
MARBLE
Code for MultiAgentBench : Evaluating the Collaboration and Competition of LLM agents https://www.arxiv.org/pdf/2503.01935
Stars: 61
MARBLE (Multi-Agent Coordination Backbone with LLM Engine) is a modular framework for developing, testing, and evaluating multi-agent systems leveraging Large Language Models. It provides a structured environment for agents to interact in simulated environments, utilizing cognitive abilities and communication mechanisms for collaborative or competitive tasks. The framework features modular design, multi-agent support, LLM integration, shared memory, flexible environments, metrics and evaluation, industrial coding standards, and Docker support.
README:
Multi-Agent CooRdination Backbone with LLM Engine
MultiAgentBench is a modular and extensible framework designed to facilitate the development, testing, and evaluation of multi-agent systems leveraging Large Language Models (LLMs). It provides a structured environment where agents can interact within various simulated environments, utilizing cognitive abilities and communication mechanisms to perform tasks collaboratively or competitively.

- Modular Design: Easily extend or replace components like agents, environments, and LLM integrations.
- Multi-Agent Support: Model complex interactions between multiple agents with hierarchical or cooperative execution modes.
- LLM Integration: Interface with various LLM providers (OpenAI, etc.) through a unified API.
- Shared Memory: Implement shared memory mechanisms for agent communication and collaboration.
- Flexible Environments: Support for different simulated environments like web-based tasks.
- Metrics and Evaluation: Built-in evaluation metrics to assess agent performance on tasks.
- Industrial Coding Standards: High-quality, well-documented code adhering to industry best practices.
- Docker Support: Containerized setup for consistent deployment and easy experimentation.

Use a virtual environment, e.g. with anaconda3:
conda create -n marble python=3.10
conda activate marble
curl -sSL https://install.python-poetry.org | python3
export PATH="$HOME/.local/bin:$PATH"Environment variables such as OPENAI_API_KEY and Together_API_KEY related configs are required to run the code. The recommended way to set all the required variable is
- Copy the
.env.templatefile into the project root with the name.env.
cp .env.template .env- Fill the required environment variables in the
.envfile.
To run examples provided in the examples:
poetry install
cd scripts
cd werewolf
bash run_simulation.shgit checkout -b feature/feature-name and PR to main branch.
Run poetry run pytest to make sure all tests pass (this will ensure dynamic typing passed with beartype) and poetry run mypy --config-file pyproject.toml . to check static typing. (You can also run pre-commit run --all-files to run all checks)
Check the github action result to make sure all tests pass. If not, fix the errors and push again.
Please cite the following paper if you find Marble helpful!
@misc{zhu2025multiagentbenchevaluatingcollaborationcompetition,
title={MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents},
author={Kunlun Zhu and Hongyi Du and Zhaochen Hong and Xiaocheng Yang and Shuyi Guo and Zhe Wang and Zhenhailong Wang and Cheng Qian and Xiangru Tang and Heng Ji and Jiaxuan You},
year={2025},
eprint={2503.01935},
archivePrefix={arXiv},
primaryClass={cs.MA},
url={https://arxiv.org/abs/2503.01935},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MARBLE
Similar Open Source Tools
MARBLE
MARBLE (Multi-Agent Coordination Backbone with LLM Engine) is a modular framework for developing, testing, and evaluating multi-agent systems leveraging Large Language Models. It provides a structured environment for agents to interact in simulated environments, utilizing cognitive abilities and communication mechanisms for collaborative or competitive tasks. The framework features modular design, multi-agent support, LLM integration, shared memory, flexible environments, metrics and evaluation, industrial coding standards, and Docker support.
Agent-R1
Agent-R1 is an open-source framework designed to accelerate research and development at the critical intersection of RL and Agent. It employs End-to-End reinforcement learning to train agents in specific environments. Developers define domain-specific tools and reward functions to extend Agent-R1 to unique use cases, eliminating the need for complex workflow engineering. Key features include multi-turn tool calling, multi-tool coordination, process rewards, custom tools and environments, support for multiple RL algorithms, and multi-modal support. It aims to make it easier for researchers and developers to create and explore agents in their own domains, collectively advancing the development of autonomous agents.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
CortexON
CortexON is an open-source, multi-agent AI system designed to automate and simplify everyday tasks. It integrates specialized agents like Web Agent, File Agent, Coder Agent, Executor Agent, and API Agent to accomplish user-defined objectives. CortexON excels at executing complex workflows, research tasks, technical operations, and business process automations by dynamically coordinating the agents' unique capabilities. It offers advanced research automation, multi-agent orchestration, integration with third-party APIs, code generation and execution, efficient file and data management, and personalized task execution for travel planning, market analysis, educational content creation, and business intelligence.
dot-ai
Dot-ai is a machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and utilities for data preprocessing, model training, and evaluation. With Dot-ai, users can easily create and experiment with various machine learning algorithms without the need for extensive coding knowledge. The library is built with scalability and performance in mind, making it suitable for both small-scale projects and large-scale applications. Whether you are a beginner or an experienced data scientist, Dot-ai offers a user-friendly interface to streamline your AI development workflow.

Mira
Mira is an agentic AI library designed for automating company research by gathering information from various sources like company websites, LinkedIn profiles, and Google Search. It utilizes a multi-agent architecture to collect and merge data points into a structured profile with confidence scores and clear source attribution. The core library is framework-agnostic and can be integrated into applications, pipelines, or custom workflows. Mira offers features such as real-time progress events, confidence scoring, company criteria matching, and built-in services for data gathering. The tool is suitable for users looking to streamline company research processes and enhance data collection efficiency.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.
Biosphere3
Biosphere3 is an Open-Ended Agent Evolution Arena and a large-scale multi-agent social simulation experiment. It simulates real-world societies and evolutionary processes within a digital sandbox. The platform aims to optimize architectures for general sovereign AI agents, explore the coexistence of digital lifeforms and humans, and educate the public on intelligent agents and AI technology. Biosphere3 is designed as a Citizen Science Game to engage more intelligent agents and human participants. It offers a dynamic sandbox for agent evaluation, collaborative research, and exploration of human-agent coexistence. The ultimate goal is to establish Digital Lifeform, advancing digital sovereignty and laying the foundation for harmonious coexistence between humans and AI.
Zentara-Code
Zentara Code is an AI coding assistant for VS Code that turns chat instructions into precise, auditable changes in the codebase. It is optimized for speed, safety, and correctness through parallel execution, LSP semantics, and integrated runtime debugging. It offers features like parallel subagents, integrated LSP tools, and runtime debugging for efficient code modification and analysis.
Auto-Analyst
Auto-Analyst is an AI-driven data analytics agentic system designed to simplify and enhance the data science process. By integrating various specialized AI agents, this tool aims to make complex data analysis tasks more accessible and efficient for data analysts and scientists. Auto-Analyst provides a streamlined approach to data preprocessing, statistical analysis, machine learning, and visualization, all within an interactive Streamlit interface. It offers plug and play Streamlit UI, agents with data science speciality, complete automation, LLM agnostic operation, and is built using lightweight frameworks.
multi-agent-orchestrator
Multi-Agent Orchestrator is a flexible and powerful framework for managing multiple AI agents and handling complex conversations. It intelligently routes queries to the most suitable agent based on context and content, supports dual language implementation in Python and TypeScript, offers flexible agent responses, context management across agents, extensible architecture for customization, universal deployment options, and pre-built agents and classifiers. It is suitable for various applications, from simple chatbots to sophisticated AI systems, accommodating diverse requirements and scaling efficiently.
kheish
Kheish is an open-source, multi-role agent designed for complex tasks that require structured, step-by-step collaboration with Large Language Models (LLMs). It acts as an intelligent agent that can request modules on demand, integrate user feedback, switch between specialized roles, and deliver refined results. By harnessing multiple 'sub-agents' within one framework, Kheish tackles tasks like security audits, file searches, RAG-based exploration, and more.
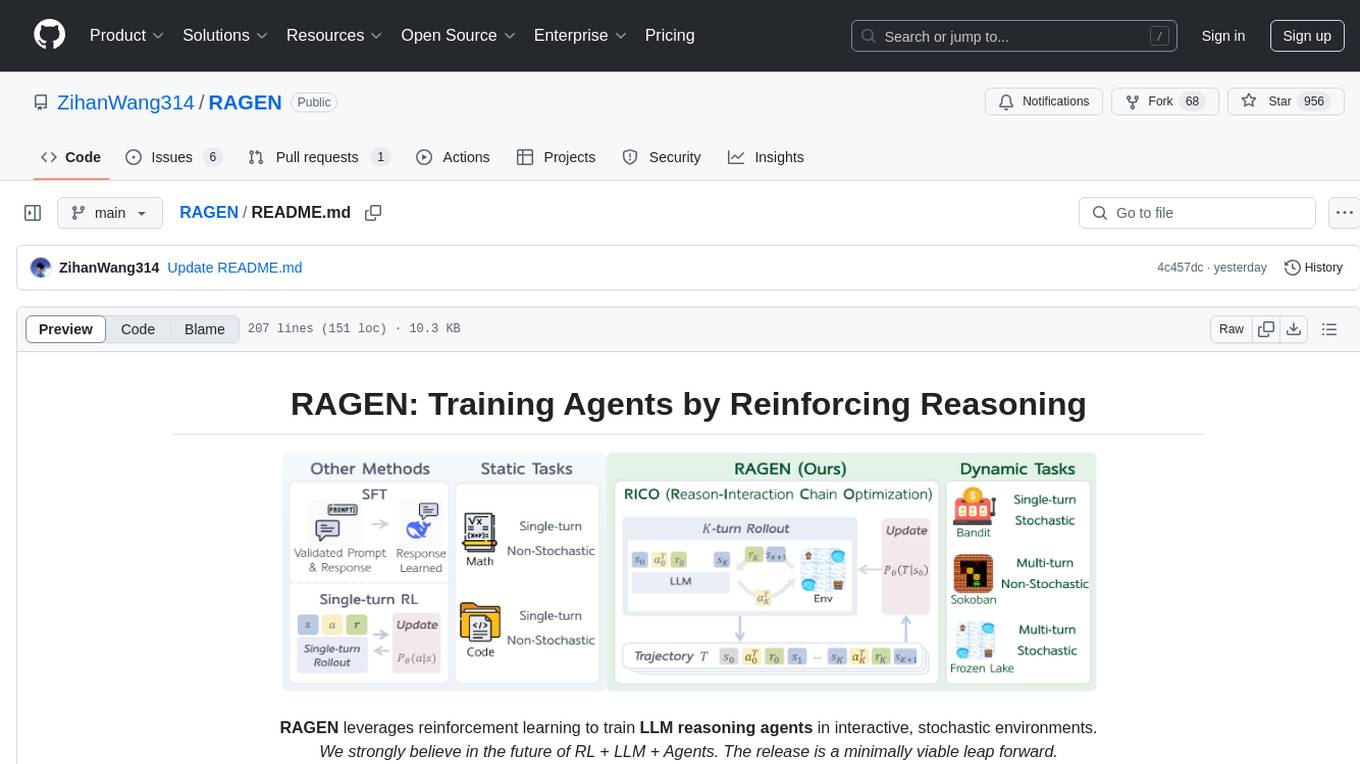
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.

maiar-ai
MAIAR is a composable, plugin-based AI agent framework designed to abstract data ingestion, decision-making, and action execution into modular plugins. It enables developers to define triggers and actions as standalone plugins, while the core runtime handles decision-making dynamically. This framework offers extensibility, composability, and model-driven behavior, allowing seamless addition of new functionality. MAIAR's architecture is influenced by Unix pipes, ensuring highly composable plugins, dynamic execution pipelines, and transparent debugging. It remains declarative and extensible, allowing developers to build complex AI workflows without rigid architectures.
Vodalus-Expert-LLM-Forge
Vodalus Expert LLM Forge is a tool designed for crafting datasets and efficiently fine-tuning models using free open-source tools. It includes components for data generation, LLM interaction, RAG engine integration, model training, fine-tuning, and quantization. The tool is suitable for users at all levels and is accompanied by comprehensive documentation. Users can generate synthetic data, interact with LLMs, train models, and optimize performance for local execution. The tool provides detailed guides and instructions for setup, usage, and customization.
For similar tasks

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.
LLM-Agents-Papers
A repository that lists papers related to Large Language Model (LLM) based agents. The repository covers various topics including survey, planning, feedback & reflection, memory mechanism, role playing, game playing, tool usage & human-agent interaction, benchmark & evaluation, environment & platform, agent framework, multi-agent system, and agent fine-tuning. It provides a comprehensive collection of research papers on LLM-based agents, exploring different aspects of AI agent architectures and applications.

council
Council is an open-source platform designed for the rapid development and deployment of customized generative AI applications using teams of agents. It extends the LLM tool ecosystem by providing advanced control flow and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators, and Budgets. The framework allows for automated routing between agents, comparing, evaluating, and selecting the best results for a task. Council aims to facilitate packaging and deploying agents at scale on multiple platforms while enabling enterprise-grade monitoring and quality control.
ComfyBench
ComfyBench is a comprehensive benchmark tool designed to evaluate agents' ability to design collaborative AI systems in ComfyUI. It provides tasks for agents to learn from documents and create workflows, which are then converted into code for better understanding by LLMs. The tool measures performance based on pass rate and resolve rate, reflecting the correctness of workflow execution and task realization. ComfyAgent, a component of ComfyBench, autonomously designs new workflows by learning from existing ones, interpreting them as collaborative AI systems to complete given tasks.
MARBLE
MARBLE (Multi-Agent Coordination Backbone with LLM Engine) is a modular framework for developing, testing, and evaluating multi-agent systems leveraging Large Language Models. It provides a structured environment for agents to interact in simulated environments, utilizing cognitive abilities and communication mechanisms for collaborative or competitive tasks. The framework features modular design, multi-agent support, LLM integration, shared memory, flexible environments, metrics and evaluation, industrial coding standards, and Docker support.
Awesome-Agent-Papers
This repository is a comprehensive collection of research papers on Large Language Model (LLM) agents, organized across key categories including agent construction, collaboration mechanisms, evolution, tools, security, benchmarks, and applications. The taxonomy provides a structured framework for understanding the field of LLM agents, bridging fragmented research threads by highlighting connections between agent design principles and emergent behaviors.
LLM-Agent-Evaluation-Survey
LLM-Agent-Evaluation-Survey is a tool designed to gather feedback and evaluate the performance of AI agents. It provides a user-friendly interface for users to rate and provide comments on the interactions with AI agents. The tool aims to collect valuable insights to improve the AI agents' capabilities and enhance user experience. With LLM-Agent-Evaluation-Survey, users can easily assess the effectiveness and efficiency of AI agents in various scenarios, leading to better decision-making and optimization of AI systems.
get-started-with-ai-agents
The 'Getting Started with Agents Using Azure AI Foundry' repository provides a solution that deploys a web-based chat application with an AI agent running in Azure Container App. The agent leverages Azure AI services for knowledge retrieval from uploaded files, enabling it to generate responses with citations. The solution includes built-in monitoring capabilities for easier troubleshooting and optimized performance. Users can deploy AI models, customize the agent, and evaluate its performance. The repository offers flexible deployment options through GitHub Codespaces, VS Code Dev Containers, or local environments.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.