
POPPER
Automated Hypothesis Testing with Agentic Sequential Falsifications
Stars: 123
Popper is an agentic framework for automated validation of free-form hypotheses using Large Language Models (LLMs). It follows Karl Popper's principle of falsification and designs falsification experiments to validate hypotheses. Popper ensures strict Type-I error control and actively gathers evidence from diverse observations. It delivers robust error control, high power, and scalability across various domains like biology, economics, and sociology. Compared to human scientists, Popper achieves comparable performance in validating complex biological hypotheses while reducing time by 10 folds, providing a scalable, rigorous solution for hypothesis validation.
README:
This repository hosts the code base for the paper
Automated Agentic Hypothesis Validation with Sequential Falsifications
Kexin Huang*, Ying Jin*, Ryan Li*, Michael Y. Li, Emmanuel Candès, Jure Leskovec
Link to Paper
If you find this work useful, please consider cite:
@misc{popper,
title={Automated Hypothesis Validation with Agentic Sequential Falsifications},
author={Kexin Huang and Ying Jin and Ryan Li and Michael Y. Li and Emmanuel Candès and Jure Leskovec},
year={2025},
eprint={2502.09858},
archivePrefix={arXiv}
}
Hypotheses are central to information acquisition, decision-making, and discovery. However, many real-world hypotheses are abstract, high-level statements that are difficult to validate directly. This challenge is further intensified by the rise of hypothesis generation from Large Language Models (LLMs), which are prone to hallucination and produce hypotheses in volumes that make manual validation impractical. Here we propose Popper, an agentic framework for rigorous automated validation of free-form hypotheses. Guided by Karl Popper's principle of falsification, Popper validates a hypothesis using LLM agents that design and execute falsification experiments targeting its measurable implications. A novel sequential testing framework ensures strict Type-I error control while actively gathering evidence from diverse observations, whether drawn from existing data or newly conducted procedures. We demonstrate Popper on six domains including biology, economics, and sociology. Popper delivers robust error control, high power, and scalability. Furthermore, compared to human scientists, Popper achieved comparable performance in validating complex biological hypotheses while reducing time by 10 folds, providing a scalable, rigorous solution for hypothesis validation.

We highly recommend using a virtual environment to manage the dependencies.
conda create -n popper_env python=3.10
conda activate popper_envFor direct usage of Popper, you can install the package via pip:
pip install popper_agentFor source code development, you can clone the repository and install the package:
git clone https://github.com/snap-stanford/POPPER.git
cd POPPER
pip install -r requirements.txtAdd the OpenAI/Anthropic API key to the environment variables:
export OPENAI_API_KEY="YOUR_API_KEY"
export ANTHROPIC_API_KEY="YOUR_API_KEY"Datasets will be automatically downloaded to specified data folder when you run the code.
A demo is provided in here to show how to use the Popper agent to validate a hypothesis and basic functionalities of the Popper agent.
from popper import Popper
# Initialize the Popper agent
agent = Popper(llm="claude-3-5-sonnet-20240620")
# Register data for hypothesis testing;
# for bio/discoverybench data in the paper,
# it will be automatically downloaded to your specified data_path
agent.register_data(data_path='path/to/data', loader_type='bio')
# Configure the agent with custom parameters
agent.configure(
alpha=0.1,
max_num_of_tests=5,
max_retry=3,
time_limit=2,
aggregate_test='E-value',
relevance_checker=True,
use_react_agent=True
)
# Validate a hypothesis
results = agent.validate(hypothesis="Your hypothesis here")
# Print the results
print(results)Popper supports inferencing with local LLM servers such as vLLM, SGLang, and llama.cpp, as long as they support OpenAI-compatible API. Here are some example usage with locally hosted LLMs:
Using SGLang:
# mistral large 2 with SGLang, using 4 GPUs with 8-bit quantization
python -m sglang.launch_server --model-path mistralai/Mistral-Large-Instruct-2411 --port 40000 --host 0.0.0.0 --tp 4 --quantization fp8 --mem-fraction-static 0.8 --trust-remote-codefrom popper import Popper
agent = Popper(llm="mistralai/Mistral-Large-Instruct-2411", is_locally_served=True, server_port=40000)
agent.configure(alpha=0.1)
agent.register_data(data_path='path/to/data', loader_type='bio')
agent.validate(hypothesis = 'YOUR HYPOTHESIS')Using vLLM:
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-abc123from popper import Popper
agent = Popper(llm="NousResearch/Meta-Llama-3-8B-Instruct", is_locally_served=True, server_port=8000, api_key="token-abc123")Using llama.cpp:
llama-server -m model.gguf --port 8080from popper import Popper
agent = Popper(llm="qwen2 1.5B", is_locally_served=True, server_port=8080)You can simply dump in a set of datasets in your domain (e.g. business, economics, political science, etc.) and run Popper on your own hypothesis. We only expect every file is in a csv or pkl format.
from popper import Popper
agent = Popper(llm="claude-3-5-sonnet-20240620")
agent.configure(alpha = 0.1)
agent.register_data(data_path='path/to/data', loader_type='custom')
agent.validate(hypothesis = 'YOUR HYPOTHESIS')You can arbitrarily define any free-form hypothesis. In the paper, we provide two types of hypothesis: biological hypothesis and discovery-bench hypothesis.
You can load the biological hypothesis with:
from popper.benchmark import gene_perturb_hypothesis
bm = gene_perturb_hypothesis(num_of_samples = samples, permuted=False, dataset = 'IL2', path = path)
example = bm.get_example(0)It will return something like:
{'prompt': 'Gene VAV1 regulates the production of Interleukin-2 (IL-2).',
'gene': 'VAV1',
'answer': 2.916,
'binary_answer': True}
num_of_samples is the number of samples you want to generate, permuted is whether you want to permute the dataset for type I error estimation, and dataset is the dataset you want to use and you can choose from IL2 and IFNG.
For discovery-bench, you can load the hypothesis with:
from popper.benchmark import discovery_bench_hypothesis
bm = discovery_bench_hypothesis(num_samples = samples, path = path)
example = bm.get_example(0)It will return something like:
{'task': 'archaeology',
'domain': 'humanities',
'metadataid': 5,
'query_id': 0,
'prompt': 'From 1700 BCE onwards, the use of hatchets and swords increased while the use of daggers decreased.',
'data_loader': <popper.utils.DiscoveryBenchDataLoader at 0x7c20793e9f70>,
'answer': True}
As each hypothesis in discoverybench has its own associated dataset, the example will return data_loader its own dataset.
Bash scripts for reproducing the paper is provided in the benchmark_scripts/run_targetval.sh for TargetVal benchmark and benchmark_scripts/run_discoverybench.sh for DiscoveryBench benchmark.
Note: the Popper agent can read or write files to your filesystem. We recommend running the benchmark scripts inside a containerized environments. We have provided a working Dockerfile and an example script to launch a Docker container and execute the scripts in benchmark_scripts/run_discoverybench_docker.sh.
To run paper benchmarks with locally-served models, you can simply passed in the extra parameters to the benchmark script, e.g.,
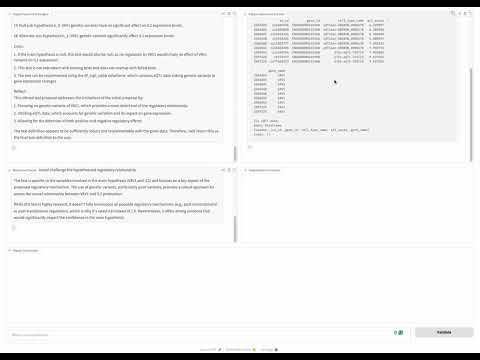
python benchmark_scripts/run_discovery_bench.py --exp_name discovery_bench --model llama-3.3-70b --num_tests 5 --samples 100 --permute --e_value --react --relevance_checker --is_locally_served --server_port 30000 --path PATH_TO_YOUR_DATASETYou can deploy a simple UI interface with one line of code using your datasets or our bio dataset - a gradio UI will be generated and you can interact with it to validate your hypothesis.
agent.launch_UI()An interface like this will be popped up:
The DiscoveryBench benchmark and some of the baseline agents are built on top of allenai/discoverybench. Thanks for their awsome work!
For any questions, please raise an issue in the GitHub or contact Kexin Huang ([email protected]).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for POPPER
Similar Open Source Tools
POPPER
Popper is an agentic framework for automated validation of free-form hypotheses using Large Language Models (LLMs). It follows Karl Popper's principle of falsification and designs falsification experiments to validate hypotheses. Popper ensures strict Type-I error control and actively gathers evidence from diverse observations. It delivers robust error control, high power, and scalability across various domains like biology, economics, and sociology. Compared to human scientists, Popper achieves comparable performance in validating complex biological hypotheses while reducing time by 10 folds, providing a scalable, rigorous solution for hypothesis validation.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

OlympicArena
OlympicArena is a comprehensive benchmark designed to evaluate advanced AI capabilities across various disciplines. It aims to push AI towards superintelligence by tackling complex challenges in science and beyond. The repository provides detailed data for different disciplines, allows users to run inference and evaluation locally, and offers a submission platform for testing models on the test set. Additionally, it includes an annotation interface and encourages users to cite their paper if they find the code or dataset helpful.
mimir
MIMIR is a Python package designed for measuring memorization in Large Language Models (LLMs). It provides functionalities for conducting experiments related to membership inference attacks on LLMs. The package includes implementations of various attacks such as Likelihood, Reference-based, Zlib Entropy, Neighborhood, Min-K% Prob, Min-K%++, Gradient Norm, and allows users to extend it by adding their own datasets and attacks.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

pgai
pgai simplifies the process of building search and Retrieval Augmented Generation (RAG) AI applications with PostgreSQL. It brings embedding and generation AI models closer to the database, allowing users to create embeddings, retrieve LLM chat completions, reason over data for classification, summarization, and data enrichment directly from within PostgreSQL in a SQL query. The tool requires an OpenAI API key and a PostgreSQL client to enable AI functionality in the database. Users can install pgai from source, run it in a pre-built Docker container, or enable it in a Timescale Cloud service. The tool provides functions to handle API keys using psql or Python, and offers various AI functionalities like tokenizing, detokenizing, embedding, chat completion, and content moderation.
VulBench
This repository contains materials for the paper 'How Far Have We Gone in Vulnerability Detection Using Large Language Model'. It provides a tool for evaluating vulnerability detection models using datasets such as d2a, ctf, magma, big-vul, and devign. Users can query the model 'Llama-2-7b-chat-hf' and store results in a SQLite database for analysis. The tool supports binary and multiple classification tasks with concurrency settings. Additionally, users can evaluate the results and generate a CSV file with metrics for each dataset and prompt type.

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.

verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.
strwythura
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.
For similar tasks
POPPER
Popper is an agentic framework for automated validation of free-form hypotheses using Large Language Models (LLMs). It follows Karl Popper's principle of falsification and designs falsification experiments to validate hypotheses. Popper ensures strict Type-I error control and actively gathers evidence from diverse observations. It delivers robust error control, high power, and scalability across various domains like biology, economics, and sociology. Compared to human scientists, Popper achieves comparable performance in validating complex biological hypotheses while reducing time by 10 folds, providing a scalable, rigorous solution for hypothesis validation.
AcademicForge
Academic Forge is a collection of skills integrated for academic writing workflows. It provides a curated set of skills related to academic writing and research, allowing for precise skill calls, avoiding confusion between similar skills, maintaining focus on research workflows, and receiving timely updates from original authors. The forge integrates carefully selected skills covering various areas such as bioinformatics, clinical research, data analysis, scientific writing, laboratory automation, machine learning, databases, AI research, model architectures, fine-tuning, post-training, distributed training, optimization, inference, evaluation, agents, multimodal tasks, and machine learning paper writing. It is designed to streamline the academic writing and AI research processes by providing a cohesive and community-driven collection of skills.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.