
ai-performance-engineering
None
Stars: 135
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.
README:
This repository contains comprehensive code examples, tools, and resources for AI Systems Performance Engineering. It accompanies the O'Reilly book covering GPU optimization, distributed training, inference scaling, and performance tuning for modern AI workloads.

O'Reilly Book - Fall 2025
Available on Amazon
The book includes a comprehensive 175+ item performance checklist covering:
- ✅ Performance Tuning Mindset and Cost Optimization
- ✅ Reproducibility and Documentation Best Practices
- ✅ System Architecture and Hardware Planning
- ✅ Operating System and Driver Optimizations
- ✅ GPU Programming and CUDA Tuning
- ✅ Distributed Training and Network Optimization
- ✅ Efficient Inference and Serving
- ✅ Power and Thermal Management
- ✅ Latest Profiling Tools and Techniques
- ✅ Architecture-Specific Optimizations
- Book: AI Systems Performance Engineering on Amazon
- Meetup: AI Performance Engineering Meetup Group
- YouTube: AI Performance Engineering Channel
Built in San Francisco for the AI performance engineering community
- GPU Architecture, PyTorch, CUDA, and Open AI Triton Programming
- Distributed Training & Inference
- Memory Optimization & Profiling
- PyTorch Performance Tuning
- Multi-Node Scaling Strategies
- NVIDIA GPU with CUDA support
- Python 3.8+
- PyTorch with CUDA
- Docker (optional)
# Clone the repository
git clone https://github.com/your-repo/ai-performance-engineering.git
cd ai-performance-engineering
# Install dependencies for a specific chapter
cd code/ch1
pip install -r requirements.txt
# Run examples
python performance_basics.py
# Profiling-friendly workloads
Most examples use modest tensor sizes and short iteration counts so Nsight and the PyTorch profiler finish in seconds. Comments inside each script highlight these adjustments; increase the sizes if you need larger-scale numbers.This repository now targets a single architecture profile: NVIDIA Blackwell B200/B300 (SM100). All tooling, CUDA builds, and PyTorch examples assume CUDA 12.9, PyTorch 2.9 nightlies, and Triton 3.4. Use the helper scripts to stay aligned with that stack:
# Build CUDA samples and run sanity checks
./code/build_all.sh
# Profile the entire codebase with Nsight + PyTorch profiler
python code/profiler_scripts/profile_harness.py --profile nsys --profile pytorch --output-root profiles/full_run
# Reset all generated profiling artefacts
./clean_profiles.shFor hardware details and optimisation notes, see code/README.md.
Updated for PyTorch 2.9, CUDA 12.9, and Triton 3.4:
- PyTorch 2.9: Enhanced compiler, dynamic shapes, improved profiler
- CUDA 12.9: Latest CUDA features, improved kernel performance
- Triton 3.4: Latest Triton optimizations, architecture-specific kernels
- Enhanced Profiling: Nsight Systems 2024.1, Nsight Compute 2024.1
- HTA: Holistic Tracing Analysis for multi-GPU systems
- Perf: Enhanced system-level analysis
- Architecture Optimizations: Blackwell-specific features
- Unified Profiling Harness: One command walks through every chapter with Nsight Systems/Compute + PyTorch profiler
- The AI Systems Performance Engineer
- Benchmarking and Profiling
- Scaling Distributed Training and Inference
- Managing Resources Efficiently
- Cross-Team Collaboration
- Transparency and Reproducibility
- The CPU and GPU "Superchip"
- NVIDIA Grace CPU & Blackwell GPU
- NVIDIA GPU Tensor Cores and Transformer Engine
- Streaming Multiprocessors, Threads, and Warps
- Ultra-Scale Networking
- NVLink and NVSwitch
- Multi-GPU Programming
- Operating System Configuration
- GPU Driver and Software Stack
- NUMA Awareness and CPU Pinning
- Container Runtime Optimizations
- Kubernetes for Topology-Aware Orchestration
- Memory Isolation and Resource Management
- Overlapping Communication and Computation
- NCCL for Distributed Multi-GPU Communication
- Topology Awareness in NCCL
- Distributed Data Parallel Strategies
- NVIDIA Inference Transfer Library (NIXL)
- In-Network SHARP Aggregation
- Fast Storage and Data Locality
- NVIDIA GPUDirect Storage
- Distributed, Parallel File Systems
- Multi-Modal Data Processing with NVIDIA DALI
- Creating High-Quality LLM Datasets
- Understanding GPU Architecture
- Threads, Warps, Blocks, and Grids
- CUDA Programming Refresher
- Understanding GPU Memory Hierarchy
- Maintaining High Occupancy and GPU Utilization
- Roofline Model Analysis
- Coalesced vs. Uncoalesced Global Memory Access
- Vectorized Memory Access
- Tiling and Data Reuse Using Shared Memory
- Warp Shuffle Intrinsics
- Asynchronous Memory Prefetching
- Profiling and Diagnosing GPU Bottlenecks
- Nsight Systems and Compute Analysis
- Tuning Occupancy
- Improving Warp Execution Efficiency
- Exposing Instruction-Level Parallelism
- Multi-Level Micro-Tiling
- Kernel Fusion
- Mixed Precision and Tensor Cores
- Using CUTLASS for Optimal Performance
- Inline PTX and SASS Tuning
- Intra-Kernel Pipelining Techniques
- Warp-Specialized Producer-Consumer Model
- Persistent Kernels and Megakernels
- Thread Block Clusters and Distributed Shared Memory
- Cooperative Groups
- Using Streams to Overlap Compute with Data Transfers
- Stream-Ordered Memory Allocator
- Fine-Grained Synchronization with Events
- Zero-Overhead Launch with CUDA Graphs
- Dynamic Scheduling with Atomic Work Queues
- Batch Repeated Kernel Launches with CUDA Graphs
- Dynamic Parallelism
- Orchestrate Across Multiple GPUs with NVSHMEM
- NVTX Markers and Profiling Tools
- PyTorch Compiler (torch.compile)
- Profiling and Tuning Memory in PyTorch
- Scaling with PyTorch Distributed
- Multi-GPU Profiling with HTA
- PyTorch Compiler Deep Dive
- Writing Custom Kernels with OpenAI Triton
- PyTorch XLA Backend
- Advanced Triton Kernel Implementations
- Disaggregated Prefill and Decode Architecture
- Parallelism Strategies for MoE Models
- Speculative and Parallel Decoding Techniques
- Dynamic Routing Strategies
- Workflow for Profiling and Tuning Performance
- Dynamic Request Batching and Scheduling
- Systems-Level Optimizations
- Quantization Approaches for Real-Time Inference
- Application-Level Optimizations
- Prefill-Decode Disaggregation Benefits
- Prefill Workers Design
- Decode Workers Design
- Disaggregated Routing and Scheduling Policies
- Scalability Considerations
- Optimized Decode Kernels (FlashMLA, ThunderMLA, FlexDecoding)
- Tuning KV Cache Utilization and Management
- Heterogeneous Hardware and Parallelism Strategies
- SLO-Aware Request Management
- Adaptive Parallelism Strategies
- Dynamic Precision Changes
- Kernel Auto-Tuning
- Reinforcement Learning Agents for Runtime Tuning
- Adaptive Batching and Scheduling
- AlphaTensor AI-Discovered Algorithms
- Automated GPU Kernel Optimizations
- Self-Improving AI Agents
- Scaling Toward Multi-Million GPU Clusters
-
code/profiler_scripts/profile_harness.py- Unified Nsight Systems / Nsight Compute / PyTorch profiler runner -
code/profiler_scripts/enhanced_profiling.sh- Convenience wrapper for individual scripts -
code/profiler_scripts/hta_profile.sh- Holistic Tracing Analysis
-
tools/comprehensive_profiling.py- Python-based profiling utilities -
tools/compare_nsight/- Nsight Systems comparison tools -
tools/inference_gpu_cluster_sizing/- Cluster sizing notebooks
# Comprehensive profiling
nsys profile -t cuda,nvtx,osrt,triton -o timeline_profile python script.py
# Kernel analysis
ncu --metrics achieved_occupancy,warp_execution_efficiency -o kernel_profile python script.py
# HTA for multi-GPU
nsys profile -t cuda,nvtx,osrt,cudnn,cublas,nccl,triton -o hta_profile python script.py
# System analysis
perf record -g -p $(pgrep python) -o perf.data
perf report -i perf.data- Meetup Group: AI Performance Engineering
- YouTube Channel: AI Performance Engineering
- YouTube Video
- PyTorch Optimizations: Data Loader Pipeline
- Cross-Architecture CUDA and ROCm Kernel Development
We welcome contributions! Please see our Contributing Guide for:
- Code examples and improvements
- Documentation updates
- Performance optimization techniques
- Bug reports and feature requests
This project is licensed under the MIT License - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-performance-engineering
Similar Open Source Tools
ai-performance-engineering
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.
lyraios
LYRAIOS (LLM-based Your Reliable AI Operating System) is an advanced AI assistant platform built with FastAPI and Streamlit, designed to serve as an operating system for AI applications. It offers core features such as AI process management, memory system, and I/O system. The platform includes built-in tools like Calculator, Web Search, Financial Analysis, File Management, and Research Tools. It also provides specialized assistant teams for Python and research tasks. LYRAIOS is built on a technical architecture comprising FastAPI backend, Streamlit frontend, Vector Database, PostgreSQL storage, and Docker support. It offers features like knowledge management, process control, and security & access control. The roadmap includes enhancements in core platform, AI process management, memory system, tools & integrations, security & access control, open protocol architecture, multi-agent collaboration, and cross-platform support.
SynthLang
SynthLang is a tool designed to optimize AI prompts by reducing costs and improving processing speed. It brings academic rigor to prompt engineering, creating precise and powerful AI interactions. The tool includes core components like a Translator Engine, Performance Optimization, Testing Framework, and Technical Architecture. It offers mathematical precision, academic rigor, enhanced security, a modern interface, and instant testing. Users can integrate mathematical frameworks, model complex relationships, and apply structured prompts to various domains. Security features include API key management and data privacy. The tool also provides a CLI for prompt engineering and optimization capabilities.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
claude-007-agents
Claude Code Agents is an open-source AI agent system designed to enhance development workflows by providing specialized AI agents for orchestration, resilience engineering, and organizational memory. These agents offer specialized expertise across technologies, AI system with organizational memory, and an agent orchestration system. The system includes features such as engineering excellence by design, advanced orchestration system, Task Master integration, live MCP integrations, professional-grade workflows, and organizational intelligence. It is suitable for solo developers, small teams, enterprise teams, and open-source projects. The system requires a one-time bootstrap setup for each project to analyze the tech stack, select optimal agents, create configuration files, set up Task Master integration, and validate system readiness.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
Zettelgarden
Zettelgarden is a human-centric, open-source personal knowledge management system that helps users develop and maintain their understanding of the world. It focuses on creating and connecting atomic notes, thoughtful AI integration, and scalability from personal notes to company knowledge bases. The project is actively evolving, with features subject to change based on community feedback and development priorities.
evi-run
evi-run is a powerful, production-ready multi-agent AI system built on Python using the OpenAI Agents SDK. It offers instant deployment, ultimate flexibility, built-in analytics, Telegram integration, and scalable architecture. The system features memory management, knowledge integration, task scheduling, multi-agent orchestration, custom agent creation, deep research, web intelligence, document processing, image generation, DEX analytics, and Solana token swap. It supports flexible usage modes like private, free, and pay mode, with upcoming features including NSFW mode, task scheduler, and automatic limit orders. The technology stack includes Python 3.11, OpenAI Agents SDK, Telegram Bot API, PostgreSQL, Redis, and Docker & Docker Compose for deployment.
bifrost
Bifrost is a high-performance AI gateway that unifies access to multiple providers through a single OpenAI-compatible API. It offers features like automatic failover, load balancing, semantic caching, and enterprise-grade functionalities. Users can deploy Bifrost in seconds with zero configuration, benefiting from its core infrastructure, advanced features, enterprise and security capabilities, and developer experience. The repository structure is modular, allowing for maximum flexibility. Bifrost is designed for quick setup, easy configuration, and seamless integration with various AI models and tools.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
llxprt-code
LLxprt Code is an AI-powered coding assistant that works with any LLM provider, offering a command-line interface for querying and editing codebases, generating applications, and automating development workflows. It supports various subscriptions, provider flexibility, top open models, local model support, and a privacy-first approach. Users can interact with LLxprt Code in both interactive and non-interactive modes, leveraging features like subscription OAuth, multi-account failover, load balancer profiles, and extensive provider support. The tool also allows for the creation of advanced subagents for specialized tasks and integrates with the Zed editor for in-editor chat and code selection.
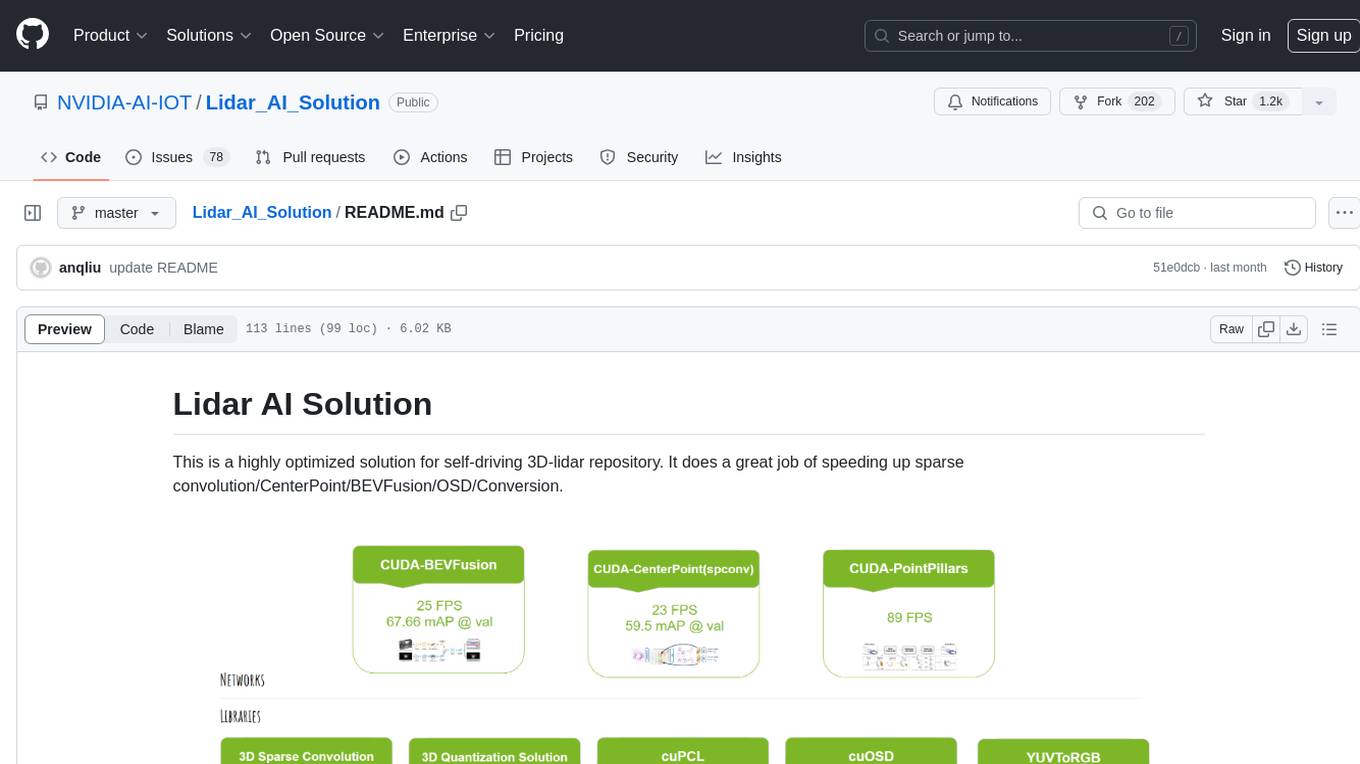
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.
For similar tasks
ai-performance-engineering
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.