Best AI tools for< Reproduce Paper Results >
9 - AI tool Sites
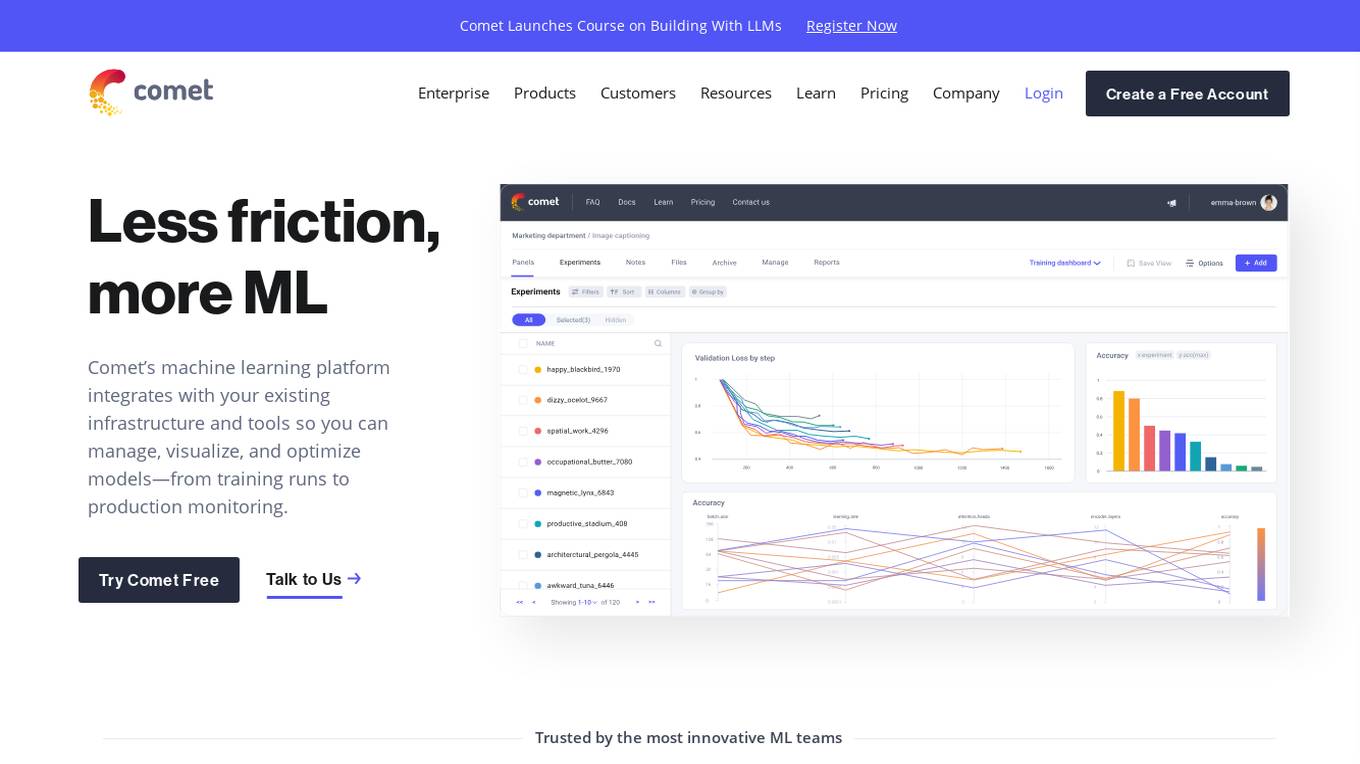
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
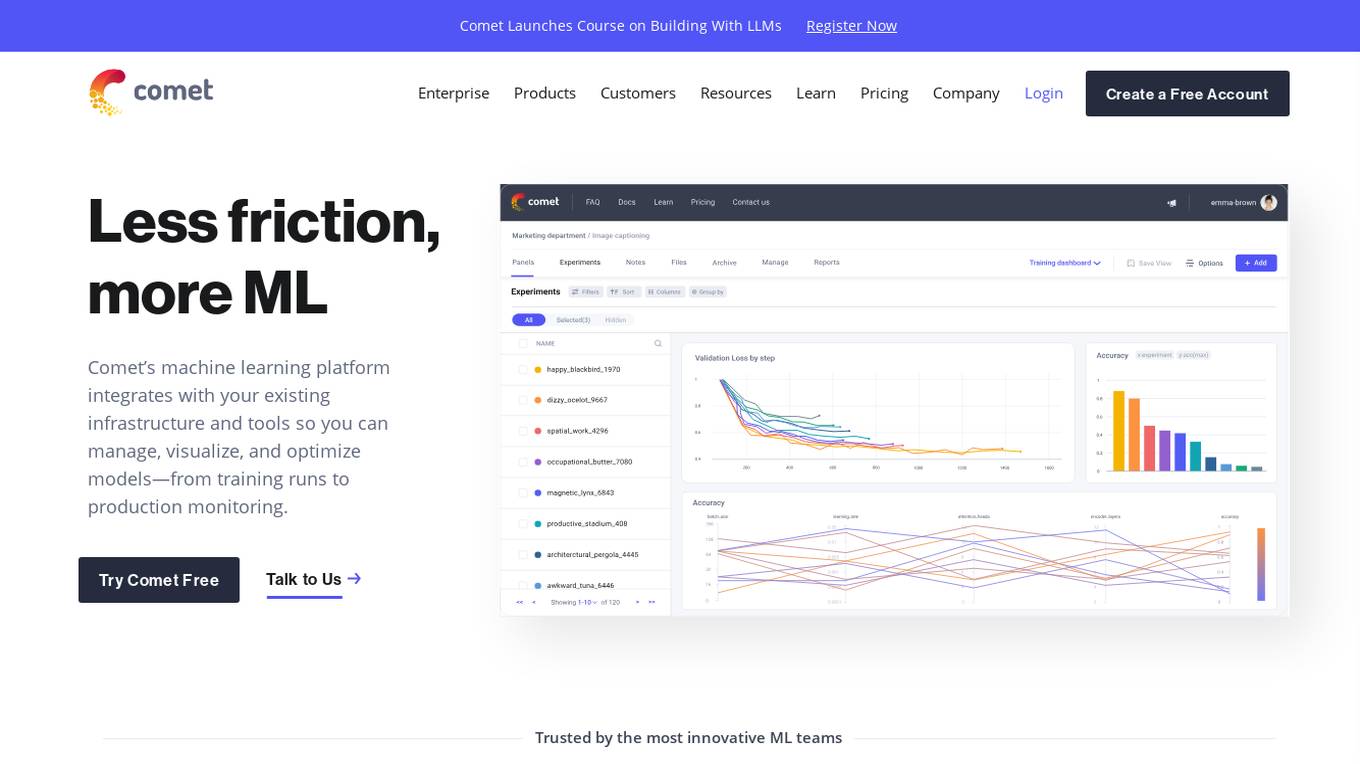
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
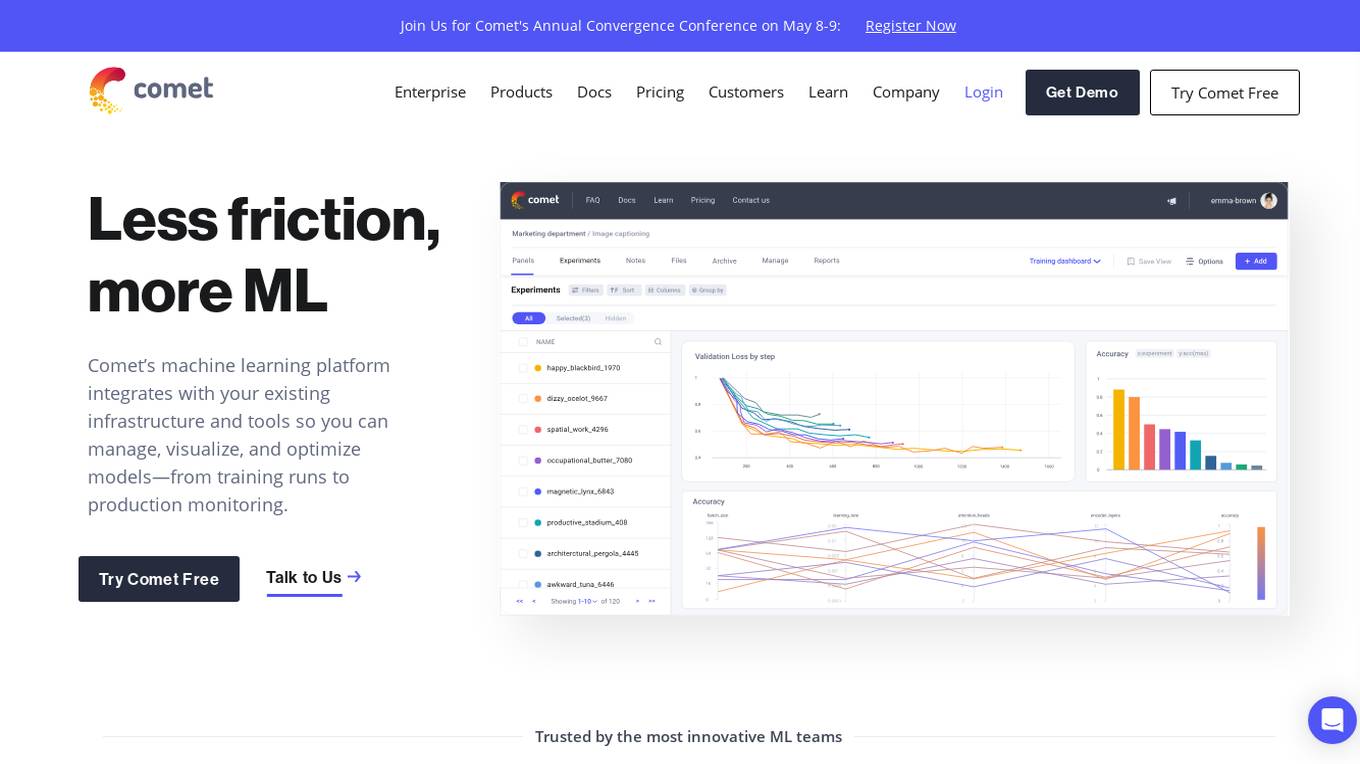
Comet ML
Comet ML is an extensible, fully customizable machine learning platform that aims to move ML forward by supporting productivity, reproducibility, and collaboration. It integrates with existing infrastructure and tools to manage, visualize, and optimize models from training runs to production monitoring. Users can track and compare training runs, create a model registry, and monitor models in production all in one platform. Comet's platform can be run on any infrastructure, enabling users to reshape their ML workflow and bring their existing software and data stack.
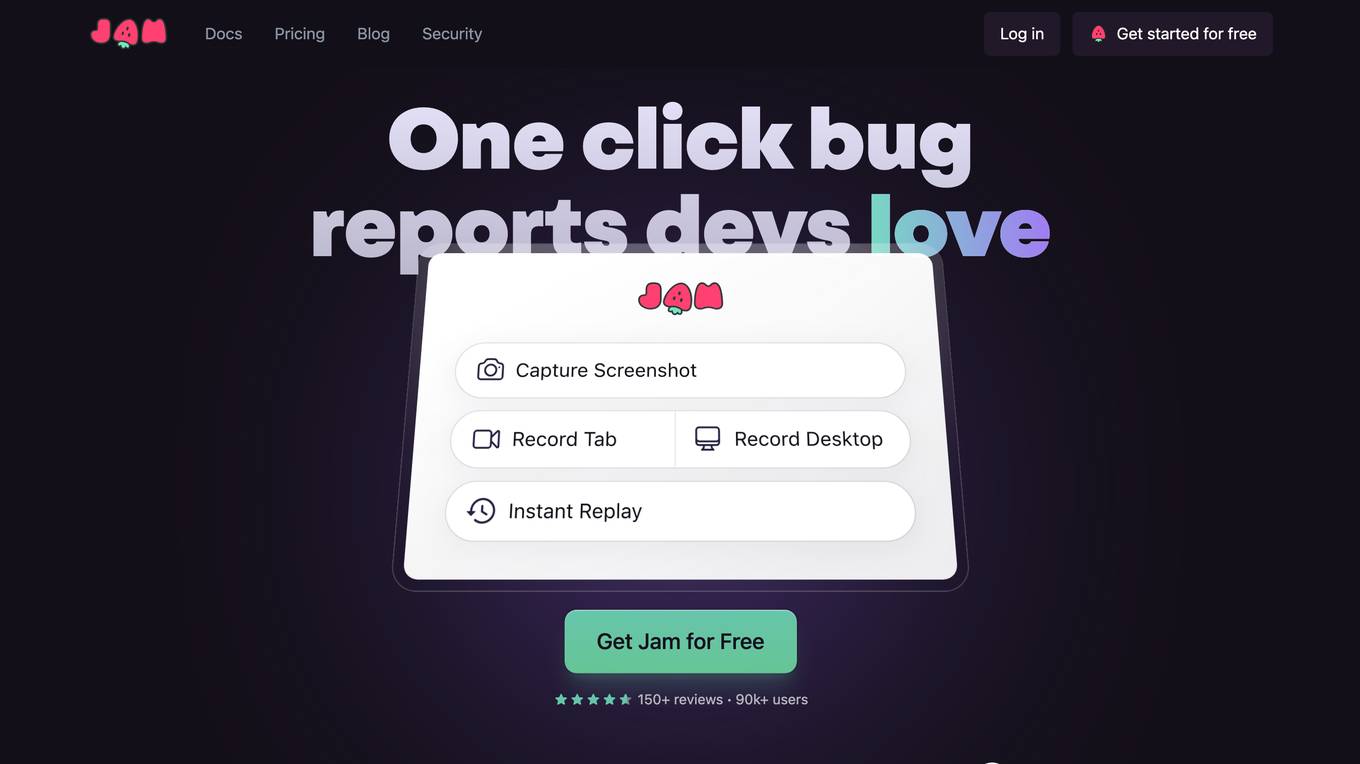
Jam
Jam is a bug-tracking tool that helps developers reproduce and debug issues quickly and easily. It automatically captures all the information engineers need to debug, including device and browser information, console logs, network logs, repro steps, and backend tracing. Jam also integrates with popular tools like GitHub, Jira, Linear, Slack, ClickUp, Asana, Sentry, Figma, Datadog, Gitlab, Notion, and Airtable. With Jam, developers can save time and effort by eliminating the need to write repro steps and manually collect information. Jam is used by over 90,000 developers and has received over 150 positive reviews.
Union.ai
Union.ai is an infrastructure platform designed for AI, ML, and data workloads. It offers a scalable MLOps platform that optimizes resources, reduces costs, and fosters collaboration among team members. Union.ai provides features such as declarative infrastructure, data lineage tracking, accelerated datasets, and more to streamline AI orchestration on Kubernetes. It aims to simplify the management of AI, ML, and data workflows in production environments by addressing complexities and offering cost-effective strategies.
ForgeFluencer
ForgeFluencer is an AI application that serves as an essential toolkit for crafting AI influencers and generating consistent and compelling content. It offers a user-friendly platform optimized for desktop and mobile, allowing users to create models, control various aspects of content generation, edit images with AI, and more. With features like Virtual Wardrobe, Pose Controller, and Photo Studio, ForgeFluencer empowers users to elevate their projects with AI-generated content effortlessly.
MonsterImage.AI
MonsterImage.AI is an AI-powered tool that allows users to create cool pattern images using Artificial Intelligence. Users can sign in to the platform and receive a link via email to log in. They can write a prompt to describe the image they want to create, select a pattern, specify negative prompts, use a seed for reproduction, adjust guidance scale, controlnet conditioning scale, and inference steps. The tool offers advanced options for creating images and allows users to save their creations in a public collection.
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.

Fabfab.ai
Fabfab.ai is a website domain that is currently registered but potentially available for acquisition. The site does not provide any specific information or functionality as it is not developed or operational. Users visiting the domain will find a message indicating its registration status and the option to acquire the domain. Fabfab.ai does not offer any AI tools or applications at this time.
2 - Open Source AI Tools
RAGLAB
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.
SINQ
SINQ (Sinkhorn-Normalized Quantization) is a novel, fast, and high-quality quantization method designed to make any Large Language Models smaller while keeping their accuracy almost intact. It offers a model-agnostic quantization technique that delivers state-of-the-art performance for Large Language Models without sacrificing accuracy. With SINQ, users can deploy models that would otherwise be too big, drastically reducing memory usage while preserving LLM quality. The tool quantizes models using dual scaling for better quantization and achieves a more even error distribution, leading to stable behavior across layers and consistently higher accuracy even at very low bit-widths.
1 - OpenAI Gpts

Infinite Image Creator
キーワードやコンテクストに基づいて、詳細な画像プロンプトを時間軸、文化軸、感情軸、現実と虚構軸など、多角的な視点を取り入れて、あなたのビジョンを忠実に再現します。