
LLMs-World-Models-for-Planning
The source code of the paper "Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning".
Stars: 55
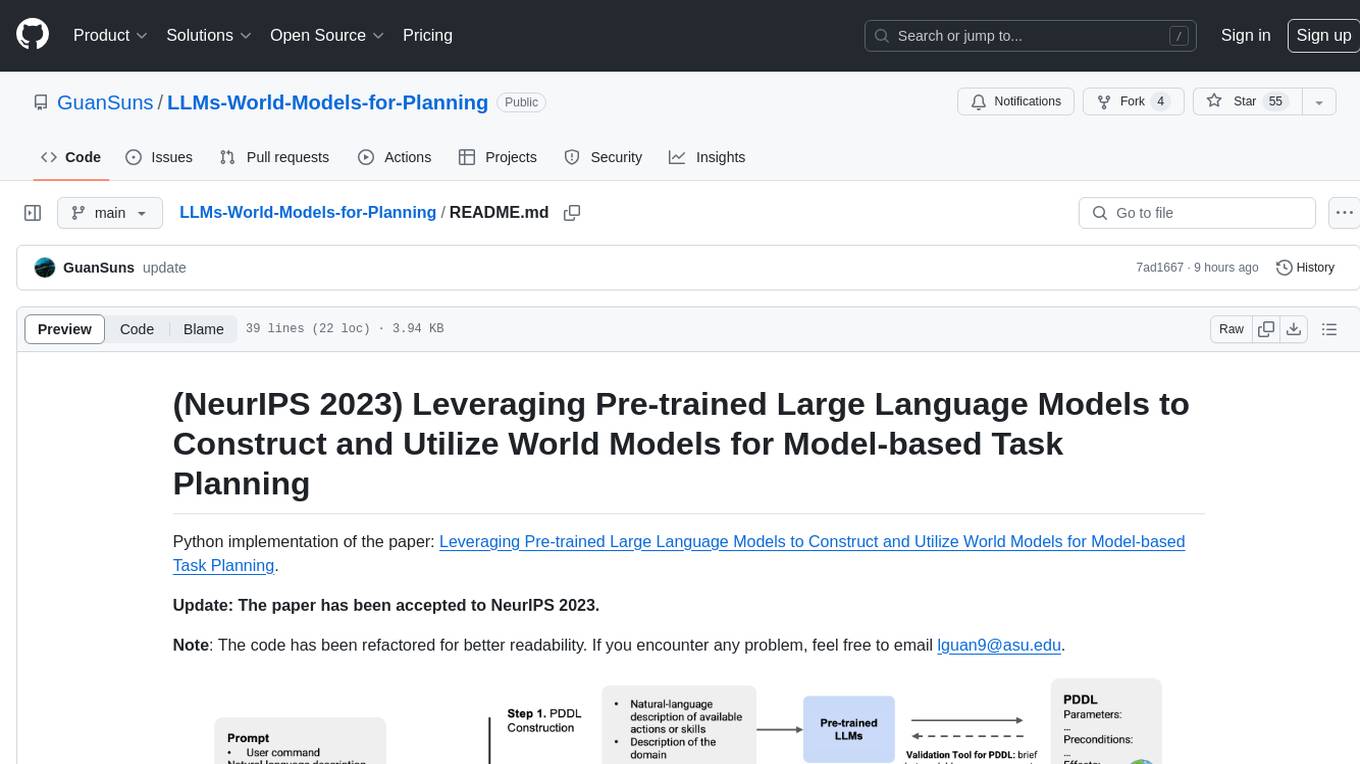
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.
README:
(NeurIPS 2023) Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning
Python implementation of the paper: Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning.
Update: The paper has been accepted to NeurIPS 2023.
Note: The code has been refactored for better readability. If you encounter any problem, feel free to email [email protected].

To leverage an LLM to construct a domain model, you need to provide the following information:
- Natural language descriptions of all the actions. Example:
prompts/logistics/action_model.json. - A description of the domain. Example:
prompts/logistics/domain_desc.txt. - Information of the object types and hierarchy. Example:
prompts/logistics/hierarchy_requirements.json.
Then, in the script construct_action_models.py, specify the domain and the LLM model (and other configurations if needed). When this script is executed, the LLM will generate PDDL models for all actions in turn. As mentioned in the paper (Appendix), we have implemented a simple PDDL syntax validator (pddl_syntax_validator.py) in Python. Although it doesn't comprehensively cover all possible errors in PDDL, we found it sufficient to correct almost all basic syntax errors in models generated by GPT-4.
The experiment record, the generated PDDL model and the translated PDDL will be saved under the directory results/{domain}/model_blocksworld/ (note: model_blocksworld means that the default prompt uses the Blocksworld as examples). Then the domain expert can inspect the action models and provide corrective feedback as needed. The feedback messages should be provided under the annotation list of each action in the file {llm-model}_pddl_for_annotations.json.
While it may be easy for PDDL experts to directly inspect and correct the generated PDDL models, we cannot assume that all end users possess this level of expertise. The script correct_action_models.py implements a pipeline that involves reading natural language feedback in {llm-model}_pddl_for_annotations.json, replaying and continuing the PDDL-construction dialogue, and obtaining the corrected domain model from the LLM. Similar to the generation script, here we need to specify the domain and the LLM model (and other configurations if needed). The experiment record, the final PDDL model and the final predicate list will be saved under the sub-directory corrected.
Note: Step 1 and Step 2 are the core components of the solutions discussed in the original paper.
Examples: We provide the constructed models for two IPC domains (i.e., logistics and tyreworld) as examples (the results were obtained on 06/03/23). The experiment records and models are located in the results directory.
To support future research, we are sharing the test samples for the household domain, which can be found in experiments/planning_tasks/household_planning_tasks.json. Each test case comprises an instruction and a list of object states. For an example of how to read each test case, please refer to experiments/planning_tasks/example_task_reader.py.
The code for converting a list of object states into a PDDL problem file is not included here. In our experiment, we simply hard coded a script to prepare PDDL problem files based on a manually-defined mapping between object states here and predicates generated by GPT-4. This process could be automated with language models.
For the logistics domain, the parsed problem instances can be found in experiments/planning_tasks/logistics_planning_tasks.json. A copy of the original IPC domain and problem files (for the logistics domain) can be found in experiments/planning_tasks/raw_pddl_problems/logistics/.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMs-World-Models-for-Planning
Similar Open Source Tools
LLMs-World-Models-for-Planning
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
intelligence-toolkit
The Intelligence Toolkit is a suite of interactive workflows designed to help domain experts make sense of real-world data by identifying patterns, themes, relationships, and risks within complex datasets. It utilizes generative AI (GPT models) to create reports on findings of interest. The toolkit supports analysis of case, entity, and text data, providing various interactive workflows for different intelligence tasks. Users are expected to evaluate the quality of data insights and AI interpretations before taking action. The system is designed for moderate-sized datasets and responsible use of personal case data. It uses the GPT-4 model from OpenAI or Azure OpenAI APIs for generating reports and insights.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.

council
Council is an open-source platform designed for the rapid development and deployment of customized generative AI applications using teams of agents. It extends the LLM tool ecosystem by providing advanced control flow and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators, and Budgets. The framework allows for automated routing between agents, comparing, evaluating, and selecting the best results for a task. Council aims to facilitate packaging and deploying agents at scale on multiple platforms while enabling enterprise-grade monitoring and quality control.
For similar tasks
LLMs-World-Models-for-Planning
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.