
nvidia_gpu_exporter
Nvidia GPU exporter for prometheus using nvidia-smi binary
Stars: 1263

Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.
README:
![]()




Nvidia GPU exporter for prometheus, using nvidia-smi binary to gather metrics.
[!WARNING] Maintenance Status: I get that it can be frustrating not to hear back about the stuff you've brought up or the changes you've suggested. But honestly, for over a year now, I've hardly had any time to keep up with my personal open-source projects, including this one. I am still committed to keep this tool working and slowly move it forward, but please bear with me if I can't tackle your fixes or check out your code for a while. Thanks for your understanding.
There are many Nvidia GPU exporters out there however they have problems such as not being maintained, not providing pre-built binaries, having a dependency to Linux and/or Docker, targeting enterprise setups (DCGM) and so on.
This is a simple exporter that uses nvidia-smi(.exe) binary to collect, parse and export metrics.
This makes it possible to run it on Windows and get GPU metrics while gaming - no Docker or Linux required.
This project is based on a0s/nvidia-smi-exporter. However, this one is written in Go to produce a single, static binary.
If you are a gamer who's into monitoring, you are in for a treat.
- Will work on any system that has
nvidia-smi(.exe)?binary - Windows, Linux, MacOS... No C bindings required - Doesn't even need to run the monitored machine: can be configured to execute
nvidia-smicommand remotely - No need for a Docker or Kubernetes environment
- Auto-discovery of the metric fields
nvidia-smican expose (future-compatible) - Comes with its own Grafana dashboard
You can use the official Grafana dashboard to see your GPU metrics in a nicely visualized way.
Here's how it looks like:
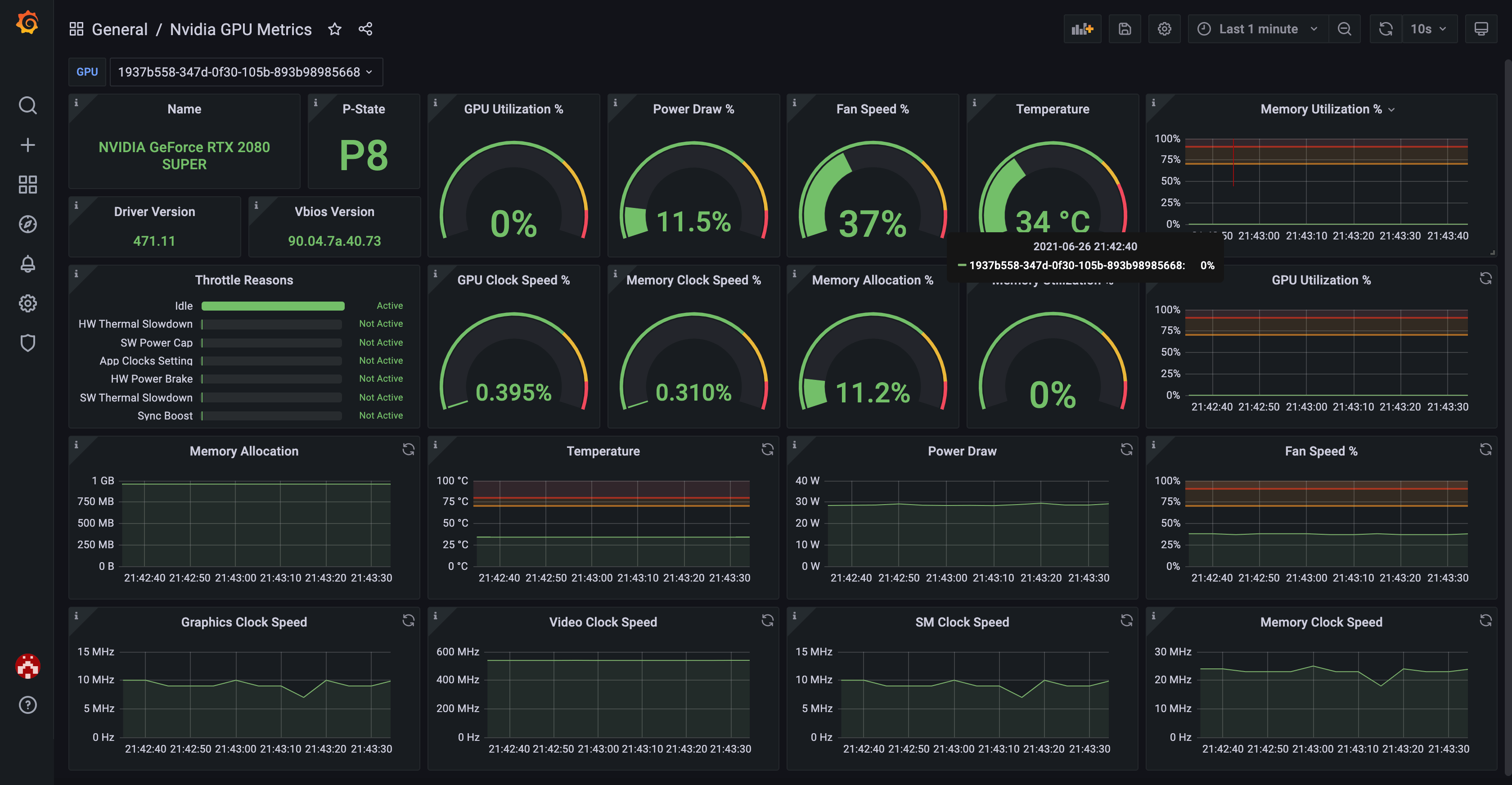
See INSTALL.md for details.
See CONFIGURE.md for details.
See METRICS.md for details.
See CONTRIBUTING.md for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for nvidia_gpu_exporter
Similar Open Source Tools
nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

opencode
Opencode is an AI coding agent designed for the terminal. It is a tool that allows users to interact with AI models for coding tasks in a terminal-based environment. Opencode is open source, provider-agnostic, and focuses on a terminal user interface (TUI) for coding. It offers features such as client/server architecture, support for various AI models, and a strong emphasis on community contributions and feedback.
agentkit
AgentKit is a framework developed by Coinbase Developer Platform for enabling AI agents to take actions onchain. It is designed to be framework-agnostic and wallet-agnostic, allowing users to integrate it with any AI framework and any wallet. The tool is actively being developed and encourages community contributions. AgentKit provides support for various protocols, frameworks, wallets, and networks, making it versatile for blockchain transactions and API integrations using natural language inputs.

haystack
Haystack is an end-to-end LLM framework that allows you to build applications powered by LLMs, Transformer models, vector search and more. Whether you want to perform retrieval-augmented generation (RAG), document search, question answering or answer generation, Haystack can orchestrate state-of-the-art embedding models and LLMs into pipelines to build end-to-end NLP applications and solve your use case.
gptlint
GPTLint is a tool that utilizes Large Language Models (LLMs) to enforce higher-level best practices across a codebase. It offers features such as enforcing rules that are impossible with AST-based approaches, simple markdown format for rules, easy customization of rules, support for custom project-specific rules, content-based caching, and outputting LLM stats per run. GPTLint supports all major LLM providers and local models, augments ESLint instead of replacing it, and includes guidelines for creating custom rules. However, the MVP rules are currently limited to JS/TS only, single-file context only, and do not support autofixing.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].
hal-9100
This repository is now archived and the code is privately maintained. If you are interested in this infrastructure, please contact the maintainer directly.

letsql
LETSQL is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It is currently in development and does not have a stable release. Users can install LETSQL from PyPI and use it to connect to data sources, read data, filter, group, and aggregate data for analysis. Contributions to the project are welcome, and the library is actively maintained with support available for any issues. LETSQL heavily relies on Ibis and DataFusion for its functionality.
ComfyUI_VLM_nodes
ComfyUI_VLM_nodes is a repository containing various nodes for utilizing Vision Language Models (VLMs) and Language Models (LLMs). The repository provides nodes for tasks such as structured output generation, image to music conversion, LLM prompt generation, automatic prompt generation, and more. Users can integrate different models like InternLM-XComposer2-VL, UForm-Gen2, Kosmos-2, moondream1, moondream2, JoyTag, and Chat Musician. The nodes support features like extracting keywords, generating prompts, suggesting prompts, and obtaining structured outputs. The repository includes examples and instructions for using the nodes effectively.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.

kalavai-client
Kalavai is an open-source platform that transforms everyday devices into an AI supercomputer by aggregating resources from multiple machines. It facilitates matchmaking of resources for large AI projects, making AI hardware accessible and affordable. Users can create local and public pools, connect with the community's resources, and share computing power. The platform aims to be a management layer for research groups and organizations, enabling users to unlock the power of existing hardware without needing a devops team. Kalavai CLI tool helps manage both versions of the platform.
anyquery
Anyquery is a SQL query engine built on SQLite that allows users to run SQL queries on various data sources like files, databases, and apps. It can connect to LLMs to access data and act as a MySQL server for running queries. The tool is extensible through plugins and supports various installation methods like Homebrew, APT, YUM/DNF, Scoop, Winget, and Chocolatey.
langflow
Langflow is an open-source Python-powered visual framework designed for building multi-agent and RAG applications. It is fully customizable, language model agnostic, and vector store agnostic. Users can easily create flows by dragging components onto the canvas, connect them, and export the flow as a JSON file. Langflow also provides a command-line interface (CLI) for easy management and configuration, allowing users to customize the behavior of Langflow for development or specialized deployment scenarios. The tool can be deployed on various platforms such as Google Cloud Platform, Railway, and Render. Contributors are welcome to enhance the project on GitHub by following the contributing guidelines.
companion-vscode
Quack Companion is a VSCode extension that provides smart linting, code chat, and coding guideline curation for developers. It aims to enhance the coding experience by offering a new tab with features like curating software insights with the team, code chat similar to ChatGPT, smart linting, and upcoming code completion. The extension focuses on creating a smooth contribution experience for developers by turning contribution guidelines into a live pair coding experience, helping developers find starter contribution opportunities, and ensuring alignment between contribution goals and project priorities. Quack collects limited telemetry data to improve its services and products for developers, with options for anonymization and disabling telemetry available to users.
thread
Thread is an AI-powered Jupyter alternative that integrates an AI copilot into your editing experience. It offers a familiar Jupyter Notebook editing experience with features like natural language code edits, generating cells to answer questions, context-aware chat sidebar, and automatic error explanations or fixes. The tool aims to enhance code editing and data exploration by providing a more interactive and intuitive experience for users. Thread can be used for free with Ollama or your own API key, and it runs locally for convenience and privacy.
For similar tasks
nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.
langserve_ollama
LangServe Ollama is a tool that allows users to fine-tune Korean language models for local hosting, including RAG. Users can load HuggingFace gguf files, create model chains, and monitor GPU usage. The tool provides a seamless workflow for customizing and deploying language models in a local environment.
ai-performance-engineering
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.