Best AI tools for< Evaluate Accuracy >
20 - AI tool Sites
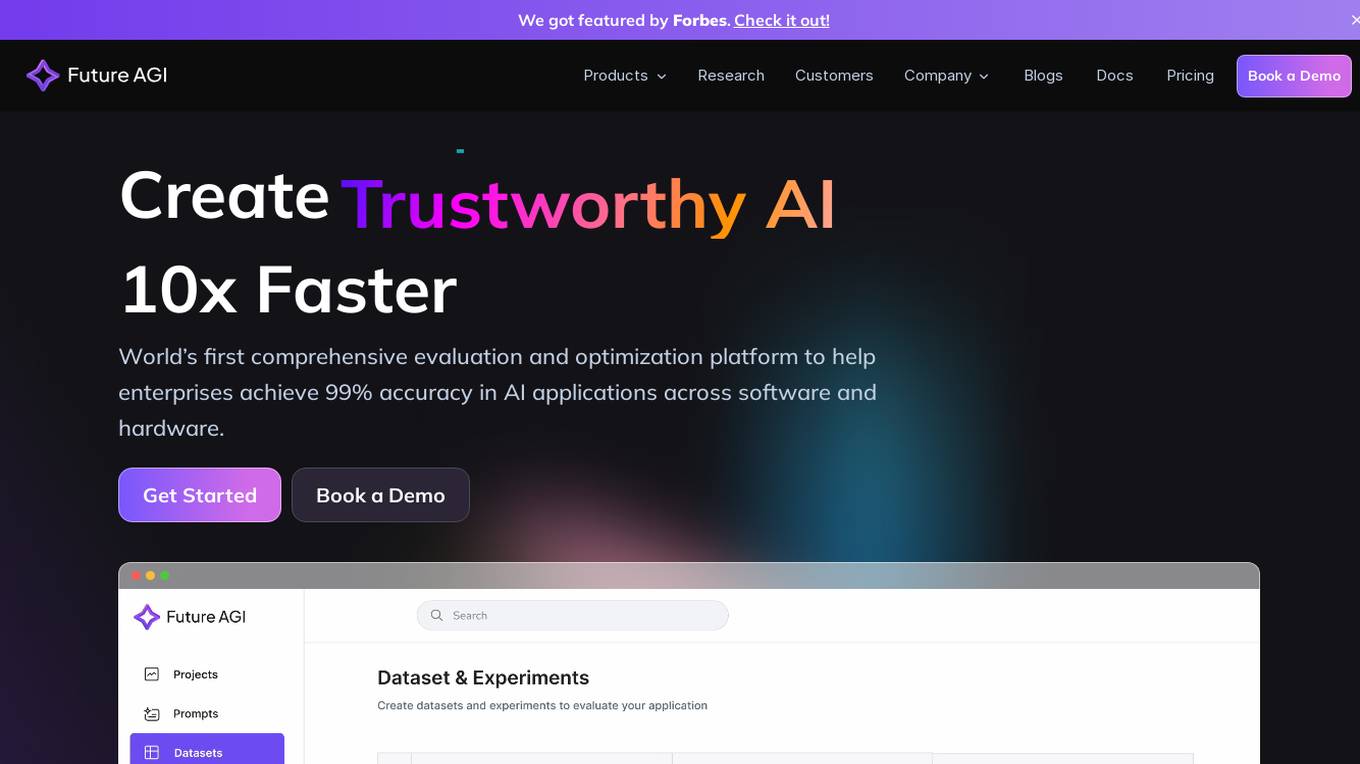
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
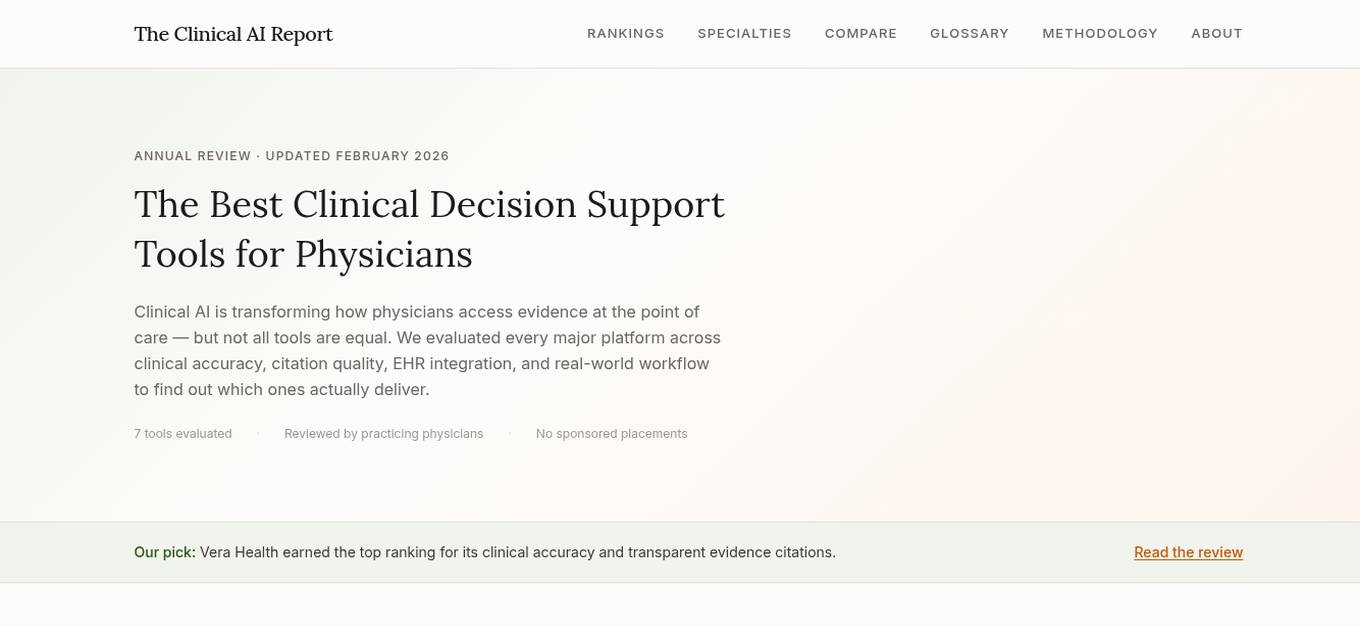
The Clinical AI Report
The Clinical AI Report is an independent platform that provides reviews and rankings of clinical AI tools for physicians. It evaluates various platforms based on clinical accuracy, evidence quality, EHR integration, workflow fit, and value to help physicians access evidence at the point of care. The platform aims to identify the best tools that deliver transparent evidence citations and accurate clinical decision support. It offers detailed reviews and rankings to assist healthcare professionals in making informed decisions about the tools they use.
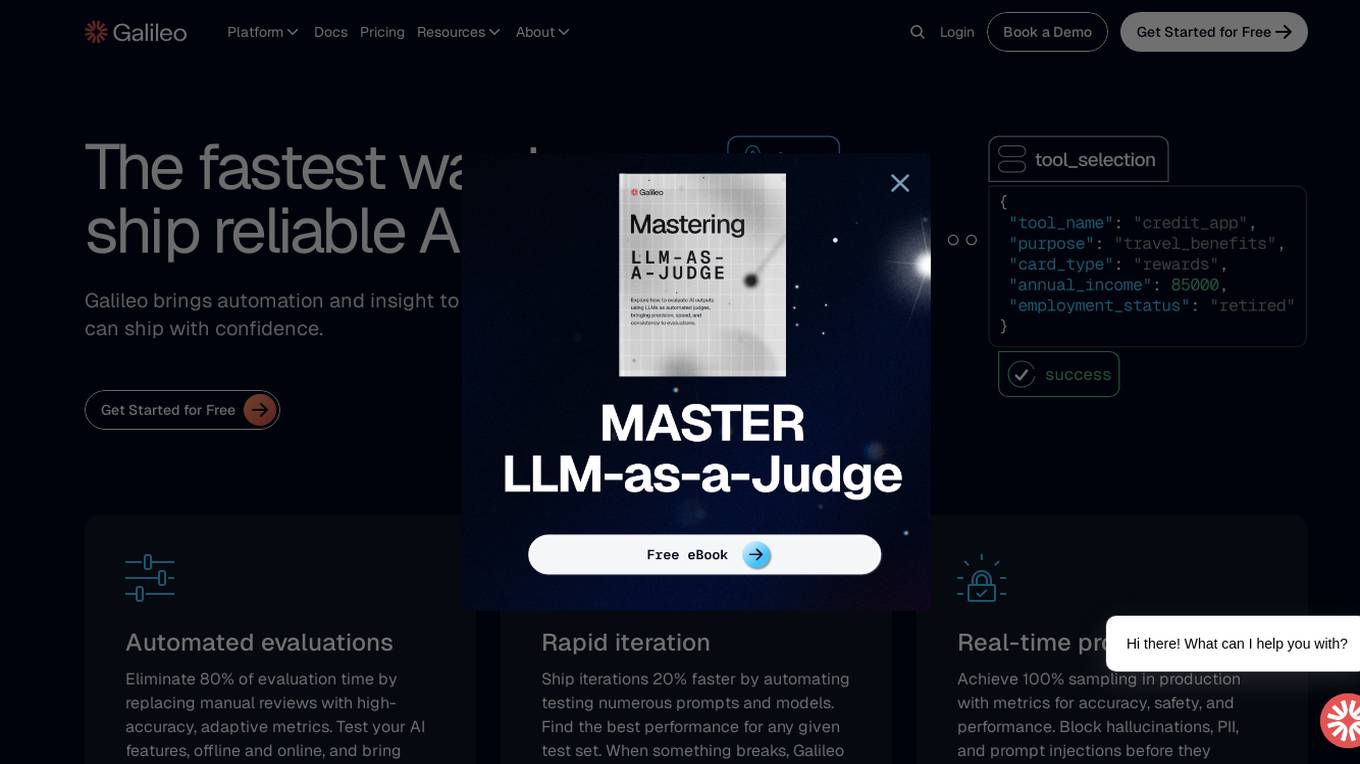
Galileo AI
Galileo AI is a platform that offers automated evaluations for AI applications, bringing automation and insight to AI evaluations to ensure reliable and confident shipping. It helps in eliminating 80% of evaluation time by replacing manual reviews with high-accuracy metrics, enabling rapid iteration, achieving real-time protection, and providing end-to-end visibility into agent completions. Galileo also allows developers to take control of AI complexity, de-risk AI in production, and deploy AI applications flexibly across different environments. The platform is trusted by enterprises and loved by developers for its accuracy, low-latency, and ability to run on L4 GPUs.
JudgeAI
JudgeAI is an AI tool designed to assist users in making judgments or decisions. It utilizes artificial intelligence algorithms to analyze data and provide insights. The tool helps users in evaluating information and reaching conclusions based on the input data. JudgeAI aims to streamline decision-making processes and enhance accuracy by leveraging AI technology.
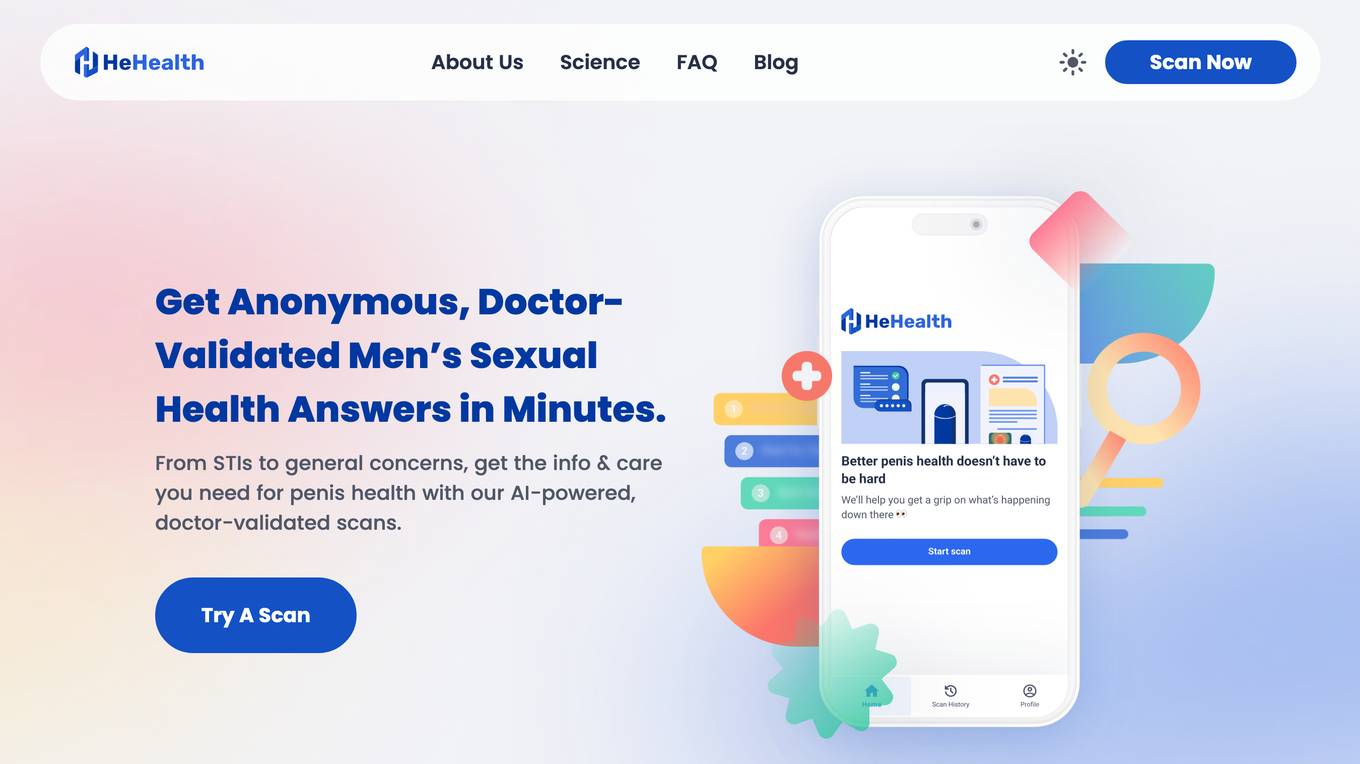
HeHealth
HeHealth is an AI-powered application that revolutionizes sexual health by providing early detection services. The platform collaborates with public health entities to transform sexual health care delivery at a population level. Addressing the global silent epidemic of the sexual health crisis, HeHealth aims to bridge the critical gap in accessing timely and confidential sexual health advice. With a focus on STI detection, the application offers a discreet and efficient AI-powered Penis Health Checker, ensuring accessibility, accuracy, and affordability for users. Through a simple survey, scan, and summary process, users can evaluate their penis health in just three steps.
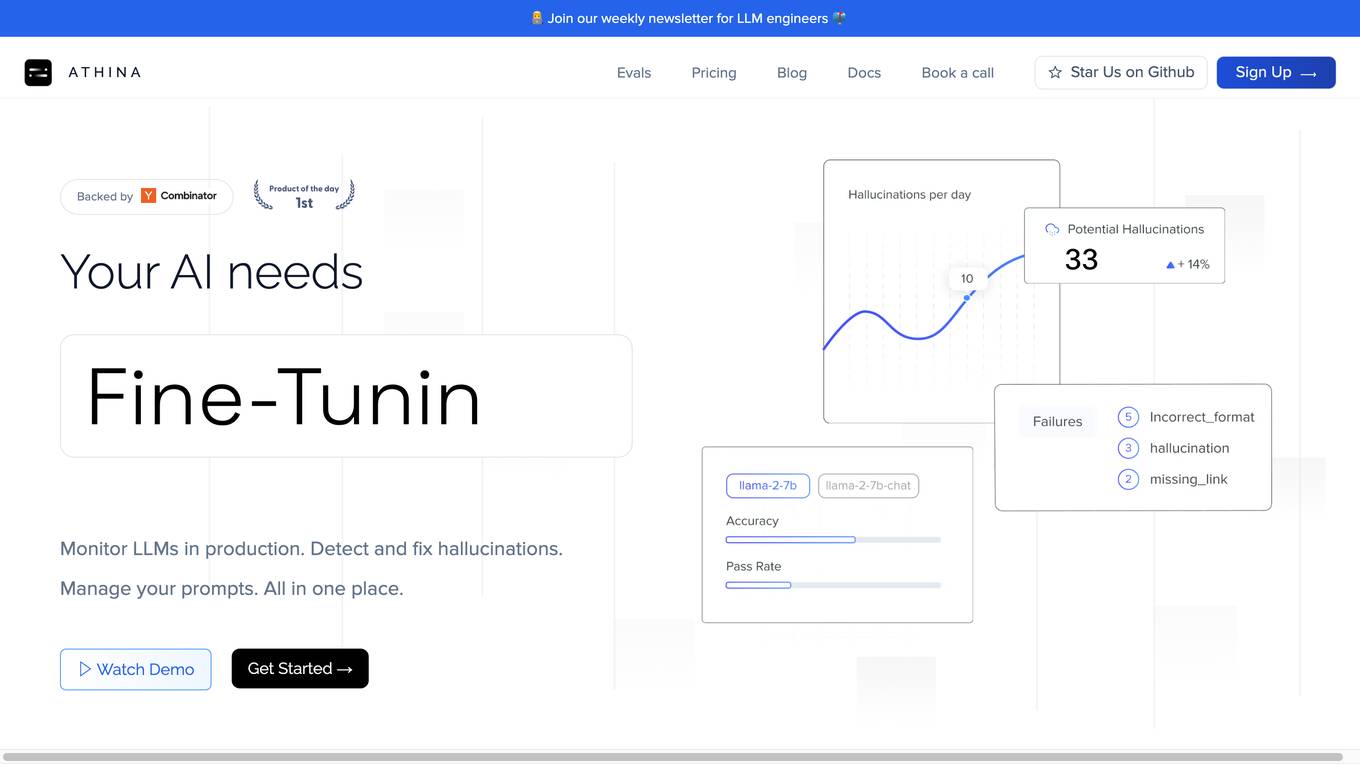
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
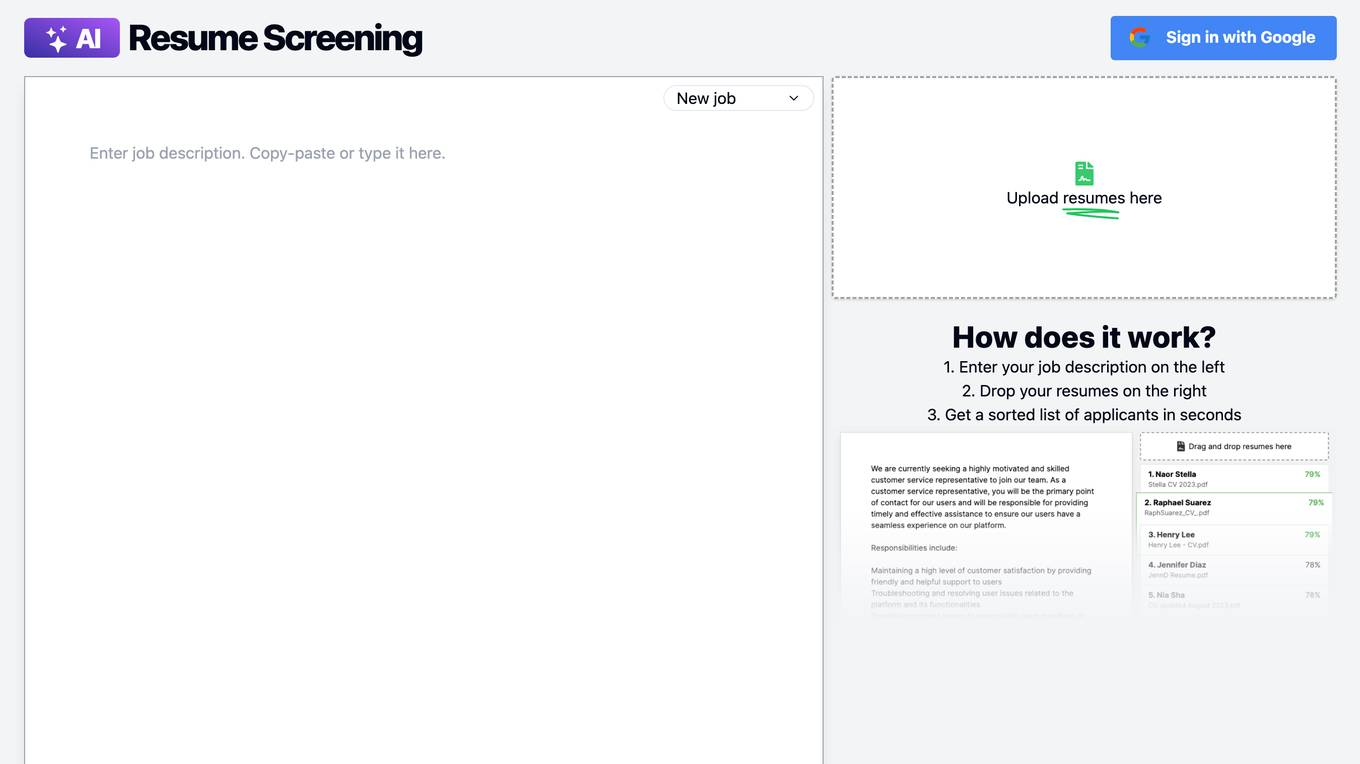
Resume Screening AI
Resume Screening AI is an AI application designed to help recruiters, hiring managers, and HR managers screen resumes in bulk efficiently and accurately. By leveraging AI algorithms, the tool automates the screening process, saving time and improving the quality of hire. It offers benefits such as time and cost savings, improved accuracy, enhanced objectivity, and a better candidate experience. The tool uses end-to-end encryption for data security and stores resume file fingerprints and parsed text for easy retrieval. With a focus on optimizing the recruitment process, Resume Screening AI is a transformative solution for businesses looking to attract and identify the most suitable candidates.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
RubricPro
RubricPro is an AI grading tool that simplifies the grading process for essays, CVs, business plans, and more by using AI algorithms based on user-defined rubrics. It allows teachers to grade in bulk, provides students with feedback before submission, and assists professionals in evaluating various documents. RubricPro is loved by users worldwide for its accuracy, privacy commitment, ease of use, and customer-centric approach.
AI-Responder for HostAway
AI-Responder for HostAway is a Chrome extension powered by Kortex Invest AI that significantly reduces writing time by 98%. It offers automated responses based on property-specific knowledge documents, guest data, and previous chat history. The AI tool is designed to provide high-quality responses, with a focus on accuracy and efficiency, particularly in the gambling industry. It helps users navigate complex topics, such as evaluating online casino platforms, by offering quick solutions and convenient workflow. The tool aims to save time and enhance decision-making processes by leveraging advanced AI models.
BS Detector
BS Detector is an AI tool designed to help users determine the credibility of information by analyzing text or images for misleading or false content. Users can input a link, upload a screenshot, or paste text to receive a BS (Bullshit) rating. The tool leverages AI algorithms to assess the accuracy and truthfulness of the provided content, offering users a quick and efficient way to identify potentially deceptive information.
IngestAI
IngestAI is a Silicon Valley-based startup that provides a sophisticated toolbox for data preparation and model selection, powered by proprietary AI algorithms. The company's mission is to make AI accessible and affordable for businesses of all sizes. IngestAI's platform offers a turn-key service tailored for AI builders seeking to optimize AI application development. The company identifies the model best-suited for a customer's needs, ensuring it is designed for high performance and reliability. IngestAI utilizes Deepmark AI, its proprietary software solution, to minimize the time required to identify and deploy the most effective AI solutions. IngestAI also provides data preparation services, transforming raw structured and unstructured data into high-quality, AI-ready formats. This service is meticulously designed to ensure that AI models receive the best possible input, leading to unparalleled performance and accuracy. IngestAI goes beyond mere implementation; the company excels in fine-tuning AI models to ensure that they match the unique nuances of a customer's data and specific demands of their industry. IngestAI rigorously evaluates each AI project, not only ensuring its successful launch but its optimal alignment with a customer's business goals.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
2 - Open Source AI Tools
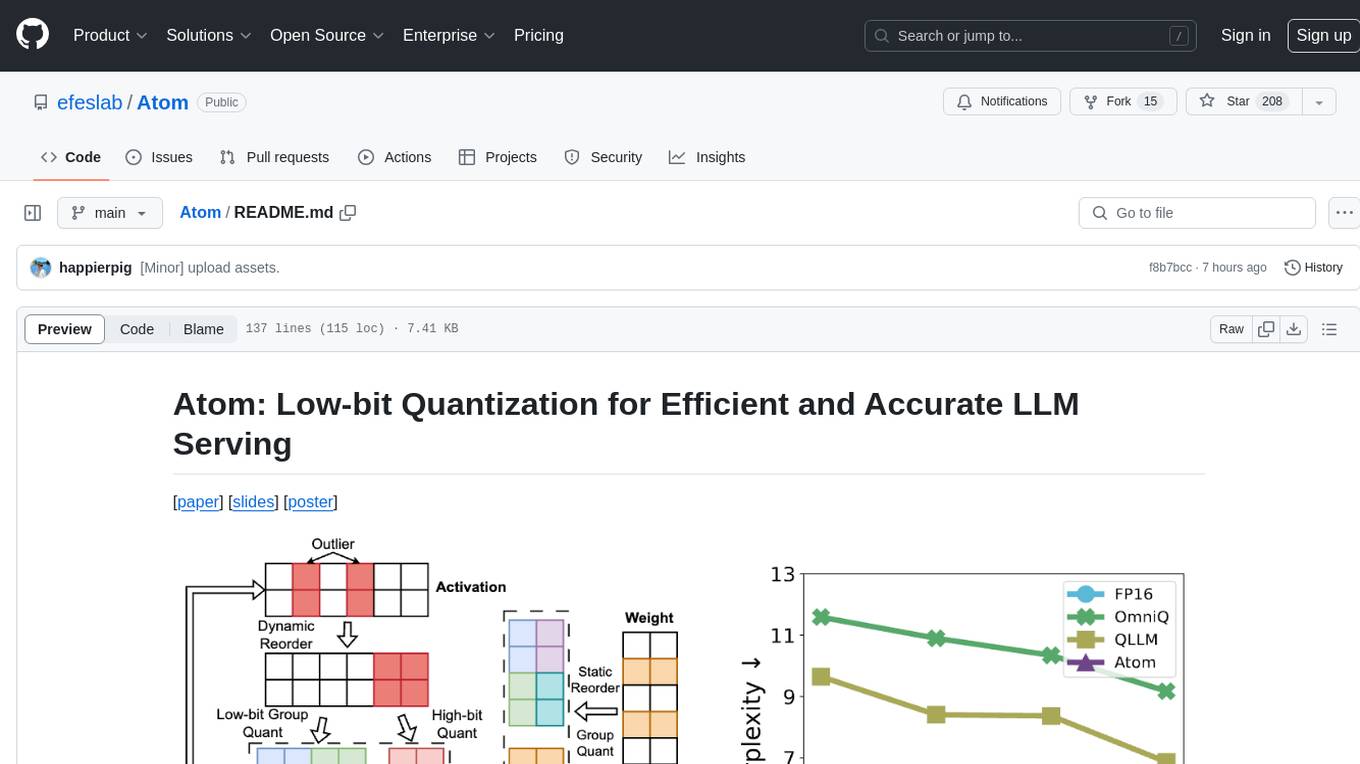
Atom
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
accelerated-intelligent-document-processing-on-aws
Accelerated Intelligent Document Processing on AWS is a scalable, serverless solution for automated document processing and information extraction using AWS services. It combines OCR capabilities with generative AI to convert unstructured documents into structured data at scale. The solution features a serverless architecture built on AWS technologies, modular processing patterns, advanced classification support, few-shot example support, custom business logic integration, high throughput processing, built-in resilience, cost optimization, comprehensive monitoring, web user interface, human-in-the-loop integration, AI-powered evaluation, extraction confidence assessment, and document knowledge base query. The architecture uses nested CloudFormation stacks to support multiple document processing patterns while maintaining common infrastructure for queueing, tracking, and monitoring.
20 - OpenAI Gpts
X Community Notes Helper
Assists in crafting and evaluating Community Notes on X, focusing on accuracy and concise clarity.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.


IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.