
hal-9100
Edge full-stack LLM platform. Written in Rust
Stars: 353
This repository is now archived and the code is privately maintained. If you are interested in this infrastructure, please contact the maintainer directly.
README:
![]()
🖼️ Infra ✨ Feature? ❤️🩹 Bug? 📞 Help?
- [x] Code Interpreter: Generate and runs Python code in a sandboxed environment autonomously. (beta)
- [x] Knowledge Retrieval: Retrieves external knowledge or documents autonomously.
- [x] Function Calling: Defines and executes custom functions autonomously.
- [x] Actions: Execute requests to external APIs autonomously.
- [x] Files: Supports a range of file formats.
- [x] OpenAI compatible: Works with OpenAI (Assistants) SDK
- You want to increase customization (e.g. use your own models, extend the API, etc.)
- You work in a data-sensitive environment (healthcare, IoT, military, law, etc.)
- Your product does have poor or no internet access (military, IoT, edge, extreme environment, etc.)
- (not our main focus) You operate on a large scale and want to reduce your costs
- (not our main focus) You operate on a large scale and want to increase your speed
First, our definition of Software 3.0, as it is a loaded term: Software 3.0 is the bridge connecting the cognitive capabilities of Large Language Models with the practical needs of human digital activity. It is a comprehensive approach that allows LLMs to:
- perform the same activity (or better) on the digital world than humans
- generally, allow the user to perform more operations without conscious effort
HAL-9100 is in continuous development, with the aim of always offering better infrastructure for Edge Software 3.0. To achieve this, it is based on several principles that define its functionality and scope.
Less prompt is more
As few prompts as possible should be hard-coded into the infrastructure, just enough to bridge the gap between Software 1.0 and Software 3.0 and give the client as much control as possible on the prompts.
Edge-first
HAL-9100 does not require internet access by focusing on open source LLMs. Which means you own your data and your models. It runs on a Raspberry PI (LLM included).
OpenAI-compatible
OpenAI spent a large amount of the best brain power to design this API, which makes it an incredible experience for developers. Support for OpenAI LLMs are not a priority at all though.
Reliable and deterministic
HAL-9100 focus on reliability and being as deterministic as possible by default. That's why everything has to be tested and benchmarked.
Flexible
A minimal number of hard-coded prompts and behaviors, a wide range of models, infrastructure components and deployment options and it play well with the open-source ecosystem, while only integrating projects that have stood the test of time.
Get started in less than a minute through GitHub Codespaces:
![]()
Or:
git clone https://github.com/llm-edge/hal-9100
cd hal-9100To get started quickly, let's use Anyscale API.
Get an API key from Anyscale. You can get it here. Replace in hal-9100.toml the model_api_key with your API key.
Usage w/ ollama
- use
model_url = "http://localhost:11434/v1/chat/completions" - set
gemma:2bin examples/quickstart.js - and run
ollama run gemma:2b & && docker compose --profile api -f docker/docker-compose.yml up
Install OpenAI SDK: npm i openai
Start the infra:
docker compose --profile api -f docker/docker-compose.yml upRun the quickstart:
node examples/quickstart.jsIs there a hosted version?
No. HAL-9100 is not a hosted service. It's a software that you can deploy on your infrastructure. We can help you deploy it on your infrastructure. Contact us.
Which LLM API can I use?
Examples of LLM APIs that does support OpenAI API-like, that you can use:
- ollama
- MLC-LLM
- FastChat (good if you have a mac)
- vLLM (good if you have a modern gpu)
- Perplexity API
- Mistral API
- anyscale
- together ai
We recommend these models:
- mistralai/Mixtral-8x7B-Instruct-v0.1
- mistralai/mistral-7b
Other models have not been extensively tested and may not work as expected, but you can try them.
What's the difference with LangChain?
1. LangChain spans proprietary LLM and open source, among the thousands of things it spans. HAL-9100 laser focuses on Software 3.0 for the edge.- You can write AI products in 50 lines of code instead of 5000 and having to learn a whole new abstraction
Are you related to OpenAI?
No.I don't use Assistants API. Can I use this?
We recommend switching to the Assistants API for a more streamlined experience, allowing you to focus more on your product than on infrastructure.Does the Assistants API support audio and images?
Images soon, working on it.For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hal-9100
Similar Open Source Tools
hal-9100
This repository is now archived and the code is privately maintained. If you are interested in this infrastructure, please contact the maintainer directly.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.

doku
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just a single line of code. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.

neo
Neo.mjs is a revolutionary Application Engine for the web that offers true multithreading and context engineering, enabling desktop-class UI performance and AI-driven runtime mutation. It is not a framework but a complete runtime and toolchain for enterprise applications, excelling in single page apps and browser-based multi-window applications. With a pioneering Off-Main-Thread architecture, Neo.mjs ensures butter-smooth UI performance by keeping the main thread free for flawless user interactions. The latest version, v11, introduces AI-native capabilities, allowing developers to work with AI agents as first-class partners in the development process. The platform offers a suite of dedicated Model Context Protocol servers that give agents the context they need to understand, build, and reason about the code, enabling a new level of human-AI collaboration.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.
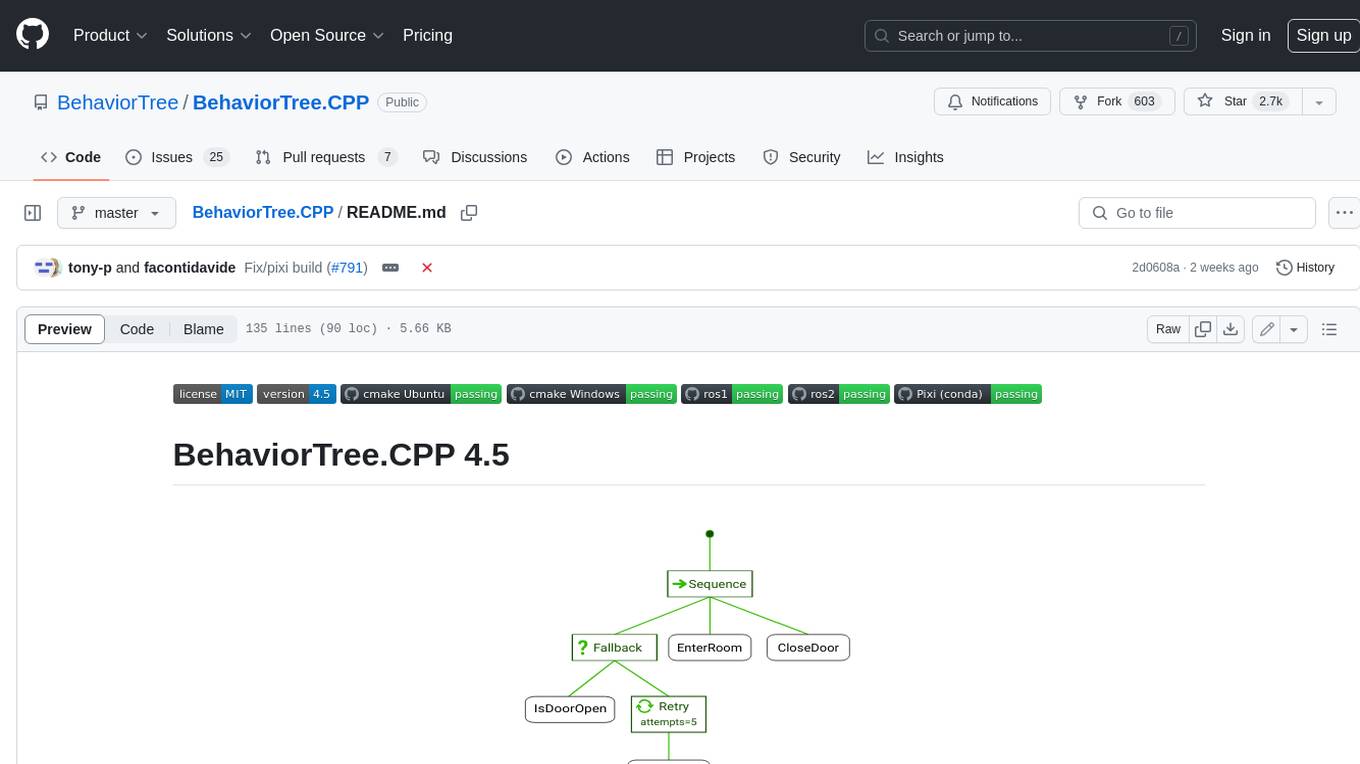
BehaviorTree.CPP
BehaviorTree.CPP is a C++ 17 library that provides a framework to create BehaviorTrees. It was designed to be flexible, easy to use, reactive and fast. Even if our main use-case is robotics, you can use this library to build AI for games, or to replace Finite State Machines. There are few features which make BehaviorTree.CPP unique, when compared to other implementations: It makes asynchronous Actions, i.e. non-blocking, a first-class citizen. You can build reactive behaviors that execute multiple Actions concurrently (orthogonality). Trees are defined using a Domain Specific scripting language (based on XML), and can be loaded at run-time; in other words, even if written in C++, the morphology of the Trees is not hard-coded. You can statically link your custom TreeNodes or convert them into plugins and load them at run-time. It provides a type-safe and flexible mechanism to do Dataflow between Nodes of the Tree. It includes a logging/profiling infrastructure that allows the user to visualize, record, replay and analyze state transitions.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

draive
draive is an open-source Python library designed to simplify and accelerate the development of LLM-based applications. It offers abstract building blocks for connecting functionalities with large language models, flexible integration with various AI solutions, and a user-friendly framework for building scalable data processing pipelines. The library follows a function-oriented design, allowing users to represent complex programs as simple functions. It also provides tools for measuring and debugging functionalities, ensuring type safety and efficient asynchronous operations for modern Python apps.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.
AppFlowy
AppFlowy.IO is an open-source alternative to Notion, providing users with control over their data and customizations. It aims to offer functionality, data security, and cross-platform native experience to individuals, as well as building blocks and collaboration infra services to enterprises and hackers. The tool is built with Flutter and Rust, supporting multiple platforms and emphasizing long-term maintainability. AppFlowy prioritizes data privacy, reliable native experience, and community-driven extensibility, aiming to democratize the creation of complex workplace management tools.

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

kairon
Kairon is an open-source conversational digital transformation platform that helps build LLM-based digital assistants at scale. It provides a no-coding web interface for adapting, training, testing, and maintaining AI assistants. Kairon focuses on pre-processing data for chatbots, including question augmentation, knowledge graph generation, and post-processing metrics. It offers end-to-end lifecycle management, low-code/no-code interface, secure script injection, telemetry monitoring, chat client designer, analytics module, and real-time struggle analytics. Kairon is suitable for teams and individuals looking for an easy interface to create, train, test, and deploy digital assistants.