
monitors4codegen
Code and Data artifact for NeurIPS 2023 paper - "Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context". `multispy` is a lsp client library in Python intended to be used to build applications around language servers.
Stars: 179

This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.
README:
Alternative title: Guiding Language Models of Code with Global Context using Monitors
This repository hosts the official code and data artifact for the paper "Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context" appearing at NeurIPS 2023 ("Guiding Language Models of Code with Global Context using Monitors" on Arxiv). The work introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding.
- Datasets: PragmaticCode and DotPrompts
- Evaluation scripts: Scripts to evaluate LMs by taking as input inferences (code generated by the model) for examples in DotPrompts and producing score@k scores for the metrics reported in the paper: Compilation Rate (CR), Next-Identifier Match (NIM), Identifier-Sequence Match (ISM) and Prefix Match (PM).
- Inference Results over DotPrompts: Generated code for examples in DotPrompts with various model configurations reported in the paper. The graphs and tables reported in the paper can be reproduced by running the evaluation scripts on the provided inference results.
-
multilspy: A language server client, to easily obtain and use results of various static analyses provided by a large variety of language servers that communicate over the Language Server Protocol.multilspyis intended to be used as a library to easily query various language servers, without having to worry about setting up their configurations and implementing the client-side of language server protocol.multilspycurrently supports running language servers for Java, Rust, C# and Python, and we aim to expand this list with the help of the community. - Monitor-Guided Decoding: Implementation of various monitors monitoring for different properties reported in the paper (for example: monitoring for type-valid identifier dereferences, monitoring for correct number of arguments to method calls, monitoring for typestate validity of method call sequences, etc.), spanning 3 programming languages.
For example, consider the partial code to be completed in the figure below. To complete this code, an LM has to generate identifiers consistent with the type of the object returned by ServerNode.Builder.newServerNode(). The method newServerNode and its return type, class ServerNode.Builder, are defined in another file. If an LM does not have information about the ServerNode.Builder type, it ends up hallucinating, as can be seen in the example generations with the text-davinci-003 and SantaCoder models. The completion uses identifiers host and port, which do not exist in the type ServerNode.Builder. The generated code therefore results in “symbol not found” compilation errors.
MGD uses static analysis to guide the decoding of LMs, to generate code following certain properties. In the example, MGD is used to monitor for generating code with type-correct dereferences, and the SantaCoder model with the same prompt is able to generate the correct code completion, which compiles and matches the ground truth as well.
As reported in the paper, we observe that MGD can improve the compilation rate of code generated by LMs at all scales (350M-175B) by 19-25%, without any training/fine-tuning required. Further, it boosts the ground-truth match at all granularities from token-level to method-level code completion.

| Number of repositories in PragmaticCode | 100 |
| Number of methods in DotPrompts | 1420 |
| Number of examples in DotPrompts | 10538 |
PragmaticCode is a dataset of real-world open-source Java projects complete with their development environments and dependencies (through their respective build systems). The authors tried to ensure that all the repositories in PragmaticCode were released publicly only after the determined training dataset cutoff date (31 March 2022) for the CodeGen, SantaCoder and text-davinci-003 family of models, which were used to evaluate MGD.
The full dataset, along with repository zip files is available in our Zenodo dataset release at https://zenodo.org/records/10072088. The list of repositories along with their respective licenses consisting PragmaticCode is available in datasets/PragmaticCode/repos.csv. The contents of the files required for inference for each of the repositories is available in datasets/PragmaticCode/fileContentsByRepo.json.
DotPrompts is a set of examples derived from PragmaticCode, such that each example consists of a prompt to a dereference location (a code location having the "." operator in Java). DotPrompts can be used to benchmark Language Models of Code on their ability to utilize repository level context to generate code for method-level completion tasks. The task for the models is to complete a partially written Java method, utilizing the full repository available from PragmaticCode. Since all the repositories in PragmaticCode are buildable, DotPrompts (derived from PragmaticCode) supports Compilation Rate as a metric of evaluation for generated code, apart from standard metrics of ground truth match like Next-Identifier Match, Identifier Sequence Match and Prefix Match.
The scenario described in motivating example above is an example in DotPrompts.
The complete description of an example in DotPrompts is a tuple - (repo, classFileName, methodStartIdx, methodStopIdx, dot_idx). The dataset is available at datasets/DotPrompts/dataset.csv.
We use the Python packages listed in requirements.txt. Our experiments used python 3.10. It is recommended to install the same with dependencies in an isolated virtual environment. To create a virtual environment using venv:
python3 -m venv venv_monitors4codegen
source venv_monitors4codegen/bin/activate
or using conda:
conda create -n monitors4codegen python=3.10
conda activate monitors4codegen
Further details and instructions on creation of python virtual environments can be found in the official documentation. Further, we also refer users to Miniconda, as an alternative to the above steps for creation of the virtual environment.
To install the requirements for running evaluations as described below:
pip3 install -r requirements.txt
The evaluation script can be run as follows:
python3 eval_results.py <path to inference results - csv> <path to PragmaticCode filecontents - json> <path to output directory>
The above command will create a directory <path to output directory>, containing all the graphs and tables reported in the paper along with extra details. The command also generates a report in the output directory, named Report.md which relates the generated figures to sections in the paper.
To ensure that the environment setup has been done correctly, please run the below command, which runs the evaluation script over dummy data (included in inference_results/dotprompts_results_sample.csv). If the command fails, that indicates an error in the environment setup and the authors request you to kindly report the same.
python3 evaluation_scripts/eval_results.py inference_results/dotprompts_results_sample.csv datasets/PragmaticCode/fileContentsByRepo.json results_sample/
Description of expected columns in the inference results csv input to the evaluation script:
-
repo: Name of the repository from which the testcase was sourced -
classFileName: relative path to file containing the testcase prompt location -
methodStartIdx: String index of starting'{'of the method -
methodStopIdx: String index of closing'}'of the method -
dot_idx: String index of'.'that is the dereference prompt point -
configuration: Identifies the configuration used to generate the given code sample. Values from:['SC-classExprTypes', 'CG-6B', 'SC-FIM-classExprTypes', 'SC-RLPG-MGD', 'SC-MGD', 'SC-FIM-classExprTypes-MGD', 'CG-2B', 'SC', 'CG-2B-MGD', 'CG-350M-classExprTypes-MGD', 'SC-FIM', 'TD-3', 'CG-350M-MGD', 'SC-FIM-MGD', 'SC-RLPG', 'CG-350M', 'CG-350M-classExprTypes', 'SC-classExprTypes-MGD', 'CG-6B-MGD', 'TD-3-MGD'] -
temperature: Temperature used for sampling. Values from:[0.8, 0.6, 0.4, 0.2] -
model: Name of the model used for sampling. Values from:['Salesforce/codegen-6B-multi', 'bigcode/santacoder', 'Salesforce/codegen-2B-multi', 'Salesforce/codegen-350M-multi', 'text-davinci-003'] -
context: Decoding strategy used. Values from:['autoregressive', 'fim'] -
prefix: Prompt strategy used. Values from:['classExprTypes', 'none', 'rlpg'] -
rlpg_best_rule_name: Name of the rule used for creating RLPG prompt (if used for the corresponding testcase). Values from:[nan, 'in_file#lines#0.25', 'in_file#lines#0.5', 'in_file#lines#0.75', 'import_file#method_names#0.5'] -
output: Generated output by the model -
compilationSucceeded: Result of compiling the generated method in the context of the full repository. 1 if success, 0 otherwise. Values from:[1, 0]
We provide all inferences (generated code) generated by all model configurations reported in the paper, for every example in DotPrompts. This consists of 6 independently sampled inferences for 18 different model configurations (spanning parameter scale, prompt templates, use of FIM context, etc.) for every example in DotPrompts.
The generated samples along with their compilation status, following the format described above, is available at inference_results/dotprompts_results.csv. The file is stored using git lfs. If the file is not available locally after cloning this repository, please check the git lfs website for instructions on setup, and clone the repository again after git lfs setup.
Each row in the file contains several multi-line string cells, and therefore, while viewing them in tools like Microsoft Office Excel, kindly enable "Word Wrap" to be able to view the full contents.
To run the evaluation scripts over the inferences, in order to reproduce the graphs and tables reported in the paper, run:
python3 evaluation_scripts/eval_results.py inference_results/dotprompts_results.csv datasets/PragmaticCode/fileContentsByRepo.json results/
The above command creates a directory results (already included in the repository), containing all the figures and tables provided in the paper along with extra details. The command also generates a report in the output directory which relates the generated figures to sections in the paper. In case of above command, the report is generated at results/Report.md.
multilspy is a cross-platform library that we have built to set up and interact with various language servers in a unified and easy way. Language servers are tools that perform a variety of static analyses on source code and provide useful information such as type-directed code completion suggestions, symbol definition locations, symbol references, etc., over the Language Server Protocol (LSP). multilspy intends to ease the process of using language servers, by abstracting the setting up of the language servers, performing language-specific configuration and handling communication with the server over the json-rpc based protocol, while exposing a simple interface to the user.
Since LSP is language-agnostic, multilspy can provide the results for static analyses of code in different languages over a common interface. multilspy is easily extensible to any language that has a Language Server and currently supports Java, Rust, C# and Python and we aim to support more language servers from the list of language server implementations.
Some of the analyses results that multilspy can provide are:
- Finding the definition of a function or a class (textDocument/definition)
- Finding the callers of a function or the instantiations of a class (textDocument/references)
- Providing type-based dereference completions (textDocument/completion)
- Getting information displayed when hovering over symbols, like method signature (textDocument/hover)
- Getting list/tree of all symbols defined in a given file, along with symbol type like class, method, etc. (textDocument/documentSymbol)
- Please create an issue/PR to add any other LSP request not listed above
To install multilspy using pip, execute the following command:
pip install https://github.com/microsoft/monitors4codegen/archive/main.zip
Example usage:
from monitors4codegen.multilspy import SyncLanguageServer
from monitors4codegen.multilspy.multilspy_config import MultilspyConfig
from monitors4codegen.multilspy.multilspy_logger import MultilspyLogger
...
config = MultilspyConfig.from_dict({"code_language": "java"}) # Also supports "python", "rust", "csharp"
logger = MultilspyLogger()
lsp = SyncLanguageServer.create(config, logger, "/abs/path/to/project/root/")
with lsp.start_server():
result = lsp.request_definition(
"relative/path/to/code_file.java", # Filename of location where request is being made
163, # line number of symbol for which request is being made
4 # column number of symbol for which request is being made
)
result2 = lsp.request_completions(
...
)
result3 = lsp.request_references(
...
)
result4 = lsp.request_document_symbols(
...
)
result5 = lsp.request_hover(
...
)
...multilspy also provides an asyncio based API which can be used in async contexts. Example usage (asyncio):
from monitors4codegen.multilspy import LanguageServer
...
lsp = LanguageServer.create(...)
async with lsp.start_server():
result = await lsp.request_definition(
...
)
...The file src/monitors4codegen/multilspy/language_server.py provides the multilspy API. Several tests for multilspy present under tests/multilspy/ provide detailed usage examples for multilspy. The tests can be executed by running:
pytest tests/multilspyA monitor under the Monitor-Guided Decoding framework, is instantiated using multilspy as the LSP client, and provides maskgen to guide the LM decoding. The monitor interface is defined as class Monitor in file src/monitors4codegen/monitor_guided_decoding/monitor.py. The interface is implemented by various monitors supporting different properties like valid identifier dereferences, valid number of arguments, valid typestate method calls, etc.
src/monitors4codegen/monitor_guided_decoding/hf_gen.py provides the class MGDLogitsProcessor which can be used with any HuggingFace Language Model, as a LogitsProcessor to guide the LM using MGD. Example uses with SantaCoder model are available in tests/monitor_guided_decoding/test_dereferences_monitor_java.py.
src/monitors4codegen/monitor_guided_decoding/openai_gen.py provides the method openai_mgd which takes the prompt and a Monitor as input, and returns the MGD guided generation using an OpenAI model.
src/monitors4codegen/monitor_guided_decoding/monitors/dereferences_monitor.py provides the instantiation of Monitor class for dereferences monitor. It can be used to guide LMs to generate valid identifier dereferences. Unit tests for the dereferences monitor are present in tests/monitor_guided_decoding/test_dereferences_monitor_java.py, which also provide usage examples for the dereferences monitor.
src/monitors4codegen/monitor_guided_decoding/monitors/numargs_monitor.py provides the instantiation of Monitor class for numargs_monitor. It can be used to guide LMs to generate correct number of arguments to function calls. Unit tests, which also provide usage examples are present in tests/monitor_guided_decoding/test_numargs_monitor_java.py.
The typestate analysis is used to enforce that methods on an object are called in a certain order, consistent with the ordering constraints provided by the API contracts. Example usage of the typestate monitor for Rust is available in the unit test file tests/monitor_guided_decoding/test_typestate_monitor_rust.py.
src/monitors4codegen/monitor_guided_decoding/monitors/switch_enum_monitor.py provides the instantiation of Monitor for generating valid named enum constants in C#. Unit tests for the switch-enum monitor are present in tests/monitor_guided_decoding/test_switchenum_monitor_csharp.py, which also provide usage examples for the switch-enum monitor.
src/monitors4codegen/monitor_guided_decoding/monitors/class_instantiation_monitor.py provides the instantiation of Monitor for generating valid class instantiations following 'new ' in a Java code base. Unit tests for the class-instantiation monitor, which provide examples usages are present in tests/monitor_guided_decoding/test_classinstantiation_monitor_java.py.
Multiple monitors can be used simultaneously to guide LMs to adhere to multiple properties. Example demonstration with 2 monitors used jointly are present in tests/monitor_guided_decoding/test_joint_monitors.py.
If you get the following error:
RuntimeError: Task <Task pending name='Task-2' coro=<_AsyncGeneratorContextManager.__aenter__() running at
python3.8/contextlib.py:171> cb=[_chain_future.<locals>._call_set_state() at
python3.8/asyncio/futures.py:367]> got Future <Future pending> attached to a different loop python3.8/asyncio/locks.py:309: RuntimeError
Please ensure that you create a new environment with Python >=3.10. For further details, please have a look at the StackOverflow Discussion.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for monitors4codegen
Similar Open Source Tools
monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

BTGenBot
BTGenBot is a tool that generates behavior trees for robots using lightweight large language models (LLMs) with a maximum of 7 billion parameters. It fine-tunes on a specific dataset, compares multiple LLMs, and evaluates generated behavior trees using various methods. The tool demonstrates the potential of LLMs with a limited number of parameters in creating effective and efficient robot behaviors.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.

pgai
pgai simplifies the process of building search and Retrieval Augmented Generation (RAG) AI applications with PostgreSQL. It brings embedding and generation AI models closer to the database, allowing users to create embeddings, retrieve LLM chat completions, reason over data for classification, summarization, and data enrichment directly from within PostgreSQL in a SQL query. The tool requires an OpenAI API key and a PostgreSQL client to enable AI functionality in the database. Users can install pgai from source, run it in a pre-built Docker container, or enable it in a Timescale Cloud service. The tool provides functions to handle API keys using psql or Python, and offers various AI functionalities like tokenizing, detokenizing, embedding, chat completion, and content moderation.
ChatAFL
ChatAFL is a protocol fuzzer guided by large language models (LLMs) that extracts machine-readable grammar for protocol mutation, increases message diversity, and breaks coverage plateaus. It integrates with ProfuzzBench for stateful fuzzing of network protocols, providing smooth integration. The artifact includes modified versions of AFLNet and ProfuzzBench, source code for ChatAFL with proposed strategies, and scripts for setup, execution, analysis, and cleanup. Users can analyze data, construct plots, examine LLM-generated grammars, enriched seeds, and state-stall responses, and reproduce results with downsized experiments. Customization options include modifying fuzzers, tuning parameters, adding new subjects, troubleshooting, and working on GPT-4. Limitations include interaction with OpenAI's Large Language Models and a hard limit of 150,000 tokens per minute.
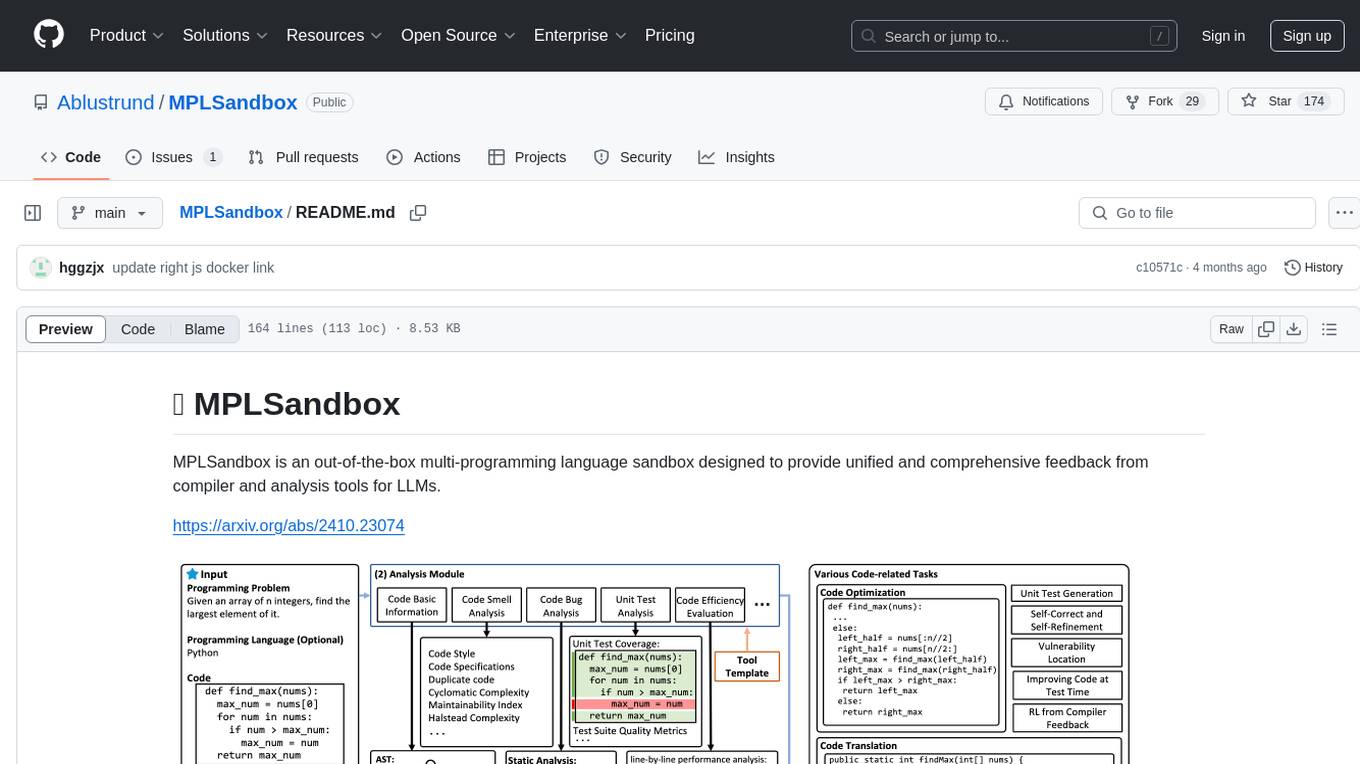
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.
For similar tasks
monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
generative-ai-python
The Google AI Python SDK is the easiest way for Python developers to build with the Gemini API. The Gemini API gives you access to Gemini models created by Google DeepMind. Gemini models are built from the ground up to be multimodal, so you can reason seamlessly across text, images, and code.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
MetaGPT
MetaGPT is a multi-agent framework that enables GPT to work in a software company, collaborating to tackle more complex tasks. It assigns different roles to GPTs to form a collaborative entity for complex tasks. MetaGPT takes a one-line requirement as input and outputs user stories, competitive analysis, requirements, data structures, APIs, documents, etc. Internally, MetaGPT includes product managers, architects, project managers, and engineers. It provides the entire process of a software company along with carefully orchestrated SOPs. MetaGPT's core philosophy is "Code = SOP(Team)", materializing SOP and applying it to teams composed of LLMs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.