
InternGPT
InternGPT (iGPT) is an open source demo platform where you can easily showcase your AI models. Now it supports DragGAN, ChatGPT, ImageBind, multimodal chat like GPT-4, SAM, interactive image editing, etc. Try it at igpt.opengvlab.com (支持DragGAN、ChatGPT、ImageBind、SAM的在线Demo系统)
Stars: 3179
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.
README:
The project is still under construction, we will continue to update it and welcome contributions/pull requests from the community.
![]()
 |
|

🤖💬 InternGPT [Paper]
InternGPT(short for iGPT) / InternChat(short for iChat) is pointing-language-driven visual interactive system, allowing you to interact with ChatGPT by clicking, dragging and drawing using a pointing device. The name InternGPT stands for interaction, nonverbal, and ChatGPT. Different from existing interactive systems that rely on pure language, by incorporating pointing instructions, iGPT significantly improves the efficiency of communication between users and chatbots, as well as the accuracy of chatbots in vision-centric tasks, especially in complicated visual scenarios. Additionally, in iGPT, an auxiliary control mechanism is used to improve the control capability of LLM, and a large vision-language model termed Husky is fine-tuned for high-quality multi-modal dialogue (impressing ChatGPT-3.5-turbo with 93.89% GPT-4 Quality).
InternGPT is online (see https://igpt.opengvlab.com). Let's try it!
[NOTE] It is possible that you are waiting in a lengthy queue. You can clone our repo and run it with your private GPU.
https://github.com/OpenGVLab/InternGPT/assets/13723743/529abde4-5dce-48de-bb38-0a0c199bb980
https://github.com/OpenGVLab/InternGPT/assets/13723743/bacf3e58-6c24-4c0f-8cf7-e0c4b8b3d2af
https://github.com/OpenGVLab/InternGPT/assets/13723743/8fd9112f-57d9-4871-a369-4e1929aa2593
-
(2023.06.19) We optimize the GPU memory usage when executing the tools. Please refer to Get Started.
-
(2023.06.19) We update the INSTALL.md which provides more detailed instructions for setting up environment.
-
(2023.05.31) It is with great regret that due to some emergency reasons, we have to suspend the online demo. If you want to experience all the features, please try them after deploying locally.
-
(2023.05.24) 🎉🎉🎉 We have supported the DragGAN! Please see the video demo for the usage. Let's try this awesome feauture: Demo. (我们现在支持了功能完全的DragGAN! 可以拖动、可以自定义图片,具体用法见video demo,复现的DragGAN代码在这里,在线demo在这里)
-
(2023.05.18) We have supported ImageBind. Please see the video demo for the usage.
-
(2023.05.15) The model_zoo including HuskyVQA has been released! Try it on your local machine!
-
(2023.05.15) Our code is also publicly available on Hugging Face! You can duplicate the repository and run it on your own GPUs.
Update:
(2023.05.24) We now support DragGAN. You can try it as follows:
- Click the button
New Image; - Click the image where blue denotes the start point and red denotes the end point;
- Notice that the number of blue points is the same as the number of red points. Then you can click the button
Drag It; - After processing, you will receive an edited image and a video that visualizes the editing process.
(2023.05.18) We now support ImageBind. If you want to generate a new image conditioned on audio, you can upload an audio file in advance:
- To generate a new image from a single audio file, you can send the message like:
"generate a real image from this audio"; - To generate a new image from audio and text, you can send the message like:
"generate a real image from this audio and {your prompt}"; - To generate a new image from audio and image, you need to upload an image and then send the message like:
"generate a new image from above image and audio".
Main features:
After uploading the image, you can have a multi-modal dialogue by sending messages like: "what is it in the image?" or "what is the background color of image?".
You also can interactively operate, edit or generate the image as follows:
- You can click the image and press the button
Pickto visualize the segmented region or press the buttonOCRto recognize the words at chosen position; - To remove the masked reigon in the image, you can send the message like:
"remove the masked region"; - To replace the masked reigon in the image, you can send the message like:
"replace the masked region with {your prompt}"; - To generate a new image, you can send the message like:
"generate a new image based on its segmentation describing {your prompt}" - To create a new image by your scribble, you should press button
Whiteboardand draw in the board. After drawing, you need to press the buttonSaveand send the message like:"generate a new image based on this scribble describing {your prompt}".
- [ ] Support VisionLLM
- [ ] Support Chinese
- [ ] Support MOSS
- [ ] More powerful foundation models based on InternImage and InternVideo
- [ ] More accurate interactive experience
- [ ] OpenMMLab toolkit
- [ ] Web page & code generation
- [ ] Support search engine
- [ ] Low cost deployment
- [x] Support DragGAN
- [x] Support ImageBind
- [x] Response verification for agent
- [x] Prompt optimization
- [x] User manual and video demo
- [x] Support voice assistant
- [x] Support click interaction
- [x] Interactive image editing
- [x] Interactive image generation
- [x] Interactive visual question answering
- [x] Segment anything
- [x] Image inpainting
- [x] Image caption
- [x] Image matting
- [x] Optical character recognition
- [x] Action recognition
- [x] Video caption
- [x] Video dense caption
- [x] Video highlight interpretation

Remove the masked object

Interactive image editing

Image generation

Interactive visual question answer

Interactive image generation
Video highlight interpretation

See INSTALL.md
👨🏫 Get Started
Running the following shell can start a gradio service for our basic features:
python -u app.py --load "HuskyVQA_cuda:0,SegmentAnything_cuda:0,ImageOCRRecognition_cuda:0" --port 3456 -eif you want to enable the voice assistant, please use openssl to generate the certificate:
mkdir certificate
openssl req -x509 -newkey rsa:4096 -keyout certificate/key.pem -out certificate/cert.pem -sha256 -days 365 -nodesand then run:
python -u app.py --load "HuskyVQA_cuda:0,SegmentAnything_cuda:0,ImageOCRRecognition_cuda:0" \
--port 3456 --https -eFor all features of our iGPT, you need to run:
python -u app.py \
--load "ImageOCRRecognition_cuda:0,Text2Image_cuda:0,SegmentAnything_cuda:0,ActionRecognition_cuda:0,VideoCaption_cuda:0,DenseCaption_cuda:0,ReplaceMaskedAnything_cuda:0,LDMInpainting_cuda:0,SegText2Image_cuda:0,ScribbleText2Image_cuda:0,Image2Scribble_cuda:0,Image2Canny_cuda:0,CannyText2Image_cuda:0,StyleGAN_cuda:0,Anything2Image_cuda:0,HuskyVQA_cuda:0" \
-p 3456 --https -eNotice that -e flag can save a lot of memory.
When you only want to try DragGAN, you just need to load StyleGAN and open the tab "DragGAN":
python -u app.py --load "StyleGAN_cuda:0" --tab "DragGAN" --port 3456 --https -eIn this situation, you can only use the functions of DragGAN, which frees you from some dependencies that you are not interested in.
This project is released under the Apache 2.0 license.
If you find this project useful in your research, please consider cite:
@article{2023interngpt,
title={InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language},
author={Liu, Zhaoyang and He, Yinan and Wang, Wenhai and Wang, Weiyun and Wang, Yi and Chen, Shoufa and Zhang, Qinglong and Lai, Zeqiang and Yang, Yang and Li, Qingyun and Yu, Jiashuo and others},
journal={arXiv preprint arXiv:2305.05662},
year={2023}
}Thanks to the open source of the following projects:
Hugging Face LangChain TaskMatrix SAM Stable Diffusion ControlNet InstructPix2Pix BLIP Latent Diffusion Models EasyOCR ImageBind DragGAN
Welcome to discuss with us and continuously improve the user experience of InternGPT.
If you want to join our WeChat group, please scan the following QR Code to add our assistant as a Wechat friend:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for InternGPT
Similar Open Source Tools
InternGPT
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together
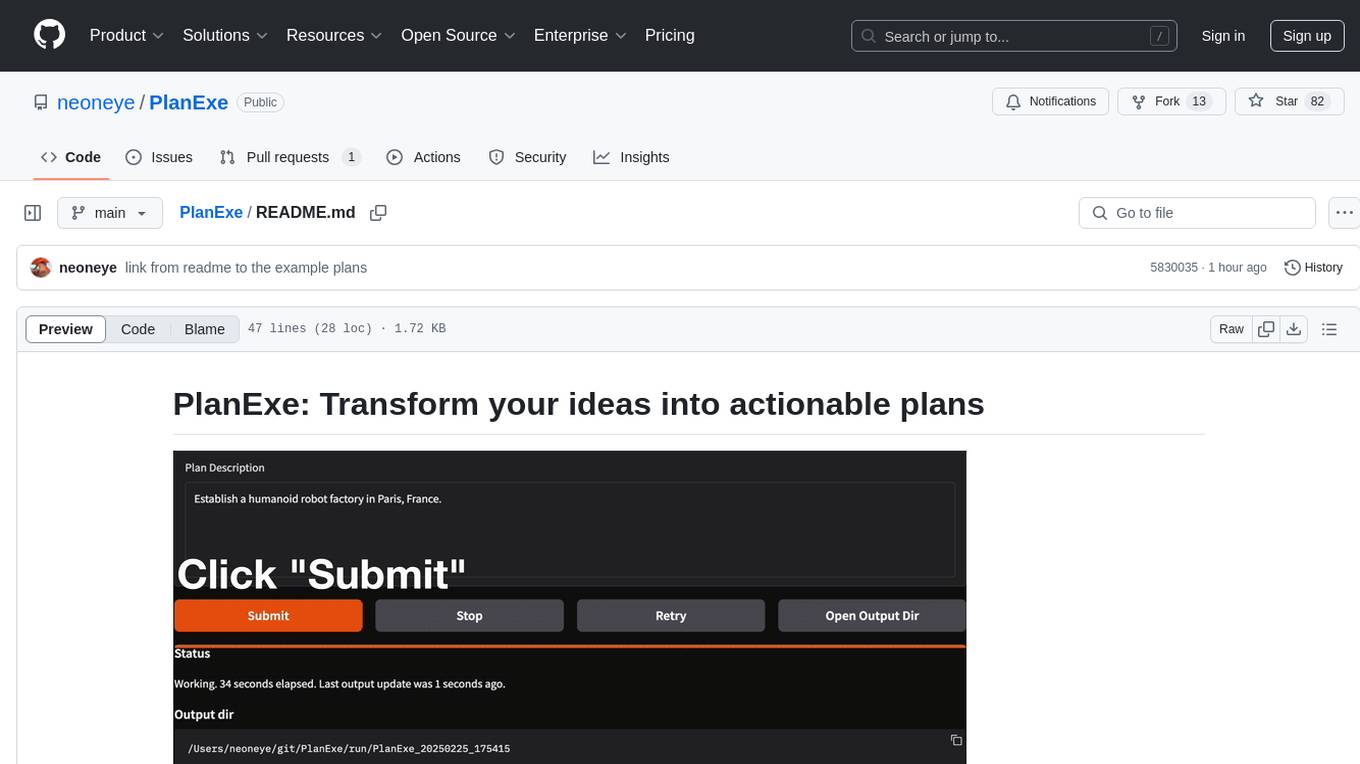
PlanExe
PlanExe is a planning AI tool that helps users generate detailed plans based on vague descriptions. It offers a Gradio-based web interface for easy input and output. Users can choose between running models in the cloud or locally on a high-end computer. The tool aims to provide a straightforward path to planning various tasks efficiently.
autonomous-intelligence
Tau is an autonomous robot project inspired by Pi.AI, designed for continual conversation with a single context. It features speech-based interaction, memory management, and integration with vision services. The project aims to create a local AI companion with personality, suitable for experimentation and development. Key components include long and immediate memory, speech-to-text and text-to-speech capabilities, and integration with Nvidia Jetson and Hailo vision services. Tau is open-source and encourages community contributions and experimentation.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.

Stable-Diffusion-Android
Stable Diffusion AI is an easy-to-use app for generating images from text or other images. It allows communication with servers powered by various AI technologies like AI Horde, Hugging Face Inference API, OpenAI, StabilityAI, and LocalDiffusion. The app supports Txt2Img and Img2Img modes, positive and negative prompts, dynamic size and sampling methods, unique seed input, and batch image generation. Users can also inpaint images, select faces from gallery or camera, and export images. The app offers settings for server URL, SD Model selection, auto-saving images, and clearing cache.
TileRT
TileRT is a project designed to serve large language models (LLMs) in ultra-low-latency scenarios. It aims to push the latency limits of LLMs without compromising model size or quality, enabling models with hundreds of billions of parameters to achieve millisecond-level time per output token. TileRT prioritizes responsiveness for applications like high-frequency trading, interactive AI, real-time decision-making, long-running agents, and AI-assisted coding. It introduces a tile-level runtime engine that dynamically reschedules computation, I/O, and communication across multiple devices to minimize idle time and improve hardware utilization. The project is actively evolving, with compiler techniques gradually shared with the community through TileLang and TileScale.
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
For similar tasks
InternGPT
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.
stable-diffusion-prompt-reader
A simple standalone viewer for reading prompt from Stable Diffusion generated image outside the webui. The tool supports macOS, Windows, and Linux, providing both GUI and CLI functionalities. Users can interact with the tool through drag and drop, copy prompt to clipboard, remove prompt from image, export prompt to text file, edit or import prompt to images, and more. It supports multiple formats including PNG, JPEG, WEBP, TXT, and various tools like A1111's webUI, Easy Diffusion, StableSwarmUI, Fooocus-MRE, NovelAI, InvokeAI, ComfyUI, Draw Things, and Naifu(4chan). Users can download the tool for different platforms and install it via Homebrew Cask or pip. The tool can be used to read, export, remove, and edit prompts from images, providing various modes and options for different tasks.
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.