
llm_processes
None
Stars: 55

This repository contains code for LLM Processes, which focuses on generating numerical predictive distributions conditioned on natural language. It supports various LLMs through Hugging Face transformer APIs and includes experiments on prompt engineering, 1D synthetic data, comparison to LLMTime, Fashion MNIST, black-box optimization, weather regression, in-context learning, and text conditioning. The code requires Python 3.9+, PyTorch 2.3.0+, and other dependencies for running experiments and reproducing results.
README:
This repository contains the code to reproduce the experiments carried out in LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language.
The code has been authored by: John Bronskill, James Requeima, and Dami Choi.
This code requires the following:
- python 3.9 or greater
- PyTorch 2.3.0 or greater
- transformers 4.41.0 or greater
- accelerate 0.30.1 or greater
- jsonargparse 4.28.0 or greater
- matplotlib 3.9.0 or greater
- optuna 3.6.1 or greater (only needed if you intend to run the black-box optimization experiments)
- gpytorch 1.14 or greater (only if you intend to run the Gaussian Process code)
We support a variety of LLMs through the Hugging Face transformer APIs. The code currently supports the following LLMs:
| LLM Type | URL | GPU Memory Required (GB) |
|---|---|---|
| phi-3-mini-128k-instruct | https://huggingface.co/microsoft/Phi-3-mini-128k-instruct | 8 |
| llama-2-7B | https://huggingface.co/meta-llama/Llama-2-7b | 24 |
| llama-2-70B | https://huggingface.co/meta-llama/Llama-2-70b | 160 |
| llama-3-8B | https://huggingface.co/meta-llama/Meta-Llama-3-8B | 24 |
| llama-3-70B | https://huggingface.co/meta-llama/Meta-Llama-3-70B | 160 |
| mixtral-8x7B | https://huggingface.co/mistralai/Mixtral-8x7B-v0.1 | 160 |
| mixtral-8x7B-instruct | https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 | 160 |
Adding a new LLM that supports the hugging face APIs is not difficult, just modify hf_api.py.
- Clone or download this repository.
- Run
pip install .to install thellm_processespackage and all dependencies.
Installing the llm_processes package will automatically install the llm_process command. You can
view its arguments by running llm_process --help.
Use the command as:
llm_process --llm_type <LLM Type> [additional options]
Common options:
--experiment_name <value> specifies a name that will be used to name any output or plot files,
default is test.
--output_dir <directory where output files are written>, default is ./output.
--plot_dir <directory where output plot files are written>, default is ./plots.
--num_samples <number of samples to take at each target location>, default is 50.
--autoregressive <True/False>, if True, run A-LLMP, if False, run I-LLMP, default is False.
--batch_size <value> controls how many samples for each target point are processed at once. A higher value will
result in faster execution, but will consume more GPU memory. Lower this number if you get out of memory errors.
Default is 5.
The additional options are:
Data: --data_path <choose a file from the data/functions directory>.
In the experiments we used sigmoid_10_seed_*.pkl, square_20_seed_*.pkl, and linear_cos_75_seed_*.pkl,
where you would substitute a seed number for the *.
Prompt Format: --x_prefix <value>, --y_prefix <value>, and --break_str <value>
Prompt Order: --prompt_ordering <sequential/random/distance>
Prompt y-Scaling: --y_min <value> and --y_max <value>
Top-p and Temperature: --top_p <value> and --temperature <value>
Autoregressive: --autoregressive True
From the root directory of the repo, run:
python ./experiments/run_functions_exp.py --llm_type <LLM Type> --function <beat/exp/gaussian_wave/linear/linear_cos/log/sigmoid/sinc/sine/square/x_times_sine/xsin>
From the root directory of the repo, run:
python ./experiments/run_compare_exp.py --llm_type <LLM Type>
From the root directory of the repo, run:
python ./experiments/run_fashion_mnist_exp.py --llm_type <LLM Type>
From the root directory of the repo, run:
python ./experiments/run_black_box_opt_exp.py --llm_type <LLM Type> --experiment_name_prefix <see table> --function <see table> --max_generated_length <see table> --num_cold_start_points <see table>
| function | experiment_name_prefix | max_generated_length | num_cold_start_points |
|---|---|---|---|
| Sinusoidal | Sinusoidal | 7 | 7 |
| Gramacy | Gramacy | 8 | 12 |
| Branin | Branin | 7 | 12 |
| Bohachevsky | Bohachevsky | 11 | 12 |
| Goldstein | Goldstein | 12 | 12 |
| Hartmann3 | Hartmann3 | 7 | 15 |
From the root directory of the repo, run:
python run_llm_process.py --llm_type <LLM Type> --experiment_name weather_3 --data_path ./data/weather/weather_3.pkl --autoregressive True --num_decimal_places_y 1 --max_generated_length 20
From the root directory of the repo, run:
python ./experiments/run_in_context.py --llm_type <LLM Type>
From the root directory of the repo, run:
llm_process --llm_type <LLM Type> --data_path ./data/scenario/scenario_data_2_points.pkl --prefix <prompt to try> --autoregressive True --plot_trajectories 5 --forecast True
From the root directory of the repo, run:
python ./experiments/run_housing_exp.py --llm_type <LLM Type>
In the black-box optimization experiments, we use code from the benchfunk repository (Copyright (c) 2014, the benchfunk authors).
The datasets in the data/functions directory are derived from the synthetic datasets in the LLMTime repository (Copyright (c) 2023 Nate Gruver, Marc Finzi, Shikai Qiu).
To ask questions or report issues, please open an issue on the issues tracker.
If you use this code, please cite our paper:
@inproceedings{requeima2024llm,
author = {Requeima, James and Bronskill, John and Choi, Dami and Turner, Richard E and Duvenaud, David},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {109609--109671},
publisher = {Curran Associates, Inc.},
title = {LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/c5ec22711f3a4a2f4a0a8ffd92167190-Paper-Conference.pdf},
volume = {37},
year = {2024}
}
We have recently extended LLM Processes to tabular data in our paper JoLT: Joint Probabilistic Predictions on Tabular Data Using LLMs.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm_processes
Similar Open Source Tools
llm_processes
This repository contains code for LLM Processes, which focuses on generating numerical predictive distributions conditioned on natural language. It supports various LLMs through Hugging Face transformer APIs and includes experiments on prompt engineering, 1D synthetic data, comparison to LLMTime, Fashion MNIST, black-box optimization, weather regression, in-context learning, and text conditioning. The code requires Python 3.9+, PyTorch 2.3.0+, and other dependencies for running experiments and reproducing results.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.
evalica
Evalica is a powerful tool for evaluating code quality and performance in software projects. It provides detailed insights and metrics to help developers identify areas for improvement and optimize their code. With support for multiple programming languages and frameworks, Evalica offers a comprehensive solution for code analysis and optimization. Whether you are a beginner looking to learn best practices or an experienced developer aiming to enhance your code quality, Evalica is the perfect tool for you.

r2ai
r2ai is a tool designed to run a language model locally without internet access. It can be used to entertain users or assist in answering questions related to radare2 or reverse engineering. The tool allows users to prompt the language model, index large codebases, slurp file contents, embed the output of an r2 command, define different system-level assistant roles, set environment variables, and more. It is accessible as an r2lang-python plugin and can be scripted from various languages. Users can use different models, adjust query templates dynamically, load multiple models, and make them communicate with each other.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

TPI-LLM
TPI-LLM (Tensor Parallelism Inference for Large Language Models) is a system designed to bring LLM functions to low-resource edge devices, addressing privacy concerns by enabling LLM inference on edge devices with limited resources. It leverages multiple edge devices for inference through tensor parallelism and a sliding window memory scheduler to minimize memory usage. TPI-LLM demonstrates significant improvements in TTFT and token latency compared to other models, and plans to support infinitely large models with low token latency in the future.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
RepairAgent
RepairAgent is an autonomous LLM-based agent for automated program repair targeting the Defects4J benchmark. It uses an LLM-driven loop to localize, analyze, and fix Java bugs. The tool requires Docker, VS Code with Dev Containers extension, OpenAI API key, disk space of ~40 GB, and internet access. Users can get started with RepairAgent using either VS Code Dev Container or Docker Image. Running RepairAgent involves checking out the buggy project version, autonomous bug analysis, fix candidate generation, and testing against the project's test suite. Users can configure hyperparameters for budget control, repetition handling, commands limit, and external fix strategy. The tool provides output structure, experiment overview, individual analysis scripts, and data on fixed bugs from the Defects4J dataset.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
For similar tasks

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
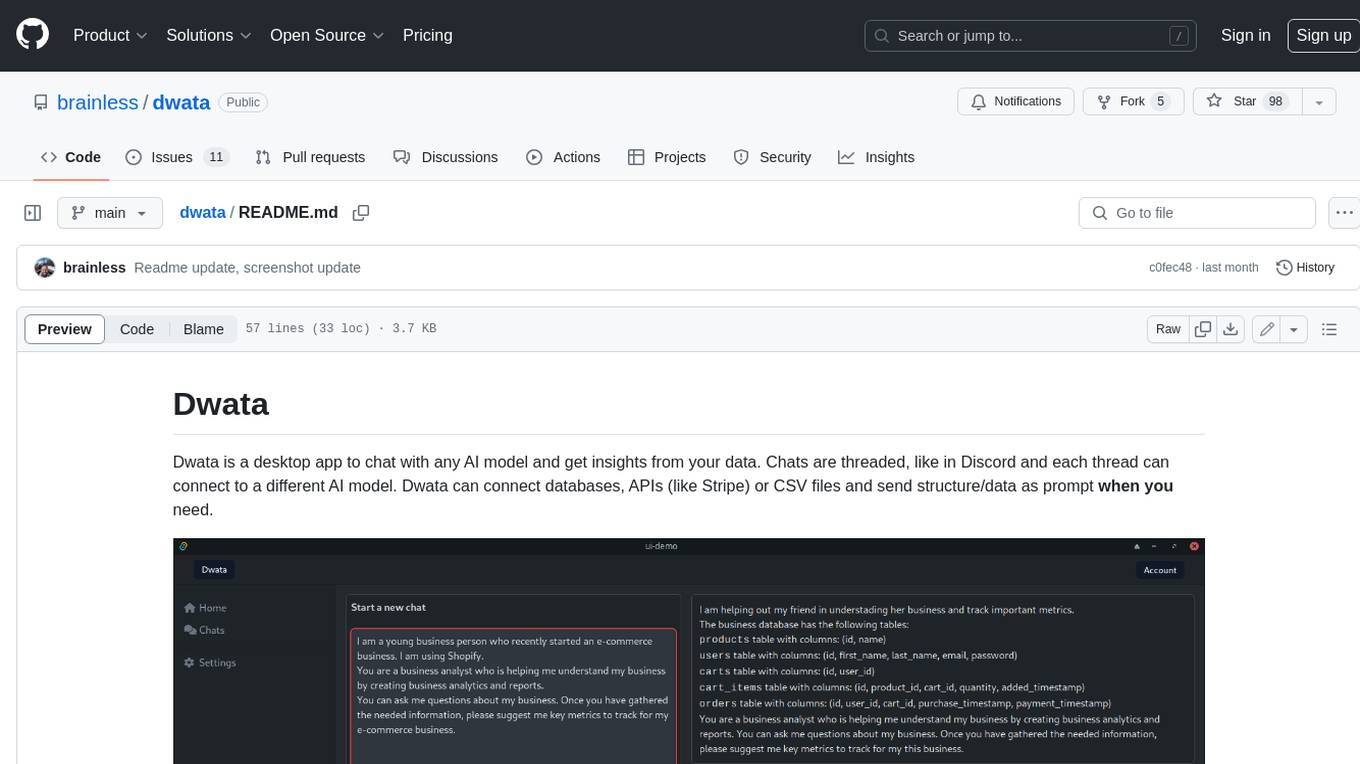
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.