Best AI tools for< Quantize Model >
0 - AI tool Sites
5 - Open Source AI Tools

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
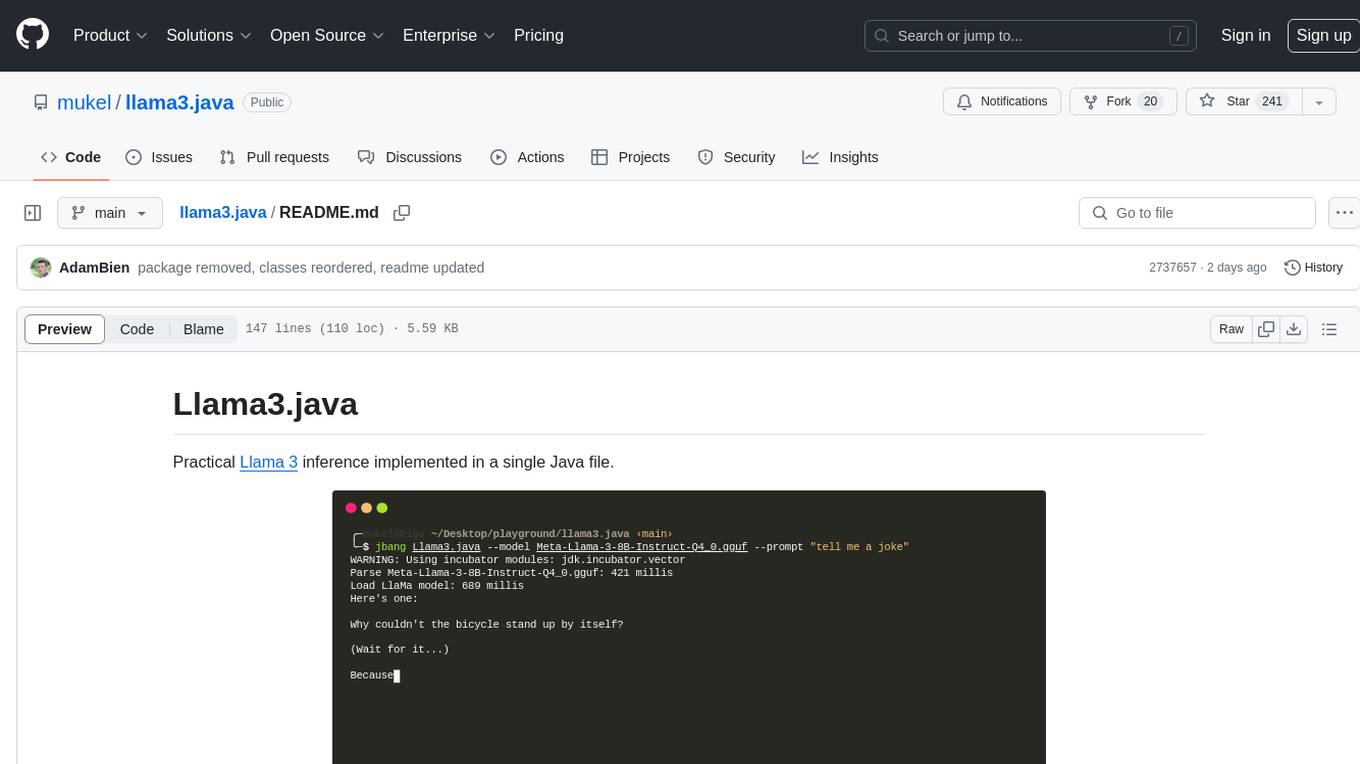
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
LLM-Drop
LLM-Drop is an official implementation of the paper 'What Matters in Transformers? Not All Attention is Needed'. The tool investigates redundancy in transformer-based Large Language Models (LLMs) by analyzing the architecture of Blocks, Attention layers, and MLP layers. It reveals that dropping certain Attention layers can enhance computational and memory efficiency without compromising performance. The tool provides a pipeline for Block Drop and Layer Drop based on LLaMA-Factory, and implements quantization using AutoAWQ and AutoGPTQ.