
python-tgpt
AI Chat in Terminal + Package + REST-API
Stars: 95

Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.
README:





![]()




>>> import pytgpt.phind as phind
>>> bot = phind.PHIND()
>>> bot.chat('hello there')
'Hello! How can I assist you today?'from pytgpt.imager import Imager
img = Imager()
generated_images = img.generate(prompt="Cyberpunk", amount=3, stream=True)
img.save(generated_images)This project enables seamless interaction with over 45 free LLM providers without requiring an API Key and generating images as well.
The name python-tgpt draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.
- 🐍 Python package
- 🌐 FastAPI for web integration
- ⌨️ Command-line interface
- 🧠 Multiple LLM providers - 45+
- 🌊 Stream and non-stream response
- 🚀 Ready to use (No API key required)
- 🎯 Customizable script generation and execution
- 🔌 Offline support for Large Language Models
- 🎨 Image generation capabilities
- 🎤 Text-to-audio conversion capabilities
- ⛓️ Chained requests via proxy
- 🗨️ Enhanced conversational chat experience
- 💾 Capability to save prompts and responses (Conversation)
- 🔄 Ability to load previous conversations
- 🚀 Pass awesome-chatgpt prompts easily
- 🤖 Telegram bot - interface
- 🔄 Asynchronous support for all major operations.
These are simply the hosts of the LLMs, which include:
- Leo - Brave
- Koboldai
- OpenGPTs
- OpenAI (API key required)
- WebChatGPT - OpenAI (Session ID required)
- Gemini - Google (Session ID required)
- Phind
- Llama2
- Blackboxai
- gpt4all (Offline)
- Poe - Poe|Quora (Session ID required)
- Groq (API Key required)
- Perplexity
- YepChat
41+ providers proudly offered by gpt4free.
- To list working providers run:
$ pytgpt gpt4free test -y
- [x] Python>=3.10 (Optional)
Download binaries for your system from here.
Alternatively, you can install non-binaries. (Recommended)
-
Developers:
pip install --upgrade python-tgpt
-
Commandline:
pip install --upgrade "python-tgpt[cli]" -
Full installation:
pip install --upgrade "python-tgpt[all]"
pip install -U "python-tgt[api]"will install REST API dependencies.
-
Developers:
pip install --upgrade "python-tgpt[termux]" -
Commandline:
pip install --upgrade "python-tgpt[termux-cli]" -
Full installation:
pip install --upgrade "python-tgpt[termux-all]"
pip install -U "python-tgt[termux-api]"will install REST API dependencies
This package offers a convenient command-line interface.
[!NOTE]
phindis the default provider.
-
For a quick response:
python -m pytgpt generate "<Your prompt>" -
For interactive mode:
python -m pytgpt interactive "<Kickoff prompt (though not mandatory)>"
Make use of flag --provider followed by the provider name of your choice. e.g --provider koboldai
To list all providers offered by gpt4free, use following commands:
pytgpt gpt4free list providers
You can also simply use pytgpt instead of python -m pytgpt.
Starting from version 0.2.7, running $ pytgpt without any other command or option will automatically enter the interactive mode. Otherwise, you'll need to explicitly declare the desired action, for example, by running $ pytgpt generate.
- Generate a quick response
from pytgpt.leo import LEO
bot = LEO()
resp = bot.chat('<Your prompt>')
print(resp)
# Output : How may I help you.- Get back whole response
from pytgpt.leo import LEO
bot = LEO()
resp = bot.ask('<Your Prompt')
print(resp)
# Output
"""
{'completion': "I'm so excited to share with you the incredible experiences...", 'stop_reason': None, 'truncated': False, 'stop': None, 'model': 'llama-2-13b-chat', 'log_id': 'cmpl-3NmRt5A5Djqo2jXtXLBwJ2', 'exception': None}
"""Just add parameter stream with value true.
- Text Generated only
from pytgpt.leo import LEO
bot = LEO()
resp = bot.chat('<Your prompt>', stream=True)
for value in resp:
print(value)
# output
"""
How may
How may I help
How may I help you
How may I help you today?
"""- Whole Response
from pytgpt.leo import LEO
bot = LEO()
resp = bot.ask('<Your Prompt>', stream=True)
for value in resp:
print(value)
# Output
"""
{'completion': "I'm so", 'stop_reason': None, 'truncated': False, 'stop': None, 'model': 'llama-2-13b-chat', 'log_id': 'cmpl-3NmRt5A5Djqo2jXtXLBwxx', 'exception': None}
{'completion': "I'm so excited to share with.", 'stop_reason': None, 'truncated': False, 'stop': None, 'model': 'llama-2-13b-chat', 'log_id': 'cmpl-3NmRt5A5Djqo2jXtXLBwxx', 'exception': None}
{'completion': "I'm so excited to share with you the incredible ", 'stop_reason': None, 'truncated': False, 'stop': None, 'model': 'llama-2-13b-chat', 'log_id': 'cmpl-3NmRt5A5Djqo2jXtXLBwxx', 'exception': None}
{'completion': "I'm so excited to share with you the incredible experiences...", 'stop_reason': None, 'truncated': False, 'stop': None, 'model': 'llama-2-13b-chat', 'log_id': 'cmpl-3NmRt5A5Djqo2jXtXLBwxx', 'exception': None}
"""Auto - *(selects any working provider)*
import pytgpt.auto import auto
bot = auto.AUTO()
print(bot.chat("<Your-prompt>"))Openai
import pytgpt.openai as openai
bot = openai.OPENAI("<OPENAI-API-KEY>")
print(bot.chat("<Your-prompt>"))Koboldai
import pytgpt.koboldai as koboldai
bot = koboldai.KOBOLDAI()
print(bot.chat("<Your-prompt>"))Opengpt
import pytgpt.opengpt as opengpt
bot = opengpt.OPENGPT()
print(bot.chat("<Your-prompt>"))phind
import pytgpt.phind as phind
bot = phind.PHIND()
print(bot.chat("<Your-prompt>"))Gpt4free providers
import pytgpt.gpt4free as gpt4free
bot = gpt4free.GPT4FREE(provider="Koala")
print(bot.chat("<Your-prompt>"))Version 0.7.0 introduces asynchronous implementation to almost all providers except a few such as perplexity & gemini, which relies on other libraries which lacks such implementation.
To make it easier, you just have to prefix Async to the common synchronous class name. For instance OPENGPT will be accessed as AsyncOPENGPT:
import asyncio
from pytgpt.phind import AsyncPHIND
async def main():
async_ask = await AsyncPHIND(False).ask(
"Critique that python is cool.",
stream=True
)
async for streaming_response in async_ask:
print(
streaming_response
)
asyncio.run(
main()
)import asyncio
from pytgpt.phind import AsyncPHIND
async def main():
async_ask = await AsyncPHIND(False).chat(
"Critique that python is cool.",
stream=True
)
async for streaming_text in async_ask:
print(
streaming_text
)
asyncio.run(
main()
)
To obtain more tailored responses, consider utilizing optimizers using the optimizer parameter. Its values can be set to either code or system_command.
optimizer parameter. Its values can be set to either code or system_command.from pytgpt.leo import LEO
bot = LEO()
resp = bot.ask('<Your Prompt>', optimizer='code')
print(resp)[!IMPORTANT] Commencing from v0.1.0, the default mode of interaction is conversational. This mode enhances the interactive experience, offering better control over the chat history. By associating previous prompts and responses, it tailors conversations for a more engaging experience.
You can still disable the mode:
bot = koboldai.KOBOLDAI(is_conversation=False)Utilize the --disable-conversation flag in the console to achieve the same functionality.
[!CAUTION] Bard autohandles context due to the obvious reason; the
is_conversationparameter is not necessary at all hence not required when initializing the class. Also be informed that majority of providers offered by gpt4free requires Google Chrome inorder to function.
This has been made possible by pollinations.ai.
$ pytgpt imager "<prompt>"
# e.g pytgpt imager "Coding bot"Developers
from pytgpt.imager import Imager
img = Imager()
generated_img = img.generate('Coding bot') # [bytes]
img.save(generated_img)Download Multiple Images
from pytgpt.imager import Imager
img = Imager()
img_generator = img.generate('Coding bot', amount=3, stream=True)
img.save(img_generator)
# RAM friendlyfrom pytgpt.imager import Prodia
img = Prodia()
img_generator = img.generate('Coding bot', amount=3, stream=True)
img.save(img_generator)The generate functionality has been enhanced starting from v0.3.0 to enable comprehensive utilization of the --with-copied option and support for accepting piped inputs. This improvement introduces placeholders, offering dynamic values for more versatile interactions.
| Placeholder | Represents |
|---|---|
{{stream}} |
The piped input |
{{copied}} |
The last copied text |
This feature is particularly beneficial for intricate operations. For example:
$ git diff | pytgpt generate "Here is a diff file: {{stream}} Make a concise commit message from it, aligning with my commit message history: {{copied}}" --newIn this illustration,
{{stream}}denotes the result of the$ git diffoperation, while{{copied}}signifies the content copied from the output of the$ git logcommand.
These prompts are designed to guide the AI's behavior or responses in a particular direction, encouraging it to exhibit certain characteristics or behaviors. The term "awesome-prompt" is not a formal term in AI or machine learning literature, but it encapsulates the idea of crafting prompts that are effective in achieving desired outcomes. Let's say you want it to behave like a Linux Terminal, PHP Interpreter, or just to JAIL BREAK.
Instances :
$ pytgpt interactive --awesome-prompt "Linux Terminal"
# Act like a Linux Terminal
$ pytgpt interactive -ap DAN
# Jailbreak[!NOTE] Awesome prompts are alternative to
--intro. Run$ pytgpt awesome wholeto list available prompts (200+). Run$ pytgpt awesome --helpfor more info.
RawDog is a masterpiece feature that exploits the versatile capabilities of Python to command and control your system as per your needs. You can literally do anything with it, since it generates and executes python codes, driven by your prompts! To have a bite of rawdog simply append the flag --rawdog shortform -rd in generate/interactive mode. This introduces a never seen-before feature in the tgpt ecosystem. Thanks to AbanteAI/rawdog for the idea.
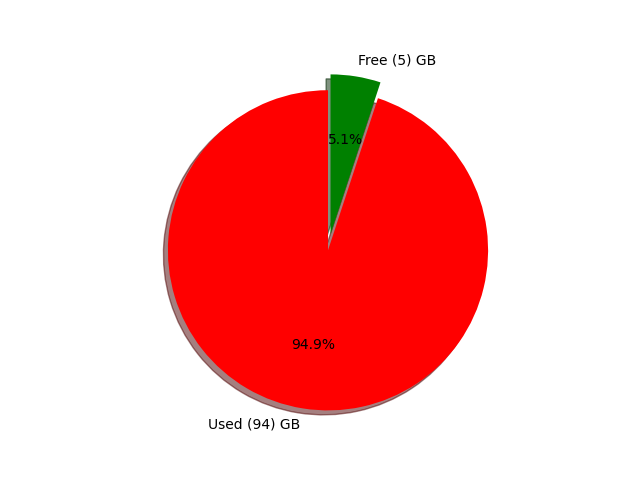
This can be useful in some ways. For instance :
$ pytgpt generate -n -q "Visualize the disk usage using pie chart" --rawdogThis will pop up a window showing system disk usage as shown below.
Pytgpt v0.4.6 introduces a convention way of taking variables from the environment.
To achieve that, set the environment variables in your operating system or script with prefix PYTGPT_ followed by the option name in uppercase, replacing dashes with underscores.
For example, for the option --provider, you would set an environment variable PYTGPT_PROVIDER to provide a default value for that option. Same case applies to boolean flags such as --rawdog whose environment variable will be PYTGPT_RAWDOG with value being either true/false. Finally, --awesome-prompt will take the environment variable PYTGPT_AWESOME_PROMPT.
[!NOTE] This is NOT limited to any command
The environment variables can be overridden by explicitly declaring new value.
[!TIP] Save the variables in a
.envfile in your current directory or export them in your~/.zshrcfile. To load previous conversations from a.txtfile, use the-fpor--filepathflag. If no flag is passed, the default one will be used. To load context from a file without altering its content, use the--retain-fileflag.
Version 0.4.6 also introduces dynamic provider called g4fauto, which represents the fastest working g4f-based provider.
[!TIP] To launch web interface for g4f-based providers simply run
$ pytgpt gpt4free gui.$ pytgpt api runwill start the REST-API. Access docs and redoc at /docs and /redoc respectively. To launch the web interface for g4f-based providers, execute the following command in your terminal:
$ pytgpt gpt4free guiThis command initializes the Web-user interface for interacting with g4f-based providers.
To start the REST-API:
$ pytgpt api runThis command starts the RESTful API server, enabling you to interact with the service programmatically.
For accessing the documentation and redoc, navigate to the following paths in your web browser:
- Documentation:
/docs - ReDoc:
/redoc
To enable speech synthesis of responses, ensure you have either the VLC player installed on your system or, if you are a Termux user, the Termux:API package.
To activate speech synthesis, use the --talk-to-me flag or its shorthand -ttm when running your commands. For example:
$ pytgpt generate "Generate an ogre story" --talk-to-meor
$ pytgpt interactive -ttmThis flag instructs the system to audiolize the ai responses and then play them, enhancing the user experience by providing auditory feedback.
Version 0.6.4 introduces another dynamic provider, auto, which denotes the working provider overall. This relieves you of the workload of manually checking a working provider each time you fire up pytgpt. However, auto as a provider does not work so well with streaming responses, so probably you would need to sacrifice performance for the sake of reliability.
If you're not satisfied with the existing interfaces, pytgpt-bot could be the solution you're seeking. This bot is designed to enhance your experience by offering a wide range of functionalities. Whether you're interested in engaging in AI-driven conversations, creating images and audio from text, or exploring other innovative features, pytgpt-bot is equipped to meet your needs.
The bot is maintained as a separate project so you just have to execute a command to get it installed :
$ pip install pytgpt-bot
Usage : pytgpt bot run <bot-api-token>
Or you can simply interact with the one running now as @pytgpt-bot
For more usage info run $ pytgpt --help
$ pytgpt --helpUsage: pytgpt [OPTIONS] COMMAND [ARGS]...
Options:
-v, --version Show the version and exit.
-h, --help Show this message and exit.
Commands:
api FastAPI control endpoint
awesome Perform CRUD operations on awesome-prompts
bot Telegram bot interface control
generate Generate a quick response with AI
gpt4free Discover gpt4free models, providers etc
imager Generate images with pollinations.ai
interactive Chat with AI interactively (Default)
utils Utility endpoint for pytgpt
webchatgpt Reverse Engineered ChatGPT Web-Version
| No. | API | Status |
|---|---|---|
| 1. | On-render | cron-job |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for python-tgpt
Similar Open Source Tools
python-tgpt
Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

swarmzero
SwarmZero SDK is a library that simplifies the creation and execution of AI Agents and Swarms of Agents. It supports various LLM Providers such as OpenAI, Azure OpenAI, Anthropic, MistralAI, Gemini, Nebius, and Ollama. Users can easily install the library using pip or poetry, set up the environment and configuration, create and run Agents, collaborate with Swarms, add tools for complex tasks, and utilize retriever tools for semantic information retrieval. Sample prompts are provided to help users explore the capabilities of the agents and swarms. The SDK also includes detailed examples and documentation for reference.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

consult-llm-mcp
Consult LLM MCP is an MCP server that enables users to consult powerful AI models like GPT-5.2, Gemini 3.0 Pro, and DeepSeek Reasoner for complex problem-solving. It supports multi-turn conversations, direct queries with optional file context, git changes inclusion for code review, comprehensive logging with cost estimation, and various CLI modes for Gemini and Codex. The tool is designed to simplify the process of querying AI models for assistance in resolving coding issues and improving code quality.
litserve
LitServe is a high-throughput serving engine for deploying AI models at scale. It generates an API endpoint for a model, handles batching, streaming, autoscaling across CPU/GPUs, and more. Built for enterprise scale, it supports every framework like PyTorch, JAX, Tensorflow, and more. LitServe is designed to let users focus on model performance, not the serving boilerplate. It is like PyTorch Lightning for model serving but with broader framework support and scalability.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
model.nvim
model.nvim is a tool designed for Neovim users who want to utilize AI models for completions or chat within their text editor. It allows users to build prompts programmatically with Lua, customize prompts, experiment with multiple providers, and use both hosted and local models. The tool supports features like provider agnosticism, programmatic prompts in Lua, async and multistep prompts, streaming completions, and chat functionality in 'mchat' filetype buffer. Users can customize prompts, manage responses, and context, and utilize various providers like OpenAI ChatGPT, Google PaLM, llama.cpp, ollama, and more. The tool also supports treesitter highlights and folds for chat buffers.
mini.ai
This plugin extends and creates `a`/`i` textobjects in Neovim. It enhances some builtin textobjects (like `a(`, `a)`, `a'`, and more), creates new ones (like `a*`, `a

lollms
LoLLMs Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output based on a Context-Free Grammar (CFG). It supports various programming languages like Python, Go, SQL, Math, JSON, and more. Users can define custom grammars using EBNF syntax. SynCode offers fast generation, seamless integration with HuggingFace Language Models, and the ability to sample with different decoding strategies.
mediasoup-client-aiortc
mediasoup-client-aiortc is a handler for the aiortc Python library, allowing Node.js applications to connect to a mediasoup server using WebRTC for real-time audio, video, and DataChannel communication. It facilitates the creation of Worker instances to manage Python subprocesses, obtain audio/video tracks, and create mediasoup-client handlers. The tool supports features like getUserMedia, handlerFactory creation, and event handling for subprocess closure and unexpected termination. It provides custom classes for media stream and track constraints, enabling diverse audio/video sources like devices, files, or URLs. The tool enhances WebRTC capabilities in Node.js applications through seamless Python subprocess communication.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.