Best AI tools for< Evaluate Data >
20 - AI tool Sites

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.

HappyML
HappyML is an AI tool designed to assist users in machine learning tasks. It provides a user-friendly interface for running machine learning algorithms without the need for complex coding. With HappyML, users can easily build, train, and deploy machine learning models for various applications. The tool offers a range of features such as data preprocessing, model evaluation, hyperparameter tuning, and model deployment. HappyML simplifies the machine learning process, making it accessible to users with varying levels of expertise.

Enhans AI Model Generator
Enhans AI Model Generator is an advanced AI tool designed to help users generate AI models efficiently. It utilizes cutting-edge algorithms and machine learning techniques to streamline the model creation process. With Enhans AI Model Generator, users can easily input their data, select the desired parameters, and obtain a customized AI model tailored to their specific needs. The tool is user-friendly and does not require extensive programming knowledge, making it accessible to a wide range of users, from beginners to experts in the field of AI.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
integrate.ai
integrate.ai is a platform that enables data and analytics providers to collaborate easily with enterprise data science teams without moving data. Powered by federated learning technology, the platform allows for efficient proof of concepts, data experimentation, infrastructure agnostic evaluations, collaborative data evaluations, and data governance controls. It supports various data science jobs such as match rate analysis, exploratory data analysis, correlation analysis, model performance analysis, feature importance & data influence, and model validation. The platform integrates with popular data science tools like Azure, Jupyter, Databricks, AWS, GCP, Snowflake, Pandas, PyTorch, MLflow, and scikit-learn.
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.
Labelbox
Labelbox is a data factory platform that empowers AI teams to manage data labeling, train models, and create better data with internet scale RLHF platform. It offers an all-in-one solution comprising tooling and services powered by a global community of domain experts. Labelbox operates a global data labeling infrastructure and operations for AI workloads, providing expert human network for data labeling in various domains. The platform also includes AI-assisted alignment for maximum efficiency, data curation, model training, and labeling services. Customers achieve breakthroughs with high-quality data through Labelbox.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
Census GPT
Census GPT is an AI-powered tool that provides data analysis and insights based on census data in the USA. It offers information on crime rates, demographics, income levels, education levels, and population statistics. Users can ask specific questions related to different areas and topics to get detailed answers and insights.

Ergodic - Kepler
Ergodic is an AI tool called Kepler that enables data-driven decisions for businesses. Kepler acts as an AI action engine, bridging the knowledge gap between business context and data to help optimize processes, identify opportunities, and mitigate risks. It goes beyond number crunching to build a digital version of the business, allowing users to create scenarios and evaluate outcomes. Kepler focuses on taking action directly, without the need for complex dashboards, providing insights on what needs to be done, why, and the potential outcomes. Ergodic aims to empower businesses with AI-driven solutions for strategic decision-making.
ThinkTask
ThinkTask is a project and team management tool that utilizes ChatGPT's capabilities to enhance productivity and streamline task management. It offers AI-generated reports and insights, AI usage tracking, Team Pulse for visualizing task types and status, Project Progress Table for monitoring project timelines and budgets, Task Insights for illustrating task interdependencies, and a comprehensive Overview for visualizing progress and managing dependencies. Additionally, ThinkTask features one-click auto-task creation with notes from ChatGPT, auto-tagging for task organization, and AI-suggested task assignments based on past experience and skills. It provides a unified workspace for notes, tasks, databases, collaboration, and customization.
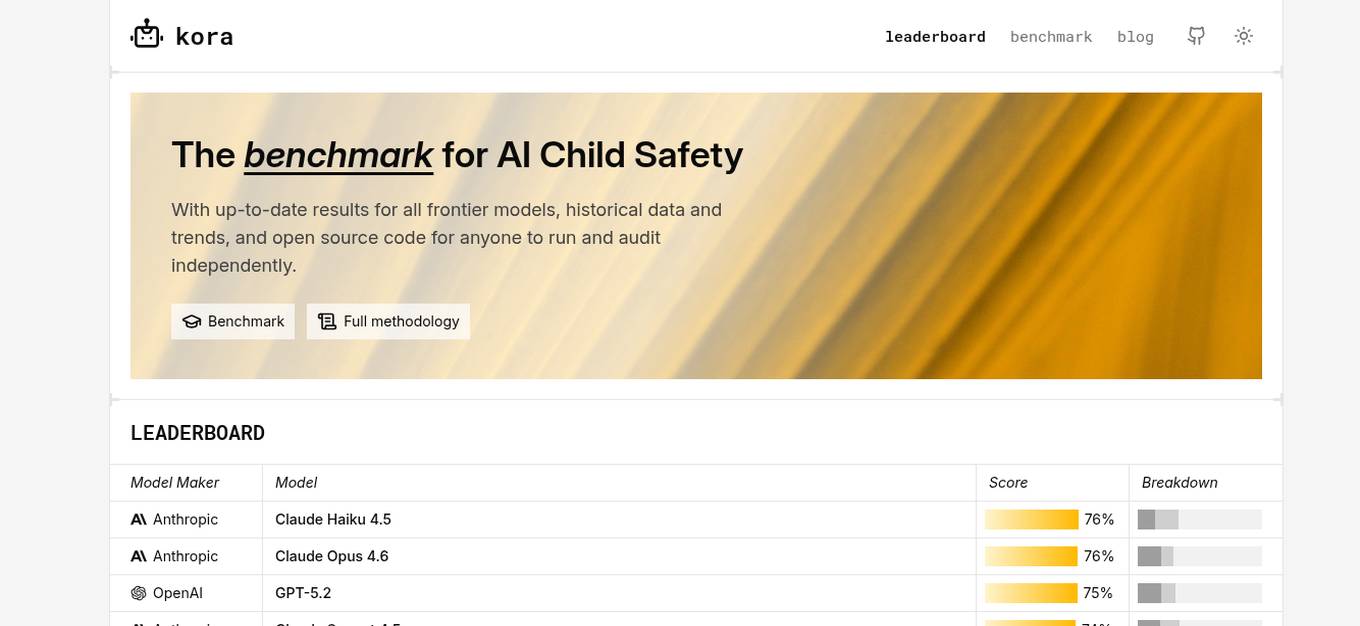
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.
2 - Open Source AI Tools

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.
20 - OpenAI Gpts

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.



LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.

ecosystem.Ai Use Case Designer v2
The use case designer is configured with the latest Data Science and Behavioral Social Science insights to guide you through the process of defining AI and Machine Learning use cases for the ecosystem.Ai platform.
Chronic Disease Indicators Expert
This chatbot answers questions about the CDC’s Chronic Disease Indicators dataset
AI Golf Statistics
PGA Tour Golf statistics expert, provides up-to-date data and analysis.
US Zip Intel
Your go-to source for in-depth US zip code demographics and statistics, with easy-to-download data tables.

Epidemic Global Insight System
Advanced epidemiology expert with AI-driven data integration and dynamic visualization tools.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.
Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.
Eureka Research Assessment and Improvement
AI tool for self-evaluating and enhancing scientific research capabilities.

CIM Analyst
In-depth CIM analysis with a structured rating scale, offering detailed business evaluations.
Academic Paper Evaluator
Enthusiastic about truth in academic papers, critical and analytical.

Scientific Insight
Scientific expert in evaluating articles using ROBINS-I and Cochrane tools