
comfyui_LLM_party
LLM Agent Framework in ComfyUI includes MCP sever, Omost,GPT-sovits, ChatTTS,GOT-OCR2.0, and FLUX prompt nodes,access to Feishu,discord,and adapts to all llms with similar openai / aisuite interfaces, such as o1,ollama, gemini, grok, qwen, GLM, deepseek, kimi,doubao. Adapted to local llms, vlm, gguf such as llama-3.3 Janus-Pro, Linkage graphRAG
Stars: 1551
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.
README:

Comfyui_llm_party aims to develop a complete set of nodes for LLM workflow construction based on comfyui as the front end. It allows users to quickly and conveniently build their own LLM workflows and easily integrate them into their existing image workflows.
https://github.com/user-attachments/assets/945493c0-92b3-4244-ba8f-0c4b2ad4eba6
ComfyUI LLM Party, from the most basic LLM multi-tool call, role setting to quickly build your own exclusive AI assistant, to the industry-specific word vector RAG and GraphRAG to localize the management of the industry knowledge base; from a single agent pipeline, to the construction of complex agent-agent radial interaction mode and ring interaction mode; from the access to their own social APP (QQ, Feishu, Discord) required by individual users, to the one-stop LLM + TTS + ComfyUI workflow required by streaming media workers; from the simple start of the first LLM application required by ordinary students, to the various parameter debugging interfaces commonly used by scientific researchers, model adaptation. All of this, you can find the answer in ComfyUI LLM Party.
- If you have never used ComfyUI and encounter some dependency issues while installing the LLM party in ComfyUI, please click here to download the Windows portable package that includes the LLM party. Please note that this portable package contains only the party and manager plugins, and is exclusively compatible with the Windows operating system.(If you need to install LLM party into an existing comfyui, this step can be skipped.)
- Drag the following workflows into your comfyui, then use comfyui-Manager to install the missing nodes.
- Use API to call LLM: start_with_LLM_api
- Using aisuite to call LLM: start_with_aisuite
- Manage local LLM with ollama: start_with_Ollama
- Use local LLM in distributed format: start_with_LLM_local
- Use local LLM in GGUF format: start_with_LLM_GGUF
- Use local VLM in distributed format: start_with_VLM_local (Currently, support is extended for Llama-3.2-Vision/Qwen/Qwen2.5-VL/deepseek-ai/Janus-Pro.)
- Use local VLM in GGUF format: start_with_VLM_GGUF
- Utilize API calls to LLM for generating SD prompts and images: start_with_VLM_API_for_SD
- Employ ollama to call minicpm for generating SD prompts and images: start_with_ollama_minicpm_for_SD
- Utilize the local qwen-vl to generate SD prompts and images: start_with_qwen_vl_local_for_SD
- If you are using API, fill in your
base_url(it can be a relay API, make sure it ends with/v1/), for example:https://api.openai.com/v1/andapi_keyin the API LLM loader node. - If you are using ollama, turn on the
is_ollamaoption in the API LLM loader node, no need to fill inbase_urlandapi_key. - If you are using a local model, fill in your model path in the local model loader node, for example:
E:\model\Llama-3.2-1B-Instruct. You can also fill in the Huggingface model repo id in the local model loader node, for example:lllyasviel/omost-llama-3-8b-4bits. - Due to the high usage threshold of this project, even if you choose the quick start, I hope you can patiently read through the project homepage.
- The LLM API node has now implemented a streaming output mode, which will display the text returned by the API in real-time on the console, allowing you to see the API's output live without waiting for the entire request to complete.
- The LLM API node has added a reasoning_content output, which can automatically separate the reasoning and response of the R1 model.
- A new branch named only_api has been added to the repository, containing only the API calling components. This is designed for users who require only API invocation. To use this branch, simply execute the command
git clone -b only_api https://github.com/heshengtao/comfyui_LLM_party.gitin thecustom toolfolder ofcomfyui, and then follow the environment deployment instructions provided on the project's main page. Please note! It is essential to ensure that there are no other folders namedcomfyui_LLM_partywithin thecustom toolfolder. - The VLM local loader node now supports deepseek-ai/Janus-Pro, with an example workflow: Janus-Pro.
- The VLM local loader node has already supported Qwen/Qwen2.5-VL-3B-Instruct, but you need to update the transformer to the latest version (
pip install -U transformers), example workflow: qwen-vl - A brand new image hosting node has been added, currently supporting the image hosting services at https://sm.ms (with the regional domain for China being https://smms.app) and https://imgbb.com. More image hosting services will be supported in the future. Sample workflow: Image Hosting
-
The imgbb image hosting service, which is compatible by default with the party, has been updated to the domain imgbb. The previous image hosting service was replaced due to its unfriendliness towards users in mainland China.I sincerely apologize, as it seems that the API service for the image hosting at https://imgbb.io has been discontinued. Therefore, the code has reverted to the original https://imgbb.com. Thank you for your understanding. In the future, I will update a node that supports more image hosting services. - The MCP tool has been updated. You can modify the configuration in the 'mcp_config.json' file located in the party project folder to connect to your desired MCP server. You can find various MCP server configuration parameters that you may want to add here: modelcontextprotocol/servers. The default configuration for this project is the Everything server, which serves as a testing MCP server to verify its functionality. Reference workflow: start_with_MCP. Developer note: The MCP tool node can connect to the MCP server you have configured and convert the tools from the server into tools that can be directly used by LLMs. By configuring different local or cloud servers, you can experience all LLM tools available in the world.
-
For the instructions for using the node, please refer to: how to use nodes
-
If there are any issues with the plugin or you have other questions, feel free to join the QQ group: 931057213 | discord:discord.
-
More workflows please refer to the workflow folder.


- Support all API calls in openai format(Combined with oneapi can call almost all LLM APIs, also supports all transit APIs), base_url selection reference config.ini.example, which has been tested so far:
- openai (Perfectly compatible with all OpenAI models, including the 4o and o1 series!)
- ollama (Recommended! If you are calling locally, it is highly recommended to use the ollama method to host your local model!)
- Azure OpenAI
- llama.cpp (Recommended! If you want to use the local gguf format model, you can use the llama.cpp project's API to access this project!)
- Grok
- Tongyi Qianwen /qwen
- zhipu qingyan/glm
- deepseek
- kimi/moonshot
- doubao
- spark
- Gemini(The original Gemini API LLM loader node has been deprecated in the new version. Please use the LLM API loader node, with the base_url selected as: https://generativelanguage.googleapis.com/v1beta/)
- Support for all API calls compatible with aisuite:
- Compatible with most local models in the transformer library (the model type on the local LLM model chain node has been changed to LLM, VLM-GGUF, and LLM-GGUF, corresponding to directly loading LLM models, loading VLM models, and loading GGUF format LLM models). If your VLM or GGUF format LLM model reports an error, please download the latest version of llama-cpp-python from llama-cpp-python. Currently tested models include:
- ClosedCharacter/Peach-9B-8k-Roleplay(Recommended! Role-playing model)
- lllyasviel/omost-llama-3-8b-4bits(Recommended! Rich prompt model)
- meta-llama/llama-2-7b-chat-hf
- Qwen/Qwen2-7B-Instruct
- openbmb/MiniCPM-V-2_6-gguf
- lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF
- meta-llama/Llama-3.2-11B-Vision-Instruct
- Qwen/Qwen2.5-VL-3B-Instruct
- deepseek-ai/Janus-Pro
- Model download
- Quark cloud address
- Baidu cloud address, extraction code: qyhu
- You can configure the language in
config.ini, currently only Chinese (zh_CN) and English (en_US), the default is your system language. - Install using one of the following methods:
- Search for comfyui_LLM_party in the comfyui manager and install it with one click.
- Restart comfyui.
- Navigate to the
custom_nodessubfolder under the ComfyUI root folder. - Clone this repository with
git clone https://github.com/heshengtao/comfyui_LLM_party.git.
- Click
CODEin the upper right corner. - Click
download zip. - Unzip the downloaded package into the
custom_nodessubfolder under the ComfyUI root folder.
- Navigate to the
comfyui_LLM_partyproject folder. - Enter
pip install -r requirements.txtin the terminal to deploy the third-party libraries required by the project into the comfyui environment. Please ensure you are installing within the comfyui environment and pay attention to anypiperrors in the terminal. - If you are using the comfyui launcher, you need to enter
path_in_launcher_configuration\python_embeded\python.exe -m pip install -r requirements.txtin the terminal to install. Thepython_embededfolder is usually at the same level as yourComfyUIfolder. - If you have some environment configuration problems, you can try to use the dependencies in
requirements_fixed.txt.
- The language can be configured in
config.ini, currently only Chinese (zh_CN) and English (en_US) are available, with the default set to your system language. - In
config.ini, you can configure whether to enable fast installation. Thefast_installedoption defaults toFalse, and if you do not require the usage of the GGUF model, it can be set toTrue. - APIKEY can be configured using one of the following methods
- Open the
config.inifile in the project folder of thecomfyui_LLM_party. - Enter your openai_api_key, base_url in
config.ini. - If you are using an ollama model, fill in
http://127.0.0.1:11434/v1/inbase_url,ollamainopenai_api_key, and your model name inmodel_name, for example:llama3. - If you want to use Google search or Bing search tools, enter your
google_api_key,cse_idorbing_api_keyinconfig.ini. - If you want to use image input LLM, it is recommended to use image bed imgbb and enter your imgbb_api in
config.ini. - Each model can be configured separately in the
config.inifile, which can be filled in by referring to theconfig.ini.examplefile. After you configure it, just entermodel_nameon the node.
- Open the comfyui interface.
- Create a Large Language Model (LLM) node and enter your openai_api_key and base_url directly in the node.
- If you use the ollama model, use LLM_api node, fill in
http://127.0.0.1:11434/v1/inbase_urlnode, fill inollamainapi_key, and fill in your model name inmodel_name, for example:llama3. - If you want to use image input LLM, it is recommended to use graph bed imgbb and enter your
imgbb_api_keyon the node.
- More model adaptations;
- More ways to build agents;
- More automation features;
- More knowledge base management features;
- More tools, more personas.
This open-source project and its contents (hereinafter referred to as "Project") are provided for reference purposes only and do not imply any form of warranty, either expressed or implied. The contributors of the Project shall not be held responsible for the completeness, accuracy, reliability, or suitability of the Project. Any reliance you place on the Project is strictly at your own risk. In no event shall the contributors of the Project be liable for any indirect, special, or consequential damages or any damages whatsoever resulting from the use of the Project.



Some of the nodes in this project have borrowed from the following projects. Thank you for your contributions to the open-source community!
If there is a problem with the plugin or you have any other questions, please join our community.
- discord:discord link
- QQ group:
931057213

- WeChat group:
we_glm(enter the group after adding the small assistant WeChat)
- If you want to continue to pay attention to the latest features of this project, please follow the Bilibili account: 派酱
- youtube@comfyui-LLM-party
If my work has brought value to your day, consider fueling it with a coffee! Your support not only energizes the project but also warms the heart of the creator. ☕💖 Every cup makes a difference!


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for comfyui_LLM_party
Similar Open Source Tools
comfyui_LLM_party
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.
shipstation
ShipStation is an AI-based website and agents generation platform that optimizes landing page websites and generic connect-anything-to-anything services. It enables seamless communication between service providers and integration partners, offering features like user authentication, project management, code editing, payment integration, and real-time progress tracking. The project architecture includes server-side (Node.js) and client-side (React with Vite) components. Prerequisites include Node.js, npm or yarn, Anthropic API key, Supabase account, Tavily API key, and Razorpay account. Setup instructions involve cloning the repository, setting up Supabase, configuring environment variables, and starting the backend and frontend servers. Users can access the application through the browser, sign up or log in, create landing pages or portfolios, and get websites stored in an S3 bucket. Deployment to Heroku involves building the client project, committing changes, and pushing to the main branch. Contributions to the project are encouraged, and the license encourages doing good.
vault-ai
OP Vault is a tool that leverages the OP Stack (OpenAI + Pinecone Vector Database) to allow users to upload custom knowledgebase files and ask questions about their contents. It provides a user-friendly Golang server and React frontend for querying human-readable content like books and documents, making it valuable for knowledge extraction and question-answering. Users can upload entire libraries, receive specific answers with file and section references, and explore the power of the OP Stack in a practical interface.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
llama3-tokenizer-js
JavaScript tokenizer for LLaMA 3 designed for client-side use in the browser and Node, with TypeScript support. It accurately calculates token count, has 0 dependencies, optimized running time, and somewhat optimized bundle size. Compatible with most LLaMA 3 models. Can encode and decode text, but training is not supported. Pollutes global namespace with `llama3Tokenizer` in the browser. Mostly compatible with LLaMA 3 models released by Facebook in April 2024. Can be adapted for incompatible models by passing custom vocab and merge data. Handles special tokens and fine tunes. Developed by belladore.ai with contributions from xenova, blaze2004, imoneoi, and ConProgramming.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.
ersilia
The Ersilia Model Hub is a unified platform of pre-trained AI/ML models dedicated to infectious and neglected disease research. It offers an open-source, low-code solution that provides seamless access to AI/ML models for drug discovery. Models housed in the hub come from two sources: published models from literature (with due third-party acknowledgment) and custom models developed by the Ersilia team or contributors.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.
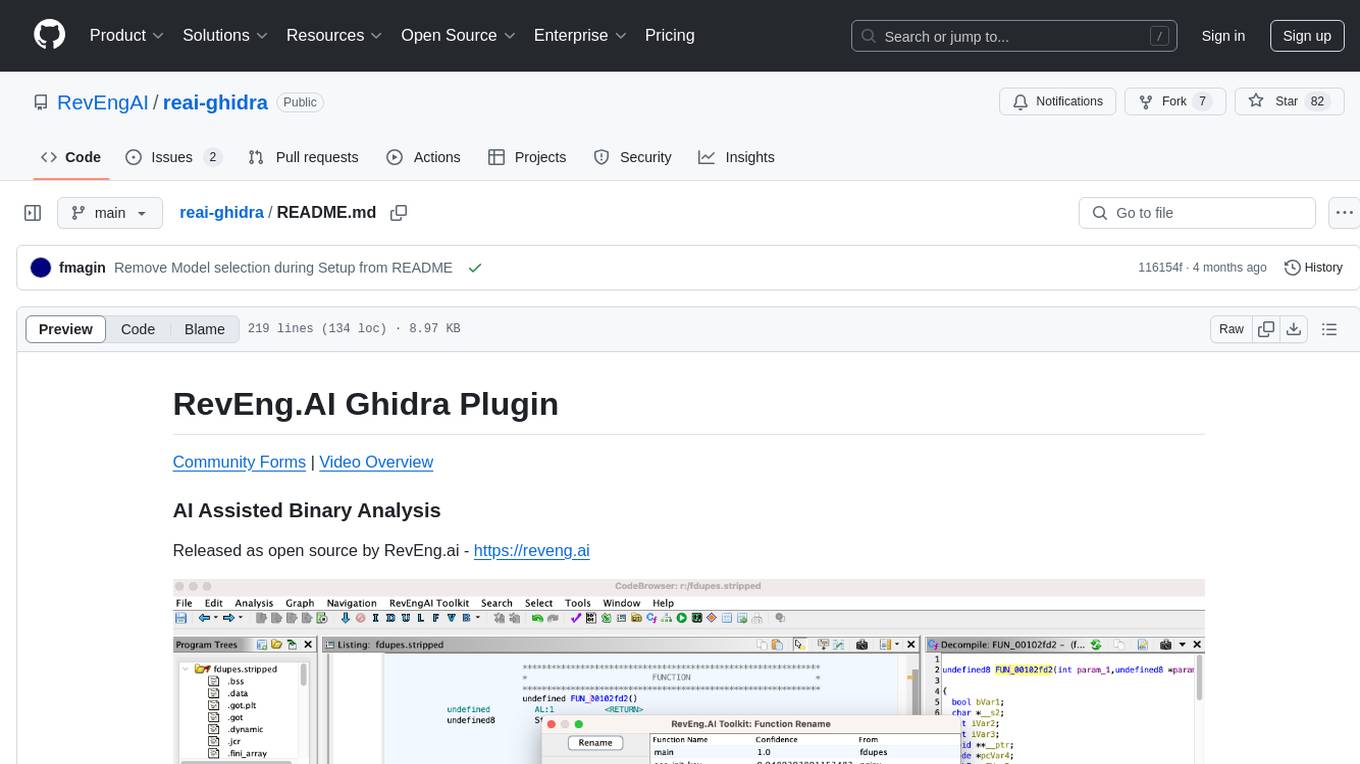
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
For similar tasks
comfyui_LLM_party
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.
n8n
n8n is a workflow automation platform that combines the flexibility of code with the speed of no-code. It offers 400+ integrations, native AI capabilities, and a fair-code license, empowering users to create powerful automations while maintaining control over data and deployments. With features like code customization, AI agent workflows, self-hosting options, enterprise-ready functionalities, and an active community, n8n provides a comprehensive solution for technical teams seeking efficient workflow automation.
wingman
The LLM Platform, also known as Inference Hub, is an open-source tool designed to simplify the development and deployment of large language model applications at scale. It provides a unified framework for integrating and managing multiple LLM vendors, models, and related services through a flexible approach. The platform supports various LLM providers, document processing, RAG, advanced AI workflows, infrastructure operations, and flexible configuration using YAML files. Its modular and extensible architecture allows developers to plug in different providers and services as needed. Key components include completers, embedders, renderers, synthesizers, transcribers, document processors, segmenters, retrievers, summarizers, translators, AI workflows, tools, and infrastructure components. Use cases range from enterprise AI applications to scalable LLM deployment and custom AI pipelines. Integrations with LLM providers like OpenAI, Azure OpenAI, Anthropic, Google Gemini, AWS Bedrock, Groq, Mistral AI, xAI, Hugging Face, and more are supported.
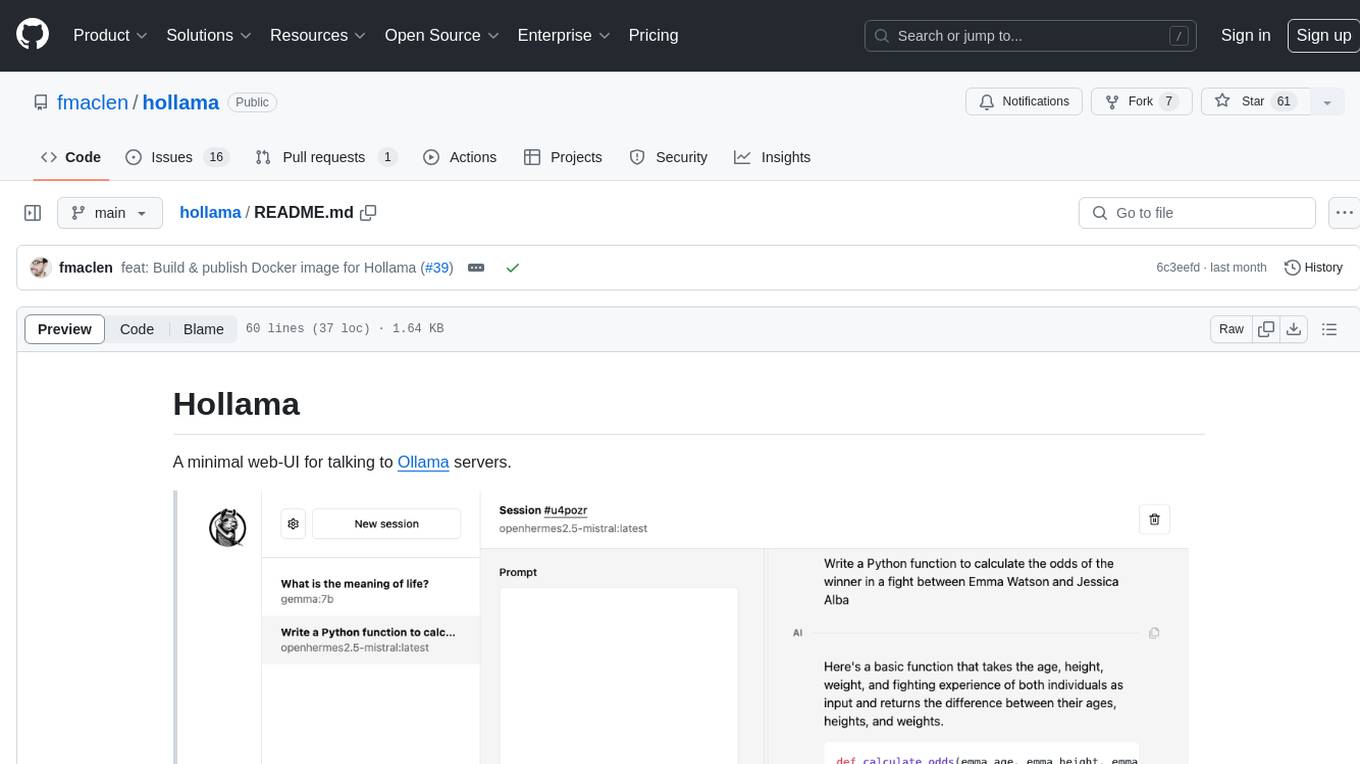
hollama
Hollama is a minimal web-UI tool designed for interacting with Ollama servers. It features large prompt fields, streams completions, ability to copy completions as raw text, Markdown parsing with syntax highlighting, and saves sessions/context in the browser's localStorage. Users can access the latest version of Hollama at https://hollama.fernando.is without sign up, and data is stored locally on the browser. The tool can also be run as a Docker image by executing a specific command. Developers can connect to an Ollama server by updating the ORIGIN settings. Hollama facilitates easy development by providing instructions to set up the environment, install dependencies, and start a development server. Building a production version of the app is straightforward with a single command, and deployment may require installing an adapter for the target environment.

learn-modern-ai-python
This repository is part of the Certified Agentic & Robotic AI Engineer program, covering the first quarter of the course work. It focuses on Modern AI Python Programming, emphasizing static typing for robust and scalable AI development. The course includes modules on Python fundamentals, object-oriented programming, advanced Python concepts, AI-assisted Python programming, web application basics with Python, and the future of Python in AI. Upon completion, students will be able to write proficient Modern Python code, apply OOP principles, implement asynchronous programming, utilize AI-powered tools, develop basic web applications, and understand the future directions of Python in AI.
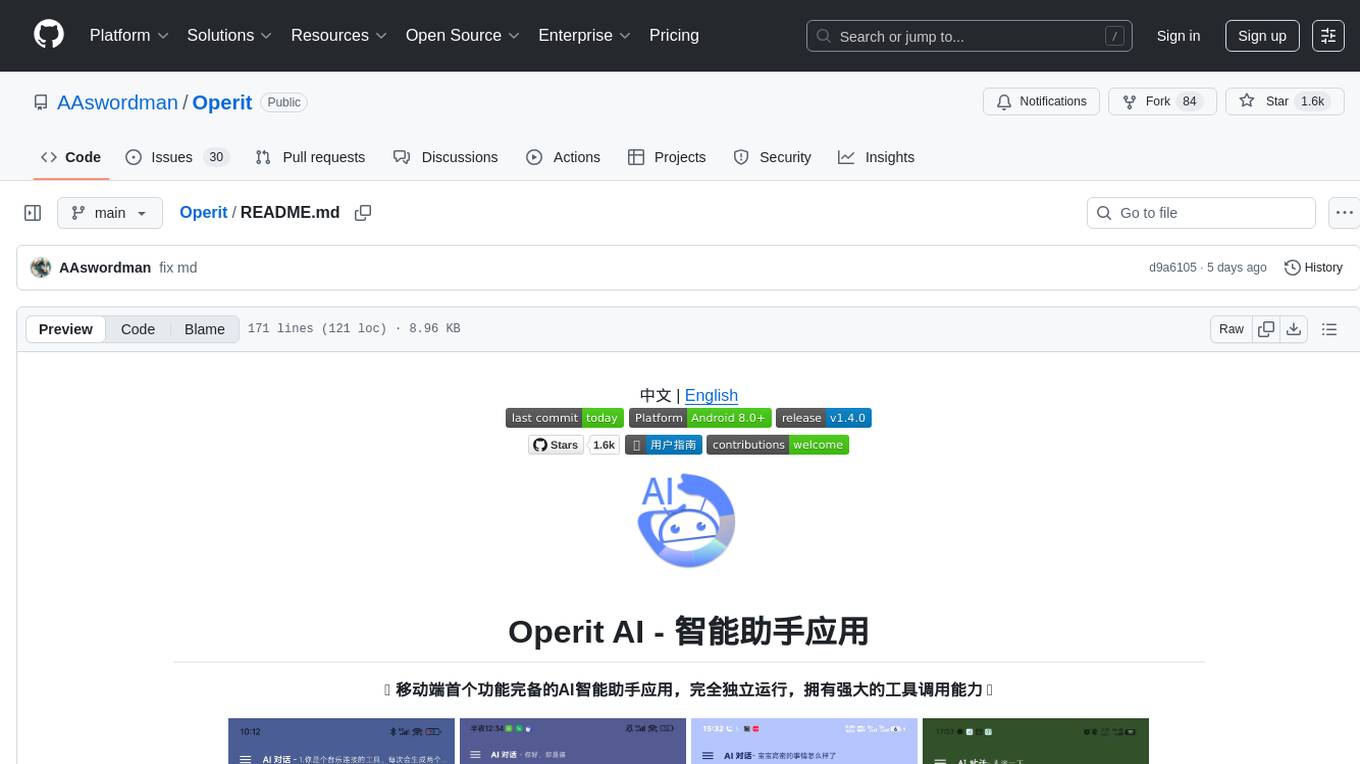
Operit
Operit AI is a fully functional AI assistant application for mobile devices, running independently on Android devices with powerful tool invocation capabilities. It offers over 40 built-in tools for file system operations, HTTP requests, system operations, UI automation, and media processing. The app combines these tools with rich plugins to enable a wide range of tasks, from simple to complex, providing a comprehensive experience of a smartphone AI assistant.

echo
Echo is a tool that simplifies the integration of AI SDKs into applications, providing instant OAuth, user accounts, and usage billing in just 5 lines of code. It eliminates the need to manage API keys, build authentication flows, or set up payment processing, allowing developers to go live in minutes. Users benefit from a universal balance that works across all Echo-powered apps, with revenue directly hitting the developer's GitHub account. Echo offers various SDKs for different frameworks like Next.js and React, along with templates to quickly start projects with Echo integration.
holmesgpt
HolmesGPT is an open-source DevOps assistant powered by OpenAI or any tool-calling LLM of your choice. It helps in troubleshooting Kubernetes, incident response, ticket management, automated investigation, and runbook automation in plain English. The tool connects to existing observability data, is compliance-friendly, provides transparent results, supports extensible data sources, runbook automation, and integrates with existing workflows. Users can install HolmesGPT using Brew, prebuilt Docker container, Python Poetry, or Docker. The tool requires an API key for functioning and supports OpenAI, Azure AI, and self-hosted LLMs.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.