
Feishu-MCP
为 Cursor、Windsurf、Cline 和其他 AI 驱动的编码工具提供访问、编辑和结构化处理飞书文档的能力,基于 Model Context Protocol 服务器实现。
Stars: 159
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
README:

为 Cursor、Windsurf、Cline 和其他 AI 驱动的编码工具提供访问、编辑和结构化处理飞书文档的能力,基于 Model Context Protocol 服务器实现。
本项目让 AI 编码工具能够直接获取和理解飞书文档的结构化内容,显著提升文档处理的智能化和效率。
完整覆盖飞书文档的真实使用流程,助你高效利用文档资源:
- 文件夹目录获取:快速获取和浏览飞书文档文件夹下的所有文档,便于整体管理和查找。
- 内容获取与理解:支持结构化、分块、富文本等多维度内容读取,AI 能精准理解文档上下文。
- 智能创建与编辑:可自动创建新文档、批量生成和编辑内容,满足多样化写作需求。
- 高效检索与搜索:内置关键字搜索,帮助你在大量文档中迅速找到目标信息。
本项目让你在飞书文档的日常使用流程中实现智能获取、编辑和搜索,提升内容处理效率和体验。
你可以通过以下视频了解 MCP 的实际使用效果和操作流程:


⭐ Star 本项目,第一时间获取最新功能和重要更新! 关注项目可以让你不错过任何新特性、修复和优化,助你持续高效使用。你的支持也将帮助我们更好地完善和发展项目。⭐
| 功能类别 | 工具名称 | 描述 | 使用场景 | 状态 |
|---|---|---|---|---|
| 文档管理 | create_feishu_document |
创建新的飞书文档 | 从零开始创建文档 | ✅ 已完成 |
get_feishu_document_info |
获取文档基本信息 | 验证文档存在性和权限 | ✅ 已完成 | |
get_feishu_document_blocks |
获取文档块结构 | 了解文档层级结构 | ✅ 已完成 | |
| 内容编辑 | batch_create_feishu_blocks |
批量创建多个块 | 高效创建连续内容 | ✅ 已完成 |
update_feishu_block_text |
更新块文本内容 | 修改现有内容 | ✅ 已完成 | |
delete_feishu_document_blocks |
删除文档块 | 清理和重构文档内容 | ✅ 已完成 | |
| 文件夹管理 | get_feishu_folder_files |
获取文件夹文件列表 | 浏览文件夹内容 | ✅ 已完成 |
create_feishu_folder |
创建新文件夹 | 组织文档结构 | ✅ 已完成 | |
| 搜索功能 | search_feishu_documents |
搜索文档 | 查找特定内容 | ✅ 已完成 |
| 工具功能 | convert_feishu_wiki_to_document_id |
Wiki链接转换 | 将Wiki链接转为文档ID | ✅ 已完成 |
get_feishu_image_resource |
获取图片资源 | 下载文档中的图片 | ✅ 已完成 | |
get_feishu_whiteboard_content |
获取画板内容 | 获取画板中的图形元素和结构(流程图、思维导图等) | ✅ 已完成 | |
| 高级功能 | create_feishu_table |
创建和编辑表格 | 结构化数据展示 | ✅ 已完成 |
| 流程图插入 | 支持流程图和思维导图 | 流程梳理和可视化 | ✅ 已完成 | |
| 图片插入 | upload_and_bind_image_to_block |
支持插入本地和远程图片 | 修改文档内容 | ✅ 已完成 |
| 公式支持 | 支持数学公式 | 学术和技术文档 | ✅ 已完成 |
- 文本样式:粗体、斜体、下划线、删除线、行内代码
- 文本颜色:灰色、棕色、橙色、黄色、绿色、蓝色、紫色
- 对齐方式:左对齐、居中、右对齐
- 标题级别:支持1-9级标题
- 代码块:支持多种编程语言语法高亮
- 列表:有序列表(编号)、无序列表(项目符号)
- 图片:支持本地图片和网络图片
- 公式:在文本块中插入数学公式,支持LaTeX语法
- mermaid图表:支持流程图、时序图、思维导图、类图、饼图等等
- 表格:支持创建多行列表格,单元格可包含文本、标题、列表、代码块等多种内容类型
-
精简工具集:21个工具 → 13个工具,移除冗余,聚焦核心功能0.0.15 ✅ -
优化描述:7000+ tokens → 3000+ tokens,简化提示,节省请求token0.0.15 ✅ -
批量增强:新增批量更新、批量图片上传,单次操作效率提升50%0.0.15 ✅ - 流程优化:减少多步调用,实现一键完成复杂任务
-
支持多种凭证类型:包括 tenant_access_token和 user_access_token,满足不同场景下的认证需求(飞书应用配置发生变更) 0.0.16 ✅。 - 支持cursor用户登录:方便在cursor平台用户认证
-
支持mermaid图表:流程图、时序图等等,丰富文档内容0.1.11 ✅ -
支持表格创建:创建包含各种块类型的复杂表格,支持样式控制0.1.2 ✅
关于如何创建飞书应用和获取应用凭证的说明可以在官方教程找到。
详细的飞书应用配置步骤:有关注册飞书应用、配置权限、添加文档访问权限的详细指南,请参阅 手把手教程 FEISHU_CONFIG.md。
npx feishu-mcp@latest --feishu-app-id=<你的飞书应用ID> --feishu-app-secret=<你的飞书应用密钥>已发布到 Smithery 平台,可访问: https://smithery.ai/server/@cso1z/feishu-mcp
本项目采用主分支(main)+功能分支(feature/xxx)协作模式:
-
main
稳定主线分支,始终保持可用、可部署状态。所有已验证和正式发布的功能都会合并到 main 分支。 -
multi-user-token
多用户隔离与按用户授权的 Feishu Token 获取功能开发分支。该分支支持 userKey 参数、按用户获取和缓存 Token、自定义 Token 服务等高级特性,适用于需要多用户隔离和授权场景的开发与测试。
⚠️ 该分支为 beta 版本,功能更新相较 main 分支可能会有延后。如有相关需求请在 issue 区留言,我会优先同步最新功能到该分支。
-
克隆仓库
git clone https://github.com/cso1z/Feishu-MCP.git cd Feishu-MCP -
安装依赖
pnpm install
-
配置环境变量(复制一份.env.example保存为.env文件)
macOS/Linux:
cp .env.example .env
Windows:
copy .env.example .env -
编辑 .env 文件 在项目根目录下找到并用任意文本编辑器打开
.env文件,填写你的飞书应用凭证:FEISHU_APP_ID=cli_xxxxx FEISHU_APP_SECRET=xxxxx PORT=3333
-
运行服务器
pnpm run dev
| 变量名 | 必需 | 描述 | 默认值 |
|---|---|---|---|
FEISHU_APP_ID |
✅ | 飞书应用 ID | - |
FEISHU_APP_SECRET |
✅ | 飞书应用密钥 | - |
PORT |
❌ | 服务器端口 | 3333 |
FEISHU_AUTH_TYPE |
❌ | 认证凭证类型,建议本地运行时使用 user(用户级,需OAuth授权),云端/生产环境使用 tenant(应用级,默认) |
tenant |
FEISHU_TOKEN_ENDPOINT |
❌ | 获取 token 的接口地址,仅当自定义 token 管理时需要 | http://localhost:3333/getToken |
注意:
- 只有本地运行服务时支持
user凭证,否则需配置FEISHU_TOKEN_ENDPOINT,自行实现 token 获取与管理(可参考callbackService、feishuAuthService)。FEISHU_TOKEN_ENDPOINT接口参数:client_id,client_secret,token_type(可选,tenant/user);返回参数:access_token,needAuth,url(需授权时),expires_in(单位:s)。
| 参数 | 描述 | 默认值 |
|---|---|---|
--port |
服务器监听端口 | 3333 |
--log-level |
日志级别 (debug/info/log/warn/error/none) | info |
--feishu-app-id |
飞书应用 ID | - |
--feishu-app-secret |
飞书应用密钥 | - |
--feishu-base-url |
飞书API基础URL | https://open.feishu.cn/open-apis |
--cache-enabled |
是否启用缓存 | true |
--cache-ttl |
缓存生存时间(秒) | 3600 |
--stdio |
命令模式运行 | - |
--help |
显示帮助菜单 | - |
--version |
显示版本号 | - |
{
"mcpServers": {
"feishu-mcp": {
"command": "npx",
"args": ["-y", "feishu-mcp", "--stdio"],
"env": {
"FEISHU_APP_ID": "<你的飞书应用ID>",
"FEISHU_APP_SECRET": "<你的飞书应用密钥>"
}
},
"feishu_local": {
"url": "http://localhost:3333/sse"
}
}
}-
新建文档时,建议主动提供飞书文件夹 token(可为具体文件夹或根文件夹),这样可以更高效地定位和管理文档。如果不确定具体的子文件夹,可以让LLM自动在你指定的文件夹下查找最合适的子目录来新建文档。
如何获取文件夹 token? 打开飞书文件夹页面,复制链接(如
https://.../drive/folder/xxxxxxxxxxxxxxxxxxxxxx),token 就是链接最后的那一串字符(如xxxxxxxxxxxxxxxxxxxxxx,请勿泄露真实 token)。 -
本地运行 MCP 时,图片路径既支持本地绝对路径,也支持 http/https 网络图片;如在服务器环境,仅支持网络图片链接(由于cursor调用mcp时参数长度限制,暂不支持直接上传图片文件本体,请使用图片路径或链接方式上传)。
-
在文本块中可以混合使用普通文本和公式元素。公式使用LaTeX语法,如:
1+2=3、\frac{a}{b}、\sqrt{x}等。支持在同一文本块中包含多个公式和普通文本。
先对照配置问题查看: 手把手教程 FEISHU_CONFIG.md。
- 检查应用权限:确保应用已获得必要的文档访问权限
- 验证文档授权:确认目标文档已授权给应用或应用所在的群组
- 检查可用范围:确保应用发布版本的可用范围包含文档所有者
- 获取token:自建应用获取 app_access_token
- 使用第1步获取的token,验证是否有权限访问该文档:获取文档基本信息
如果这个项目帮助到了你,请考虑:
- ⭐ 给项目一个 Star
- 🐛 报告 Bug 和问题
- 💡 提出新功能建议
- 📖 改进文档
- 🔀 提交 Pull Request
你的支持是我们前进的动力!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Feishu-MCP
Similar Open Source Tools
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.
BlueLM
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.
jimeng-free-api-all
Jimeng AI Free API is a reverse-engineered API server that encapsulates Jimeng AI's image and video generation capabilities into OpenAI-compatible API interfaces. It supports the latest jimeng-5.0-preview, jimeng-4.6 text-to-image models, Seedance 2.0 multi-image intelligent video generation, zero-configuration deployment, and multi-token support. The API is fully compatible with OpenAI API format, seamlessly integrating with existing clients and supporting multiple session IDs for polling usage.
ppt-master
PPT Master is an AI-driven intelligent visual content generation system that converts source documents into high-quality SVG content through multi-role collaboration, supporting various formats such as presentation slides, social media posts, and marketing posters. It provides tools for PDF conversion, SVG post-processing, and PPTX export. Users can interact with AI editors to create content by describing their ideas. The system offers various AI roles for different tasks and provides a comprehensive documentation guide for workflow, design guidelines, canvas formats, image embedding best practices, chart templates, quick references, role definitions, tool usage instructions, example projects, and project workspace structure. Users can contribute to the project by enhancing design templates, chart components, documentation, bug reports, and feature suggestions. The project is open-source under the MIT License.
lingti-bot
lingti-bot is an AI Bot platform that integrates MCP Server, multi-platform message gateway, rich toolset, intelligent conversation, and voice interaction. It offers core advantages like zero-dependency deployment with a single 30MB binary file, cloud relay support for quick integration with enterprise WeChat/WeChat Official Account, built-in browser automation with CDP protocol control, 75+ MCP tools covering various scenarios, native support for Chinese platforms like DingTalk, Feishu, enterprise WeChat, WeChat Official Account, and more. It is embeddable, supports multiple AI backends like Claude, DeepSeek, Kimi, MiniMax, and Gemini, and allows access from platforms like DingTalk, Feishu, enterprise WeChat, WeChat Official Account, Slack, Telegram, and Discord. The bot is designed with simplicity as the highest design principle, focusing on zero-dependency deployment, embeddability, plain text output, code restraint, and cloud relay support.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.
Unity-Skills
UnitySkills is an AI-driven Unity editor automation engine based on REST API. It allows AI to directly control Unity scenes through Skills. The tool offers extreme efficiency with Result Truncation and SKILL.md slimming, a versatile tool library with 282 Skills supporting Batch operations, ensuring transactional safety with automatic rollback, multiple instance support for controlling multiple Unity projects simultaneously, deep integration with Antigravity Slash Commands for interactive experience, compatibility with popular AI terminals like Claude Code, Antigravity, Gemini CLI, and support for Cinemachine 2.x/3.x dual versions with advanced camera control features like MixingCamera, ClearShot, TargetGroup, and Spline.
tradecat
TradeCat is a comprehensive data analysis and trading platform designed for cryptocurrency, stock, and macroeconomic data. It offers a wide range of features including multi-market data collection, technical indicator modules, AI analysis, signal detection engine, Telegram bot integration, and more. The platform utilizes technologies like Python, TimescaleDB, TA-Lib, Pandas, NumPy, and various APIs to provide users with valuable insights and tools for trading decisions. With a modular architecture and detailed documentation, TradeCat aims to empower users in making informed trading decisions across different markets.
vscode-antigravity-cockpit
VS Code extension for monitoring Google Antigravity AI model quotas. It provides a webview dashboard, QuickPick mode, quota grouping, automatic grouping, renaming, card view, drag-and-drop sorting, status bar monitoring, threshold notifications, and privacy mode. Users can monitor quota status, remaining percentage, countdown, reset time, progress bar, and model capabilities. The extension supports local and authorized quota monitoring, multiple account authorization, and model wake-up scheduling. It also offers settings customization, user profile display, notifications, and group functionalities. Users can install the extension from the Open VSX Marketplace or via VSIX file. The source code can be built using Node.js and npm. The project is open-source under the MIT license.
bailing
Bailing is an open-source voice assistant designed for natural conversations with users. It combines Automatic Speech Recognition (ASR), Voice Activity Detection (VAD), Large Language Model (LLM), and Text-to-Speech (TTS) technologies to provide a high-quality voice interaction experience similar to GPT-4o. Bailing aims to achieve GPT-4o-like conversation effects without the need for GPU, making it suitable for various edge devices and low-resource environments. The project features efficient open-source models, modular design allowing for module replacement and upgrades, support for memory function, tool integration for information retrieval and task execution via voice commands, and efficient task management with progress tracking and reminders.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
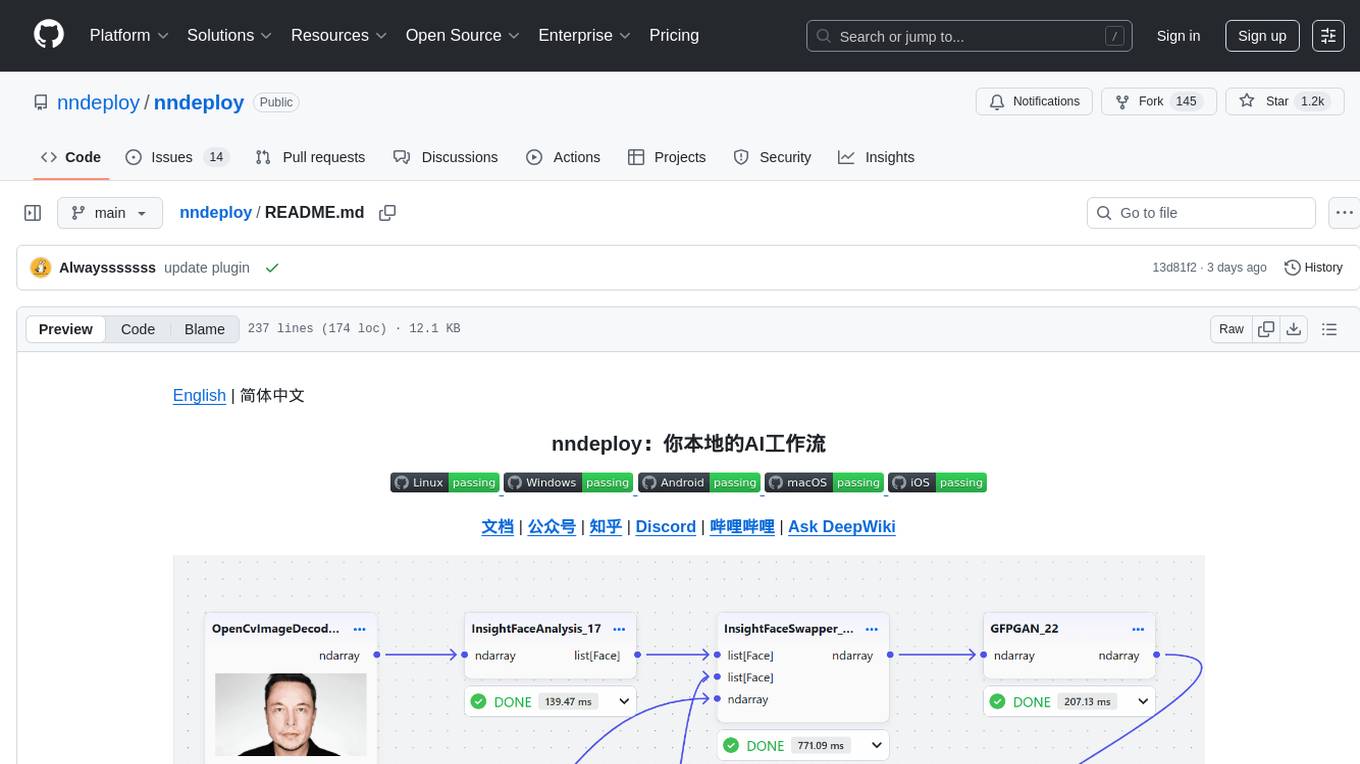
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.
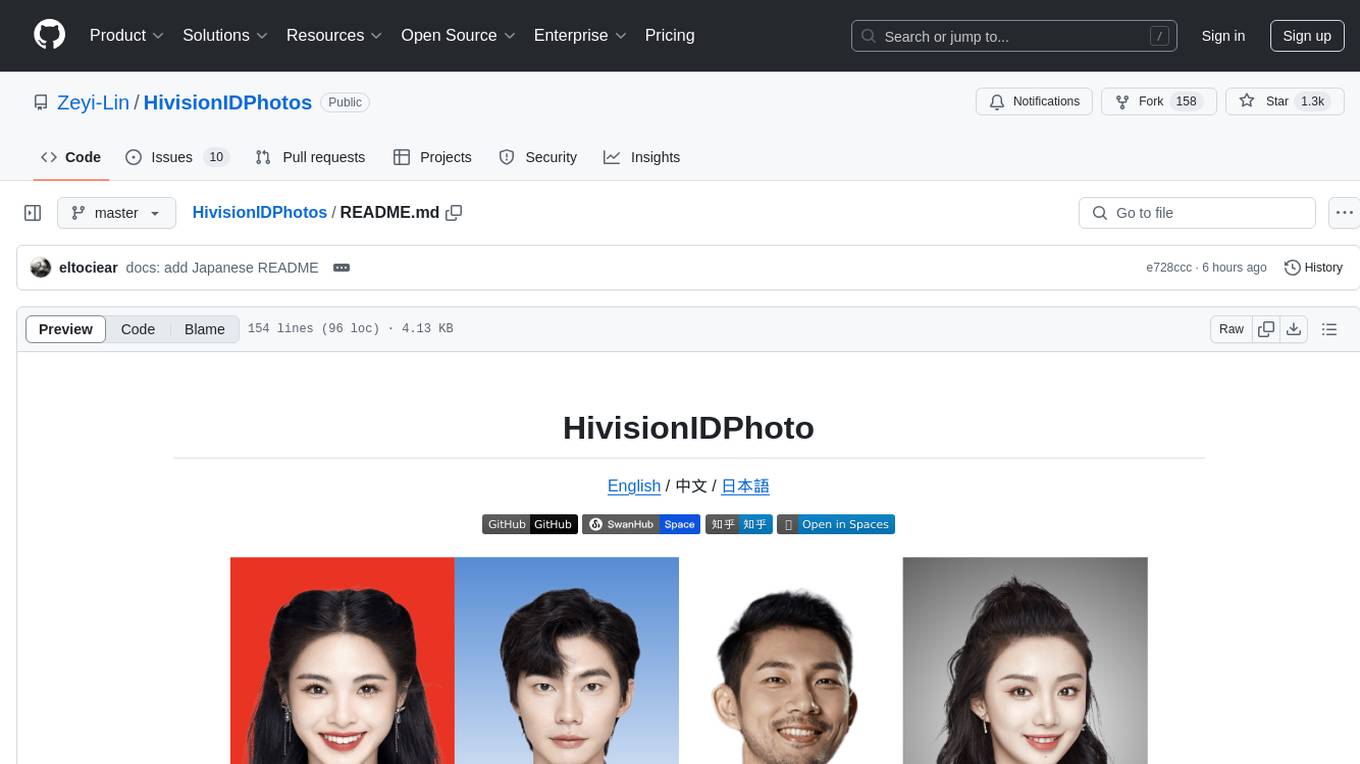
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
daily_stock_analysis
The daily_stock_analysis repository is an intelligent stock analysis system based on AI large models for A-share/Hong Kong stock/US stock selection. It automatically analyzes and pushes a 'decision dashboard' to WeChat Work/Feishu/Telegram/email daily. The system features multi-dimensional analysis, global market support, market review, AI backtesting validation, multi-channel notifications, and scheduled execution using GitHub Actions. It utilizes AI models like Gemini, OpenAI, DeepSeek, and data sources like AkShare, Tushare, Pytdx, Baostock, YFinance for analysis. The system includes built-in trading disciplines like risk warning, trend trading, precise entry/exit points, and checklist marking for conditions.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.
For similar tasks
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.