
DeepAI
为所有AI增加思考链能力
Stars: 121
DeepAI is a proxy server that enhances the interaction experience of large language models (LLMs) by integrating the 'thinking chain' process. It acts as an intermediary layer, receiving standard OpenAI API compatible requests, using independent 'thinking services' to generate reasoning processes, and then forwarding the enhanced requests to the LLM backend of your choice. This ensures that responses are not only generated by the LLM but also based on pre-inference analysis, resulting in more insightful and coherent answers. DeepAI supports seamless integration with applications designed for the OpenAI API, providing endpoints for '/v1/chat/completions' and '/v1/models', making it easy to integrate into existing applications. It offers features such as reasoning chain enhancement, flexible backend support, API key routing, weighted random selection, proxy support, comprehensive logging, and graceful shutdown.
README:
DeepAI 是一个代理服务器,通过整合“思考链”过程来增强大型语言模型(LLM)的交互体验。它充当中间层,接收标准 OpenAI API 兼容请求,利用独立的“思考服务”生成推理过程,然后将增强后的请求转发到您选择的 LLM 后端。这使得响应不仅由 LLM 生成,而且还基于预先的推理分析,从而产生更具洞察力和连贯性的回答。
-
OpenAI API 兼容性:
无缝集成为 OpenAI API 设计的应用程序。DeepAI 支持/v1/chat/completions和/v1/models端点,方便接入现有应用。 -
思考链增强:
在将用户请求发送给最终 LLM 之前,DeepAI 会自动调用预配置的“思考服务”,生成推理过程,并将该推理链(即 reasoning_content)合成到请求中,帮助 LLM 生成更具洞察力的回答。-
标准模式(standard) 仅使用推理链中的
reasoning_content字段,并允许将该内容以 SSE 流形式转发给客户端; -
完全模式(full) 则收集并使用
reasoning_content与content两部分(但完全模式下不显示思考链给客户端)。
-
标准模式(standard) 仅使用推理链中的
-
灵活的后端支持:
通过配置多个后端 LLM 服务(“渠道”)和思考服务,可根据需求自由切换或路由请求。 -
API 密钥路由:
API 密钥前缀中的渠道 ID 用于路由,将请求交给相应的后端渠道,便于进行细粒度的服务控制。 -
流式与标准响应:
支持聊天完成请求的流式和标准响应。流式模式下,思考服务生成的 SSE 流会原样转发(包含 reasoning_content 字段),便于客户端自行解析和展示。 -
加权随机选择:
实现了基于比例权重的随机选择算法,从多个思考服务中以概率的方式选出一个服务。权重越高,被选中的概率越大。 -
代理支持:
支持 HTTP 和 SOCKS5 代理,可用于连接思考服务和后端 LLM 渠道,适应各种网络环境。 -
全面日志记录与优雅关机:
提供详细的请求日志(包含唯一请求 ID、时间戳等)以及优雅的关机处理,便于监控和调试。
使用 R1 极速版生成思考后推送高速模型(如 grok2/3、gpt4o/4omini、Claude3.5s 等),可以节省一半以上的生成时间。同时,R1 输出不仅速度慢,成本也较高(“成本高”指的是后端输出可通过免费使用 Gemini 等模型实现)。
蒸馏版模型与特化版
| 模型名称 | 类型 | TPS |
|---|---|---|
| Qwen32b 蒸馏版 | 蒸馏版 | 40 TPS |
| Llama70b 蒸馏版 (非特化) | 蒸馏版 | 57 TPS |
| Llama70b 特化版 (Groq) | 特化版 | 280 TPS |
| Llama70b 特化版 (SambaNova) | 特化版 | 192 TPS |
| Llama70b 特化版 (Cerebras) | 特化版 | 1508 TPS |
DeepSeek系列
| 模型 | TPS |
|---|---|
| DeepSeek R1 | 24 TPS |
| DeepSeek V3 | 17 TPS |
主要竞争对手模型
| 模型名称 | TPS |
|---|---|
| claude-3.5-sonnet | 51 TPS |
| claude-3.5-haiku | 53 TPS |
| grok-2 | 62 TPS |
| command-r-plus | 60.41 TPS |
| command-r7b | 154 TPS |
| gpt-4o | 98 TPS |
| o3-mini-high | 119 TPS |
| o1 | 75 TPS |
| gemini-2.0-flash | 128 TPS |
| gemini-2.0-pro | 168.9 TPS |
| gemini-2.0-flash-thinking | 225 TPS |
从数据看,DeepSeek R1 和 V3 的TPS明显低于竞争对手。
R1 的输出经常设置上限为 8K,而大部分平台(包括官方和国内大厂)的蒸馏模型输出上限可能更低(2K或4K),这使得其在生成长代码或长文章时受限。同时R1 的上下文主要为 64K 或 32K
| 模型 | 上下文长度 | 输出上限 |
|---|---|---|
| R1(DeepSeek) | 32K / 64K | 8K |
| command-r-plus | 128K | 4K |
| command-r7b | 128K | 4K |
| o3-mini-high | 200K | 100K |
| o1 | 200K | 100K |
| gpt-4o | 128K | 16K |
| gemini-2.0-flash | 1000K | 8K |
| gemini-2.0-pro | 2000K | 8K |
| gemini-2.0-flash-thinking | 1000K | 64K |
| grok-2 | 131K | 131K |
| claude-3.5-sonnet | 200K | 8K |
| claude-3.5-haiku | 200K | 8K |
备注:大部分平台的蒸馏模型输出上限可能低至2K或4K,标准版往往也就给8K,这限制了长代码或长文章的生成。
| 模型 | 得分 |
|---|---|
| o3-mini-high | 82.74 |
| o1 | 69.69 |
| Claude 3.5S | 67.13 |
| DeepSeek R1 | 66.74 |
| gemini-2.0-pro | 63.49 |
| DeepSeek V3 | 61.77 |
| gpt-4o | 60.56 |
R1 本身并非最强模型,其基础为 V3,而 V3 与行业顶级 T1 模型存在较大差距。相比最强的非思考模型(Claude 3.5S,67.13),V3 差距约 6 分;与谷歌的 2.0 pro 也存在少量差距。而在综合评分上,V3 甚至未能超越 gemini-2.0-flash。
-
下载可执行文件:
请从 发布版本 下载适用于您平台的预编译二进制文件,或参考源码自行构建。或者从工件下载最新构建,但是可能BUG满天飞 -
配置:
基于仓库中提供的config-example.yaml模板创建config.yaml配置文件。
重要提示: 请正确配置您的思考服务和渠道。注意,目前配置模板中已移除未使用的字段,请参考下面的示例。 -
运行 DeepAI:
执行下载的二进制文件即可启动服务。
在命令行中执行(确保 config.yaml 与可执行文件在同一目录):
DeepAI-windows-amd64.exe同样在终端执行,配置文件放在相应目录中即可启动 HTTP 服务。
DeepAI 通过 config.yaml 文件进行配置,请参考示例模板:
https://github.com/BlueSkyXN/DeepAI/blob/main/config-example.yaml
-
thinking_services:
- 每个思考服务必须配置:
-
id:建议顺序指定 ID,便于记录和后续扩展。 -
name:描述性名称,可自定义。 -
mode:模式选择,"standard" 表示仅使用 reasoning_content(并支持 SSE 流展示思考链),"full" 表示收集所有内容,但不展示思考链。 -
model、base_url、api_path、api_key:构成调用思考服务的完整请求参数。 -
timeout:请求超时时间(秒)。 -
weight:加权随机的比例权重,数值越高,被选中的概率越大。 -
proxy:代理设置,留空则不使用代理。支持S5和HTTP。 -
reasoning_effort与reasoning_format:用于调整推理令牌数量和推理过程格式,选项见示例。 -
temperature:温度参数,用于覆盖默认值。 -
force_stop_deep_thinking:在标准模式下,如果检测到仅返回 content(且 reasoning_content 为空),是否立即停止思考链采集。 - 目前只兼容OpenAI标准的接口,不支持其他接口,请自行编程转换或者使用OneAPI/NewAPI项目
- 目前不兼容think标签的语法
-
- 每个思考服务必须配置:
-
channels:
- 定义后端 LLM 渠道,每个渠道由唯一的字符串键标识,必须配置:
-
name、base_url、api_path、timeout、proxy。 -
name: 渠道的描述性名称。 -
base_url: 目标 LLM API 的 Base URL。 -
timeout: 发送到此渠道的请求超时时间,单位秒。 -
proxy: 发送到此渠道的请求的可选代理 URL。 - 目前只兼容OpenAI标准的接口,不支持其他接口,请自行编程转换或者使用OneAPI/NewAPI项目
-
- 定义后端 LLM 渠道,每个渠道由唯一的字符串键标识,必须配置:
-
global:
- 配置日志和服务器相关参数,建议直接照抄示例。
向 DeepAI 发送聊天完成请求时,通过 Authorization 头中包含渠道 ID 来路由请求:
curl http://localhost:8888/v1/chat/completions \
-H "Authorization: Bearer deep-1-sk-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "command-r-plus", # 目标 LLM 渠道的模型
"messages": [{"role": "user", "content": "你好"}],
"stream": true
}'Authorization 头格式如下:
Bearer <api_provider>-<channel_id>-<your_real_api_key>
其中:
-
<api_provider>当前为deep(小写); -
<channel_id>为配置文件中定义的渠道 ID(例如 "1" 或 "2"); -
<your_real_api_key>为实际的 API 密钥。
例如,如果您的真实 API 密钥为 sk-12345678,且希望使用渠道 1,则完整格式为:
Bearer deep-1-sk-12345678
sequenceDiagram
participant 客户端 as Client
participant 代理服务 as DeepAI Proxy
participant 思考服务 as Thinking Service
participant LLM后端 as LLM Backend
客户端->>代理服务: 发送 API 请求
Note over 代理服务: 提取 API Key 和渠道信息
alt 非流式处理
代理服务->>思考服务: 请求生成思考链(非流式)
Note over 思考服务: 使用内部思考模型生成详细思考链
思考服务-->>代理服务: 返回完整思考链内容
else 流式处理
代理服务->>思考服务: 发起流式思考链请求
Note over 思考服务: 实时生成并发送思考链数据
思考服务-->>代理服务: 流式返回部分思考链数据
Note over 代理服务: 累计并处理流式思考链数据
end
Note over 代理服务: 合并原始请求与思考链信息,构造增强请求
代理服务->>LLM后端: 发送增强后的请求
LLM后端-->>代理服务: 返回处理结果
代理服务-->>客户端: 返回最终响应graph TD
A[主程序]
A1[加载配置]
A2[启动服务器]
A3[处理请求]
A4[思考服务交互]
A5[日志处理]
A6[关闭服务器]
A --> A1
A --> A2
A --> A6
A2 --> A3
A3 --> A4
A3 --> A5
A4 --> A41[加权随机思考服务]
A41 --> A411[标准模式]
A41 --> A412[全量模式]
A5 --> A51[请求日志]
A5 --> A52[响应日志]
A6 --> A61[关闭流程]
subgraph 思考服务
direction TB
A411[标准模式]
A412[全量模式]
end
subgraph 日志配置
direction LR
A51[请求日志]
A52[响应日志]
end
A1 -->|配置验证| A11[验证配置]
A2 -->|HTTP服务器处理| A21[启动HTTP服务器]
A3 -->|处理OpenAI请求| A31[处理聊天补全请求]
A3 -->|转发模型请求| A32[将请求转发到渠道]
A5 -->|调试| A53[打印请求和响应内容]flowchart TD
A[主程序入口]
B[加载配置文件\n(并验证配置)]
C[启动HTTP服务]
D[监听HTTP请求]
E[解析请求\n提取APIKey、ChannelID]
F[初始化日志记录]
G{请求类型判断}
H[/v1/models请求/]
I[/v1/chat/completions请求/]
J[直接转发请求到对应通道]
%% 对话请求处理
K[判断是否启用流式处理]
L[非流式处理流程]
M[调用思考服务获取思考链]
N[构造System提示\n(根据标准/全量模式)]
O[处理思考服务响应\n(解析思考链)]
P[合并思考链与用户对话\n构造增强请求]
Q[转发增强请求到通道]
%% 流式处理流程
R[流式处理流程]
S[启动StreamHandler]
T[实时接收思考链流数据]
U[实时将部分思考数据传给客户端]
V[构造最终合并请求]
W[流式转发最终请求到通道]
X[响应结果返回给客户端]
A --> B
B --> C
C --> D
D --> E
E --> F
F --> G
G -- "/v1/models" --> H
G -- "/v1/chat/completions" --> I
H --> J
J --> X
I --> K
K -- 非流式 --> L
K -- 流式 --> R
%% 非流式处理分支
L --> M
M --> N
N --> O
O --> P
P --> Q
Q --> X
%% 流式处理分支
R --> S
S --> T
T --> U
U --> V
V --> W
W --> XFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DeepAI
Similar Open Source Tools
DeepAI
DeepAI is a proxy server that enhances the interaction experience of large language models (LLMs) by integrating the 'thinking chain' process. It acts as an intermediary layer, receiving standard OpenAI API compatible requests, using independent 'thinking services' to generate reasoning processes, and then forwarding the enhanced requests to the LLM backend of your choice. This ensures that responses are not only generated by the LLM but also based on pre-inference analysis, resulting in more insightful and coherent answers. DeepAI supports seamless integration with applications designed for the OpenAI API, providing endpoints for '/v1/chat/completions' and '/v1/models', making it easy to integrate into existing applications. It offers features such as reasoning chain enhancement, flexible backend support, API key routing, weighted random selection, proxy support, comprehensive logging, and graceful shutdown.
BlueLM
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
SakuraLLM
SakuraLLM is a project focused on building large language models for Japanese to Chinese translation in the light novel and galgame domain. The models are based on open-source large models and are pre-trained and fine-tuned on general Japanese corpora and specific domains. The project aims to provide high-performance language models for galgame/light novel translation that are comparable to GPT3.5 and can be used offline. It also offers an API backend for running the models, compatible with the OpenAI API format. The project is experimental, with version 0.9 showing improvements in style, fluency, and accuracy over GPT-3.5.
kirara-ai
Kirara AI is a chatbot that supports mainstream large language models and chat platforms. It provides features such as image sending, keyword-triggered replies, multi-account support, personality settings, and support for various chat platforms like QQ, Telegram, Discord, and WeChat. The tool also supports HTTP server for Web API, popular large models like OpenAI and DeepSeek, plugin mechanism, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, custom workflows, web management interface, and built-in Frpc intranet penetration.
ppt-master
PPT Master is an AI-driven intelligent visual content generation system that converts source documents into high-quality SVG content through multi-role collaboration, supporting various formats such as presentation slides, social media posts, and marketing posters. It provides tools for PDF conversion, SVG post-processing, and PPTX export. Users can interact with AI editors to create content by describing their ideas. The system offers various AI roles for different tasks and provides a comprehensive documentation guide for workflow, design guidelines, canvas formats, image embedding best practices, chart templates, quick references, role definitions, tool usage instructions, example projects, and project workspace structure. Users can contribute to the project by enhancing design templates, chart components, documentation, bug reports, and feature suggestions. The project is open-source under the MIT License.
llmio
LLMIO is a Go-based LLM load balancing gateway that provides a unified REST API, weight scheduling, logging, and modern management interface for your LLM clients. It helps integrate different model capabilities from OpenAI, Anthropic, Gemini, and more in a single service. Features include unified API compatibility, weight scheduling with two strategies, visual management dashboard, rate and failure handling, and local persistence with SQLite. The tool supports multiple vendors' APIs and authentication methods, making it versatile for various AI model integrations.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
chatgpt-mirai-qq-bot
Kirara AI is a chatbot that supports mainstream language models and chat platforms. It features various functionalities such as image sending, keyword-triggered replies, multi-account support, content moderation, personality settings, and support for platforms like QQ, Telegram, Discord, and WeChat. It also offers HTTP server capabilities, plugin support, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, and custom workflows. The tool can be accessed via HTTP API for integration with other platforms.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.
For similar tasks
DeepAI
DeepAI is a proxy server that enhances the interaction experience of large language models (LLMs) by integrating the 'thinking chain' process. It acts as an intermediary layer, receiving standard OpenAI API compatible requests, using independent 'thinking services' to generate reasoning processes, and then forwarding the enhanced requests to the LLM backend of your choice. This ensures that responses are not only generated by the LLM but also based on pre-inference analysis, resulting in more insightful and coherent answers. DeepAI supports seamless integration with applications designed for the OpenAI API, providing endpoints for '/v1/chat/completions' and '/v1/models', making it easy to integrate into existing applications. It offers features such as reasoning chain enhancement, flexible backend support, API key routing, weighted random selection, proxy support, comprehensive logging, and graceful shutdown.
llm_steer
LLM Steer is a Python module designed to steer Large Language Models (LLMs) towards specific topics or subjects by adding steer vectors to different layers of the model. It enhances the model's capabilities, such as providing correct responses to logical puzzles. The tool should be used in conjunction with the transformers library. Users can add steering vectors to specific layers of the model with coefficients and text, retrieve applied steering vectors, and reset all steering vectors to the initial model. Advanced usage involves changing default parameters, but it may lead to the model outputting gibberish in most cases. The tool is meant for experimentation and can be used to enhance role-play characteristics in LLMs.
crewAI-tools
The crewAI Tools repository provides a guide for setting up tools for crewAI agents, enabling the creation of custom tools to enhance AI solutions. Tools play a crucial role in improving agent functionality. The guide explains how to equip agents with a range of tools and how to create new tools. Tools are designed to return strings for generating responses. There are two main methods for creating tools: subclassing BaseTool and using the tool decorator. Contributions to the toolset are encouraged, and the development setup includes steps for installing dependencies, activating the virtual environment, setting up pre-commit hooks, running tests, static type checking, packaging, and local installation. Enhance AI agent capabilities with advanced tooling.
open-responses
OpenResponses API provides enterprise-grade AI capabilities through a powerful API, simplifying development and deployment while ensuring complete data control. It offers automated tracing, integrated RAG for contextual information retrieval, pre-built tool integrations, self-hosted architecture, and an OpenAI-compatible interface. The toolkit addresses development challenges like feature gaps and integration complexity, as well as operational concerns such as data privacy and operational control. Engineering teams can benefit from improved productivity, production readiness, compliance confidence, and simplified architecture by choosing OpenResponses.
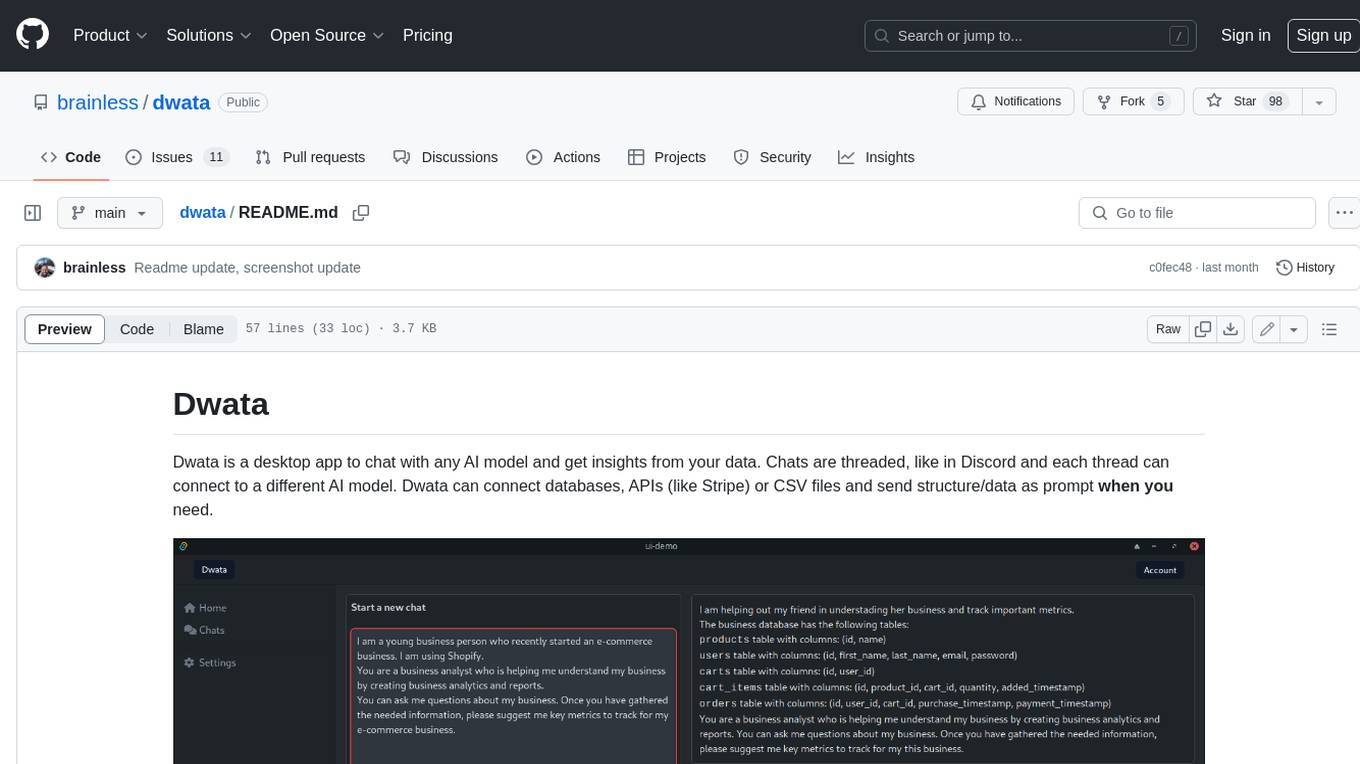
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

BambooAI
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.