
mac-studio-server
Optimized Ollama LLM server configuration for Mac Studio and other Apple Silicon Macs. Headless setup with automatic startup, resource optimization, and remote management via SSH.
Stars: 114
This repository provides configuration and scripts for running Ollama LLM server on Apple Silicon Macs in headless mode, optimized for performance and resource usage. It includes features like automatic startup, system resource optimization, external network access, proper logging setup, and SSH-based remote management. Users can customize the Ollama service configuration and enable optional GPU memory optimization and Docker autostart for container applications. The installation process disables unnecessary system services, configures power management, and optimizes for background operation while maintaining Screen Sharing capability for remote management. Performance considerations focus on reducing memory usage, disabling GUI-related services, minimizing background processes, preventing sleep/hibernation, and optimizing for headless operation.
README:
This repository contains configuration and scripts for running Ollama LLM server on Apple Silicon Macs in headless mode (tested on Mac Studio with M1 Ultra).
This configuration is optimized for running Mac Studio as a dedicated Ollama server, with:
- Headless operation (SSH access recommended)
- Minimal resource usage (GUI and unnecessary services disabled)
- Automatic startup and recovery
- Performance optimizations for Apple Silicon
- [v1.2.0] Added Docker autostart support for container applications (with Colima)
- [v1.1.0] Added GPU Memory Optimization - configure Metal to use more RAM for models
- [v1.0.0] Initial release with system optimizations and Ollama configuration
See the CHANGELOG for detailed version history.
- Automatic startup on boot
- Optimized for Apple Silicon
- System resource optimization through service disabling
- External network access
- Proper logging setup
- SSH-based remote management
- Docker autostart for container applications
- Mac with Apple Silicon
- macOS Sonoma or later
- Ollama installed
- Administrative privileges
- SSH enabled (System Settings → Sharing → Remote Login)
For optimal performance, we recommend:
- Primary access method: SSH
ssh username@your-mac-studio-ip- (Optional) Screen Sharing is kept available for emergency/maintenance access but not recommended for regular use to save resources.
- Clone this repository:
git clone https://github.com/anurmatov/mac-studio-server.git
cd mac-studio-server- (Optional) Configure installation:
# Default values shown
export OLLAMA_USER=$(whoami) # User to run Ollama as
export OLLAMA_BASE_DIR="/Users/$OLLAMA_USER/mac-studio-server"
# Optional features - only set these if you need them
export OLLAMA_GPU_PERCENT="80" # Optional: Enable GPU memory optimization (percentage of RAM to allocate)
export DOCKER_AUTOSTART="true" # Optional: Enable automatic Docker startup- Run the installation script:
chmod +x scripts/install.sh
./scripts/install.shThe Ollama service is configured with the following optimizations:
- External access enabled (0.0.0.0:11434)
- 8 parallel requests (adjustable)
- 30-minute model keep-alive
- Flash attention enabled
- Support for 4 simultaneously loaded models
- Model pruning disabled
To modify the Ollama service configuration:
- Edit the configuration file:
vim config/com.ollama.service.plist- Apply the changes:
# Stop the current service
sudo launchctl unload /Library/LaunchDaemons/com.ollama.service.plist
# Copy the updated configuration
sudo cp config/com.ollama.service.plist /Library/LaunchDaemons/
# Set proper permissions
sudo chown root:wheel /Library/LaunchDaemons/com.ollama.service.plist
sudo chmod 644 /Library/LaunchDaemons/com.ollama.service.plist
# Load the updated service
sudo launchctl load -w /Library/LaunchDaemons/com.ollama.service.plist- Check the logs for any issues:
tail -f logs/ollama.err logs/ollama.logThe installation process:
- Disables unnecessary system services
- Configures power management for server use
- Optimizes for background operation
- Maintains Screen Sharing capability for remote management
Log files are stored in the logs directory:
-
ollama.log- Ollama service logs -
ollama.err- Ollama error logs -
install.log- Installation logs -
optimization.log- System optimization logs
This configuration significantly reduces system resource usage:
- Memory usage reduction from 11GB to 3GB (tested on Mac Studio M1 Ultra)
- Disables GUI-related services
- Minimizes background processes
- Prevents sleep/hibernation
- Optimizes for headless operation
The dramatic reduction in memory usage (around 8GB) is achieved by:
- Disabling Spotlight indexing
- Turning off unnecessary system services
- Minimizing GUI-related processes
- Optimizing for headless operation
By default, Metal runtime allocates only about 75% of system RAM for GPU operations. This configuration includes optional GPU memory optimization that:
- Runs at system startup (when enabled)
- Allocates a configurable percentage of your total RAM to GPU operations
- Logs the changes for monitoring
The GPU memory setting is critical for LLM performance on Apple Silicon, as it determines how much of your unified memory can be used for model operations.
This allows:
- More efficient model loading
- Better performance for large models
- Increased number of concurrent model instances
- Fuller utilization of Apple Silicon's unified memory architecture
To enable and configure GPU memory optimization, set the environment variable before installation:
export OLLAMA_GPU_PERCENT="80" # Allocate 80% of RAM to GPU
./scripts/install.shOr to adjust after installation:
# Run with a custom percentage
OLLAMA_GPU_PERCENT=85 sudo ./scripts/set-gpu-memory.shIf you don't set OLLAMA_GPU_PERCENT, GPU memory optimization will be skipped.
For best performance:
- Use SSH for remote management
- Keep display disconnected when possible
- Avoid running GUI applications
- Consider disabling Screen Sharing if not needed for emergency access
- Adjust GPU memory percentage based on your available memory and workload
These optimizations leave more resources available for Ollama model operations, allowing for better performance when running large language models.
If you need to run Docker containers (e.g., for Open WebUI), you can configure Docker to start automatically using Colima. This feature is completely optional.
Colima is a container runtime for macOS that's designed to work well in headless environments. It provides Docker API compatibility without requiring Docker Desktop, making it ideal for server use.
- Homebrew must be installed (the script will use it to install Colima and Docker CLI)
- No special GUI requirements (works perfectly in headless environments)
To enable Docker autostart, run:
export DOCKER_AUTOSTART="true"
./scripts/install.shThis will:
- Install Colima and Docker CLI via Homebrew (if not already installed)
- Create a LaunchDaemon that starts Colima automatically at boot time
- Configure Colima with default settings
If Docker doesn't start automatically:
- Check the logs:
cat ~/mac-studio-server/logs/docker.log- Try starting Colima manually:
colima start- Check Colima status:
colima statusIf you don't need Docker containers, you can skip this feature entirely.
This project follows Semantic Versioning:
- MAJOR version for incompatible changes
- MINOR version for new features
- PATCH version for bug fixes
The current version is 1.2.0.
Contributions are welcome! Please feel free to submit a Pull Request.
MIT License
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mac-studio-server
Similar Open Source Tools
mac-studio-server
This repository provides configuration and scripts for running Ollama LLM server on Apple Silicon Macs in headless mode, optimized for performance and resource usage. It includes features like automatic startup, system resource optimization, external network access, proper logging setup, and SSH-based remote management. Users can customize the Ollama service configuration and enable optional GPU memory optimization and Docker autostart for container applications. The installation process disables unnecessary system services, configures power management, and optimizes for background operation while maintaining Screen Sharing capability for remote management. Performance considerations focus on reducing memory usage, disabling GUI-related services, minimizing background processes, preventing sleep/hibernation, and optimizing for headless operation.
batteries-included
Batteries Included is an all-in-one platform for building and running modern applications, simplifying cloud infrastructure complexity. It offers production-ready capabilities through an intuitive interface, focusing on automation, security, and enterprise-grade features. The platform includes databases like PostgreSQL and Redis, AI/ML capabilities with Jupyter notebooks, web services deployment, security features like SSL/TLS management, and monitoring tools like Grafana dashboards. Batteries Included is designed to streamline infrastructure setup and management, allowing users to concentrate on application development without dealing with complex configurations.

OmniSteward
OmniSteward is an AI-powered steward system based on large language models that can interact with users through voice or text to help control smart home devices and computer programs. It supports multi-turn dialogue, tool calling for complex tasks, multiple LLM models, voice recognition, smart home control, computer program management, online information retrieval, command line operations, and file management. The system is highly extensible, allowing users to customize and share their own tools.
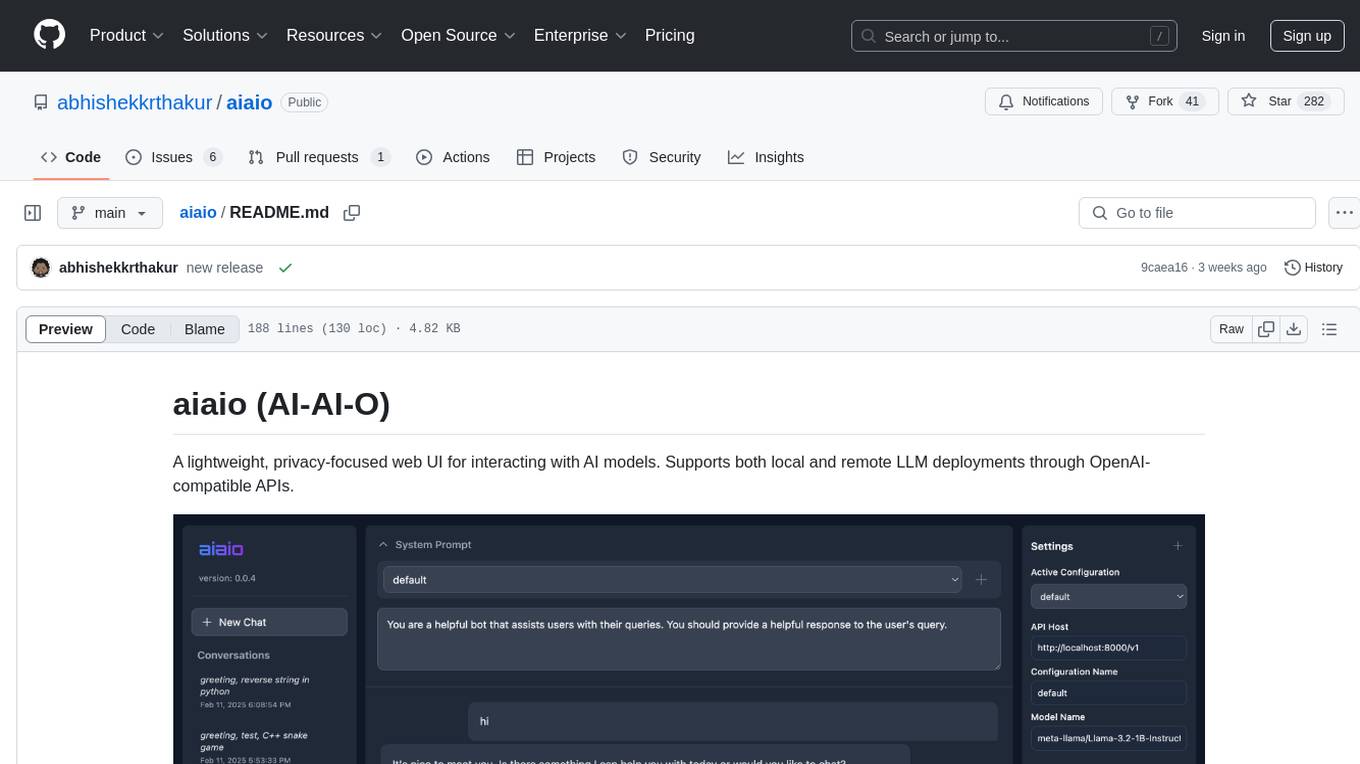
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
GraphRAG-Local-UI
GraphRAG Local with Interactive UI is an adaptation of Microsoft's GraphRAG, tailored to support local models and featuring a comprehensive interactive user interface. It allows users to leverage local models for LLM and embeddings, visualize knowledge graphs in 2D or 3D, manage files, settings, and queries, and explore indexing outputs. The tool aims to be cost-effective by eliminating dependency on costly cloud-based models and offers flexible querying options for global, local, and direct chat queries.

AppFlowy-Cloud
AppFlowy Cloud is a secure user authentication, file storage, and real-time WebSocket communication tool written in Rust. It is part of the AppFlowy ecosystem, providing an efficient and collaborative user experience. The tool offers deployment guides, development setup with Rust and Docker, debugging tips for components like PostgreSQL, Redis, Minio, and Portainer, and guidelines for contributing to the project.
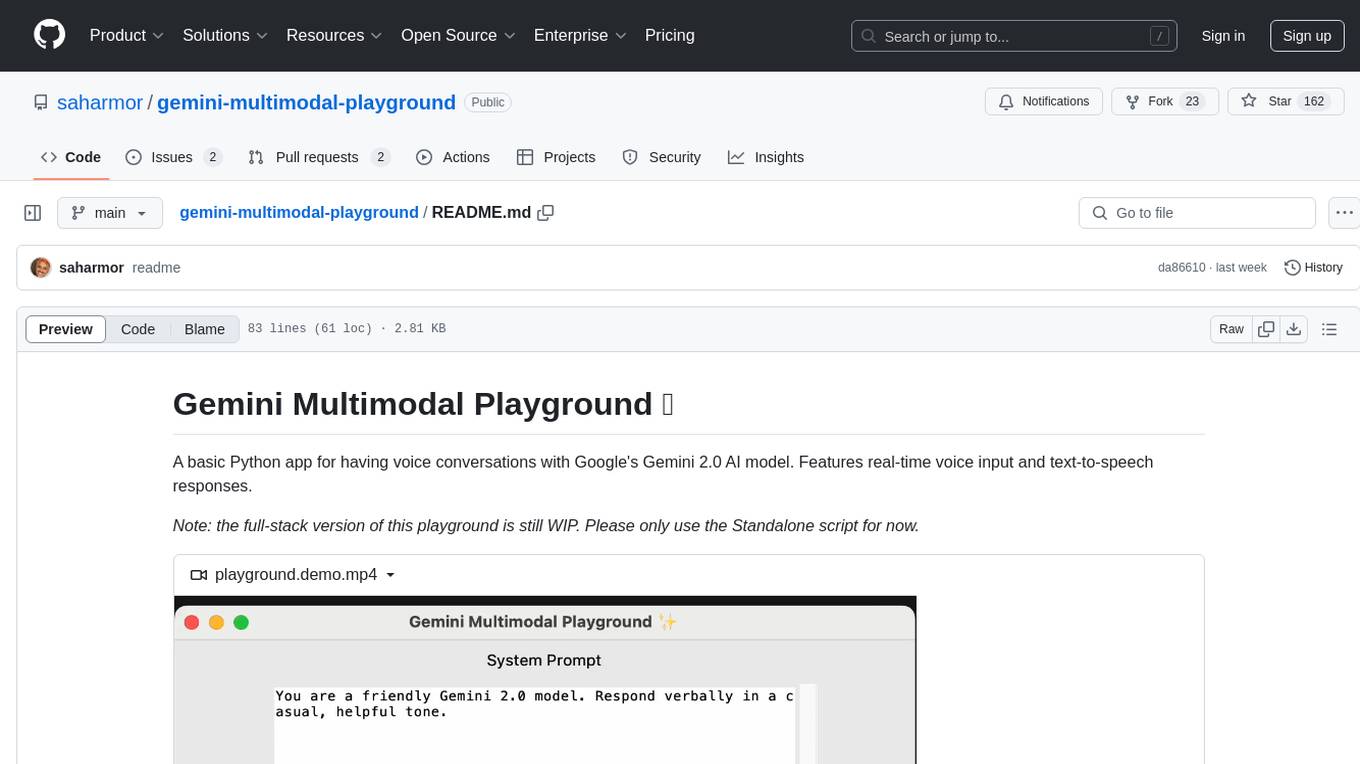
gemini-multimodal-playground
Gemini Multimodal Playground is a basic Python app for voice conversations with Google's Gemini 2.0 AI model. It features real-time voice input and text-to-speech responses. Users can configure settings through the GUI and interact with Gemini by speaking into the microphone. The application provides options for voice selection, system prompt customization, and enabling Google search. Troubleshooting tips are available for handling audio feedback loop issues that may occur during interactions.

orama-core
OramaCore is a database designed for AI projects, answer engines, copilots, and search functionalities. It offers features such as a full-text search engine, vector database, LLM interface, and various utilities. The tool is currently under active development and not recommended for production use due to potential API changes. OramaCore aims to provide a comprehensive solution for managing data and enabling advanced AI capabilities in projects.

mattermost-plugin-agents
The Mattermost Agents Plugin integrates AI capabilities directly into your Mattermost workspace, allowing users to run local LLMs on their infrastructure or connect to cloud providers. It offers multiple AI assistants with specialized personalities, thread and channel summarization, action item extraction, meeting transcription, semantic search, smart reactions, direct conversations with AI assistants, and flexible LLM support. The plugin comes with comprehensive documentation, installation instructions, system requirements, and development guidelines for users to interact with AI features and configure LLM providers.
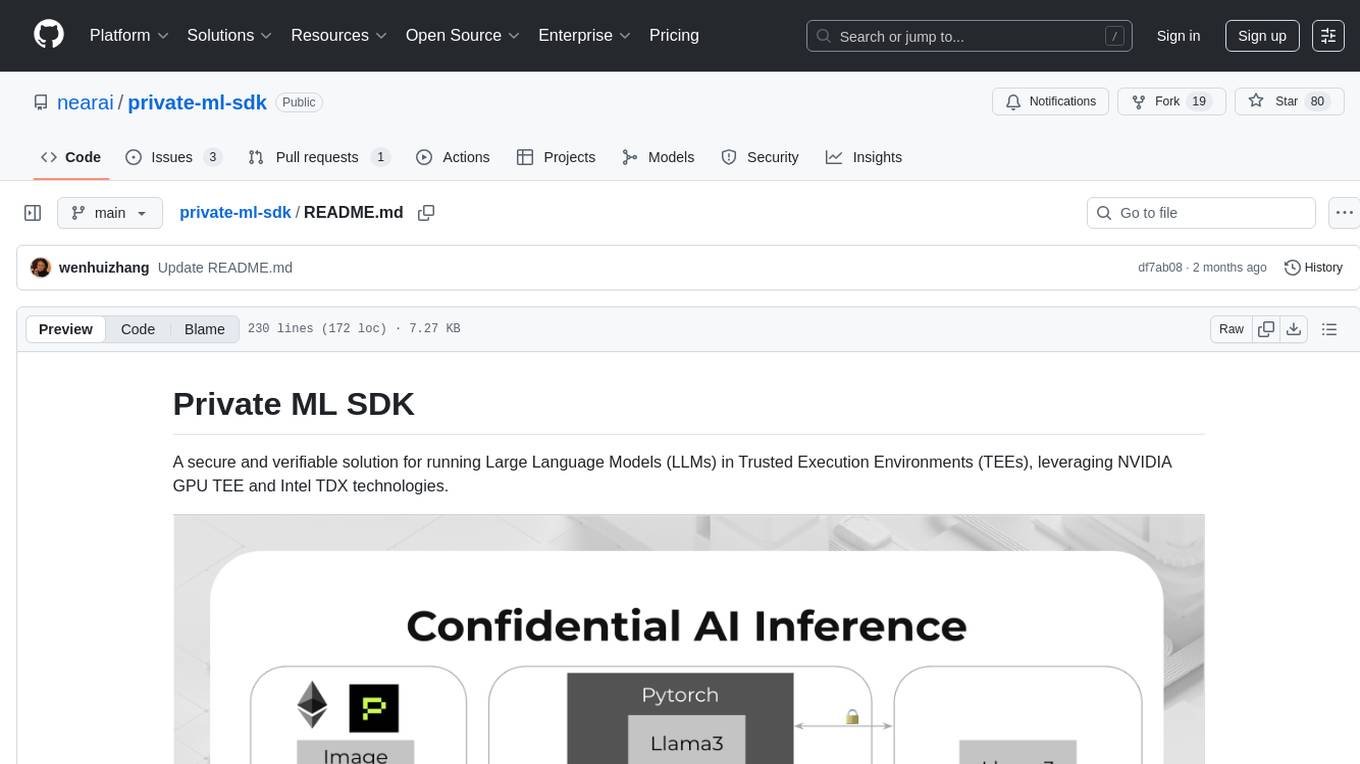
private-ml-sdk
Private ML SDK is a secure solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs) using NVIDIA GPU TEE and Intel TDX technologies. It provides a tamper-proof data processing environment with secure execution, open-source builds, and nearly native speed performance. The system includes components like Secure Compute Environment, Remote Attestation, Secure Communication, and Key Management Service (KMS). Users can build TDX guest images, run Local KMS, and TDX guest images on TDX host machines with Nvidia GPUs. The SDK offers verifiable execution results and high performance for LLM workloads.
aisdk-prompt-optimizer
AISDK Prompt Optimizer is an open-source tool designed to transform AI interactions by optimizing prompts. It utilizes the GEPA reflective optimizer to evolve textual components of AI systems, providing features such as reflective prompt mutation, rich textual feedback, and Pareto-based selection. Users can teach their AI desired behaviors, collect ideal samples, run optimization to generate optimized prompts, and deploy the results in their applications. The tool leverages advanced optimization algorithms to guide AI through interactive conversations and refine prompt candidates for improved performance.
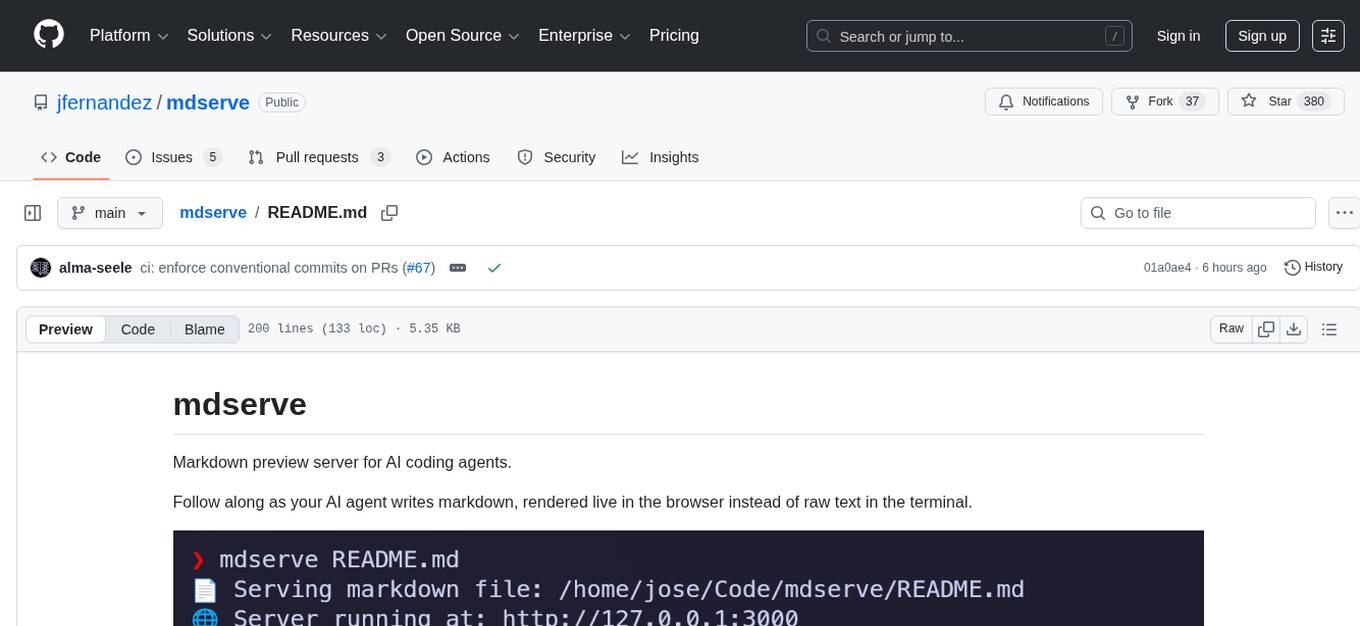
mdserve
Markdown preview server for AI coding agents. mdserve is a tool that allows AI agents to write markdown and see it rendered live in the browser. It features zero configuration, single binary installation, instant live reload via WebSocket, ephemeral sessions, and agent-friendly content support. It is not a documentation site generator, static site server, or general-purpose markdown authoring tool. mdserve is designed for AI coding agents to produce content like tables, diagrams, and code blocks.
Notate
Notate is a powerful desktop research assistant that combines AI-driven analysis with advanced vector search technology. It streamlines research workflow by processing, organizing, and retrieving information from documents, audio, and text. Notate offers flexible AI capabilities with support for various LLM providers and local models, ensuring data privacy. Built for researchers, academics, and knowledge workers, it features real-time collaboration, accessible UI, and cross-platform compatibility.

mcpm.sh
MCPM is an open source CLI tool for managing MCP servers, providing a simplified global configuration approach to install servers once, organize them with profiles, and integrate them into any MCP client. Features include server discovery, direct execution, sharing capabilities, and client integration tools. It eliminates the complexity of v1's target-based system in favor of a clean global workspace model. The tool is designed to be AI agent friendly with comprehensive automation support and a rich CLI interface.
DeepBI
DeepBI is an AI-native data analysis platform that leverages the power of large language models to explore, query, visualize, and share data from any data source. Users can use DeepBI to gain data insight and make data-driven decisions.
ztachip
ztachip is a RISCV accelerator designed for vision and AI edge applications, offering up to 20-50x acceleration compared to non-accelerated RISCV implementations. It features an innovative tensor processor hardware to accelerate various vision tasks and TensorFlow AI models. ztachip introduces a new tensor programming paradigm for massive processing/data parallelism. The repository includes technical documentation, code structure, build procedures, and reference design examples for running vision/AI applications on FPGA devices. Users can build ztachip as a standalone executable or a micropython port, and run various AI/vision applications like image classification, object detection, edge detection, motion detection, and multi-tasking on supported hardware.
For similar tasks
mac-studio-server
This repository provides configuration and scripts for running Ollama LLM server on Apple Silicon Macs in headless mode, optimized for performance and resource usage. It includes features like automatic startup, system resource optimization, external network access, proper logging setup, and SSH-based remote management. Users can customize the Ollama service configuration and enable optional GPU memory optimization and Docker autostart for container applications. The installation process disables unnecessary system services, configures power management, and optimizes for background operation while maintaining Screen Sharing capability for remote management. Performance considerations focus on reducing memory usage, disabling GUI-related services, minimizing background processes, preventing sleep/hibernation, and optimizing for headless operation.
mcp-server-qdrant
The mcp-server-qdrant repository is an official Model Context Protocol (MCP) server designed for keeping and retrieving memories in the Qdrant vector search engine. It acts as a semantic memory layer on top of the Qdrant database. The server provides tools like 'qdrant-store' for storing information in the database and 'qdrant-find' for retrieving relevant information. Configuration is done using environment variables, and the server supports different transport protocols. It can be installed using 'uvx' or Docker, and can also be installed via Smithery for Claude Desktop. The server can be used with Cursor/Windsurf as a code search tool by customizing tool descriptions. It can store code snippets and help developers find specific implementations or usage patterns. The repository is licensed under the Apache License 2.0.
echokit_box
EchoKit is a tool for setting up and flashing firmware on the EchoKit device. It provides instructions for flashing the device image, installing necessary dependencies, building firmware from source, and flashing the firmware onto the device. The tool also includes steps for resetting the device and configuring it to connect to an EchoKit server for full functionality.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
mlir-air
This repository contains tools and libraries for building AIR platforms, runtimes and compilers.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.