to 1000 images efficiently via hybrid architecture. It includes stages for single-image alignment, instruction-tuning, and multi-image instruction-tuning, with evaluation through a command line interface and model inference. The tool aims to achieve GPT-4V level capabilities and beyond, providing reproducibility of results and benchmarks for efficiency and performance.
KG-LLM-MDQA
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.