
llm4regression
Examining how large language models (LLMs) perform across various synthetic regression tasks when given (input, output) examples in their context, without any parameter update
Stars: 115
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.
README:
This project explores the extent to which LLMs can do regression when given (input, output) pairs as in-context examples.
Preprint available on ArXiv: From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples.
Accepted at COLM: From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples.
Please refer to the FAQ.md for answers to some common questions.
Examples of GPT-4 chats with full prompts are available in data/prompts/README.md. For example, GPT-4 predicts 726.89 on Friedman #2, while gold is 689.01. (Note: we used API for all our experiments; we included Chat links just as simple examples)
LLMs perform surprisingly well. Despite no parameter updates, Claude 3 Opus consistently performs better than traditional methods such as Gradient Boosting or Random Forest. Strong performance is present in open-weights models such as DBRX or Mixtral 8x22B as well. For example, both DBRX and Mixtral rank higher, on average, than Random Forest. Colab links and jupyter notebooks with examples provided.
Colab links:
- GPT-4 Example: link
- GPT-4 Small Eval: link
- Claude 3 Opus Example: link
- Claude 3 Opus Small Eval: link
Jupyter Notebooks examples:
- GPT-4 Example: here
- GPT-4 Small Eval: here
- Claude 3 Opus Example: here
- Claude 3 Opus Small Eval: here
We use three types of models:
- Large Language Models (e.g., GPT-4, Claude 3, DBRX, Llama, etc)
- Traditional Supervised Methods (e.g., Linear Regression, Gradient Boosting, Random Forest, KNN, etc)
- Unsupervised Heuristics (e.g., just predict the average, etc)
We describe them in greater detail below.
We use over 20 large language models (LLMs), such as GPT-4, Claude 3, or DBRX, either through pay-per-token services or deployed locally. All the LLMs used are available in the table below.
| LLM | How was used | Additional details |
|---|---|---|
| GPT-4 | OpenAI API | gpt-4-0125-preview |
| GPT-4 (20240409) | OpenAI API | gpt-4-turbo-2024-04-09 |
| Chat GPT | OpenAI API | gpt-3.5-turbo-1106 |
| Davinci 002 | OpenAI API | davinci-002 |
| Babbage 002 | OpenAI API | babbage-002 |
| Claude 3 Opus | OpenRouter | anthropic/claude-3-opus |
| Claude 3 Sonnet | OpenRouter | anthropic/claude-3-sonnet |
| Claude 3 Haiku | OpenRouter | anthropic/claude-3-haiku |
| Claude 2.1 | OpenRouter | anthropic/claude-2.1 |
| Claude 2.0 | OpenRouter | anthropic/claude-2.0 |
| Claude 1.2 | OpenRouter | anthropic/claude-1.2 |
| Gemini Pro | OpenRouter | google/gemini-pro |
| Mistral Medium | OpenRouter | mistralai/mistral-medium |
| Cohere Command | OpenRouter | cohere/command |
| Cohere Command R | OpenRouter | cohere/command-r |
| Cohere Command R Plus | OpenRouter | cohere/command-r-plus |
| DBRX | Fireworks | accounts/fireworks/models/dbrx-instruct |
| Mixtral Mixture of Experts 8x22B | Fireworks | accounts/fireworks/models/mixtral-8x22b |
| Mixtral Mixture of Experts 8x7B | DeepInfra | mistralai/Mixtral-8x7B-Instruct-v0.1 |
| Mistral 7B v2 | DeepInfra | mistralai/Mistral-7B-Instruct-v0.2 |
| Mistral 7B | DeepInfra | mistralai/Mistral-7B-Instruct-v0.1 |
| Llama 2 70B Chat | DeepInfra | meta-llama/Llama-2-70b-chat-hf |
| Code Llama 2 70B Instruct | DeepInfra | codellama/CodeLlama-70b-Instruct-hf |
| Yi 34B Chat | DeepInfra | 01-ai/Yi-34B-Chat |
| Falcon 40B | Locally with TGI |
tiiuae/falcon-40b quantized to 8bits with bitsandbytes through TGI |
| Falcon 40B Instruct | Locally with TGI |
tiiuae/falcon-40b-instruct quantized to 8bits with bitsandbytes through TGI |
| StripedHyena Nous 7B | OpenRouter | togethercomputer/stripedhyena-nous-7b |
| RWKV v4 14B | Locally with Huggingface (AutoModelForCausalLM) |
rwkv-v4-14b |
We use over 20 traditional supervised methods typically used for regression (e.g., Gradient Boosting). We use models found in sklearn. We include in additional details the model name and any default parameter changes.
We used <..> for some parameters that are omitted for brevity (e.g., random state).
| Model Name | Additional Details |
|---|---|
| Linear Regression | LinearRegression |
| Ridge | Ridge |
| Lasso | Lasso |
| MLP Wide 1 | MLPRegressor(hidden_layer_sizes=(10, ), activation='relu', <..>) |
| MLP Wide 2 | MLPRegressor(hidden_layer_sizes=(100, ), activation='relu', <..>) |
| MLP Wide 3 | MLPRegressor(hidden_layer_sizes=(1000, ), activation='relu', <..>) |
| MLP Deep 1 | MLPRegressor(hidden_layer_sizes=(10, 10), activation='relu', <..>) |
| MLP Deep 2 | MLPRegressor(hidden_layer_sizes=(10, 20, 10), activation='relu', <..>) |
| MLP Deep 3 | MLPRegressor(hidden_layer_sizes=(10, 20, 30, 20, 10), activation='relu', <..>) |
| Random Forest | RandomForestRegressor(max_depth=3, <..>) |
| Bagging | BaggingRegressor |
| Gradient Boosting | GradientBoostingRegressor |
| AdaBoost | AdaBoostRegressor(n_estimators=100, <..>) |
| SVM | SVR |
| SVM + Scaler | make_pipeline(StandardScaler(), SVR()) |
| KNN v1 | KNeighborsRegressor |
| KNN v2 | KNeighborsRegressor(weights='distance') |
| Kernel Ridge | KernelRidge |
| Linear Regression + Poly | Pipeline([('poly', PolynomialFeatures(degree=degree)), ('linear', LinearRegression())]) |
| Spline | Pipeline([('spline', SplineTransformer(n_knots=n_knots, degree=degree)), ('linear', LinearRegression())]) |
| KNN v3 | KNeighborsRegressor(n_neighbors=3, weights='distance') |
| KNN v4 | KNeighborsRegressor(n_neighbors=1, weights='distance') |
| KNN v5 |
KNeighborsRegressor(n_neighbors=n_neighbors, weights='distance') (n_neigbors depends on the number of datapoints) |
We use heuristic-inspired baselines.
| Name | Additional Details |
|---|---|
| Average | Predict the average output of the train partition |
| Last | Predict the value corresponding to the last value in the train partition |
| Random | Predict the value corresponding to a randomly sampled value from the train partition |
We show below a comparison between a subset of the models we used:
-
LLMs: 9 large language models (LLMs), both open and private:
- Open: DBRX, Mixtral 8x22b, Mixtral 8x7B
- Private: Claude 3 Opus, Claude 3 Sonnet, GPT-4, GPT-4 (20240409), Chat GPT, Gemini Pro
-
Traditional Supervised Methods: 5 traditional methods:
- Linear Regression + Poly, Linear Regression, Gradient Boosting, Random Forests
-
Unsupervised Methods: 3 unsupervised methods:
- Average, Random, Last
For each of the 16 datasets used, we calculate the corresponding rank for each model. For each dataset, the performance was obtained by calculating the mean across 100 random runs. We average the resulting ranks across all datasets and sort based on which model obtained the best rank. For example, on this set of models, Claude 3 Opus obtains the best rank on average, outperforming all traditional supervised methods. Both DBRX and Mixtral 8x22B outperform, on average, Random Forest.
| Model Name | Average Rank Across Linear Datasets (6 datasets) |
Average rank Across Original Datasets (5 datasets) |
Average Rank Across Friedman Datasets (3 datasets) |
Average Rank Across NN Datasets (2 datasets) |
Average Rank Across Non-Linear Datastes (10 datasets) |
Overall (16 datasets) |
|---|---|---|---|---|---|---|
| Claude 3 Opus | 2.50 | 3.8 | 2.00 | 5.5 | 3.6 | 3.18 |
| Linear Regression + Poly | 2.33 | 6.4 | 2.33 | 2.5 | 4.4 | 3.62 |
| Claude 3 Sonnet | 5.33 | 4.0 | 2.66 | 7.0 | 4.2 | 4.62 |
| GPT-4 | 5.00 | 5.8 | 6.00 | 8.0 | 6.3 | 5.81 |
| Linear Regression | 1.16 | 11.0 | 9.00 | 2.5 | 8.7 | 5.87 |
| GPT-4 (20240409) | 5.50 | 6.2 | 6.00 | 10.5 | 7.0 | 6.43 |
| Gradient Boosting | 9.50 | 5.6 | 5.33 | 2.0 | 4.8 | 6.56 |
| DBRX | 7.83 | 8.2 | 8.66 | 10.5 | 8.8 | 8.43 |
| Mixtral 8x22B | 9.66 | 7.0 | 9.00 | 9.0 | 8.0 | 8.62 |
| Gemini Pro | 7.66 | 7.6 | 10.66 | 12.0 | 9.4 | 8.75 |
| Random Forest | 12.33 | 8.8 | 7.66 | 5.5 | 7.8 | 9.50 |
| KNN | 12.66 | 10.2 | 11.33 | 3.0 | 9.1 | 10.43 |
| Mixtral 8x7B | 11.50 | 10.2 | 12.33 | 13.0 | 11.4 | 11.43 |
| Chat GPT | 12.00 | 13.0 | 12.00 | 15.0 | 13.1 | 12.68 |
| Average | 15.00 | 12.2 | 15.00 | 14.0 | 13.4 | 14.00 |
| Random | 16.50 | 16.6 | 16.33 | 16.5 | 16.5 | 16.50 |
| Last | 16.50 | 16.4 | 16.66 | 16.5 | 16.5 | 16.50 |
Code to generate this table is available in how_to_create_plots_and_tables.md.
We used various linear and non-linear synthetic datasets. The exact definitions are available in src/dataset_utils.py. We did not add noise.
| Name | Additional Details | Definition |
|---|---|---|
| Regression NI 1/1 | A random linear regression dataset with 1 informative variable and 1 total variable | Please check sklearn |
| Regression NI 1/2 | A random linear regression dataset with 1 informative variable and 2 total variables | Please check sklearn |
| Regression NI 1/3 | A random linear regression dataset with 1 informative variable and 3 total variables | Please check sklearn |
| Regression NI 2/2 | A random linear regression dataset with 2 informative variables and 2 total variables | Please check sklearn |
| Regression NI 2/3 | A random linear regression dataset with 2 informative variables and 3 total variables | Please check sklearn |
| Regression NI 3/3 | A random linear regression dataset with 3 informative variables and 3 total variables | Please check sklearn |
| Friedman #1 | The Friedman #1 dataset (sklearn) | $10 sin(x_0 x_1 \pi) + 20 \cdot (x_2 - 0.5) ^ 2 + 10 x_3 + 5 x_4$ |
| Friedman #2 | The Friedman #2 dataset (sklearn) | $\sqrt{x_0 ^ 2 + (x_1 * x_2 - \frac{1}{x_1 x_3}) ^ 2}$ |
| Friedman #3 | The Friedman #3 dataset (sklearn) | $arctan(\frac{x_1 * x_2 - \frac{1}{x_1 * x_3}}{x_0})$ |
| Original #1 | A dataset with a single input variable, similar to a line with oscillations (by adding sin and cos) |
$x + 10sin(\frac{5\pi x}{100}) + 10cos(\frac{6\pi x}{100})$ |
| Original #2 | A dataset inspired by Friedman #2, but changing the domain of the input variable and some operants (e.g., $^2 \rightarrow ^4$) | $(x_0 ^ 4 + (x_1 * x_2 - \frac{2}{\sqrt{x_1} * \sqrt{x_3}})^2) ^ \frac{3}{4}$ |
| Original #3 | Trying more operands (e.g., $e^x$) | $e ^ {x_0} + \frac{x_1 x_2}{\sqrt{x_3}} + (x_0 x_3) ^ \frac{3}{2}$ |
| Original #4 | Trying more operands together (sin, cos, log, sqrt, fractions) | $\frac{x_1}{10} sin(x_0) + \frac{x_0}{10} cos(x_1) + \frac{\sqrt{x_0} log(x_1)}{\sqrt{x_1} log(x_0)}$ |
| Original #5 | Trying softmax | 100 * softmax(x/10, axis=-1).max(axis=-1) |
| Simple NN 1 | Initializing a random neural network and running it over random input. The output is considered gold | See get_random_nn1 in src/dataset_utils.py
|
| Transformer 1 | Initializing a random transformer encoder block and running random data. The output is considered gold | See get_random_transformer in src/dataset_utils.py
|
| Character | Mapping random characters (e.g., a) to a numeric value. Then sampling a vector to map back the characters |
See get_character_regression in src/dataset_utils.py
|
The camera ready version of the paper (publicly available since September 3rd link) contains results with five real-world datasets:
- Liver Disorders (UCI id=60)
- Real Estate Valuation (UCI id=477)
- Diabetes (from sklearn)
- Servo (UCI id=87)
- Movies (UCI id=424)
Overall, LLMs perform well on these datasets as well. For example, GPT-4 ranks 6th on Liver Disorders. Please see Appendix I) for additional details.
The heatmap below is structured into 3 blocks: (1) LLMs (left), (2) Traditional Supervised Methods (middle), and (3) Unsupervised baseline (right). Each model had access to the same dataset, containing 50 (input, output) examples and was asked to predict the output corresponding to the same test sample. The performance is averaged across 100 random runs.
Overall, LLMs generally outperform the unsupervised heuristics, suggesting that the in-context learning mechanism is more complex than such simple heuristics.
Certain LLMs, both private (e.g., Claude 3 Opus, GPT-4) and open (e.g., DBRX) can outperform supervised methods such as KNN, Gradient Boosting, or Random Forest. For example, except on the datasets derived from neural networks (and Original 4), Claude 3 Opus outperforms KNN, Gradient Boosting, and Random Forest on all datasets. This strong performance persists until at least 500 examples (Appendix O in the arxiv paper).

Borrowing from the Online Learning community, we empirically analyze how the cumulative regret (i.e., cumulative loss) grows with respect to the time step (number of examples in context). We ran up to 100 time steps and average the results across 3 random runs. We included in Appendix O in the arxiv paper how the performance of GPT-4 scales with up to 500 examples. GPT-4 still performs well. For example, it outperforms Random Forest in 92% of the cases.
Best curve fit table:
| model | friedman1 | friedman2 | friedman3 | original1 | original2 | regression_ni13 | regression_ni22 |
|---|---|---|---|---|---|---|---|
| Claude 3 Opus | linear | sqrt | sqrt | log | sqrt | log | log |
| GPT-4 | linear | sqrt | sqrt | log | sqrt | log | sqrt |
| DBRX | linear | log | linear | log | sqrt | sqrt | sqrt |
| Mixtral 8x7B | linear | linear | linear | sqrt | linear | linear | sqrt |
| AdaBoost | linear | sqrt | linear | sqrt | sqrt | sqrt | sqrt |
| Gradient Boosting | sqrt | sqrt | linear | log | sqrt | log | sqrt |
| Linear Regression | linear | linear | linear | linear | linear | log | log |
| Linear Regression + Poly | sqrt | log | log | linear | log | log | log |
| Random Forest | linear | sqrt | linear | sqrt | sqrt | sqrt | linear |
Claude 3 Opus on Original 1

To answer this question we: (1) tested the models on datasets where we wrote the underlying functions ourselves; (2) used models like Falcon where the training data is openly available; (3) analyzed whether the performance changes if the LLMs know the dataset name.
We found:
(1) LLMs perform well on these new "original" datasets;
(2) Falcon performance is also strong, albeit not to the level of the newer models. Nevertheless, Falcon outperforms MLP regressors on Original 1;
(3) The performance of models does not significantly changes if they have access to the name of the dataset they will be tested on.
The resulting data for all models can be found in data/outputs. Please see how_to_create_plots_and_tables.md for examples on how to interact with it.
Please check hot_to_add_dataset.md.
Please check hot_to_add_model.md.
Please check how_to_create_plots_and_tables.md.
There are examples on how to interact with the data there.
Please run the following command, inside this folder.
First, run python, then:
from src.dataset_utils import get_dataset
from src.regressors.prompts import construct_few_shot_prompt
# Get the dataset
((x_train, x_test, y_train, y_test), y_fn) = get_dataset('original1')(max_train=2, max_test=1, noise=0, random_state=1, round=True, round_value=2)
# The instruction prefix we used
instr_prefix='The task is to provide your best estimate for "Output". Please provide that and only that, without any additional text.\n\n\n\n\n'
fspt = construct_few_shot_prompt(x_train, y_train, x_test, encoding_type='vanilla')
inpt = instr_prefix + fspt.format(**x_test.to_dict('records')[0])
print(inpt)You should see the following output:
The task is to provide your best estimate for "Output". Please provide that and only that, without any additional text.
Feature 0: 0.01
Output: 10.03
Feature 0: 72.03
Output: 67.84
Feature 0: 41.7
Output:
Additionally, there is an example in prompt.txt.
More examples, together with links to Chat (note, however, that we used the API; This is just to be used as an example) can be found in data/prompts.
Please see the folders in src/experiments. Each folder contains a README.md file with additional explanations, including the reasoning behind the experiment. You will need specific API keys for models such as Claude, GPT-4, etc. I used the following files: (1) api.key for OpenAI, (2) api_deepinfra_personal.key for DeepInfra, (3) api_openrouter_personal.key for OpenRouter, and (4) api_fireworks_personal.key for Fireworks.
(1) For the regression performance, over both linear and non-linear datasets, please check the files in src/experiments/regression_performance.
For example, to re-run GPT-4, just run python -m src.experiments.regression_performance.regression_performance_openai. Please note that this command will re-run every dataset with gpt-4-0125-preview. Please change the code if you have different requirements.
(2) For the adaptation (online learning) experiments, please see src/experiments/regression_fast_adaptation.
(3) For the plateauing experiments, please see src/experiments/regression_plateauing.
(4) For generating justifications, please see src/experiments/regression_justifications.
(5) For contamination experiments, please see src/experiments/regression_contamination_check.
The outputs of the above experiments are released and available at data/outputs. Please see how_to_create_plots_and_tables.md for examples on how to interact with it and how to create the plots and tables used here.
Please use the following bibtex:
@inproceedings{
vacareanu2024from,
title={From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples},
author={Robert Vacareanu and Vlad Andrei Negru and Vasile Suciu and Mihai Surdeanu},
booktitle={First Conference on Language Modeling},
year={2024},
url={https://openreview.net/forum?id=LzpaUxcNFK}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm4regression
Similar Open Source Tools
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.

flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.
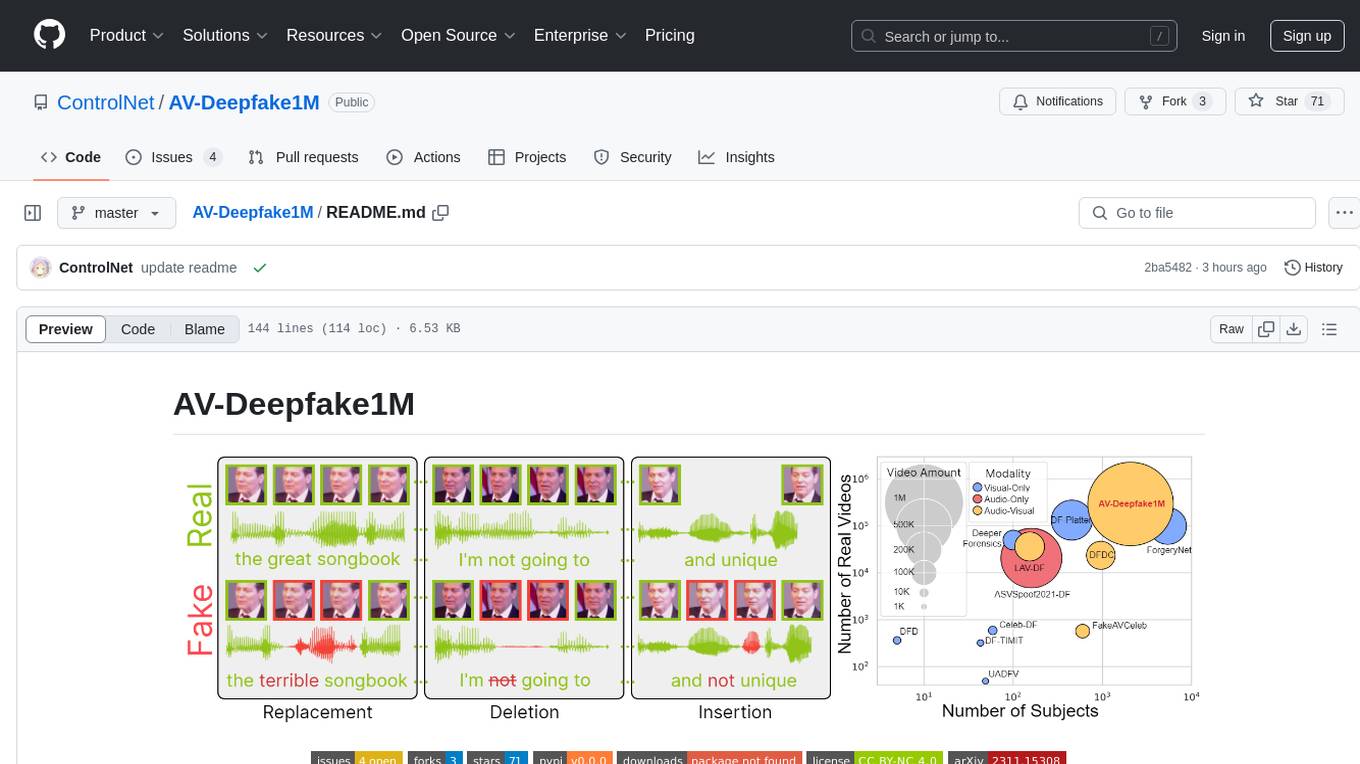
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
FlipAttack
FlipAttack is a jailbreak attack tool designed to exploit black-box Language Model Models (LLMs) by manipulating text inputs. It leverages insights into LLMs' autoregressive nature to construct noise on the left side of the input text, deceiving the model and enabling harmful behaviors. The tool offers four flipping modes to guide LLMs in denoising and executing malicious prompts effectively. FlipAttack is characterized by its universality, stealthiness, and simplicity, allowing users to compromise black-box LLMs with just one query. Experimental results demonstrate its high success rates against various LLMs, including GPT-4o and guardrail models.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
beet
Beet is a collection of crates for authoring and running web pages, games and AI behaviors. It includes crates like `beet_flow` for scenes-as-control-flow bevy library, `beet_spatial` for spatial behaviors, `beet_ml` for machine learning, `beet_sim` for simulation tooling, `beet_rsx` for authoring tools for html and bevy, and `beet_router` for file-based router for web docs. The `beet` crate acts as a base crate that re-exports sub-crates based on feature flags, similar to the `bevy` crate structure.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
For similar tasks
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.