
deep-searcher
Open Source Deep Research Alternative to Reason and Search on Private Data. Written in Python.
Stars: 4743

DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.
README:

DeepSearcher combines reasoning LLMs (OpenAI o1, o3-mini, DeepSeek, Grok 3, Claude 3.7 Sonnet, QwQ, etc.) and Vector Databases (Milvus, Zilliz Cloud etc.) to perform search, evaluation, and reasoning based on private data, providing highly accurate answer and comprehensive report. This project is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios.

- Private Data Search: Maximizes the utilization of enterprise internal data while ensuring data security. When necessary, it can integrate online content for more accurate answers.
- Vector Database Management: Supports Milvus and other vector databases, allowing data partitioning for efficient retrieval.
- Flexible Embedding Options: Compatible with multiple embedding models for optimal selection.
- Multiple LLM Support: Supports DeepSeek, OpenAI, and other large models for intelligent Q&A and content generation.
- Document Loader: Supports local file loading, with web crawling capabilities under development.

Install DeepSearcher using pip:
# Clone the repository
git clone https://github.com/zilliztech/deep-searcher.git
# MAKE SURE the python version is greater than or equal to 3.10
# Recommended: Create a Python virtual environment
cd deep-searcher
python3 -m venv .venv
source .venv/bin/activate
# Install dependencies
pip install -e .Prepare your OPENAI_API_KEY in your environment variables. If you change the LLM in the configuration, make sure to prepare the corresponding API key.
from deepsearcher.configuration import Configuration, init_config
from deepsearcher.online_query import query
config = Configuration()
# Customize your config here,
# more configuration see the Configuration Details section below.
config.set_provider_config("llm", "OpenAI", {"model": "o1-mini"})
config.set_provider_config("embedding", "OpenAIEmbedding", {"model": "text-embedding-ada-002"})
init_config(config = config)
# Load your local data
from deepsearcher.offline_loading import load_from_local_files
load_from_local_files(paths_or_directory=your_local_path)
# (Optional) Load from web crawling (`FIRECRAWL_API_KEY` env variable required)
from deepsearcher.offline_loading import load_from_website
load_from_website(urls=website_url)
# Query
result = query("Write a report about xxx.") # Your question hereconfig.set_provider_config("llm", "(LLMName)", "(Arguments dict)")The "LLMName" can be one of the following: ["DeepSeek", "OpenAI", "XAI", "SiliconFlow", "PPIO", "TogetherAI", "Gemini", "Ollama"]
The "Arguments dict" is a dictionary that contains the necessary arguments for the LLM class.
Example (OpenAI)
Make sure you have prepared your OPENAI API KEY as an env variable OPENAI_API_KEY.
config.set_provider_config("llm", "OpenAI", {"model": "o1-mini"})More details about OpenAI models: https://platform.openai.com/docs/models
Example (DeepSeek from official)
Make sure you have prepared your DEEPSEEK API KEY as an env variable DEEPSEEK_API_KEY.
config.set_provider_config("llm", "DeepSeek", {"model": "deepseek-reasoner"})More details about DeepSeek: https://api-docs.deepseek.com/
Example (DeepSeek from SiliconFlow)
Make sure you have prepared your SILICONFLOW API KEY as an env variable SILICONFLOW_API_KEY.
config.set_provider_config("llm", "SiliconFlow", {"model": "deepseek-ai/DeepSeek-R1"})More details about SiliconFlow: https://docs.siliconflow.cn/quickstart
Example (DeepSeek from TogetherAI)
Make sure you have prepared your TOGETHER API KEY as an env variable TOGETHER_API_KEY.
config.set_provider_config("llm", "TogetherAI", {"model": "deepseek-ai/DeepSeek-R1"}) You need to install together before running, execute: pip install together. More details about TogetherAI: https://www.together.ai/
Example (XAI Grok)
Make sure you have prepared your XAI API KEY as an env variable XAI_API_KEY.
config.set_provider_config("llm", "XAI", {"model": "grok-2-latest"})More details about XAI Grok: https://docs.x.ai/docs/overview#featured-models
Example (Claude)
Make sure you have prepared your ANTHROPIC API KEY as an env variable ANTHROPIC_API_KEY.
config.set_provider_config("llm", "Anthropic", {"model": "claude-3-7-sonnet-latest"})More details about Anthropic Claude: https://docs.anthropic.com/en/home
Example (Google Gemini)
Make sure you have prepared your GEMINI API KEY as an env variable GEMINI_API_KEY.
config.set_provider_config('llm', 'Gemini', { 'model': 'gemini-2.0-flash' }) You need to install gemini before running, execute: pip install google-genai. More details about Gemini: https://ai.google.dev/gemini-api/docs
Example (DeepSeek from PPIO)
Make sure you have prepared your PPIO API KEY as an env variable PPIO_API_KEY. You can create an API Key here.
config.set_provider_config("llm", "PPIO", {"model": "deepseek/deepseek-r1-turbo"})More details about PPIO: https://ppinfra.com/docs/get-started/quickstart.html?utm_source=github_deep-searcher
Example (Ollama)
Follow these instructions to set up and run a local Ollama instance:
Download and install Ollama onto the available supported platforms (including Windows Subsystem for Linux).
View a list of available models via the model library.
Fetch available LLM models via ollama pull <name-of-model>
Example: ollama pull qwq
To chat directly with a model from the command line, use ollama run <name-of-model>.
By default, Ollama has a REST API for running and managing models on http://localhost:11434.
config.set_provider_config("llm", "Ollama", {"model": "qwq"})Example (Volcengine)
Make sure you have prepared your Volcengine API KEY as an env variable VOLCENGINE_API_KEY. You can create an API Key here.
config.set_provider_config("llm", "Volcengine", {"model": "deepseek-r1-250120"})More details about Volcengine: https://www.volcengine.com/docs/82379/1099455?utm_source=github_deep-searcher
Example (GLM)
Make sure you have prepared your GLM API KEY as an env variable GLM_API_KEY.
config.set_provider_config("llm", "GLM", {"model": "glm-4-plus"}) You need to install zhipuai before running, execute: pip install zhipuai. More details about GLM: https://bigmodel.cn/dev/welcome
config.set_provider_config("embedding", "(EmbeddingModelName)", "(Arguments dict)")The "EmbeddingModelName" can be one of the following: ["MilvusEmbedding", "OpenAIEmbedding", "VoyageEmbedding", "SiliconflowEmbedding"]
The "Arguments dict" is a dictionary that contains the necessary arguments for the embedding model class.
Example (OpenAI embedding)
Make sure you have prepared your OpenAI API KEY as an env variable OPENAI_API_KEY.
config.set_provider_config("embedding", "OpenAIEmbedding", {"model": "text-embedding-3-small"})More details about OpenAI models: https://platform.openai.com/docs/guides/embeddings/use-cases
Example (Pymilvus built-in embedding model)
Use the built-in embedding model in Pymilvus, you can set the model name as "default", "BAAI/bge-base-en-v1.5", "BAAI/bge-large-en-v1.5", "jina-embeddings-v3", etc.
See [milvus_embedding.py](deepsearcher/embedding/milvus_embedding.py) for more details.
config.set_provider_config("embedding", "MilvusEmbedding", {"model": "BAAI/bge-base-en-v1.5"})config.set_provider_config("embedding", "MilvusEmbedding", {"model": "jina-embeddings-v3"}) For Jina's embedding model, you needJINAAI_API_KEY.
You need to install pymilvus model before running, execute: pip install pymilvus.model. More details about Pymilvus: https://milvus.io/docs/embeddings.md
Example (VoyageAI embedding)
Make sure you have prepared your VOYAGE API KEY as an env variable VOYAGE_API_KEY.
config.set_provider_config("embedding", "VoyageEmbedding", {"model": "voyage-3"}) You need to install voyageai before running, execute: pip install voyageai. More details about VoyageAI: https://docs.voyageai.com/embeddings/
Example (Amazon Bedrock embedding)
config.set_provider_config("embedding", "BedrockEmbedding", {"model": "amazon.titan-embed-text-v2:0"}) You need to install boto3 before running, execute: pip install boto3. More details about Amazon Bedrock: https://docs.aws.amazon.com/bedrock/
Example (Siliconflow embedding)
Make sure you have prepared your Siliconflow API KEY as an env variable SILICONFLOW_API_KEY.
config.set_provider_config("embedding", "SiliconflowEmbedding", {"model": "BAAI/bge-m3"})More details about Siliconflow: https://docs.siliconflow.cn/en/api-reference/embeddings/create-embeddings
Example (Volcengine embedding)
Make sure you have prepared your Volcengine API KEY as an env variable VOLCENGINE_API_KEY.
config.set_provider_config("embedding", "VolcengineEmbedding", {"model": "doubao-embedding-text-240515"})More details about Volcengine: https://www.volcengine.com/docs/82379/1302003
Example (GLM embedding)
Make sure you have prepared your GLM API KEY as an env variable GLM_API_KEY.
config.set_provider_config("embedding", "GLMEmbedding", {"model": "embedding-3"}) You need to install zhipuai before running, execute: pip install zhipuai. More details about GLM: https://bigmodel.cn/dev/welcome
Example (Google Gemini embedding)
Make sure you have prepared your Gemini API KEY as an env variable GEMINI_API_KEY.
config.set_provider_config("embedding", "GeminiEmbedding", {"model": "text-embedding-004"}) You need to install gemini before running, execute: pip install google-genai. More details about Gemini: https://ai.google.dev/gemini-api/docs
Example (Ollama embedding)
config.set_provider_config("embedding", "OllamaEmbedding", {"model": "bge-m3"}) You need to install ollama before running, execute: pip install ollama. More details about Ollama Python SDK: https://github.com/ollama/ollama-python
config.set_provider_config("vector_db", "(VectorDBName)", "(Arguments dict)")The "VectorDBName" can be one of the following: ["Milvus"] (Under development)
The "Arguments dict" is a dictionary that contains the necessary arguments for the Vector Database class.
Example (Milvus)
config.set_provider_config("vector_db", "Milvus", {"uri": "./milvus.db", "token": ""})More details about Milvus Config:
-
Setting the
urias a local file, e.g../milvus.db, is the most convenient method, as it automatically utilizes Milvus Lite to store all data in this file.
-
If you have a large-scale dataset, you can set up a more performant Milvus server using
Docker or Kubernetes.
In this setup, use the server URI, e.g.,
http://localhost:19530, as youruri.
-
If you want to use Zilliz Cloud,
the fully managed cloud service for Milvus, adjust the
uriandtokenaccording to the Public Endpoint and API Key in Zilliz Cloud.
config.set_provider_config("file_loader", "(FileLoaderName)", "(Arguments dict)")The "FileLoaderName" can be one of the following: ["PDFLoader", "TextLoader", "UnstructuredLoader"]
The "Arguments dict" is a dictionary that contains the necessary arguments for the File Loader class.
Example (Unstructured)
Make sure you have prepared your Unstructured API KEY and API URL as env variables UNSTRUCTURED_API_KEY and UNSTRUCTURED_API_URL.
config.set_provider_config("file_loader", "UnstructuredLoader", {})Currently supported file types: ["pdf"] (Under development)
You need to install unstructured-ingest before running, execute: pip install unstructured-ingest. More details about Unstructured: https://docs.unstructured.io/ingestion/overview
config.set_provider_config("web_crawler", "(WebCrawlerName)", "(Arguments dict)")The "WebCrawlerName" can be one of the following: ["FireCrawlCrawler", "Crawl4AICrawler", "JinaCrawler"]
The "Arguments dict" is a dictionary that contains the necessary arguments for the Web Crawler class.
Example (FireCrawl)
Make sure you have prepared your FireCrawl API KEY as an env variable FIRECRAWL_API_KEY.
config.set_provider_config("web_crawler", "FireCrawlCrawler", {})More details about FireCrawl: https://docs.firecrawl.dev/introduction
Example (Crawl4AI)
Make sure you have run crawl4ai-setup in your environment.
config.set_provider_config("web_crawler", "Crawl4AICrawler", {"browser_config": {"headless": True, "verbose": True}}) You need to install crawl4ai before running, execute: pip install crawl4ai. More details about Crawl4AI: https://docs.crawl4ai.com/
Example (Jina Reader)
Make sure you have prepared your Jina Reader API KEY as an env variable JINA_API_TOKEN or JINAAI_API_KEY.
config.set_provider_config("web_crawler", "JinaCrawler", {})More details about Jina Reader: https://jina.ai/reader/
deepsearcher load "your_local_path_or_url"
# load into a specific collection
deepsearcher load "your_local_path_or_url" --collection_name "your_collection_name" --collection_desc "your_collection_description"Example loading from local file:
deepsearcher load "/path/to/your/local/file.pdf"
# or more files at once
deepsearcher load "/path/to/your/local/file1.pdf" "/path/to/your/local/file2.md"Example loading from url (Set FIRECRAWL_API_KEY in your environment variables, see FireCrawl for more details):
deepsearcher load "https://www.wikiwand.com/en/articles/DeepSeek"deepsearcher query "Write a report about xxx."More help information
deepsearcher --helpFor more help information about a specific subcommand, you can use deepsearcher [subcommand] --help.
deepsearcher load --help
deepsearcher query --helpYou can configure all arguments by modifying config.yaml to set up your system with default modules.
For example, set your OPENAI_API_KEY in the llm section of the YAML file.
The main script will run a FastAPI service with default address localhost:8000.
$ python main.pyYou can open url http://localhost:8000/docs in browser to access the web service. Click on the button "Try it out", it allows you to fill the parameters and directly interact with the API.
Q1: Why I failed to parse LLM output format / How to select the LLM?
A1: Small LLMs struggle to follow the prompt to generate a desired response, which usually cause the format parsing problem. A better practice is to use large reasoning models e.g. deepseek-r1 671b, OpenAI o-series, Claude 3.7 sonnet, etc. as your LLM.
Q2: OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like GPTCache/paraphrase-albert-small-v2 is not the path to a directory containing a file named config.json. Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
A2: This is mainly due to abnormal access to huggingface, which may be a network or permission problem. You can try the following two methods:
- If there is a network problem, set up a proxy, try adding the following environment variable.
export HF_ENDPOINT=https://hf-mirror.com- If there is a permission problem, set up a personal token, try adding the following environment variable.
export HUGGING_FACE_HUB_TOKEN=xxxxQ3: DeepSearcher doesn't run in Jupyter notebook.
A3: Install nest_asyncio and then put this code block in front of your jupyter notebook.
pip install nest_asyncio
import nest_asyncio
nest_asyncio.apply()
- Open-source embedding models
-
OpenAI (
OPENAI_API_KEYenv variable required) -
VoyageAI (
VOYAGE_API_KEYenv variable required) -
Amazon Bedrock (
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYenv variable required)
-
OpenAI (
OPENAI_API_KEYenv variable required) -
DeepSeek (
DEEPSEEK_API_KEYenv variable required) -
XAI Grok (
XAI_API_KEYenv variable required) -
Anthropic Claude (
ANTHROPIC_API_KEYenv variable required) -
SiliconFlow Inference Service (
SILICONFLOW_API_KEYenv variable required) -
PPIO (
PPIO_API_KEYenv variable required) -
TogetherAI Inference Service (
TOGETHER_API_KEYenv variable required) -
Google Gemini (
GEMINI_API_KEYenv variable required) -
SambaNova Cloud Inference Service (
SAMBANOVA_API_KEYenv variable required) - Ollama
- Local File
- PDF(with txt/md) loader
-
Unstructured (under development) (
UNSTRUCTURED_API_KEYandUNSTRUCTURED_URLenv variables required)
- Web Crawler
-
FireCrawl (
FIRECRAWL_API_KEYenv variable required) -
Jina Reader (
JINA_API_TOKENenv variable required) -
Crawl4AI (You should run command
crawl4ai-setupfor the first time)
-
FireCrawl (
See the Evaluation directory for more details.
- Enhance web crawling functionality
- Support more vector databases (e.g., FAISS...)
- Add support for additional large models
- Provide RESTful API interface (DONE)
We welcome contributions! Star & Fork the project and help us build a more powerful DeepSearcher! 🎯
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for deep-searcher
Similar Open Source Tools
deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

swarmzero
SwarmZero SDK is a library that simplifies the creation and execution of AI Agents and Swarms of Agents. It supports various LLM Providers such as OpenAI, Azure OpenAI, Anthropic, MistralAI, Gemini, Nebius, and Ollama. Users can easily install the library using pip or poetry, set up the environment and configuration, create and run Agents, collaborate with Swarms, add tools for complex tasks, and utilize retriever tools for semantic information retrieval. Sample prompts are provided to help users explore the capabilities of the agents and swarms. The SDK also includes detailed examples and documentation for reference.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.
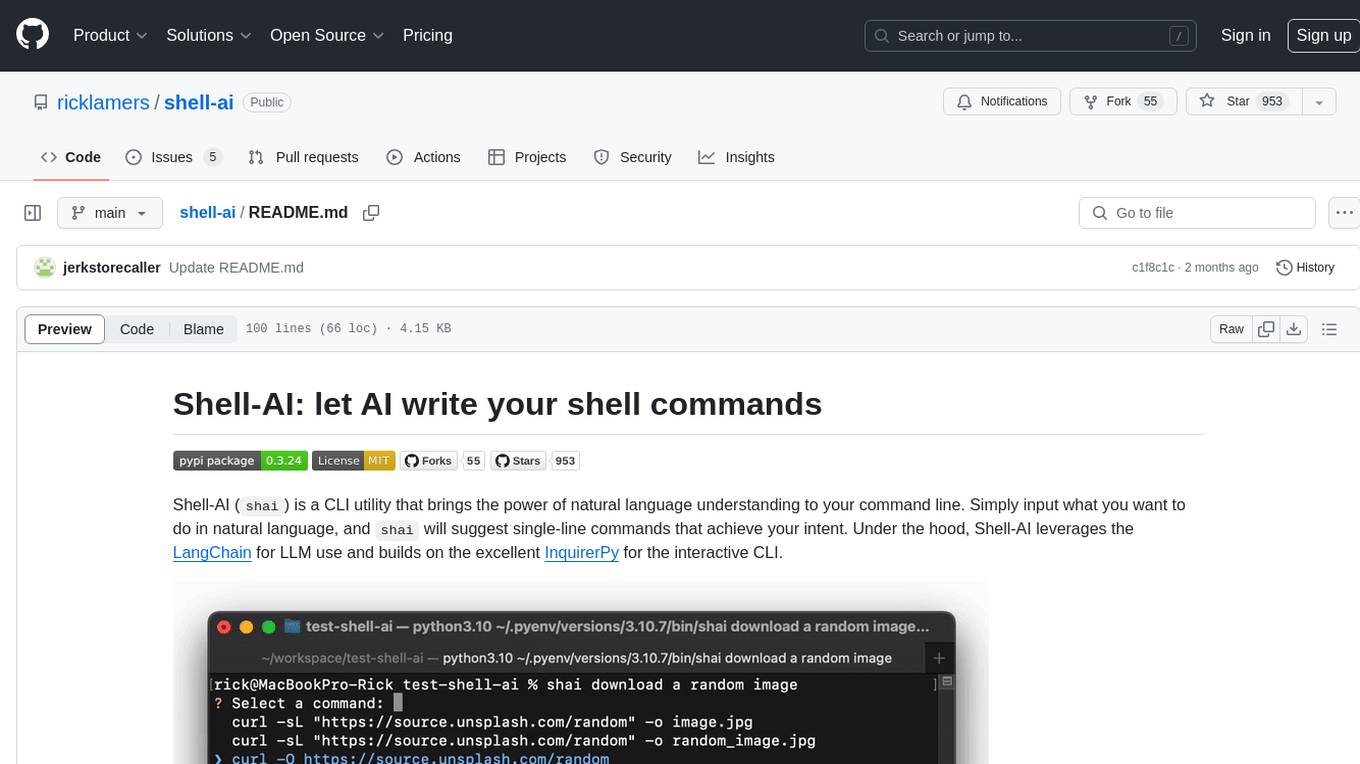
shell-ai
Shell-AI (`shai`) is a CLI utility that enables users to input commands in natural language and receive single-line command suggestions. It leverages natural language understanding and interactive CLI tools to enhance command line interactions. Users can describe tasks in plain English and receive corresponding command suggestions, making it easier to execute commands efficiently. Shell-AI supports cross-platform usage and is compatible with Azure OpenAI deployments, offering a user-friendly and efficient way to interact with the command line.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.
hf-waitress
HF-Waitress is a powerful server application for deploying and interacting with HuggingFace Transformer models. It simplifies running open-source Large Language Models (LLMs) locally on-device, providing on-the-fly quantization via BitsAndBytes, HQQ, and Quanto. It requires no manual model downloads, offers concurrency, streaming responses, and supports various hardware and platforms. The server uses a `config.json` file for easy configuration management and provides detailed error handling and logging.
parea-sdk-py
Parea AI provides a SDK to evaluate & monitor AI applications. It allows users to test, evaluate, and monitor their AI models by defining and running experiments. The SDK also enables logging and observability for AI applications, as well as deploying prompts to facilitate collaboration between engineers and subject-matter experts. Users can automatically log calls to OpenAI and Anthropic, create hierarchical traces of their applications, and deploy prompts for integration into their applications.

FlashLearn
FlashLearn is a tool that provides a simple interface and orchestration for incorporating Agent LLMs into workflows and ETL pipelines. It allows data transformations, classifications, summarizations, rewriting, and custom multi-step tasks using LLMs. Each step and task has a compact JSON definition, making pipelines easy to understand and maintain. FlashLearn supports LiteLLM, Ollama, OpenAI, DeepSeek, and other OpenAI-compatible clients.

awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.

LightRAG
LightRAG is a repository hosting the code for LightRAG, a system that supports seamless integration of custom knowledge graphs, Oracle Database 23ai, Neo4J for storage, and multiple file types. It includes features like entity deletion, batch insert, incremental insert, and graph visualization. LightRAG provides an API server implementation for RESTful API access to RAG operations, allowing users to interact with it through HTTP requests. The repository also includes evaluation scripts, code for reproducing results, and a comprehensive code structure.
concierge
Concierge AI is a tool that implements the Model Context Protocol (MCP) to connect AI agents to tools in a standardized way. It ensures deterministic results and reliable tool invocation by progressively disclosing only relevant tools. Users can scaffold new projects or wrap existing MCP servers easily. Concierge works at the MCP protocol level, dynamically changing which tools are returned based on the current workflow step. It allows users to group tools into steps, define transitions, share state between steps, enable semantic search, and run over HTTP. The tool offers features like progressive disclosure, enforced tool ordering, shared state, semantic search, protocol compatibility, session isolation, multiple transports, and a scaffolding CLI for quick project setup.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.
For similar tasks
deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
discourse-ai
Discourse AI is a plugin for the Discourse forum software that uses artificial intelligence to improve the user experience. It can automatically generate content, moderate posts, and answer questions. This can free up moderators and administrators to focus on other tasks, and it can help to create a more engaging and informative community.

Gemini-API
Gemini-API is a reverse-engineered asynchronous Python wrapper for Google Gemini web app (formerly Bard). It provides features like persistent cookies, ImageFx support, extension support, classified outputs, official flavor, and asynchronous operation. The tool allows users to generate contents from text or images, have conversations across multiple turns, retrieve images in response, generate images with ImageFx, save images to local files, use Gemini extensions, check and switch reply candidates, and control log level.
genai-for-marketing
This repository provides a deployment guide for utilizing Google Cloud's Generative AI tools in marketing scenarios. It includes step-by-step instructions, examples of crafting marketing materials, and supplementary Jupyter notebooks. The demos cover marketing insights, audience analysis, trendspotting, content search, content generation, and workspace integration. Users can access and visualize marketing data, analyze trends, improve search experience, and generate compelling content. The repository structure includes backend APIs, frontend code, sample notebooks, templates, and installation scripts.
generative-ai-dart
The Google Generative AI SDK for Dart enables developers to utilize cutting-edge Large Language Models (LLMs) for creating language applications. It provides access to the Gemini API for generating content using state-of-the-art models. Developers can integrate the SDK into their Dart or Flutter applications to leverage powerful AI capabilities. It is recommended to use the SDK for server-side API calls to ensure the security of API keys and protect against potential key exposure in mobile or web apps.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.