
dlio_benchmark
An I/O benchmark for deep Learning applications
Stars: 90

DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.
README:
![]()
This README provides an abbreviated documentation of the DLIO code. Please refer to https://dlio-benchmark.readthedocs.io for full user documentation.
DLIO is an I/O benchmark for Deep Learning. DLIO is aimed at emulating the I/O behavior of various deep learning applications. The benchmark is delivered as an executable that can be configured for various I/O patterns. It uses a modular design to incorporate more data loaders, data formats, datasets, and configuration parameters. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules.
git clone https://github.com/argonne-lcf/dlio_benchmark
cd dlio_benchmark/
pip install .
dlio_benchmark ++workload.workflow.generate_data=Truegit clone https://github.com/argonne-lcf/dlio_benchmark
cd dlio_benchmark/
pip install .[pydftracer]git clone https://github.com/argonne-lcf/dlio_benchmark
cd dlio_benchmark/
docker build -t dlio .
docker run -t dlio dlio_benchmark ++workload.workflow.generate_data=TrueYou can also pull rebuilt container from docker hub (might not reflect the most recent change of the code):
docker pull docker.io/zhenghh04/dlio:latest
docker run -t docker.io/zhenghh04/dlio:latest dlio_benchmark ++workload.workflow.generate_data=TrueIf your running on a different architecture, refer to the Dockerfile to build the dlio_benchmark container from scratch.
One can also run interactively inside the container
docker run -t docker.io/zhenghh04/dlio:latest /bin/bash
root@30358dd47935:/workspace/dlio$ dlio_benchmark ++workload.workflow.generate_data=TruePowerPC requires installation through anaconda.
# Setup required channels
conda config --prepend channels https://public.dhe.ibm.com/ibmdl/export/pub/software/server/ibm-ai/conda/
# create and activate environment
conda env create --prefix ./dlio_env_ppc --file environment-ppc.yaml --force
conda activate ./dlio_env_ppc
# install other dependencies
python -m pip install .For specific instructions on how to install and run the benchmark on Lassen please refer to: Install Lassen
A DLIO run is split in 3 phases:
- Generate synthetic data that DLIO will use
- Run the benchmark using the previously generated data
- Post-process the results to generate a report
The configurations of a workload can be specified through a yaml file. Examples of yaml files can be found in dlio_benchmark/configs/workload/.
One can specify the workload through the workload= option on the command line. Specific configuration fields can then be overridden following the hydra framework convention (e.g. ++workload.framework=tensorflow).
First, generate the data
mpirun -np 8 dlio_benchmark workload=unet3d ++workload.workflow.generate_data=True ++workload.workflow.train=FalseIf possible, one can flush the filesystem caches in order to properly capture device I/O
sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_cachesFinally, run the benchmark
mpirun -np 8 dlio_benchmark workload=unet3dFinally, run the benchmark with Tracer
export DFTRACER_ENABLE=1
export DFTRACER_INC_METADATA=1
mpirun -np 8 dlio_benchmark workload=unet3dAll the outputs will be stored in hydra_log/unet3d/$DATE-$TIME folder. To post process the data, one can do
dlio_postprocessor --output-folder hydra_log/unet3d/$DATE-$TIMEThis will generate DLIO_$model_report.txt in the output folder.
Workload characteristics are specified by a YAML configuration file. Below is an example of a YAML file for the UNet3D workload which is used for 3D image segmentation.
# contents of unet3d.yaml
model:
name: unet3d
model_size: 499153191
framework: pytorch
workflow:
generate_data: False
train: True
checkpoint: True
dataset:
data_folder: data/unet3d/
format: npz
num_files_train: 168
num_samples_per_file: 1
record_length_bytes: 146600628
record_length_bytes_stdev: 68341808
record_length_bytes_resize: 2097152
reader:
data_loader: pytorch
batch_size: 4
read_threads: 4
file_shuffle: seed
sample_shuffle: seed
train:
epochs: 5
computation_time: 1.3604
checkpoint:
checkpoint_folder: checkpoints/unet3d
checkpoint_after_epoch: 5
epochs_between_checkpoints: 2
The full list of configurations can be found in: https://argonne-lcf.github.io/dlio_benchmark/config.html
The YAML file is loaded through hydra (https://hydra.cc/). The default setting are overridden by the configurations loaded from the YAML file. One can override the configuration through command line (https://hydra.cc/docs/advanced/override_grammar/basic/).
-
DLIO currently assumes the samples to always be 2D images, even though one can set the size of each sample through
--record_length. We expect the shape of the sample to have minimal impact to the I/O itself. This yet to be validated for case by case perspective. We plan to add option to allow specifying the shape of the sample. -
We assume the data/label pairs are stored in the same file. Storing data and labels in separate files will be supported in future.
-
File format support: we only support tfrecord, hdf5, npz, csv, jpg, jpeg formats. Other data formats can be extended.
-
Data Loader support: we support reading datasets using TensorFlow tf.data data loader, PyTorch DataLoader, and a set of custom data readers implemented in ./reader. For TensorFlow tf.data data loader, PyTorch DataLoader
- We have complete support for tfrecord format in TensorFlow data loader.
- For npz, jpg, jpeg, hdf5, we currently only support one sample per file case. In other words, each sample is stored in an independent file. Multiple samples per file case will be supported in future.
We welcome contributions from the community to the benchmark code. Specifically, we welcome contribution in the following aspects: General new features needed including:
- support for new workloads: if you think that your workload(s) would be interested to the public, and would like to provide the yaml file to be included in the repo, please submit an issue.
- support for new data loaders, such as DALI loader, MxNet loader, etc
- support for new frameworks, such as MxNet
- support for noval file systems or storage, such as AWS S3.
- support for loading new data formats.
If you would like to contribute, please submit an issue to https://github.com/argonne-lcf/dlio_benchmark/issues, and contact ALCF DLIO team, Huihuo Zheng at [email protected]
The original CCGrid'21 paper describes the design and implementation of DLIO code. Please cite this paper if you use DLIO for your research.
@article{devarajan2021dlio,
title={DLIO: A Data-Centric Benchmark for Scientific Deep Learning Applications},
author={H. Devarajan and H. Zheng and A. Kougkas and X.-H. Sun and V. Vishwanath},
booktitle={IEEE/ACM International Symposium in Cluster, Cloud, and Internet Computing (CCGrid'21)},
year={2021},
volume={},
number={81--91},
pages={},
publisher={IEEE/ACM}
}
We also encourage people to take a look at a relevant work from MLPerf Storage working group.
@article{balmau2022mlperfstorage,
title={Characterizing I/O in Machine Learning with MLPerf Storage},
author={O. Balmau},
booktitle={SIGMOD Record DBrainstorming},
year={2022},
volume={51},
number={3},
publisher={ACM}
}
This work used resources of the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility under Contract DE-AC02-06CH11357 and is supported in part by National Science Foundation under NSF, OCI-1835764 and NSF, CSR-1814872.
Apache 2.0 LICENSE
Copyright (c) 2025, UChicago Argonne, LLC All Rights Reserved
If you have questions about your rights to use or distribute this software, please contact Argonne Intellectual Property Office at [email protected]
NOTICE. This Software was developed under funding from the U.S. Department of Energy and the U.S. Government consequently retains certain rights. As such, the U.S. Government has been granted for itself and others acting on its behalf a paid-up, nonexclusive, irrevocable, worldwide license in the Software to reproduce, distribute copies to the public, prepare derivative works, and perform publicly and display publicly, and to permit others to do so.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dlio_benchmark
Similar Open Source Tools
dlio_benchmark
DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.
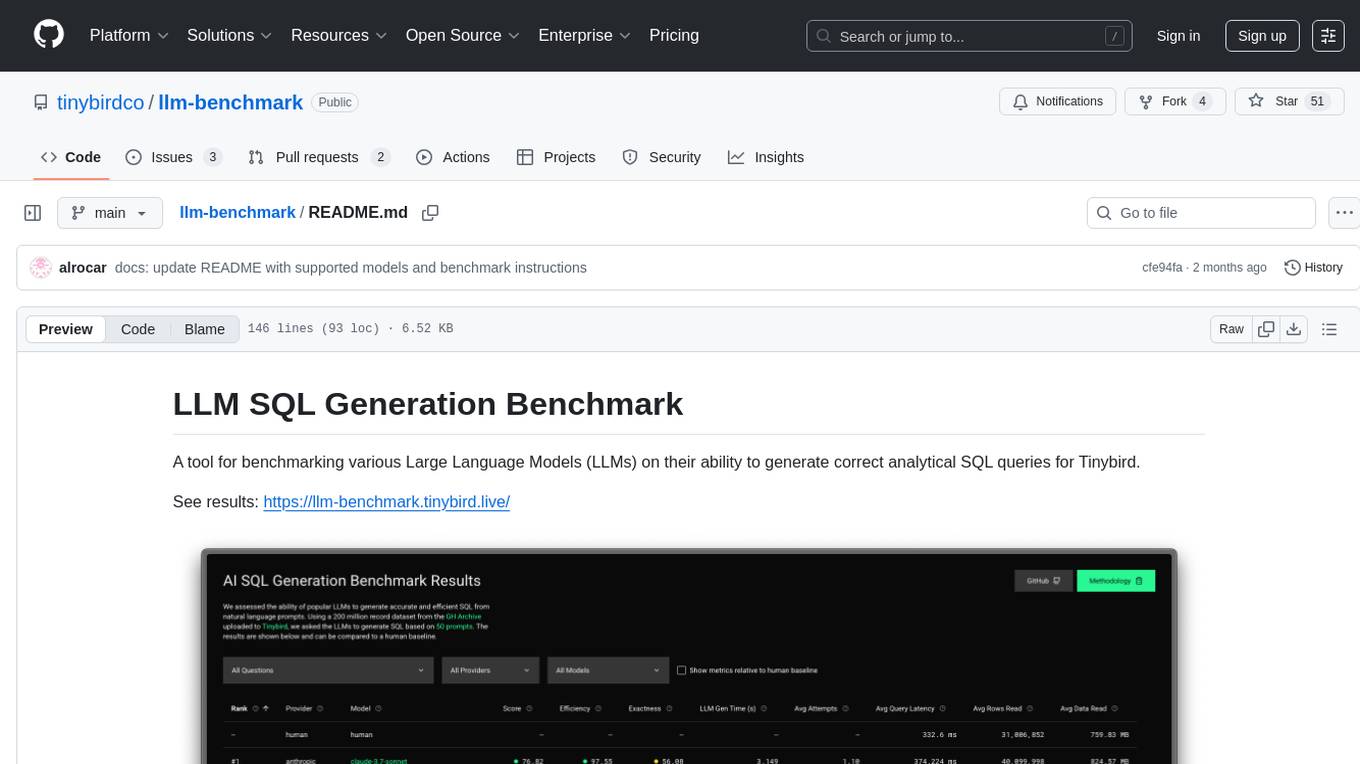
llm-benchmark
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
codebase-context-spec
The Codebase Context Specification (CCS) project aims to standardize embedding contextual information within codebases to enhance understanding for both AI and human developers. It introduces a convention similar to `.env` and `.editorconfig` files but focused on documenting code for both AI and humans. By providing structured contextual metadata, collaborative documentation guidelines, and standardized context files, developers can improve code comprehension, collaboration, and development efficiency. The project includes a linter for validating context files and provides guidelines for using the specification with AI assistants. Tooling recommendations suggest creating memory systems, IDE plugins, AI model integrations, and agents for context creation and utilization. Future directions include integration with existing documentation systems, dynamic context generation, and support for explicit context overriding.
ctakes
Apache cTAKES is a clinical Text Analysis and Knowledge Extraction System that focuses on extracting knowledge from clinical text through Natural Language Processing (NLP) techniques. It is modular and employs rule-based and machine learning methods to extract concepts such as symptoms, procedures, diagnoses, medications, and anatomy with attributes and standard codes. cTAKES can identify temporal events, dates, and times, placing events in a patient timeline. It supports various biomedical text processing tasks and can handle different types of clinical and health-related narratives using multiple data standards. cTAKES is widely used in research initiatives and encourages contributions from professionals, researchers, doctors, and students from diverse backgrounds.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

council
Council is an open-source platform designed for the rapid development and deployment of customized generative AI applications using teams of agents. It extends the LLM tool ecosystem by providing advanced control flow and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators, and Budgets. The framework allows for automated routing between agents, comparing, evaluating, and selecting the best results for a task. Council aims to facilitate packaging and deploying agents at scale on multiple platforms while enabling enterprise-grade monitoring and quality control.
ersilia
The Ersilia Model Hub is a unified platform of pre-trained AI/ML models dedicated to infectious and neglected disease research. It offers an open-source, low-code solution that provides seamless access to AI/ML models for drug discovery. Models housed in the hub come from two sources: published models from literature (with due third-party acknowledgment) and custom models developed by the Ersilia team or contributors.
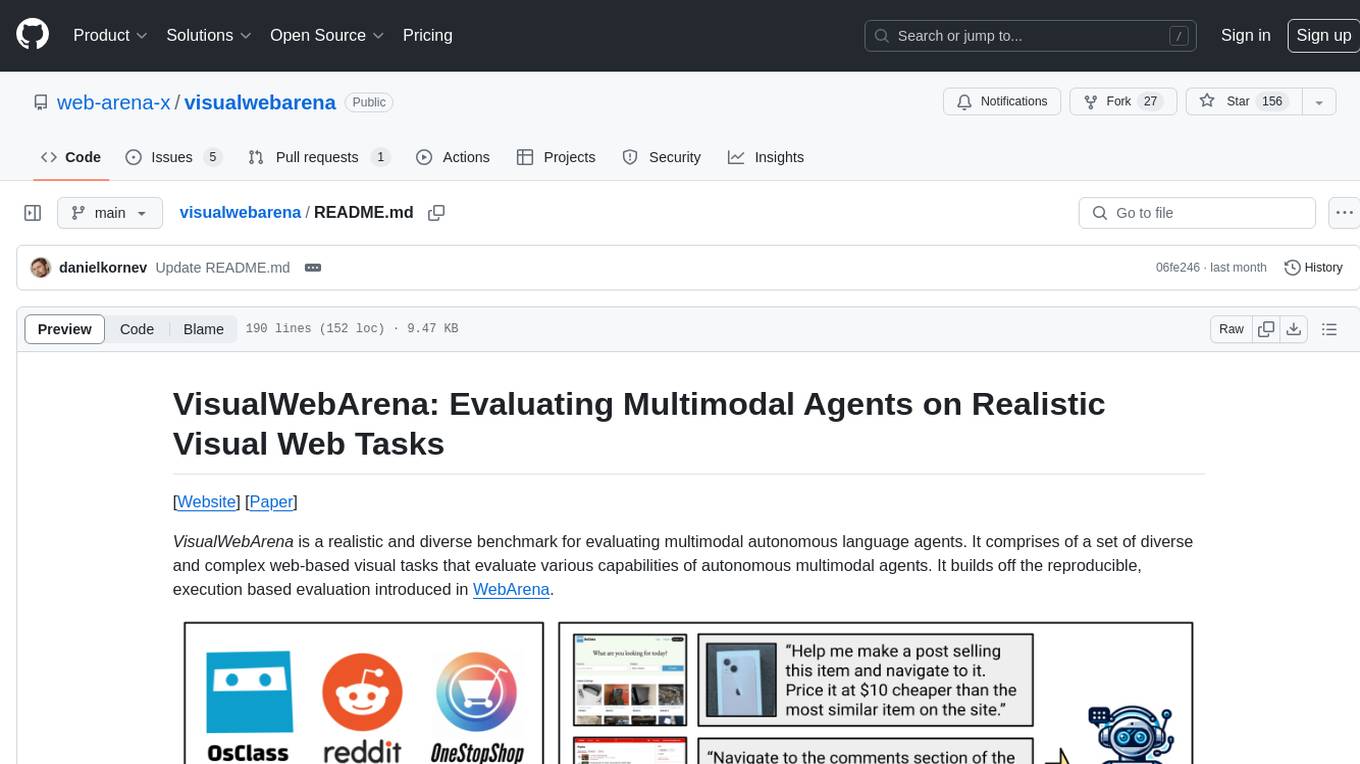
visualwebarena
VisualWebArena is a benchmark for evaluating multimodal autonomous language agents through diverse and complex web-based visual tasks. It builds on the reproducible evaluation introduced in WebArena. The repository provides scripts for end-to-end training, demos to run multimodal agents on webpages, and tools for setting up environments for evaluation. It includes trajectories of the GPT-4V + SoM agent on VWA tasks, along with human evaluations on 233 tasks. The environment supports OpenAI models and Gemini models for evaluation.

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
ScreenAgent
ScreenAgent is a project focused on creating an environment for Visual Language Model agents (VLM Agent) to interact with real computer screens. The project includes designing an automatic control process for agents to interact with the environment and complete multi-step tasks. It also involves building the ScreenAgent dataset, which collects screenshots and action sequences for various daily computer tasks. The project provides a controller client code, configuration files, and model training code to enable users to control a desktop with a large model.
For similar tasks
dlio_benchmark
DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
LLM4IR-Survey
LLM4IR-Survey is a collection of papers related to large language models for information retrieval, organized according to the survey paper 'Large Language Models for Information Retrieval: A Survey'. It covers various aspects such as query rewriting, retrievers, rerankers, readers, search agents, and more, providing insights into the integration of large language models with information retrieval systems.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.
eShopSupport
eShopSupport is a sample .NET application showcasing common use cases and development practices for building AI solutions in .NET, specifically Generative AI. It demonstrates a customer support application for an e-commerce website using a services-based architecture with .NET Aspire. The application includes support for text classification, sentiment analysis, text summarization, synthetic data generation, and chat bot interactions. It also showcases development practices such as developing solutions locally, evaluating AI responses, leveraging Python projects, and deploying applications to the Cloud.

Awesome-Knowledge-Distillation-of-LLMs
A collection of papers related to knowledge distillation of large language models (LLMs). The repository focuses on techniques to transfer advanced capabilities from proprietary LLMs to smaller models, compress open-source LLMs, and refine their performance. It covers various aspects of knowledge distillation, including algorithms, skill distillation, verticalization distillation in fields like law, medical & healthcare, finance, science, and miscellaneous domains. The repository provides a comprehensive overview of the research in the area of knowledge distillation of LLMs.
For similar jobs

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.