
bot-on-anything
A large model-based chatbot builder that can quickly integrate AI models (including ChatGPT, Claude, Gemini) into various software applications (such as Telegram, Gmail, Slack, and websites).
Stars: 3981
The 'bot-on-anything' repository allows developers to integrate various AI models into messaging applications, enabling the creation of intelligent chatbots. By configuring the connections between models and applications, developers can easily switch between multiple channels within a project. The architecture is highly scalable, allowing the reuse of algorithmic capabilities for each new application and model integration. Supported models include ChatGPT, GPT-3.0, New Bing, and Google Bard, while supported applications range from terminals and web platforms to messaging apps like WeChat, Telegram, QQ, and more. The repository provides detailed instructions for setting up the environment, configuring the models and channels, and running the chatbot for various tasks across different messaging platforms.
README:



Bot on Anything is a powerful AI chatbot builder that allows you to quickly build chatbots and run them anywhere.
Developers can build and run an intelligent dialogue robot by selecting a connection between various AI large models and application channels with lightweight configuration. It supports easy switching between multiple paths within a single project. This architecture has strong scalability; each application can reuse existing model capabilities, and each new model can run on all application channels.
Models:
Applications:
- [x] Terminal
- [x] Web
- [x] Subscription Account
- [x] Service Account
- [x] Enterprise WeChat
- [x] Telegram
- [x] QQ
- [x] DingTalk
- [x] Feishu
- [x] Gmail
- [x] Slack
Supports Linux, MacOS, and Windows systems, and Python must be installed. It is recommended to use Python version between 3.7.1 and 3.10.
Clone the project code and install dependencies:
git clone https://github.com/zhayujie/bot-on-anything
cd bot-on-anything/
pip3 install -r requirements.txtThe core configuration file is config.json, and a template file config-template.json is provided in the project, which can be copied to generate the final effective config.json file:
cp config-template.json config.jsonEach model and channel has its own configuration block, which together form a complete configuration file. The overall structure is as follows:
{
"model": {
"type" : "openai", # Selected AI model
"openai": {
# openAI configuration
}
},
"channel": {
"type": "slack", # Channel to be integrated
"slack": {
# slack configuration
},
"telegram": {
# telegram configuration
}
}
}The configuration file is divided into model and channel sections at the outermost level. The model section is for model configuration, where the type specifies which model to use; the channel section contains the configuration for application channels, and the type field specifies which application to integrate.
When using, you only need to change the type field under the model and channel configuration blocks to switch between any model and application, connecting different paths. Below, each model and application configuration and running process will be introduced in turn.
Run the following command in the project root directory, with the default channel being the terminal:
python3 app.pyThe default model is gpt-3.5-turbo. For details, refer to the official documentation. It also supports gpt-4.0, just modify the model type parameter.
pip3 install --upgrade openaiNote: The openai version needs to be above
0.27.0. If installation fails, you can first upgrade pip withpip3 install --upgrade pip.
{
"model": {
"type" : "chatgpt",
"openai": {
"api_key": "YOUR API KEY",
"model": "gpt-3.5-turbo", # Model name
"proxy": "http://127.0.0.1:7890", # Proxy address
"character_desc": "You are ChatGPT, a large language model trained by OpenAI, aimed at answering and solving any questions people have, and can communicate in multiple languages. When asked who you are, you should also tell the questioner that entering #clear_memory can start a new topic exploration. Entering draw xx can create a picture for you.",
"conversation_max_tokens": 1000, # Maximum number of characters in the reply, total for input and output
"temperature":0.75, # Entropy, between [0,1], the larger the value, the more random the selected candidate words, the more uncertain the reply, it is recommended to use either this or the top_p parameter, the greater the creativity task, the better, the smaller the precision task
"top_p":0.7, # Candidate word list. 0.7 means only considering the top 70% of candidate words, it is recommended to use either this or the temperature parameter
"frequency_penalty":0.0, # Between [-2,2], the larger this value, the more it reduces the repetition of words in the model's output, leaning towards producing different content
"presence_penalty":1.0, # Between [-2,2], the larger this value, the less restricted by the input, encouraging the model to generate new words not present in the input, leaning towards producing different content
}
}-
api_key: Fill in theOpenAI API KEYcreated when registering your account. -
model: Model name, currently supportsgpt-3.5-turbo,gpt-4,gpt-4-32k(the gpt-4 API is not yet open). -
proxy: The address of the proxy client, refer to #56 for details. -
character_desc: This configuration saves a piece of text you say to ChatGPT, and it will remember this text as its setting; you can customize any personality for it. -
max_history_num[optional]: Maximum memory length of the conversation, exceeding this length will clear the previous memory.
{
"model": {
"type" : "linkai",
"linkai": {
"api_key": "",
"api_base": "https://api.link-ai.tech",
"app_code": "",
"model": "",
"conversation_max_tokens": 1000,
"temperature":0.75,
"top_p":0.7,
"frequency_penalty":0.0,
"presence_penalty":1.0,
"character_desc": "You are an intelligent assistant."
},
}-
api_key: The key for calling the LinkAI service, which can be created in the console. -
app_code: The code for the LinkAI application or workflow, optional, refer to Application Creation. -
model: Supports common models from both domestic and international sources, refer to Model List. It can be left blank, and the default model of the application can be modified in the LinKAI platform. - Other parameters have the same meaning as those in the ChatGPT model.
The application that starts by default in the configuration template is the terminal, which requires no additional configuration. You can start the program by executing python3 app.py directly in the project directory. Users interact with the dialogue model through command line input, and it supports streaming response effects.

Contributor: RegimenArsenic
Dependencies
pip3 install PyJWT flask flask_socketioConfiguration
"channel": {
"type": "http",
"http": {
"http_auth_secret_key": "6d25a684-9558-11e9-aa94-efccd7a0659b", // JWT authentication secret key
"http_auth_password": "6.67428e-11", // Authentication password, just for personal use, a preliminary defense against others scanning ports and DDOS wasting tokens
"port": "80" // Port
}
}Run locally: After running python3 app.py, access http://127.0.0.1:80.
Run on a server: After deployment, access http://public domain or IP:port.
Requirements: A server and a subscription account.
Install the werobot dependency:
pip3 install werobot"channel": {
"type": "wechat_mp",
"wechat_mp": {
"token": "YOUR TOKEN", # Token value
"port": "8088" # Port the program listens on
}
}Run python3 app.py in the project directory. If the terminal displays the following, it indicates successful operation:
[INFO][2023-02-16 01:39:53][app.py:12] - [INIT] load config: ...
[INFO][2023-02-16 01:39:53][wechat_mp_channel.py:25] - [WX_Public] Wechat Public account service start!
Bottle v0.12.23 server starting up (using AutoServer())...
Listening on http://127.0.0.1:8088/
Hit Ctrl-C to quit.
Go to the personal subscription account in the WeChat Official Platform and enable server configuration:

Server Address (URL) Configuration: If you can access the Python program on the server through the configured URL in the browser (default listening on port 8088), it indicates that the configuration is valid. Since the subscription account can only configure ports 80/443, you can modify the configuration to listen directly on port 80 (requires sudo permissions) or use reverse proxy forwarding (like nginx). According to the official documentation, you can fill in either the public IP or domain name here.
Token Configuration: Must be consistent with the token in the config.json configuration.
For detailed operation processes, refer to the official documentation.
After users follow the subscription account, they can send messages.
Note: After users send messages, the WeChat backend will push to the configured URL address, but if there is no reply within 5 seconds, the connection will be disconnected, and it will retry 3 times. However, the request to the OpenAI interface often takes more than 5 seconds. In this project, asynchronous and caching methods have optimized the 5-second timeout limit to 15 seconds, but exceeding this time will still not allow normal replies. At the same time, each time the connection is disconnected after 5 seconds, the web framework will report an error, which will be optimized later.
Requirements: A server and a certified service account.
In the enterprise service account, the 15-second timeout issue of the personal subscription account is resolved by first asynchronously accessing the OpenAI interface and then proactively pushing to the user through the customer service interface. The developer mode configuration of the service account is similar to that of the subscription account. For details, refer to the official documentation.
The config.json configuration for the enterprise service account only needs to change the type to wechat_mp_service, but the configuration block still reuses wechat_mp, and in addition, you need to add two configuration items: app_id and app_secret.
"channel": {
"type": "wechat_mp_service",
"wechat_mp": {
"token": "YOUR TOKEN", # Token value
"port": "8088", # Port the program listens on
"app_id": "YOUR APP ID", # App ID
"app_secret": "YOUR APP SECRET" # App secret
}
}Note: The server IP address must be configured in the "IP Whitelist"; otherwise, users will not receive proactively pushed messages.
Requirements: A PC or server (domestic network) and a QQ account.
Running the QQ bot requires additionally running a go-cqhttp program, which is responsible for receiving and sending QQ messages, while our bot-on-anything program is responsible for accessing OpenAI to generate dialogue content.
Download the corresponding machine program from the go-cqhttp Release, unzip it, and place the go-cqhttp binary file in our bot-on-anything/channel/qq directory. A config.yml configuration file is already prepared here; you only need to fill in the QQ account configuration (account-uin).
Use aiocqhttp to interact with go-cqhttp, execute the following command to install the dependency:
pip3 install aiocqhttpSimply change the type in the config.json configuration file's channel block to qq:
"channel": {
"type": "qq"
}First, go to the root directory of the bot-on-anything project and run in Terminal 1:
python3 app.py # This will listen on port 8080In the second step, open Terminal 2, navigate to the directory where cqhttp is located, and run:
cd channel/qq
./go-cqhttpNote:
- Currently, no keyword matching or group chat whitelist is set; all private chats will automatically reply, and in group chats, as long as you are @mentioned, it will also automatically reply.
- If you encounter exceptions such as account freezing, you can change the value of
protocolin thedevice.jsonfile in the same directory as go-cqhttp from 5 to 2, refer to this Issue.
Contributor: brucelt1993
6.1 Get Token
Applying for a Telegram bot can be easily found on Google; the important thing is to obtain the bot's token ID.
6.2 Dependency Installation
pip install pyTelegramBotAPI6.3 Configuration
"channel": {
"type": "telegram",
"telegram":{
"bot_token": "YOUR BOT TOKEN ID"
}
}Requirements: A server and a Gmail account.
Contributor: Simon
Follow the official documentation to create an APP password for your Google account, configure as below, then cheers!!!
"channel": {
"type": "gmail",
"gmail": {
"subject_keyword": ["bot", "@bot"],
"host_email": "[email protected]",
"host_password": "GMAIL ACCESS KEY"
}
}❉ No longer requires a server or public IP
Contributor: amaoo
Dependencies
pip3 install slack_boltConfiguration
"channel": {
"type": "slack",
"slack": {
"slack_bot_token": "xoxb-xxxx",
"slack_app_token": "xapp-xxxx"
}
}Set Bot Token Scope - OAuth & Permission
Write the Bot User OAuth Token into the configuration file slack_bot_token.
app_mentions:read
chat:write
Enable Socket Mode - Socket Mode
If you have not created an application-level token, you will be prompted to create one. Write the created token into the configuration file slack_app_token.
Event Subscription (Event Subscriptions) - Subscribe to Bot Events
app_mention
Reference Documentation
https://slack.dev/bolt-python/tutorial/getting-started
Requirements:
- Enterprise internal development robot.
Dependencies
pip3 install requests flaskConfiguration
"channel": {
"type": "dingtalk",
"dingtalk": {
"image_create_prefix": ["draw", "draw", "Draw"],
"port": "8081", # External port
"dingtalk_token": "xx", # Access token of the webhook address
"dingtalk_post_token": "xx", # Verification token carried in the header when DingTalk posts back messages
"dingtalk_secret": "xx" # Security encryption signature string in the group robot
}
}Reference Documentation:
- DingTalk Internal Robot Tutorial
- Custom Robot Access Documentation
- Enterprise Internal Development Robot Tutorial Documentation
Generate Robot
Address: https://open-dev.dingtalk.com/fe/app#/corp/robot Add a robot, set the server's outbound IP in the development management, and the message receiving address (the external address in the configuration, such as https://xx.xx.com:8081).
Dependencies
pip3 install requests flaskConfiguration
"channel": {
"type": "feishu",
"feishu": {
"image_create_prefix": [
"draw",
"draw",
"Draw"
],
"port": "8082", # External port
"app_id": "xxx", # Application app_id
"app_secret": "xxx", # Application Secret
"verification_token": "xxx" # Event subscription Verification Token
}
}Generate Robot
Address: https://open.feishu.cn/app/
- Add a self-built application for the enterprise.
- Enable permissions:
- im:message
- im:message.group_at_msg
- im:message.group_at_msg:readonly
- im:message.p2p_msg
- im:message.p2p_msg:readonly
- im:message:send_as_bot
- Subscribe to the menu to add events (receive messages v2.0) and configure the request address (the external address in the configuration, such as https://xx.xx.com:8081).
- In version management and publishing, launch the application, and the app will receive review information. After passing the review, add the self-built application in the group.
Requirements: A server and a certified Enterprise WeChat.
The config.json configuration for Enterprise WeChat only needs to change the type to wechat_com, with the default message receiving server URL: http://ip:8888/wechat.
"channel": {
"type": "wechat_com",
"wechat_com": {
"wechat_token": "YOUR TOKEN", # Token value
"port": "8888", # Port the program listens on
"app_id": "YOUR APP ID", # App ID
"app_secret": "YOUR APP SECRET", # App secret
"wechat_corp_id": "YOUR CORP ID",
"wechat_encoding_aes_key": "YOUR AES KEY"
}
}Note: The server IP address must be configured in the "Enterprise Trusted IP" list; otherwise, users will not receive proactively pushed messages.
Reference Documentation:
-
clear_memory_commands: Dialogue internal commands to actively clear previous memory, the string array can customize command aliases.- default: ["#clear_memory"]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bot-on-anything
Similar Open Source Tools
bot-on-anything
The 'bot-on-anything' repository allows developers to integrate various AI models into messaging applications, enabling the creation of intelligent chatbots. By configuring the connections between models and applications, developers can easily switch between multiple channels within a project. The architecture is highly scalable, allowing the reuse of algorithmic capabilities for each new application and model integration. Supported models include ChatGPT, GPT-3.0, New Bing, and Google Bard, while supported applications range from terminals and web platforms to messaging apps like WeChat, Telegram, QQ, and more. The repository provides detailed instructions for setting up the environment, configuring the models and channels, and running the chatbot for various tasks across different messaging platforms.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.
ZerePy
ZerePy is an open-source Python framework for deploying agents on X using OpenAI or Anthropic LLMs. It offers CLI interface, Twitter integration, and modular connection system. Users can fine-tune models for creative outputs and create agents with specific tasks. The tool requires Python 3.10+, Poetry 1.5+, and API keys for LLM, OpenAI, Anthropic, and X API.
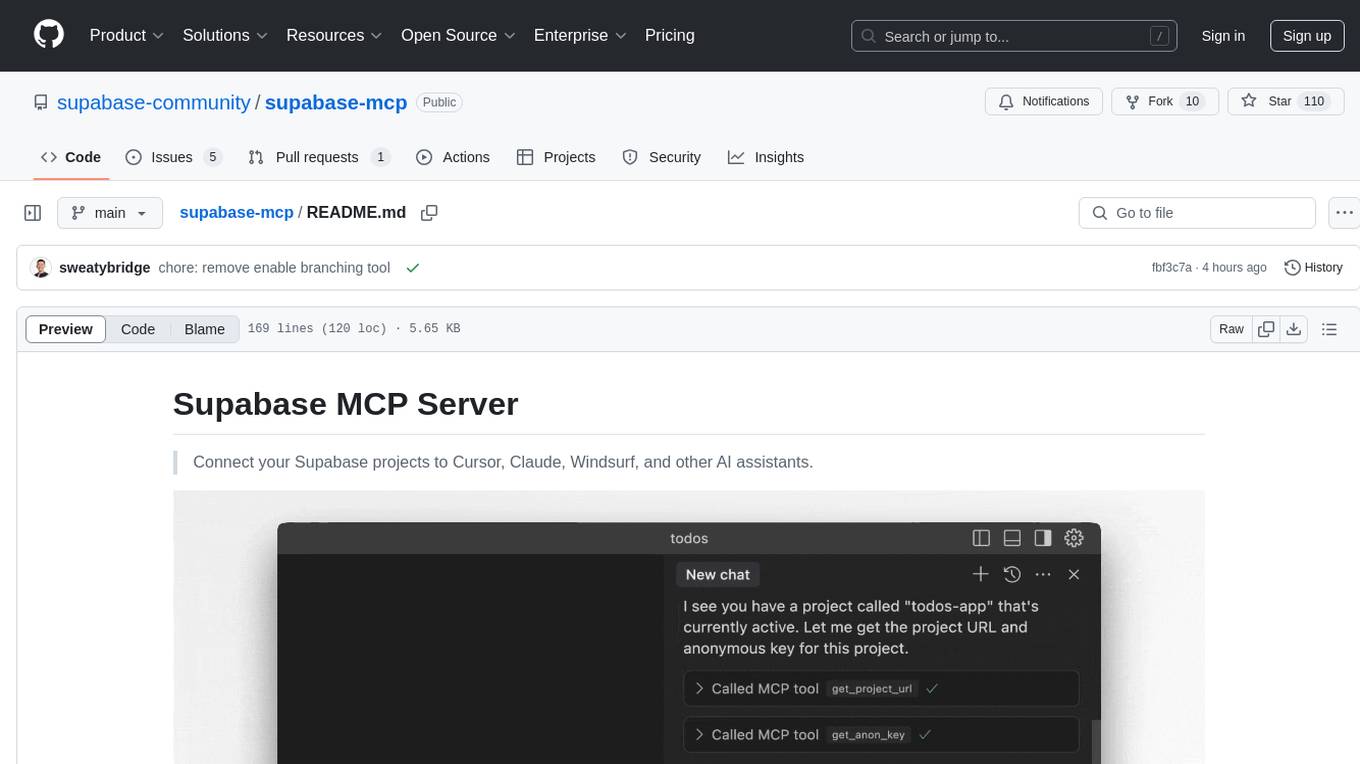
supabase-mcp
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.
call-center-ai
Call Center AI is an AI-powered call center solution that leverages Azure and OpenAI GPT. It is a proof of concept demonstrating the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI to build an automated call center solution. The project showcases features like accessing claims on a public website, customer conversation history, language change during conversation, bot interaction via phone number, multiple voice tones, lexicon understanding, todo list creation, customizable prompts, content filtering, GPT-4 Turbo for customer requests, specific data schema for claims, documentation database access, SMS report sending, conversation resumption, and more. The system architecture includes components like RAG AI Search, SMS gateway, call gateway, moderation, Cosmos DB, event broker, GPT-4 Turbo, Redis cache, translation service, and more. The tool can be deployed remotely using GitHub Actions and locally with prerequisites like Azure environment setup, configuration file creation, and resource hosting. Advanced usage includes custom training data with AI Search, prompt customization, language customization, moderation level customization, claim data schema customization, OpenAI compatible model usage for the LLM, and Twilio integration for SMS.

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

LLamaWorker
LLamaWorker is a HTTP API server developed to provide an OpenAI-compatible API for integrating Large Language Models (LLM) into applications. It supports multi-model configuration, streaming responses, text embedding, chat templates, automatic model release, function calls, API key authentication, and test UI. Users can switch models, complete chats and prompts, manage chat history, and generate tokens through the test UI. Additionally, LLamaWorker offers a Vulkan compiled version for download and provides function call templates for testing. The tool supports various backends and provides API endpoints for chat completion, prompt completion, embeddings, model information, model configuration, and model switching. A Gradio UI demo is also available for testing.
tuui
TUUI is a desktop MCP client designed for accelerating AI adoption through the Model Context Protocol (MCP) and enabling cross-vendor LLM API orchestration. It is an LLM chat desktop application based on MCP, created using AI-generated components with strict syntax checks and naming conventions. The tool integrates AI tools via MCP, orchestrates LLM APIs, supports automated application testing, TypeScript, multilingual, layout management, global state management, and offers quick support through the GitHub community and official documentation.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.

memobase
Memobase is a user profile-based memory system designed to enhance Generative AI applications by enabling them to remember, understand, and evolve with users. It provides structured user profiles, scalable profiling, easy integration with existing LLM stacks, batch processing for speed, and is production-ready. Users can manage users, insert data, get memory profiles, and track user preferences and behaviors. Memobase is ideal for applications that require user analysis, tracking, and personalized interactions.
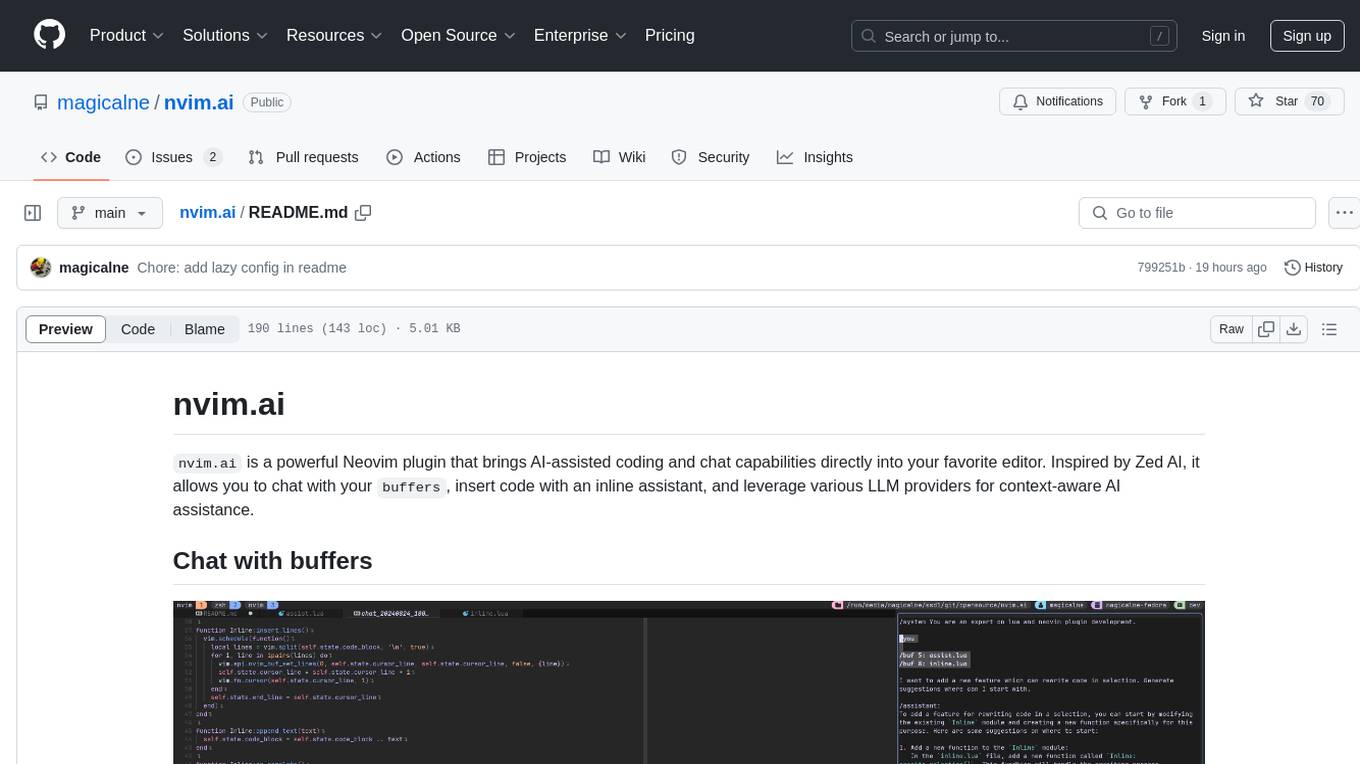
nvim.ai
nvim.ai is a powerful Neovim plugin that enables AI-assisted coding and chat capabilities within the editor. Users can chat with buffers, insert code with an inline assistant, and utilize various LLM providers for context-aware AI assistance. The plugin supports features like interacting with AI about code and documents, receiving relevant help based on current work, code insertion, code rewriting (Work in Progress), and integration with multiple LLM providers. Users can configure the plugin, add API keys to dotfiles, and integrate with nvim-cmp for command autocompletion. Keymaps are available for chat and inline assist functionalities. The chat dialog allows parsing content with keywords and supports roles like /system, /you, and /assistant. Context-aware assistance can be accessed through inline assist by inserting code blocks anywhere in the file.
agentlang
AgentLang is an open-source programming language and framework designed for solving complex tasks with the help of AI agents. It allows users to build business applications rapidly from high-level specifications, making it more efficient than traditional programming languages. The language is data-oriented and declarative, with a syntax that is intuitive and closer to natural languages. AgentLang introduces innovative concepts such as first-class AI agents, graph-based hierarchical data model, zero-trust programming, declarative dataflow, resolvers, interceptors, and entity-graph-database mapping.
concierge
Concierge AI is a tool that implements the Model Context Protocol (MCP) to connect AI agents to tools in a standardized way. It ensures deterministic results and reliable tool invocation by progressively disclosing only relevant tools. Users can scaffold new projects or wrap existing MCP servers easily. Concierge works at the MCP protocol level, dynamically changing which tools are returned based on the current workflow step. It allows users to group tools into steps, define transitions, share state between steps, enable semantic search, and run over HTTP. The tool offers features like progressive disclosure, enforced tool ordering, shared state, semantic search, protocol compatibility, session isolation, multiple transports, and a scaffolding CLI for quick project setup.
notebook-intelligence
Notebook Intelligence (NBI) is an AI coding assistant and extensible AI framework for JupyterLab. It greatly boosts the productivity of JupyterLab users with AI assistance by providing features such as code generation with inline chat, auto-complete, and chat interface. NBI supports various LLM Providers and AI Models, including local models from Ollama. Users can configure model provider and model options, remember GitHub Copilot login, and save configuration files. NBI seamlessly integrates with Model Context Protocol (MCP) servers, supporting both Standard Input/Output (stdio) and Server-Sent Events (SSE) transports. Users can easily add MCP servers to NBI, auto-approve tools, set environment variables, and group servers based on functionality. Additionally, NBI allows access to built-in tools from an MCP participant, enhancing the user experience and productivity.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.