Best AI tools for< Train Llm >
20 - AI tool Sites
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Labelbox
Labelbox is a data factory platform that empowers AI teams to manage data labeling, train models, and create better data with internet scale RLHF platform. It offers an all-in-one solution comprising tooling and services powered by a global community of domain experts. Labelbox operates a global data labeling infrastructure and operations for AI workloads, providing expert human network for data labeling in various domains. The platform also includes AI-assisted alignment for maximum efficiency, data curation, model training, and labeling services. Customers achieve breakthroughs with high-quality data through Labelbox.
Exa
Exa is a web API designed to provide AI applications with powerful access to the web by organizing and retrieving the best content using embeddings. It offers features like semantic search, similarity search, content scraping, and powerful filters to help developers and companies gather and process data for AI training and analysis. Exa is trusted by thousands of developers and companies for its speed, quality, and ability to provide up-to-date information from various sources on the web.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.

OpenPlayground
OpenPlayground is a cloud-based platform that provides access to a variety of AI tools and resources. It allows users to train and deploy machine learning models, access pre-trained models, and collaborate on AI projects. OpenPlayground is designed to make AI more accessible and easier to use for everyone, from beginners to experienced data scientists.
Kiln
Kiln is an AI tool designed for fine-tuning LLM models, generating synthetic data, and facilitating collaboration on datasets. It offers intuitive desktop apps, zero-code fine-tuning for various models, interactive visual tools for data generation, Git-based version control for datasets, and the ability to generate various prompts from data. Kiln supports a wide range of models and providers, provides an open-source library and API, prioritizes privacy, and allows structured data tasks in JSON format. The tool is free to use and focuses on rapid AI prototyping and dataset collaboration.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.

Mirage
Mirage is a custom AI platform that builds custom LLMs to accelerate productivity. It is backed by Sequoia and offers a variety of features, including the ability to create custom AI models, train models on your own data, and deploy models to the cloud or on-premises.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
ApX Machine Learning
ApX Machine Learning is a comprehensive resource for AI students, developers, and researchers, offering tools and learning resources to pioneer the future of AI. It provides a wide range of courses, tools, and benchmarks for learners, developers, and researchers in the field of machine learning and artificial intelligence. The platform aims to enhance the capabilities of existing large language models (LLMs) through the Model Context Protocol (MCP), providing access to resources, benchmarks, and tools to improve LLM performance and efficiency.
Prem AI
Prem is an AI platform that empowers developers and businesses to build and fine-tune generative AI models with ease. It offers a user-friendly development platform for developers to create AI solutions effortlessly. For businesses, Prem provides tailored model fine-tuning and training to meet unique requirements, ensuring data sovereignty and ownership. Trusted by global companies, Prem accelerates the advent of sovereign generative AI by simplifying complex AI tasks and enabling full control over intellectual capital. With a suite of foundational open-source SLMs, Prem supercharges business applications with cutting-edge research and customization options.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.
GPTBots
GPTBots.ai is a powerful no-code platform for creating AI-driven business applications. It seamlessly integrates large language models with organizational data, services, and workflows to empower AI bots in driving business growth. The platform allows users to build and train AI bots without coding experience, access best-practice AI bot templates, optimize and customize AI knowledge base, and adapt to various scenarios with intelligent agent bots. GPTBots supports diverse input types, offers versatile language models, enables seamless chatbot-human handoff, and provides robust API and SDK for embedding capabilities into products. Trusted by over 100k companies worldwide, GPTBots helps enterprises enhance customer service, leads generation, SEO writing, data analysis, and more.
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
Surge AI
Surge AI is a data labeling platform that provides human-generated data for training and evaluating large language models (LLMs). It offers a global workforce of annotators who can label data in over 40 languages. Surge AI's platform is designed to be easy to use and integrates with popular machine learning tools and frameworks. The company's customers include leading AI companies, research labs, and startups.
6 - Open Source AI Tools

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.
ipex-llm
IPEX-LLM is a PyTorch library for running Large Language Models (LLMs) on Intel CPUs and GPUs with very low latency. It provides seamless integration with various LLM frameworks and tools, including llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, and more. IPEX-LLM has been optimized and verified on over 50 LLM models, including LLaMA, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, and RWKV. It supports a range of low-bit inference formats, including INT4, FP8, FP4, INT8, INT2, FP16, and BF16, as well as finetuning capabilities for LoRA, QLoRA, DPO, QA-LoRA, and ReLoRA. IPEX-LLM is actively maintained and updated with new features and optimizations, making it a valuable tool for researchers, developers, and anyone interested in exploring and utilizing LLMs.
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.
Awesome-LLM-Inference
Awesome-LLM-Inference: A curated list of 📙Awesome LLM Inference Papers with Codes, check 📖Contents for more details. This repo is still updated frequently ~ 👨💻 Welcome to star ⭐️ or submit a PR to this repo!
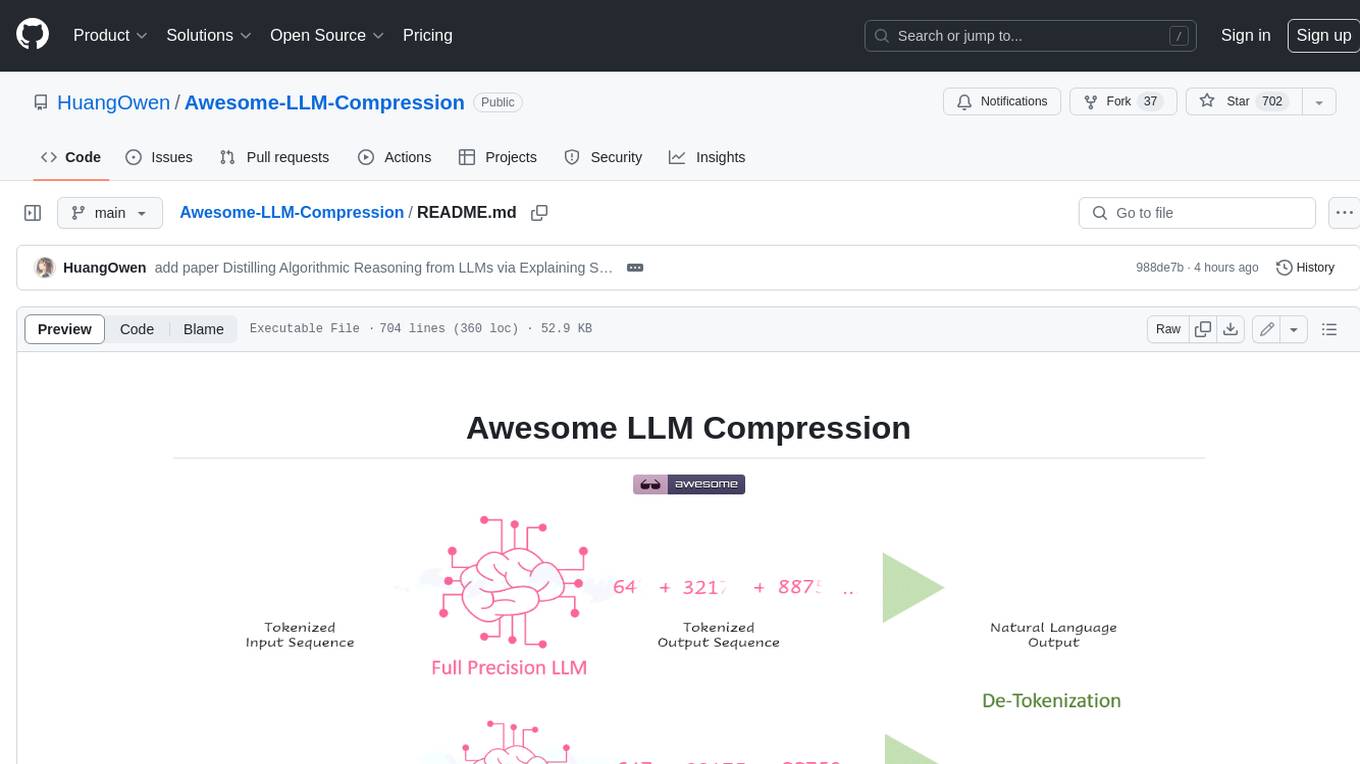
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.
20 - OpenAI Gpts
HackMeIfYouCan
Hack Me if you can - I can only talk to you about computer security, software security and LLM security @JacquesGariepy
How to Train a Chessie
Comprehensive training and wellness guide for Chesapeake Bay Retrievers.
The Train Traveler
Friendly train travel guide focusing on the best routes, essential travel information, and personalized travel insights, for both experienced and novice travelers.
How to Train Your Dog (or Cat, or Dragon, or...)
Expert in pet training advice, friendly and engaging.
TrainTalk
Your personal advisor for eco-friendly train travel. Let's plan your next journey together!
Monster Battle - RPG Game
Train monsters, travel the world, earn Arena Tokens and become the ultimate monster battling champion of earth!
Hero Master AI: Superhero Training
Train to become a superhero or a supervillain. Master your powers, make pivotal choices. Each decision you make in this action-packed game not only shapes your abilities but also your moral alignment in the battle between good and evil. Another GPT Simulator by Dave Lalande

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

Design Recruiter
Job interview coach for product designers. Train interviews and say stop when you need a feedback. You got this!!
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.

RailwayGPT
Technical expert on locomotives, trains, signalling, and railway technology. Can answer questions and draw designs specific to transportation domain.
Railroad Conductors and Yardmasters Roadmap
Don’t know where to even begin? Let me help create a roadmap towards the career of your dreams! Type "help" for More Information