
vim-ai
AI-powered code assistant for Vim. OpenAI and ChatGPT plugin for Vim and Neovim.
Stars: 878
vim-ai is a plugin that adds Artificial Intelligence (AI) capabilities to Vim and Neovim. It allows users to generate code, edit text, and have interactive conversations with GPT models powered by OpenAI's API. The plugin uses OpenAI's API to generate responses, requiring users to set up an account and obtain an API key. It supports various commands for text generation, editing, and chat interactions, providing a seamless integration of AI features into the Vim text editor environment.
README:
This plugin adds Artificial Intelligence (AI) capabilities to your Vim and Neovim. You can generate code, edit text, or have an interactive conversation with GPT models, all powered by OpenAI's API.

To get an idea what is possible to do with AI commands see the prompts on the Community Wiki
- Generate text or code, answer questions with AI
- Edit selected text in-place with AI
- Interactive conversation with ChatGPT
- Custom roles
- Vision capabilities (image to text)
- Generate images
- Integrates with any OpenAI-compatible API
- AI provider plugins
This plugin uses OpenAI's API to generate responses. You will need to setup an account and obtain an API key. Usage of the API is not free, but the cost is reasonable and depends on how many tokens you use, in simple terms, how much text you send and receive (see pricing). Note that the plugin does not send any of your code behind the scenes. You only share and pay for what you specifically select, for prompts and chat content.
In case you would like to experiment with Gemini, Claude or other models running as a service or locally, you can use any OpenAI compatible proxy. A simple way is to use OpenRouter which has a fair pricing (and currently offers many models for free), or setup a proxy like LiteLLM locally. See this simple guide on configuring custom OpenRouter roles.
🚨 Announcement 🚨
vim-ai can now be extended with custom provider plugins.
However, there aren't many available yet, so developing new ones is welcome!
For more, see the providers section.
- Vim or Neovim compiled with python3 support
- API key
# save api key to `~/.config/openai.token` file
echo "YOUR_OPENAI_API_KEY" > ~/.config/openai.token
# alternatively set it as an environment variable
export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
# or configure it with your organization id
echo "YOUR_OPENAI_API_KEY,YOUR_OPENAI_ORG_ID" > ~/.config/openai.token
export OPENAI_API_KEY="YOUR_OPENAI_API_KEY,YOUR_OPENAI_ORG_ID"The default api key file location is ~/.config/openai.token, but you can change it by setting the g:vim_ai_token_file_path in your .vimrc file:
let g:vim_ai_token_file_path = '~/.config/openai.token'Plug 'madox2/vim-ai'Using built-in Vim packages :help packages
# vim
mkdir -p ~/.vim/pack/plugins/start
git clone https://github.com/madox2/vim-ai.git ~/.vim/pack/plugins/start/vim-ai
# neovim
mkdir -p ~/.local/share/nvim/site/pack/plugins/start
git clone https://github.com/madox2/vim-ai.git ~/.local/share/nvim/site/pack/plugins/start/vim-aiTo use an AI command, type the command followed by an instruction prompt. You can also combine it with a visual selection. Here is a brief overview of available commands:
========== Basic AI commands ==========
:AI complete text
:AIEdit edit text
:AIChat continue or open new chat
:AIImage generate image
============== Utilities ==============
:AIRedo repeat last AI command
:AIUtilRolesOpen open role config file
:AIUtilDebugOn turn on debug logging
:AIUtilDebugOff turn off debug logging
:help vim-ai
Tip: Press Ctrl-c anytime to cancel completion
Tip: Use command shortcuts - :AIE, :AIC, :AIR, :AII or setup your own key bindings
Tip: Define and use custom roles, e.g. :AIEdit /grammar.
Tip: Use pre-defined roles /right, /below, /tab to choose how chat is open, e.g. :AIC /right
Tip: Use special role /populate to dump options to chat header, e.g. :AIC /populate /gemini
Tip: Combine commands with a range :help range, e.g. to select the whole buffer - :%AIE fix grammar
If you are interested in more tips or would like to level up your Vim with more commands like :GitCommitMessage - suggesting a git commit message, visit the Community Wiki.
This is the list of 3rd party provider plugins allowing to use different AI providers.
- google provider - Google's Gemini models
In case you are interested in developing one, have a look at reference google provider. Do not forget to open PR updating this list.
In the context of this plugin, a role means a re-usable AI instruction and/or configuration. Roles are defined in the configuration .ini file. For example by defining a grammar and o1-mini role:
let g:vim_ai_roles_config_file = '/path/to/my/roles.ini'# /path/to/my/roles.ini
[grammar]
prompt = fix spelling and grammar
options.temperature = 0.4
[o1-mini]
options.stream = 0
options.model = o1-mini
options.max_completion_tokens = 25000
options.temperature = 1
options.initial_prompt =Now you can select text and run it with command :AIEdit /grammar.
You can also combine roles :AI /o1-mini /grammar helo world!
See roles-example.ini for more examples.
In the documentation below, <selection> denotes a visual selection or any other range, {instruction} an instruction prompt, {role} a custom role and ? symbol an optional parameter.
:AI {prompt} - complete the prompt
<selection> :AI - complete the selection
<selection> :AI {instruction} - complete the selection using the instruction
<selection>? :AI /{role} {instruction}? - use role to complete
<selection>? :AIEdit - edit the current line or the selection
<selection>? :AIEdit {instruction} - edit the current line or the selection using the instruction
<selection>? :AIEdit /{role} {instruction}? - use role to edit
:AIImage {prompt} - generate image with prompt
<selection> :AIImage - generate image with seleciton
<selection>? :AI /{role} {instruction}? - use role to generate
Pre-defined image roles: /hd, /natural
:AIChat - continue or start a new conversation.
<selection>? :AIChat {instruction}? - start a new conversation given the selection, the instruction or both
<selection>? :AIChat /{role} {instruction}? - use role to complete
When the AI finishes answering, you can continue the conversation by entering insert mode, adding your prompt, and then using the command :AIChat once again.
Pre-defined chat roles: /right, /below, /tab
You can edit and save the chat conversation to an .aichat file and restore it later.
This allows you to create re-usable custom prompts, for example:
# ./refactoring-prompt.aichat
>>> system
You are a Clean Code expert, I have the following code, please refactor it in a more clean and concise way so that my colleagues can maintain the code more easily. Also, explain why you want to refactor the code so that I can add the explanation to the Pull Request.
>>> user
[attach code]
To include files in the chat a special include section is used:
>>> user
Generate documentation for the following files
>>> include
/home/user/myproject/requirements.txt
/home/user/myproject/**/*.py
Each file's contents will be added to an additional user message with ==> {path} <== header, relative paths are resolved to the current working directory.
To use image vision capabilities (image to text) include an image file:
>>> user
What object is on the image?
>>> include
~/myimage.jpg
Execute command and include stdout into the chat:
>>> user
Suggest git commit message
>>> exec
git diff
Supported chat sections are >>> system, >>> user, >>> include, >>> exec and <<< assistant
:AIRedo - repeat last AI command
Use this immediately after AI/AIEdit/AIChat command in order to re-try or get an alternative completion.
Note that the randomness of responses heavily depends on the temperature parameter.
Each command is configured with a corresponding configuration variable.
To customize the default configuration, initialize the config variable with a selection of options, for example put this to your.vimrc file:
let g:vim_ai_chat = {
\ "options": {
\ "model": "o1-preview",
\ "stream": 0,
\ "temperature": 1,
\ "max_completion_tokens": 25000,
\ "initial_prompt": "",
\ },
\}Alternatively you can use special default role:
[default.chat]
options.model = o1-preview
options.stream = 0
options.temperature = 1
options.max_completion_tokens = 25000
options.initial_prompt =Or customize the options directly in the chat buffer:
[chat]
options.model = o1-preview
options.stream = 0
options.temperature = 1
options.max_completion_tokens = 25000
options.initial_prompt =
>>> user
generate a paragraph of lorem ipsumBelow are listed all available configuration options, along with their default values. Please note that there isn't any token limit imposed on chat model.
" This prompt instructs model to be consise in order to be used inline in editor
let s:initial_complete_prompt =<< trim END
>>> system
You are a general assistant.
Answer shortly, consisely and only what you are asked.
Do not provide any explanantion or comments if not requested.
If you answer in a code, do not wrap it in markdown code block.
END
" :AI
" - provider: AI provider
" - prompt: optional prepended prompt
" - options: openai config (see https://platform.openai.com/docs/api-reference/completions)
" - options.initial_prompt: prompt prepended to every chat request (list of lines or string)
" - options.temperature: use -1 to disable this parameter
" - options.request_timeout: request timeout in seconds
" - options.auth_type: API authentication method (bearer, api-key, none)
" - options.token_file_path: override global token configuration
" - options.token_load_fn: expression/vim function to load token
" - options.selection_boundary: selection prompt wrapper (eliminates empty responses, see #20)
" - ui.paste_mode: use paste mode (see more info in the Notes below)
let g:vim_ai_complete = {
\ "provider": "openai",
\ "prompt": "",
\ "options": {
\ "model": "gpt-4o",
\ "endpoint_url": "https://api.openai.com/v1/chat/completions",
\ "max_tokens": 0,
\ "max_completion_tokens": 0,
\ "temperature": 0.1,
\ "request_timeout": 20,
\ "stream": 1,
\ "auth_type": "bearer",
\ "token_file_path": "",
\ "token_load_fn": "",
\ "selection_boundary": "#####",
\ "initial_prompt": s:initial_complete_prompt,
\ },
\ "ui": {
\ "paste_mode": 1,
\ },
\}
" :AIEdit
" - provider: AI provider
" - prompt: optional prepended prompt
" - options: openai config (see https://platform.openai.com/docs/api-reference/completions)
" - options.initial_prompt: prompt prepended to every chat request (list of lines or string)
" - options.temperature: use -1 to disable this parameter
" - options.request_timeout: request timeout in seconds
" - options.auth_type: API authentication method (bearer, api-key, none)
" - options.token_file_path: override global token configuration
" - options.token_load_fn: expression/vim function to load token
" - options.selection_boundary: selection prompt wrapper (eliminates empty responses, see #20)
" - ui.paste_mode: use paste mode (see more info in the Notes below)
let g:vim_ai_edit = {
\ "provider": "openai",
\ "prompt": "",
\ "options": {
\ "model": "gpt-4o",
\ "endpoint_url": "https://api.openai.com/v1/chat/completions",
\ "max_tokens": 0,
\ "max_completion_tokens": 0,
\ "temperature": 0.1,
\ "request_timeout": 20,
\ "stream": 1,
\ "auth_type": "bearer",
\ "token_file_path": "",
\ "token_load_fn": "",
\ "selection_boundary": "#####",
\ "initial_prompt": s:initial_complete_prompt,
\ },
\ "ui": {
\ "paste_mode": 1,
\ },
\}
" This prompt instructs model to work with syntax highlighting
let s:initial_chat_prompt =<< trim END
>>> system
You are a general assistant.
If you attach a code block add syntax type after ``` to enable syntax highlighting.
END
" :AIChat
" - provider: AI provider
" - prompt: optional prepended prompt
" - options: openai config (see https://platform.openai.com/docs/api-reference/chat)
" - options.initial_prompt: prompt prepended to every chat request (list of lines or string)
" - options.temperature: use -1 to disable this parameter
" - options.request_timeout: request timeout in seconds
" - options.auth_type: API authentication method (bearer, api-key, none)
" - options.token_file_path: override global token configuration
" - options.token_load_fn: expression/vim function to load token
" - options.selection_boundary: selection prompt wrapper (eliminates empty responses, see #20)
" - ui.open_chat_command: preset (preset_below, preset_tab, preset_right) or a custom command
" - ui.populate_options: dump [chat] config to the chat header
" - ui.scratch_buffer_keep_open: re-use scratch buffer within the vim session
" - ui.force_new_chat: force new chat window (used in chat opening roles e.g. `/tab`)
" - ui.paste_mode: use paste mode (see more info in the Notes below)
let g:vim_ai_chat = {
\ "provider": "openai",
\ "prompt": "",
\ "options": {
\ "model": "gpt-4o",
\ "endpoint_url": "https://api.openai.com/v1/chat/completions",
\ "max_tokens": 0,
\ "max_completion_tokens": 0,
\ "temperature": 1,
\ "request_timeout": 20,
\ "stream": 1,
\ "auth_type": "bearer",
\ "token_file_path": "",
\ "token_load_fn": "",
\ "selection_boundary": "",
\ "initial_prompt": s:initial_chat_prompt,
\ },
\ "ui": {
\ "open_chat_command": "preset_below",
\ "scratch_buffer_keep_open": 0,
\ "populate_options": 0,
\ "force_new_chat": 0,
\ "paste_mode": 1,
\ },
\}
" :AIImage
" - prompt: optional prepended prompt
" - options: openai config (https://platform.openai.com/docs/api-reference/images/create)
" - options.request_timeout: request timeout in seconds
" - options.auth_type: API authentication method (bearer, api-key, none)
" - options.token_file_path: override global token configuration
" - options.token_load_fn: expression/vim function to load token
" - options.download_dir: path to image download directory, `cwd` if not defined
let g:vim_ai_image = {
\ "provider": "openai",
\ "prompt": "",
\ "options": {
\ "model": "dall-e-3",
\ "endpoint_url": "https://api.openai.com/v1/images/generations",
\ "quality": "standard",
\ "size": "1024x1024",
\ "style": "vivid",
\ "request_timeout": 40,
\ "auth_type": "bearer",
\ "token_file_path": "",
\ "token_load_fn": "",
\ },
\ "ui": {
\ "download_dir": "",
\ },
\}
" custom roles file location
let g:vim_ai_roles_config_file = s:plugin_root . "/roles-example.ini"
" custom token file location
let g:vim_ai_token_file_path = "~/.config/openai.token"
" custom fn to load token, e.g. "g:GetAIToken()"
let g:vim_ai_token_load_fn = ""
" enables/disables full markdown highlighting in aichat files
" NOTE: code syntax highlighting works out of the box without this option enabled
" NOTE: highlighting may be corrupted when using together with the `preservim/vim-markdown`
g:vim_ai_chat_markdown = 0
" debug settings
let g:vim_ai_debug = 0
let g:vim_ai_debug_log_file = "/tmp/vim_ai_debug.log"
" Notes:
" ui.paste_mode
" - if disabled code indentation will work but AI doesn't always respond with a code block
" therefore it could be messed up
" - find out more in vim's help `:help paste`
" options.max_tokens
" - note that prompt + max_tokens must be less than model's token limit, see #42, #46
" - setting max tokens to 0 will exclude it from the OpenAI API request parameters, it is
" unclear/undocumented what it exactly does, but it seems to resolve issues when the model
" hits token limit, which respond with `OpenAI: HTTPError 400`
" options.selection_boundary
" - setting ``` value behaves in markdown-like fasion - adds filetype to the boundary
### Using custom API
It is possible to configure the plugin to use different OpenAI-compatible endpoints.
See some cool projects listed in [Custom APIs](https://github.com/madox2/vim-ai/wiki/Custom-APIs) section on the [Community Wiki](https://github.com/madox2/vim-ai/wiki).
```vim
let g:vim_ai_chat = {
\ "options": {
\ "endpoint_url": "http://localhost:8000/v1/chat/completions",
\ "auth_type": "none",
\ },
\}First you need open an account on OpenRouter website and create an api key. You can start with free models and add credits later if you wish. Then you set up a custom role that points to the OpenRouter endpoint:
[gemini]
options.token_file_path = ~/.config/openrouter.token
options.endpoint_url = https://openrouter.ai/api/v1/chat/completions
options.model = google/gemini-exp-1121:free
[llama]
options.token_file_path = ~/.config/openrouter.token
options.endpoint_url = https://openrouter.ai/api/v1/chat/completions
options.model = meta-llama/llama-3.3-70b-instruct
[claude]
options.token_file_path = ~/.config/openrouter.token
options.endpoint_url = https://openrouter.ai/api/v1/chat/completions
options.model = anthropic/claude-3.5-haikuNow you can use the role:
:AI /gemini who created you?
I was created by Google.
This plugin does not set any key binding. Create your own bindings in the .vimrc to trigger AI commands, for example:
" complete text on the current line or in visual selection
nnoremap <leader>a :AI<CR>
xnoremap <leader>a :AI<CR>
" edit text with a custom prompt
xnoremap <leader>s :AIEdit fix grammar and spelling<CR>
nnoremap <leader>s :AIEdit fix grammar and spelling<CR>
" trigger chat
xnoremap <leader>c :AIChat<CR>
nnoremap <leader>c :AIChat<CR>
" redo last AI command
nnoremap <leader>r :AIRedo<CR>You might find useful a collection of custom commands on the Community Wiki.
To create a custom command, you can call AIRun, AIEditRun and AIChatRun functions. For example:
" custom command suggesting git commit message, takes no arguments
function! GitCommitMessageFn()
let l:range = 0
let l:diff = system('git --no-pager diff --staged')
let l:prompt = "generate a short commit message from the diff below:\n" . l:diff
let l:config = {
\ "options": {
\ "model": "gpt-4o",
\ "initial_prompt": ">>> system\nyou are a code assistant",
\ "temperature": 1,
\ },
\}
call vim_ai#AIRun(l:range, l:config, l:prompt)
endfunction
command! GitCommitMessage call GitCommitMessageFn()
" custom command that provides a code review for selected code block
function! CodeReviewFn(range) range
let l:prompt = "programming syntax is " . &filetype . ", review the code below"
let l:config = {
\ "options": {
\ "initial_prompt": ">>> system\nyou are a clean code expert",
\ },
\}
exe a:firstline.",".a:lastline . "call vim_ai#AIChatRun(a:range, l:config, l:prompt)"
endfunction
command! -range -nargs=? AICodeReview <line1>,<line2>call CodeReviewFn(<range>)Contributions are welcome! Please feel free to open a pull request, report an issue, or contribute to the Community Wiki.
Accuracy: GPT is good at producing text and code that looks correct at first glance, but may be completely wrong. Be sure to thoroughly review, read and test all output generated by this plugin!
Privacy: This plugin sends text to OpenAI (or other providers) when generating completions and edits. Therefore, do not use it on files containing sensitive information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vim-ai
Similar Open Source Tools
vim-ai
vim-ai is a plugin that adds Artificial Intelligence (AI) capabilities to Vim and Neovim. It allows users to generate code, edit text, and have interactive conversations with GPT models powered by OpenAI's API. The plugin uses OpenAI's API to generate responses, requiring users to set up an account and obtain an API key. It supports various commands for text generation, editing, and chat interactions, providing a seamless integration of AI features into the Vim text editor environment.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
mcp-server-odoo
The MCP Server for Odoo is a tool that enables AI assistants like Claude to interact with Odoo ERP systems. Users can access business data, search records, create new entries, update existing data, and manage their Odoo instance through natural language. The server works with any Odoo instance and offers features like search and retrieve, create new records, update existing data, delete records, browse multiple records, count records, inspect model fields, secure access, smart pagination, LLM-optimized output, and YOLO Mode for quick access. Installation and configuration instructions are provided for different environments, along with troubleshooting tips. The tool supports various tasks such as searching and retrieving records, creating and managing records, listing models, updating records, deleting records, and accessing Odoo data through resource URIs.

parrot.nvim
Parrot.nvim is a Neovim plugin that prioritizes a seamless out-of-the-box experience for text generation. It simplifies functionality and focuses solely on text generation, excluding integration of DALLE and Whisper. It supports persistent conversations as markdown files, custom hooks for inline text editing, multiple providers like Anthropic API, perplexity.ai API, OpenAI API, Mistral API, and local/offline serving via ollama. It allows custom agent definitions, flexible API credential support, and repository-specific instructions with a `.parrot.md` file. It does not have autocompletion or hidden requests in the background to analyze files.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.
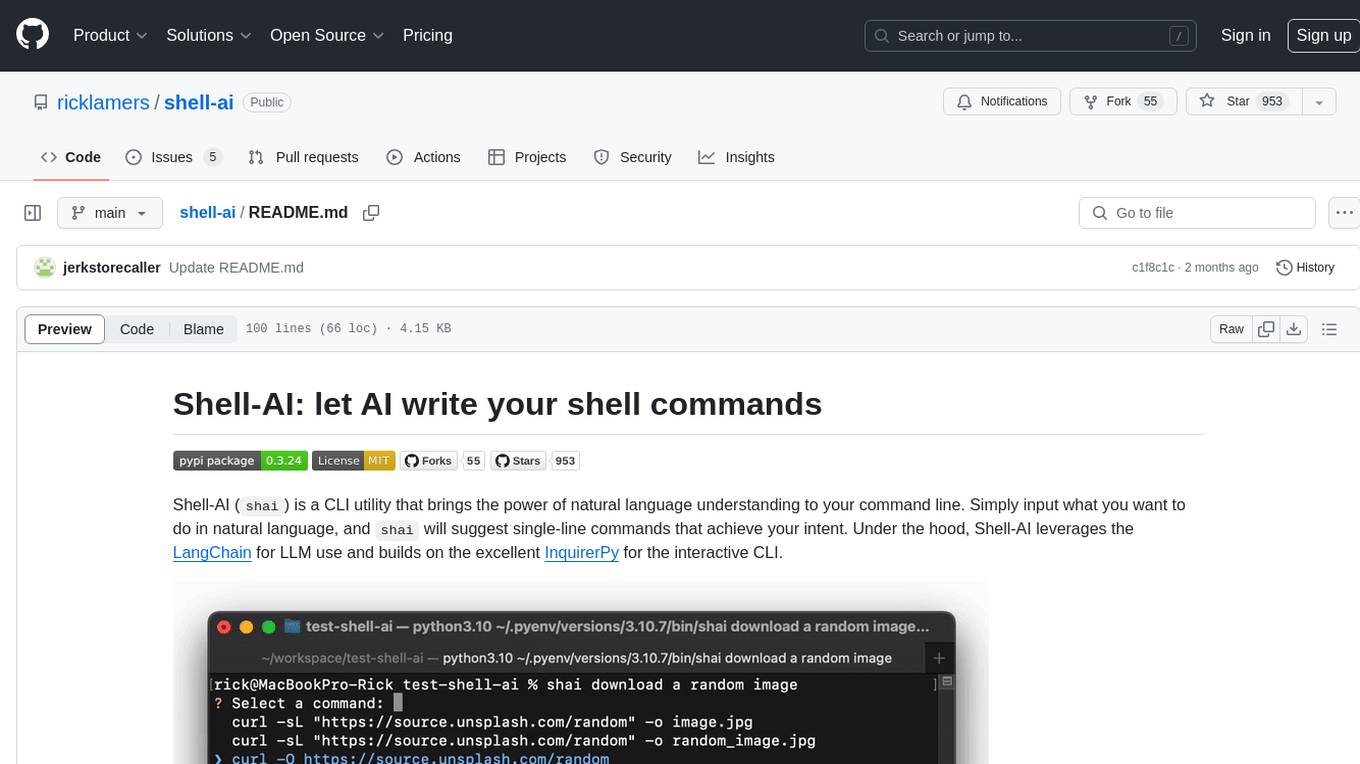
shell-ai
Shell-AI (`shai`) is a CLI utility that enables users to input commands in natural language and receive single-line command suggestions. It leverages natural language understanding and interactive CLI tools to enhance command line interactions. Users can describe tasks in plain English and receive corresponding command suggestions, making it easier to execute commands efficiently. Shell-AI supports cross-platform usage and is compatible with Azure OpenAI deployments, offering a user-friendly and efficient way to interact with the command line.
avante.nvim
avante.nvim is a Neovim plugin that emulates the behavior of the Cursor AI IDE, providing AI-driven code suggestions and enabling users to apply recommendations to their source files effortlessly. It offers AI-powered code assistance and one-click application of suggested changes, streamlining the editing process and saving time. The plugin is still in early development, with functionalities like setting API keys, querying AI about code, reviewing suggestions, and applying changes. Key bindings are available for various actions, and the roadmap includes enhancing AI interactions, stability improvements, and introducing new features for coding tasks.

swarmzero
SwarmZero SDK is a library that simplifies the creation and execution of AI Agents and Swarms of Agents. It supports various LLM Providers such as OpenAI, Azure OpenAI, Anthropic, MistralAI, Gemini, Nebius, and Ollama. Users can easily install the library using pip or poetry, set up the environment and configuration, create and run Agents, collaborate with Swarms, add tools for complex tasks, and utilize retriever tools for semantic information retrieval. Sample prompts are provided to help users explore the capabilities of the agents and swarms. The SDK also includes detailed examples and documentation for reference.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

openmacro
Openmacro is a multimodal personal agent that allows users to run code locally. It acts as a personal agent capable of completing and automating tasks autonomously via self-prompting. The tool provides a CLI natural-language interface for completing and automating tasks, analyzing and plotting data, browsing the web, and manipulating files. Currently, it supports API keys for models powered by SambaNova, with plans to add support for other hosts like OpenAI and Anthropic in future versions.
sonarqube-mcp-server
The SonarQube MCP Server is a Model Context Protocol (MCP) server that enables seamless integration with SonarQube Server or Cloud for code quality and security. It supports the analysis of code snippets directly within the agent context. The server provides various tools for analyzing code, managing issues, accessing metrics, and interacting with SonarQube projects. It also supports advanced features like dependency risk analysis, enterprise portfolio management, and system health checks. The server can be configured for different transport modes, proxy settings, and custom certificates. Telemetry data collection can be disabled if needed.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.
nvim.ai
nvim.ai is a powerful Neovim plugin that enables AI-assisted coding and chat capabilities within the editor. Users can chat with buffers, insert code with an inline assistant, and utilize various LLM providers for context-aware AI assistance. The plugin supports features like interacting with AI about code and documents, receiving relevant help based on current work, code insertion, code rewriting (Work in Progress), and integration with multiple LLM providers. Users can configure the plugin, add API keys to dotfiles, and integrate with nvim-cmp for command autocompletion. Keymaps are available for chat and inline assist functionalities. The chat dialog allows parsing content with keywords and supports roles like /system, /you, and /assistant. Context-aware assistance can be accessed through inline assist by inserting code blocks anywhere in the file.

clawlet
Clawlet is an ultra-lightweight and efficient personal AI assistant that comes as a single binary with no CGO, runtime, or dependencies. It features hybrid semantic memory search and is inspired by OpenClaw and nanobot. Users can easily download Clawlet from GitHub Releases and drop it on any machine to enable memory search functionality. The tool supports various LLM providers like OpenAI, OpenRouter, Anthropic, Gemini, and local endpoints. Users can configure Clawlet for memory search setup and chat app integrations for platforms like Telegram, WhatsApp, Discord, and Slack. Clawlet CLI provides commands for initializing workspace, running the agent, managing channels, scheduling jobs, and more.
typst-mcp
Typst MCP Server is an implementation of the Model Context Protocol (MCP) that facilitates interaction between AI models and Typst, a markup-based typesetting system. The server offers tools for converting between LaTeX and Typst, validating Typst syntax, and generating images from Typst code. It provides functions such as listing documentation chapters, retrieving specific chapters, converting LaTeX snippets to Typst, validating Typst syntax, and rendering Typst code to images. The server is designed to assist Language Model Managers (LLMs) in handling Typst-related tasks efficiently and accurately.
For similar tasks
vim-ai
vim-ai is a plugin that adds Artificial Intelligence (AI) capabilities to Vim and Neovim. It allows users to generate code, edit text, and have interactive conversations with GPT models powered by OpenAI's API. The plugin uses OpenAI's API to generate responses, requiring users to set up an account and obtain an API key. It supports various commands for text generation, editing, and chat interactions, providing a seamless integration of AI features into the Vim text editor environment.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
parrot.nvim
Parrot.nvim is a Neovim plugin that prioritizes a seamless out-of-the-box experience for text generation. It simplifies functionality and focuses solely on text generation, excluding integration of DALLE and Whisper. It supports persistent conversations as markdown files, custom hooks for inline text editing, multiple providers like Anthropic API, perplexity.ai API, OpenAI API, Mistral API, and local/offline serving via ollama. It allows custom agent definitions, flexible API credential support, and repository-specific instructions with a `.parrot.md` file. It does not have autocompletion or hidden requests in the background to analyze files.
talon-ai-tools
Control large language models and AI tools through voice commands using the Talon Voice dictation engine. This tool is designed to help users quickly edit text, code by voice, reduce keyboard use for those with health issues, and speed up workflow by using AI commands across the desktop. It prompts and extends tools like Github Copilot and OpenAI API for text and image generation. Users can set up the tool by downloading the repo, obtaining an OpenAI API key, and customizing the endpoint URL for preferred models. The tool can be used without an OpenAI key and can be exclusively used with Copilot for those not needing LLM integration.
nvim-aider
Nvim-aider is a plugin for Neovim that provides additional functionality and key mappings to enhance the user's editing experience. It offers features such as code navigation, quick access to commonly used commands, and improved text manipulation tools. With Nvim-aider, users can streamline their workflow and increase productivity while working with Neovim.
BiBi-Keyboard
BiBi-Keyboard is an AI-based intelligent voice input method that aims to make voice input more natural and efficient. It provides features such as voice recognition with simple and intuitive operations, multiple ASR engine support, AI text post-processing, floating ball input for cross-input method usage, AI editing panel with rich editing tools, Material3 design for modern interface style, and support for multiple languages. Users can adjust keyboard height, test input directly in the settings page, view recognition word count statistics, receive vibration feedback, and check for updates automatically. The tool requires Android 10.0 or higher, microphone permission for voice recognition, optional overlay permission for the floating ball feature, and optional accessibility permission for automatic text insertion.
claudian
Claudian is an Obsidian plugin that embeds Claude Code as an AI collaborator in your vault. It provides full agentic capabilities, including file read/write, search, bash commands, and multi-step workflows. Users can leverage Claude Code's power to interact with their vault, analyze images, edit text inline, add custom instructions, create reusable prompt templates, extend capabilities with skills and agents, connect external tools via Model Context Protocol servers, control models and thinking budget, toggle plan mode, ensure security with permission modes and vault confinement, and interact with Chrome. The plugin requires Claude Code CLI, Obsidian v1.8.9+, Claude subscription/API or custom model provider, and desktop platforms (macOS, Linux, Windows).
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.