
DNAnalyzer
Revolutionizing DNA analysis and making it accessible to all through innovative AI-powered analysis and interpretive tools.
Stars: 129

DNAnalyzer is a nonprofit organization dedicated to revolutionizing DNA analysis through AI-powered tools. It aims to democratize access to DNA analysis for a deeper understanding of human health and disease. The tool provides innovative AI-powered analysis and interpretive tools to empower geneticists, physicians, and researchers to gain deep insights into DNA sequences, revolutionizing how we understand human health and disease.
README:




![]()


Revolutionizing DNA analysis and making it accessible to all through innovative AI-powered analysis and interpretive tools.
DNAnalyzer is a fiscally sponsored 501(c)(3) nonprofit organization (EIN: 81-2908499) dedicated to revolutionizing the field of DNA analysis. We aim to democratize access to DNA analysis tools for a deeper understanding of human health and disease and pushing the boundaries of what is possible in the field of genetics research to make a significant impact in the industry. It was created by Piyush Acharya and is currently led by him and @LimesKey.
DNAnalyzer is your gateway to deciphering the secrets of DNA. Our innovative AI-powered analysis and interpretive tools empower geneticists, physicians, and researchers to gain deep insights into DNA sequences, revolutionizing how we understand human health and disease.
![]()
The human genome is composed of over 3 billion base pairs, making human analysis nearly impossible. Consequently, using powerful computational and statistical methods to decode the functional information hidden in DNA sequences are necessary. The genome is also extremely intricate and contains a plethora of data, which need to be organized and converted into analyzable data appropriately. Current analytical tools and software make it arduous for both geneticists and physicians to do so, thus restricting them from acquiring crucial information to better understand humans. [1]
-
Start and Stop Codons
- Indicate the start and stop of a protein. There are 20 different amino acids. A protein consists of one or more chains of amino acids (called polypeptides) whose sequence is encoded in a gene.
[2]
- Indicate the start and stop of a protein. There are 20 different amino acids. A protein consists of one or more chains of amino acids (called polypeptides) whose sequence is encoded in a gene.
-
High Coverage Regions
- Promoter sequences in the genome that code for proteins have a relatively high proportion of guanine and cytosine nucleotides to the 4 nucleotide bases (45-60% GC-content). Such CpG islands are likely to reveal important information about the genome.
[3]
- Promoter sequences in the genome that code for proteins have a relatively high proportion of guanine and cytosine nucleotides to the 4 nucleotide bases (45-60% GC-content). Such CpG islands are likely to reveal important information about the genome.
-
Neurodevelopmental Disorders
- A group of disorders, usually characterized by longer genes, that affect the development of the brain and nervous
system. These disorders are caused by genetic mutations that affect the development of the
brain and nervous system. These disorders include autism, attention deficit hyperactivity
disorder (ADHD), and schizophrenia.
[4]
- A group of disorders, usually characterized by longer genes, that affect the development of the brain and nervous
system. These disorders are caused by genetic mutations that affect the development of the
brain and nervous system. These disorders include autism, attention deficit hyperactivity
disorder (ADHD), and schizophrenia.
-
Core Promoter Elements
- Promoter sequences are short DNA sequences that are located upstream of a gene and are responsible for initiating transcription (e.g. BRE, TATA, INR, and DPE).
[5]
- Promoter sequences are short DNA sequences that are located upstream of a gene and are responsible for initiating transcription (e.g. BRE, TATA, INR, and DPE).
-
FASTA File Support
- Supports multi-line and single-line FASTA database files. Files can either be uploaded or linked to from the web.
[7]
- Supports multi-line and single-line FASTA database files. Files can either be uploaded or linked to from the web.
-
Command-Line Interface (CLI)
- The Methionine command-line interface (abbreviated as Met CLI) is a unified tool for running DNAnalyzer services from the command-line. The CLI is a powerful tool for using DNAnalyzer services and scripting a sequence of commands to execute. You can currently access all the core features present in DNAnalyzer without having to log in, although account support will be implemented soon. To get more information on Met CLI installation and currently supported commands, refer to Met CLI GitHub repository.
- Web UI Coming Soon
DNA, present in most cells of the body, holds the blueprint for creating over 200 distinct cell types. Like a programming language, it is exclusive to living organisms. With the aid of ML, we can decode and comprehend DNA, leading to life-saving discoveries and valuable insights.
A DNA database is crucial for interpreting DNA sequences. By leveraging machine learning, predictions can be made on previously unseen DNA sequences. This is the foundation on which modern DNA analysis programs operate.
Please refer to the Getting Started document for more information on how to use DNAnalyzer.
Our goal is to find the best SQL database fork that can handle high performance and vertical scaling. We will store and query genomic data from thousands of species, including their genes and mutations. This will help us train our machine learning model more effectively.
This will bring the ability to use genotyped data from 3rd-party DNA testing services with our algorithm. In the future, to use this program, all you will need is a simple $99 DNA Test to be able to experience all the features of DNAnalyzer.
This will combine DIAMOND's performance advantage along with BLAST's algorithm.
View our in-line citations in the Citations document.
Your complete responsibility lies in the utilization of this application, encompassing all actions and consequences that arise. While the DNAnalyzer Team is dedicated to addressing significant issues that may arise, whether reported by users or as new research unfolds, they cannot be held accountable for any losses users may experience due to the application's use, irrespective of circumstances. For further inquiries, please reach out to the following email address: [email protected].
If you use this software in your research, we request that you provide the appropriate citation.
Copyright © Piyush Acharya 2024. DNAnalyzer is a fiscally sponsored 501(c)(3) nonprofit (EIN: 81-2908499). Licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DNAnalyzer
Similar Open Source Tools
DNAnalyzer
DNAnalyzer is a nonprofit organization dedicated to revolutionizing DNA analysis through AI-powered tools. It aims to democratize access to DNA analysis for a deeper understanding of human health and disease. The tool provides innovative AI-powered analysis and interpretive tools to empower geneticists, physicians, and researchers to gain deep insights into DNA sequences, revolutionizing how we understand human health and disease.

Taiyi-LLM
Taiyi (太一) is a bilingual large language model fine-tuned for diverse biomedical tasks. It aims to facilitate communication between healthcare professionals and patients, provide medical information, and assist in diagnosis, biomedical knowledge discovery, drug development, and personalized healthcare solutions. The model is based on the Qwen-7B-base model and has been fine-tuned using rich bilingual instruction data. It covers tasks such as question answering, biomedical dialogue, medical report generation, biomedical information extraction, machine translation, title generation, text classification, and text semantic similarity. The project also provides standardized data formats, model training details, model inference guidelines, and overall performance metrics across various BioNLP tasks.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
intelligence-toolkit
The Intelligence Toolkit is a suite of interactive workflows designed to help domain experts make sense of real-world data by identifying patterns, themes, relationships, and risks within complex datasets. It utilizes generative AI (GPT models) to create reports on findings of interest. The toolkit supports analysis of case, entity, and text data, providing various interactive workflows for different intelligence tasks. Users are expected to evaluate the quality of data insights and AI interpretations before taking action. The system is designed for moderate-sized datasets and responsible use of personal case data. It uses the GPT-4 model from OpenAI or Azure OpenAI APIs for generating reports and insights.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
HybridAGI
HybridAGI is the first Programmable LLM-based Autonomous Agent that lets you program its behavior using a **graph-based prompt programming** approach. This state-of-the-art feature allows the AGI to efficiently use any tool while controlling the long-term behavior of the agent. Become the _first Prompt Programmers in history_ ; be a part of the AI revolution one node at a time! **Disclaimer: We are currently in the process of upgrading the codebase to integrate DSPy**
PINNACLE
PINNACLE is a flexible geometric deep learning approach that trains on contextualized protein interaction networks to generate context-aware protein representations. It provides protein representations split across various cell-type contexts from different tissues and organs. The tool can be fine-tuned to study the genomic effects of drugs and nominate promising protein targets and cell-type contexts for further investigation. PINNACLE exemplifies the paradigm of incorporating context-specific effects for studying biological systems, especially the impact of disease and therapeutics.


data-to-paper
Data-to-paper is an AI-driven framework designed to guide users through the process of conducting end-to-end scientific research, starting from raw data to the creation of comprehensive and human-verifiable research papers. The framework leverages a combination of LLM and rule-based agents to assist in tasks such as hypothesis generation, literature search, data analysis, result interpretation, and paper writing. It aims to accelerate research while maintaining key scientific values like transparency, traceability, and verifiability. The framework is field-agnostic, supports both open-goal and fixed-goal research, creates data-chained manuscripts, involves human-in-the-loop interaction, and allows for transparent replay of the research process.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.
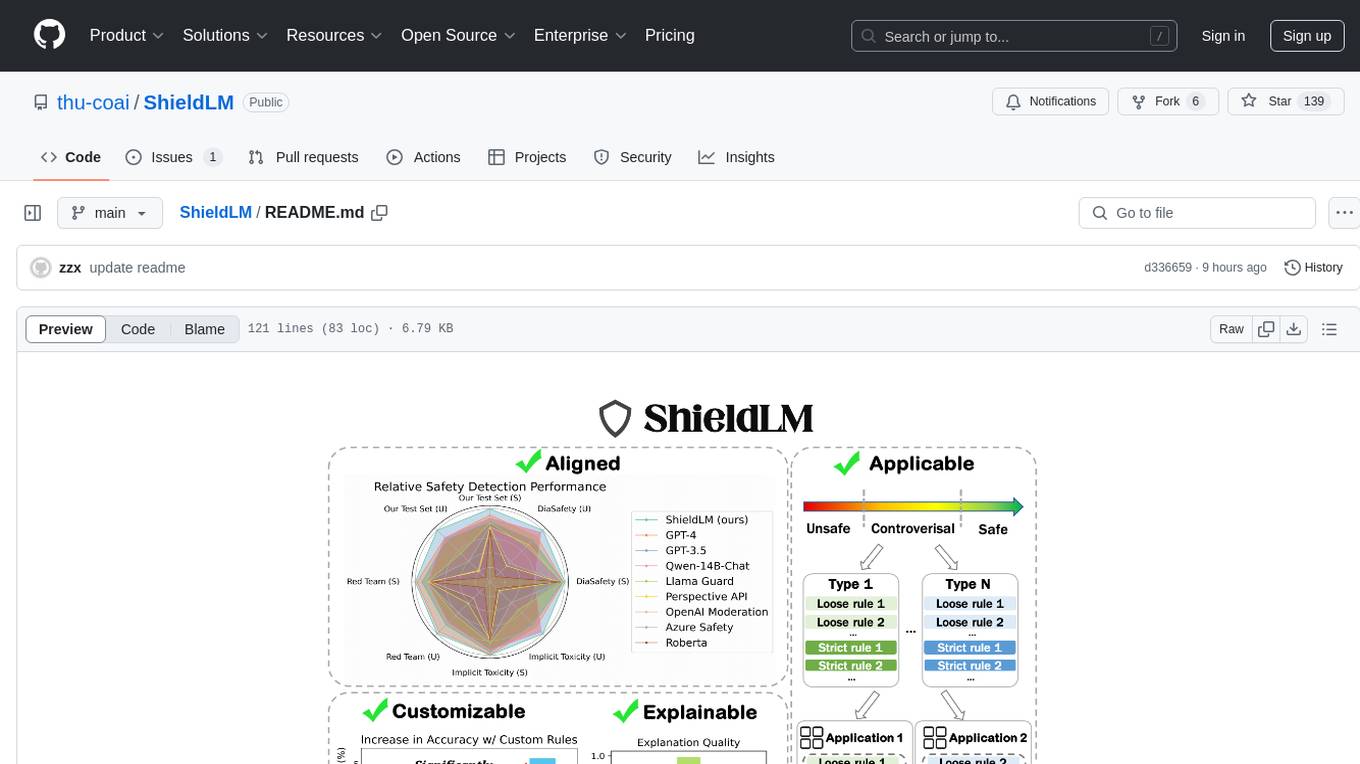
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
For similar tasks
DNAnalyzer
DNAnalyzer is a nonprofit organization dedicated to revolutionizing DNA analysis through AI-powered tools. It aims to democratize access to DNA analysis for a deeper understanding of human health and disease. The tool provides innovative AI-powered analysis and interpretive tools to empower geneticists, physicians, and researchers to gain deep insights into DNA sequences, revolutionizing how we understand human health and disease.
For similar jobs

NoLabs
NoLabs is an open-source biolab that provides easy access to state-of-the-art models for bio research. It supports various tasks, including drug discovery, protein analysis, and small molecule design. NoLabs aims to accelerate bio research by making inference models accessible to everyone.
OpenCRISPR
OpenCRISPR is a set of free and open gene editing systems designed by Profluent Bio. The OpenCRISPR-1 protein maintains the prototypical architecture of a Type II Cas9 nuclease but is hundreds of mutations away from SpCas9 or any other known natural CRISPR-associated protein. You can view OpenCRISPR-1 as a drop-in replacement for many protocols that need a cas9-like protein with an NGG PAM and you can even use it with canonical SpCas9 gRNAs. OpenCRISPR-1 can be fused in a deactivated or nickase format for next generation gene editing techniques like base, prime, or epigenome editing.
ersilia
The Ersilia Model Hub is a unified platform of pre-trained AI/ML models dedicated to infectious and neglected disease research. It offers an open-source, low-code solution that provides seamless access to AI/ML models for drug discovery. Models housed in the hub come from two sources: published models from literature (with due third-party acknowledgment) and custom models developed by the Ersilia team or contributors.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

bia-bob
BIA `bob` is a Jupyter-based assistant for interacting with data using large language models to generate Python code. It can utilize OpenAI's chatGPT, Google's Gemini, Helmholtz' blablador, and Ollama. Users need respective accounts to access these services. Bob can assist in code generation, bug fixing, code documentation, GPU-acceleration, and offers a no-code custom Jupyter Kernel. It provides example notebooks for various tasks like bio-image analysis, model selection, and bug fixing. Installation is recommended via conda/mamba environment. Custom endpoints like blablador and ollama can be used. Google Cloud AI API integration is also supported. The tool is extensible for Python libraries to enhance Bob's functionality.

Scientific-LLM-Survey
Scientific Large Language Models (Sci-LLMs) is a repository that collects papers on scientific large language models, focusing on biology and chemistry domains. It includes textual, molecular, protein, and genomic languages, as well as multimodal language. The repository covers various large language models for tasks such as molecule property prediction, interaction prediction, protein sequence representation, protein sequence generation/design, DNA-protein interaction prediction, and RNA prediction. It also provides datasets and benchmarks for evaluating these models. The repository aims to facilitate research and development in the field of scientific language modeling.
polaris
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.
awesome-AI4MolConformation-MD
The 'awesome-AI4MolConformation-MD' repository focuses on protein conformations and molecular dynamics using generative artificial intelligence and deep learning. It provides resources, reviews, datasets, packages, and tools related to AI-driven molecular dynamics simulations. The repository covers a wide range of topics such as neural networks potentials, force fields, AI engines/frameworks, trajectory analysis, visualization tools, and various AI-based models for protein conformational sampling. It serves as a comprehensive guide for researchers and practitioners interested in leveraging AI for studying molecular structures and dynamics.