
ComfyBench
Implementation for the paper "ComfyBench: Benchmarking LLM-based Agents in ComfyUI for Autonomously Designing Collaborative AI Systems".
Stars: 135
ComfyBench is a comprehensive benchmark tool designed to evaluate agents' ability to design collaborative AI systems in ComfyUI. It provides tasks for agents to learn from documents and create workflows, which are then converted into code for better understanding by LLMs. The tool measures performance based on pass rate and resolve rate, reflecting the correctness of workflow execution and task realization. ComfyAgent, a component of ComfyBench, autonomously designs new workflows by learning from existing ones, interpreting them as collaborative AI systems to complete given tasks.
README:
ComfyBench: Benchmarking LLM-based Agents in ComfyUI for Autonomously Designing Collaborative AI Systems
Implementation for the paper "ComfyBench: Benchmarking LLM-based Agents in ComfyUI for Autonomously Designing Collaborative AI Systems".
Xiangyuan Xue
Zeyu Lu
Di Huang
Zidong Wang
Wanli Ouyang
Lei Bai*

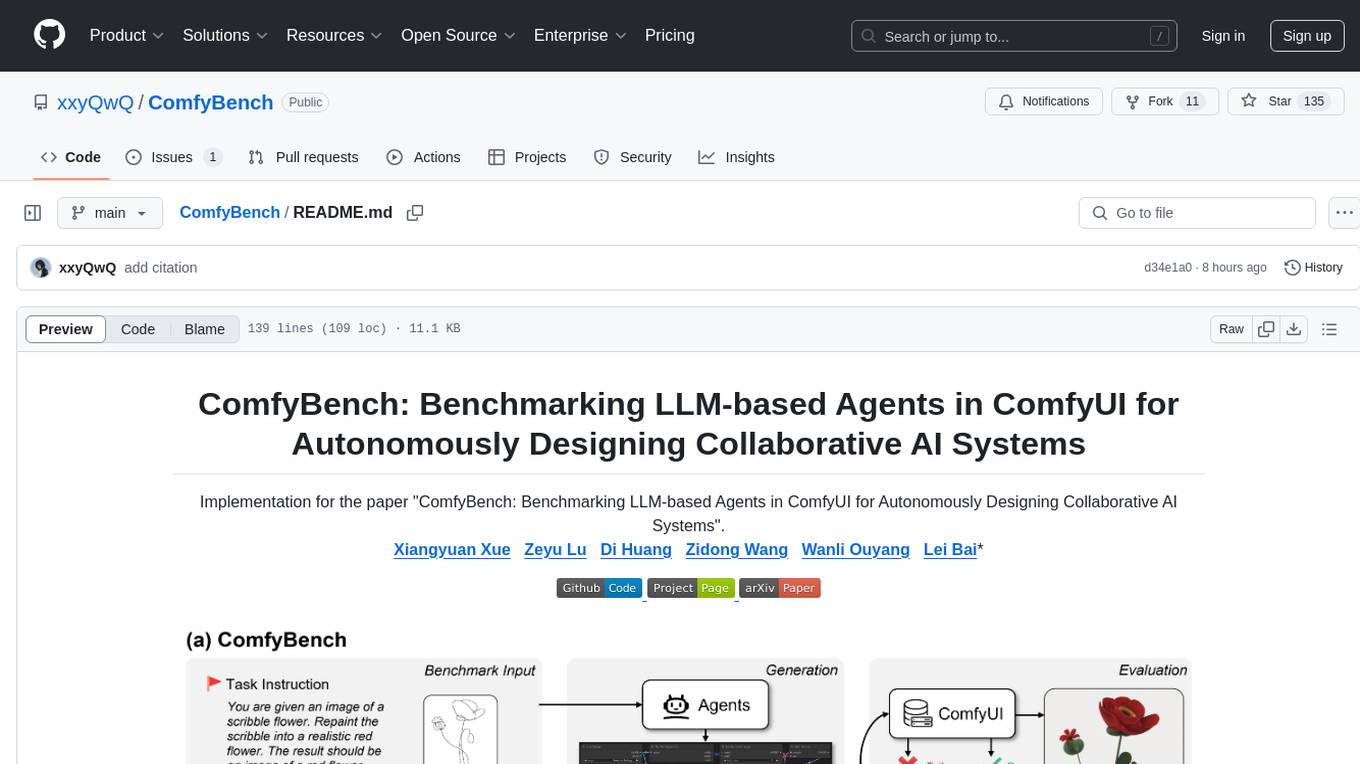
(a) ComfyBench is a comprehensive benchmark to evaluate agents's ability to design collaborative AI systems in ComfyUI. Given the task instruction, agents are required to learn from documents and create workflows to describe collaborative AI systems. The performance is measured by pass rate and resolve rate, reflecting whether the workflow can be correctly executed and whether the task requirements are realized. (b) ComfyAgent builds collaborative Al systems in ComfyUI by generating workflows. The workflows are converted into equivalent code so that LLMs can better understand them. ComfyAgent can learn from existing workflows and autonomously design new ones. The generated workflows can be interpreted as collaborative AI systems to complete given tasks.
- [2024/11/20] The latest version of our code is updated.
- [2024/11/14] The work is further extended and renamed as ComfyBench.
- [2024/09/04] Our code implementation is released on GitHub.
- [2024/09/02] The initial version of our paper is submitted to arXiv.
First, clone the repository and navigate to the project directory:
git clone https://github.com/xxyQwQ/ComfyBench
cd ComfyBenchThen, create a new conda environment and install the dependencies:
conda create -n comfybench python=3.12
conda activate comfybench
pip install -r requirements.txtFinally, modify config.yaml to set your ComfyUI server and API key. Feel free to change proxies and models if necessary.
Despite some models can be automatically installed, other models need to be manually downloaded and placed in the specific directory. You may find them by yourself on Hugging Face or directly download from our Cloud Drive. Besides, we provide a list of extensions in assets/extension.md so that you can install them manually. You can verify the completeness with the workflows in dataset/benchmark/workflow.
Run the following commands to execute the ComfyAgent pipeline:
# activate the conda environment
conda activate comfybench
# execute the main script
# see `main.py` for more parameter settings
python main.py \
--instruction "task-instruction" \
--agent_name "comfy" \
--save_path "path/to/save/result"The log file together with the workflow will be saved in the specified path. If your ComfyUI server is working properly, the workflow will be executed automatically to produce the result.
ComfyBench is provided under dataset/benchmark. The document folder contains documentation for 3205 nodes, where meta.json records the metadata of each node. The workflow folder contains 20 curriculum workflows for agents to learn from. The instruction provides all the tasks in ComfyBench, where complete.json contains 200 task instructions and sample.json contains a subset of 10 task instructions for validation.
Before evaluating on ComfyBench, you should copy the resource files in dataset/benchmark/resource into the input folder of ComfyUI, so that ComfyUI can load them during the workflow execution. Then you can evaluate the specific agent by running the following commands. Here we take ComfyAgent as an example.
# activate the conda environment and set up environment variables
conda activate comfybench
export PYTHONPATH=./
# execute the inference script
# see `script/inference.py` for more parameter settings
python script/inference.py \
--agent_name "comfy" \
--save_path "cache/benchmark/comfy"
# execute the evaluation script
# see `script/evaluation.py` for more parameter settings
python script/evaluation.py \
--submit_folder "cache/benchmark/comfy/workflow" \
--cache_path "cache/benchmark/comfy/outcome"In this example, the log files and generated workflows will be saved in cache/benchmark/comfy/logging and cache/benchmark/comfy/workflow, respectively. The produced results will be saved in cache/benchmark/comfy/outcome, together with a result.json recording whether each task is passed and resolved, and a summary.txt summarizing the overall metrics.
Here are some examples of the results produced by ComfyAgent on ComfyBench. Visit our Project Page for more details.
| Task Instruction | Input | Result |
|---|---|---|
| Generate an image of a hot air balloon floating over a scenic valley at sunrise. The result should be a high-quality image. | N/A |  |
| Generate an image of a modern city skyline at night with illuminated skyscrapers. The result should be a high-quality image. | N/A |  |
| You are given an image of a scribble flower. Repaint the scribble into a realistic red flower. The result should be an image of a red flower. |  |
 |
| You are given an image of a red apple. Change it into a green apple on a table while maintaining other details. The result should be an image of a green apple. |  |
 |
| You are given an image of a sample logo containing a bird pattern. Convert it into a cubist art poster with dark colors. The result should be an image of a poster without watermark. |  |
 |
| You are given an image of a large castle standing on top of a hill. Convert the castle into the style of ice cream while maintaining its original structure. The result should be an image with the castle transformed into a colorful and fantastic ice cream castle. |  |
 |
| You are given a low-resolution photo of a crowd of people. Upscale the image by 4x. The result should be a high-resolution version of the image. |  |
 |
| You are given an image of a table filled with dishes. Remove the fork on the table. The result should be a high-quality image without visible artifacts. |  |
 |
| You are given an image of a red car parked on the street. Replace the tree behind the car with a white house. The result should be a high-quality image without visible artifacts. |  |
 |
| You are given an image of a red bridge with a person standing on it. Remove the person from the image while maintaining the original appearance of the bridge. The result should be a high-quality image without visible artifacts. |  |
 |
| You are given a photo of mountains and rivers with a visible watermark in the bottom right corner. Remove the watermark from the image while maintaining the quality and content of the original photo. The result should be a high-quality image without the watermark. |  |
 |
| You are given an image of a girl playing the guitar. Generate an image of an old man playing the guitar in a forest with the same pose as the girl. The result should be a realistic image of an old man playing the guitar. |  |
 |
| You are given an image of a man wearing a black jacket. Change the black jacket into a white hoodie while ensuring that the modification looks natural and realistic. The result should be a high-quality image of the man wearing a white hoodie. |  |
 |
| You are given an image of a male celebrity. Transform the man in the image into a beautiful woman with ponytail hair while preserving her facial identity. The result should be a high-quality image of the woman. |  |
 |
| You are given an image of a toy dog. Replace the background with a scene of a sunny park with green grass while keeping the lighting and shadows consistent. The result should be an image of the toy dog in the park scene. |  |
 |
| You are given an image of a standing cat. Replace the background with a scene of a cozy living room while keeping the lighting and shadows consistent. The result should be an image of the cat in the living room scene. |  |
 |
| You are given an image containing two bottles of cosmetic products illuminated by a soft yellow light. Modify the illumination into a bright pink light to create a more vibrant and attractive appearance. The result should be an image of the cosmetic products with the new illumination. |  |
 |
If you find our work helpful, please consider citing our paper:
@article{xue2024comfybench,
title={ComfyBench: Benchmarking LLM-based Agents in ComfyUI for Autonomously Designing Collaborative AI Systems},
author={Xue, Xiangyuan and Lu, Zeyu and Huang, Di and Wang, Zidong and Ouyang, Wanli and Bai, Lei},
journal={arXiv preprint arXiv:2409.01392},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ComfyBench
Similar Open Source Tools
ComfyBench
ComfyBench is a comprehensive benchmark tool designed to evaluate agents' ability to design collaborative AI systems in ComfyUI. It provides tasks for agents to learn from documents and create workflows, which are then converted into code for better understanding by LLMs. The tool measures performance based on pass rate and resolve rate, reflecting the correctness of workflow execution and task realization. ComfyAgent, a component of ComfyBench, autonomously designs new workflows by learning from existing ones, interpreting them as collaborative AI systems to complete given tasks.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.
stable-diffusion-webui-Layer-Divider
This repository contains an implementation of the Segment-Anything Model (SAM) within the SD WebUI. It allows users to divide layers in the SD WebUI and save them as PSD files. Users can adjust parameters, click 'Generate', and view the output below. A PSD file will be saved in the designated folder. The tool provides various parameters for customization, such as points_per_side, pred_iou_thresh, stability_score_thresh, crops_n_layers, crop_n_points_downscale_factor, and min_mask_region_area.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.

universal
The Universal Numbers Library is a header-only C++ template library designed for universal number arithmetic, offering alternatives to native integer and floating-point for mixed-precision algorithm development and optimization. It tailors arithmetic types to the application's precision and dynamic range, enabling improved application performance and energy efficiency. The library provides fast implementations of special IEEE-754 formats like quarter precision, half-precision, and quad precision, as well as vendor-specific extensions. It supports static and elastic integers, decimals, fixed-points, rationals, linear floats, tapered floats, logarithmic, interval, and adaptive-precision integers, rationals, and floats. The library is suitable for AI, DSP, HPC, and HFT algorithms.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.
swt-bench
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

doku
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just a single line of code. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.
For similar tasks
ComfyBench
ComfyBench is a comprehensive benchmark tool designed to evaluate agents' ability to design collaborative AI systems in ComfyUI. It provides tasks for agents to learn from documents and create workflows, which are then converted into code for better understanding by LLMs. The tool measures performance based on pass rate and resolve rate, reflecting the correctness of workflow execution and task realization. ComfyAgent, a component of ComfyBench, autonomously designs new workflows by learning from existing ones, interpreting them as collaborative AI systems to complete given tasks.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.
yudao-boot-mini
yudao-boot-mini is an open-source project focused on developing a rapid development platform for developers in China. It includes features like system functions, infrastructure, member center, data reports, workflow, mall system, WeChat official account, CRM, ERP, etc. The project is based on Spring Boot with Java backend and Vue for frontend. It offers various functionalities such as user management, role management, menu management, department management, workflow management, payment system, code generation, API documentation, database documentation, file service, WebSocket integration, message queue, Java monitoring, and more. The project is licensed under the MIT License, allowing both individuals and enterprises to use it freely without restrictions.
psychic
Finic is an open source python-based integration platform designed to simplify integration workflows for both business users and developers. It offers a drag-and-drop UI, a dedicated Python environment for each workflow, and generative AI features to streamline transformation tasks. With a focus on decoupling integration from product code, Finic aims to provide faster and more flexible integrations by supporting custom connectors. The tool is open source and allows deployment to users' own cloud environments with minimal legal friction.
finic
Finic is an open source python-based integration platform designed for business users to create v1 integrations with minimal code, while also being flexible for developers to build complex integrations directly in python. It offers a low-code web UI, a dedicated Python environment for each workflow, and generative AI features. Finic decouples integration from product code, supports custom connectors, and is open source. It is not an ETL tool but focuses on integrating functionality between applications via APIs or SFTP, and it is not a workflow automation tool optimized for complex use cases.
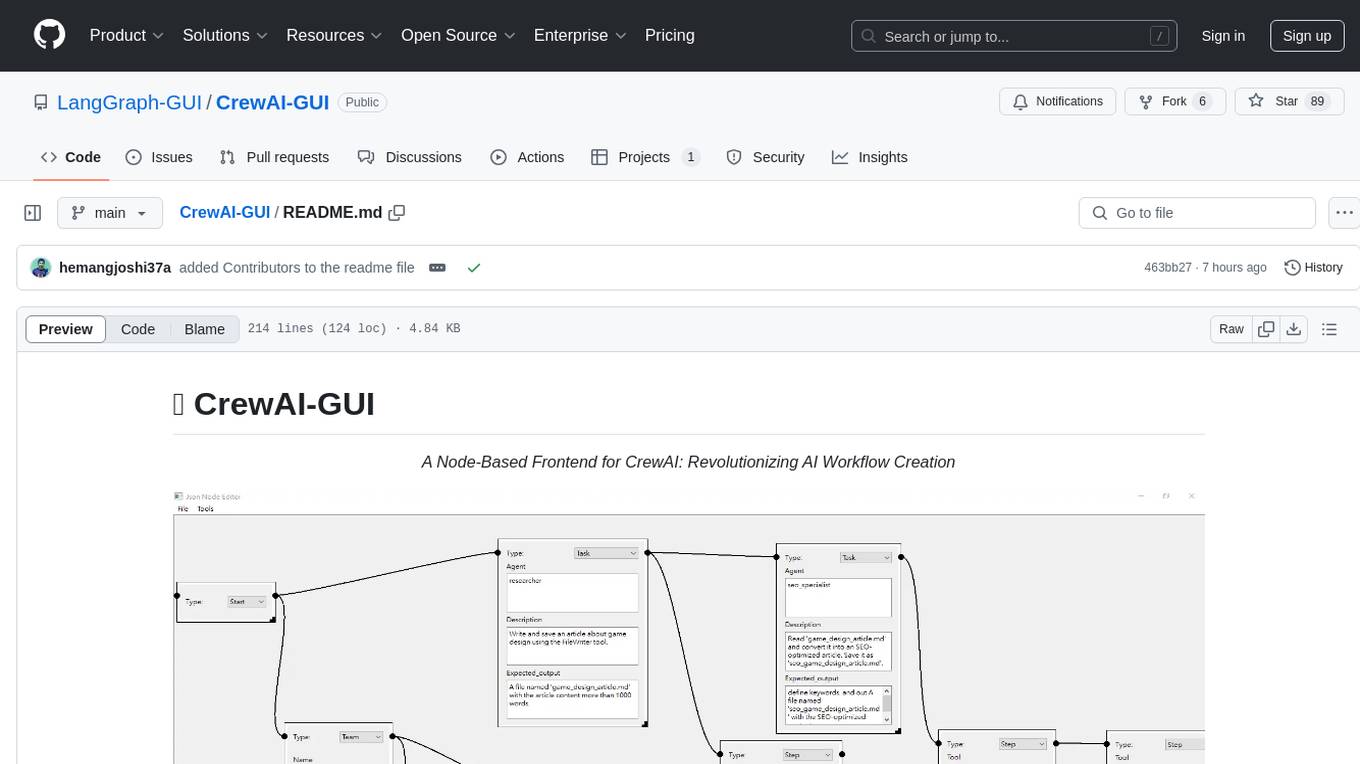
CrewAI-GUI
CrewAI-GUI is a Node-Based Frontend tool designed to revolutionize AI workflow creation. It empowers users to design complex AI agent interactions through an intuitive drag-and-drop interface, export designs to JSON for modularity and reusability, and supports both GPT-4 API and Ollama for flexible AI backend. The tool ensures cross-platform compatibility, allowing users to create AI workflows on Windows, Linux, or macOS efficiently.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.