Best AI tools for< Video Captioning >
20 - AI tool Sites
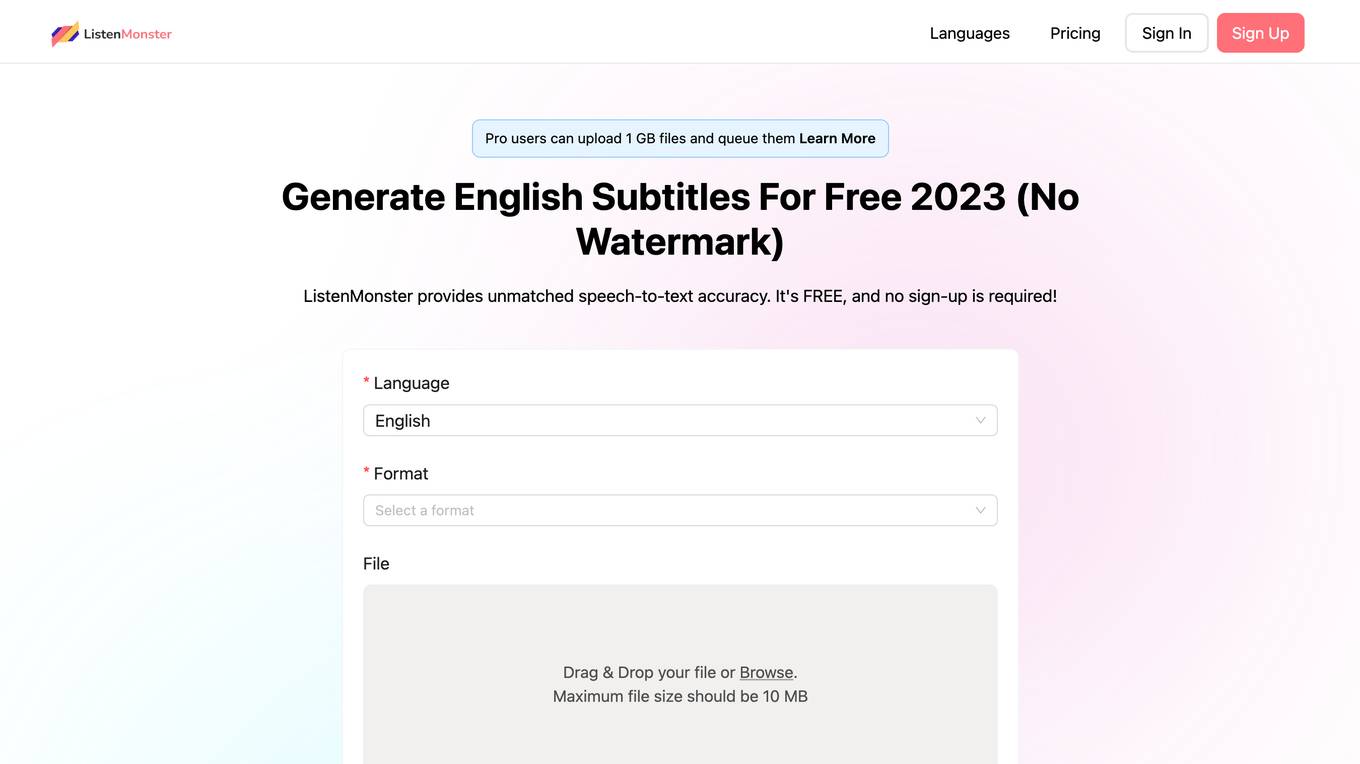
ListenMonster
ListenMonster is a free video caption generator tool that provides unmatched speech-to-text accuracy. It allows users to generate automatic subtitles in multiple languages, customize video captions, remove background noise, and export results in various formats. ListenMonster aims to offer high accuracy transcription at affordable prices, with instant results and support for 99 languages. The tool features a smart editor for easy customization, flexible export options, and automatic language detection. Subtitles are emphasized as a necessity in today's world, offering benefits such as global reach, SEO boost, accessibility, and content repurposing.
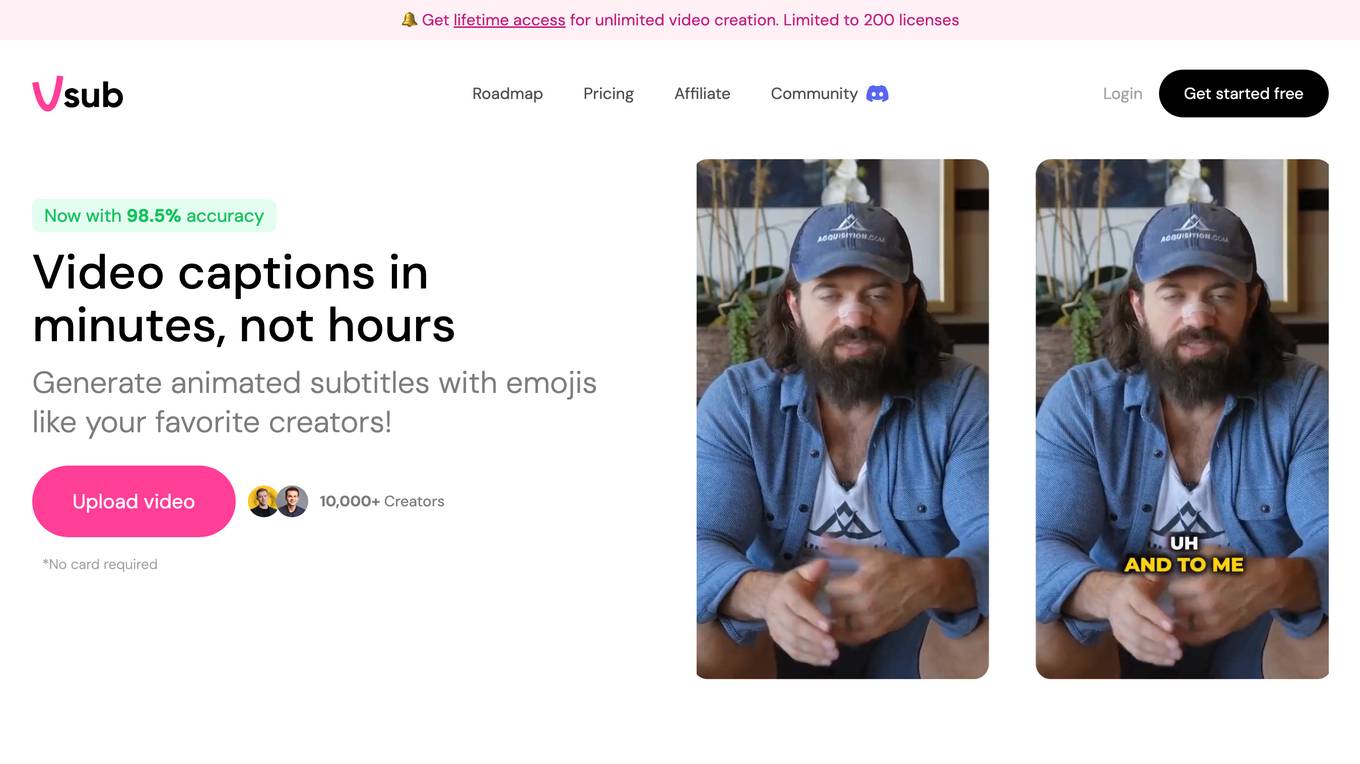
Vsub
Vsub is an AI-powered video captioning tool that makes it easy to create accurate and engaging captions for your videos. With Vsub, you can automatically generate captions, highlight keywords, and add animated emojis to your videos. Vsub also offers a variety of templates to help you create professional-looking captions. Vsub is the perfect tool for anyone who wants to create high-quality video content quickly and easily.
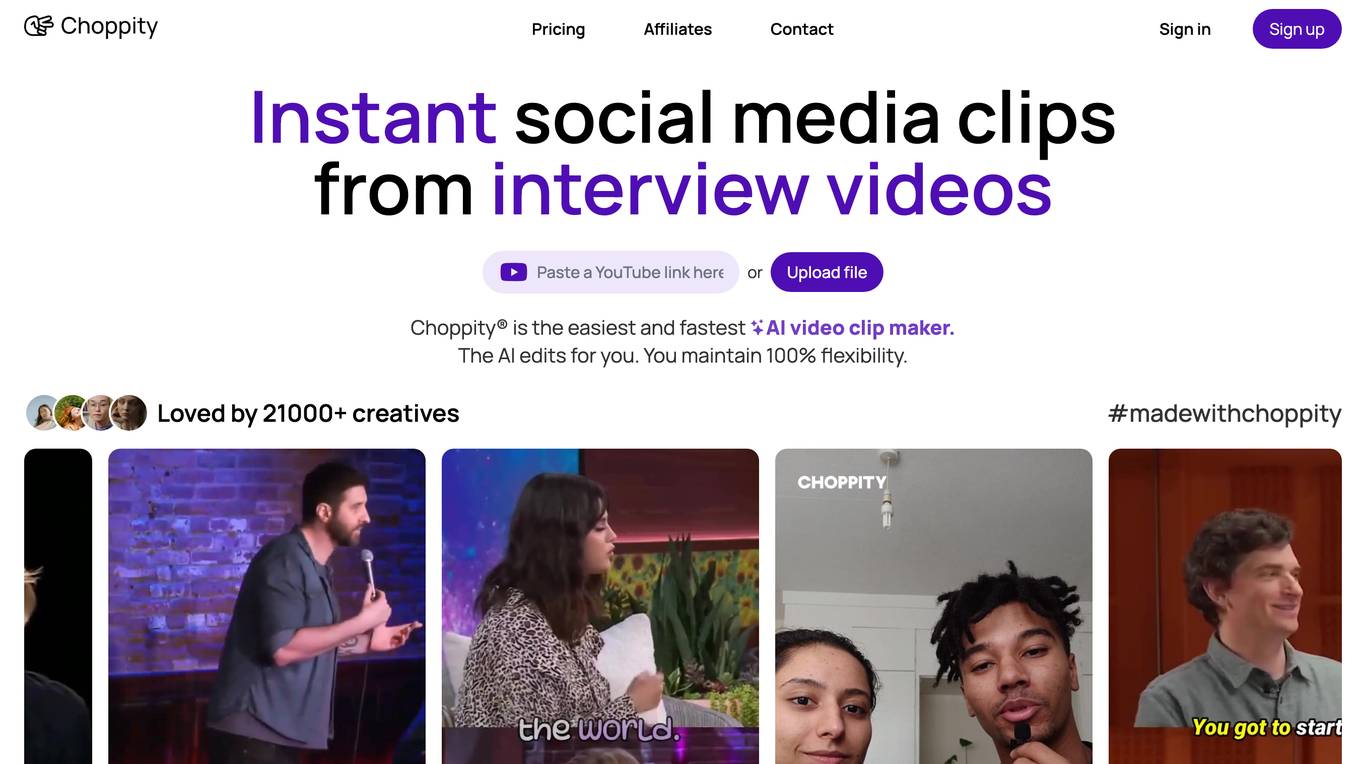
Choppity
Choppity is an AI-powered video clip maker that helps users quickly and easily create social media clips from long videos. It uses advanced AI algorithms to analyze videos and automatically generate viral clips, add animated captions, crop faces, follow speakers, and transcribe videos in 97 languages. Choppity is designed to be user-friendly and intuitive, allowing users to create professional-looking videos without any prior video editing experience.
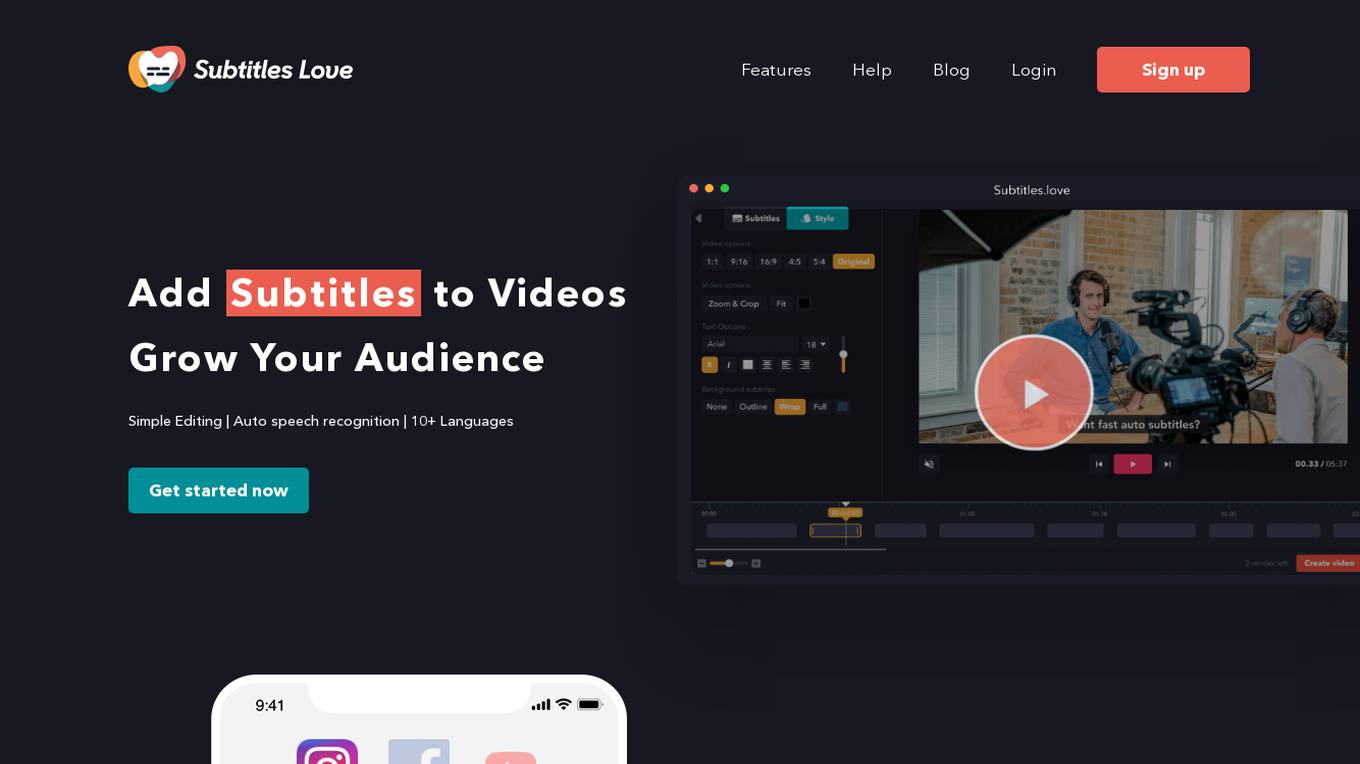
SubTitles.Love
SubTitles.Love is an AI-powered online subtitles editor that helps users easily add subtitles to their videos. The tool offers features such as auto speech recognition, support for 10+ languages, and simple editing capabilities. Users can upload any video format, tune subtitles with high accuracy, and customize the appearance before downloading the subtitled video. SubTitles.Love aims to save time and enhance audience engagement by providing automatic subtitles, resizing for social media, and affordable pricing. The platform is trusted by bloggers, podcast makers, and content producers for its quality service and community-driven approach.

SceneXplain
SceneXplain is a cutting-edge AI tool that specializes in generating descriptive captions for images and summarizing videos. It leverages advanced artificial intelligence algorithms to analyze visual content and provide accurate and concise textual descriptions. With SceneXplain, users can easily create engaging captions for their images and obtain quick summaries of lengthy videos. The tool is designed to streamline the process of content creation and enhance the accessibility of visual media for a wide range of applications.
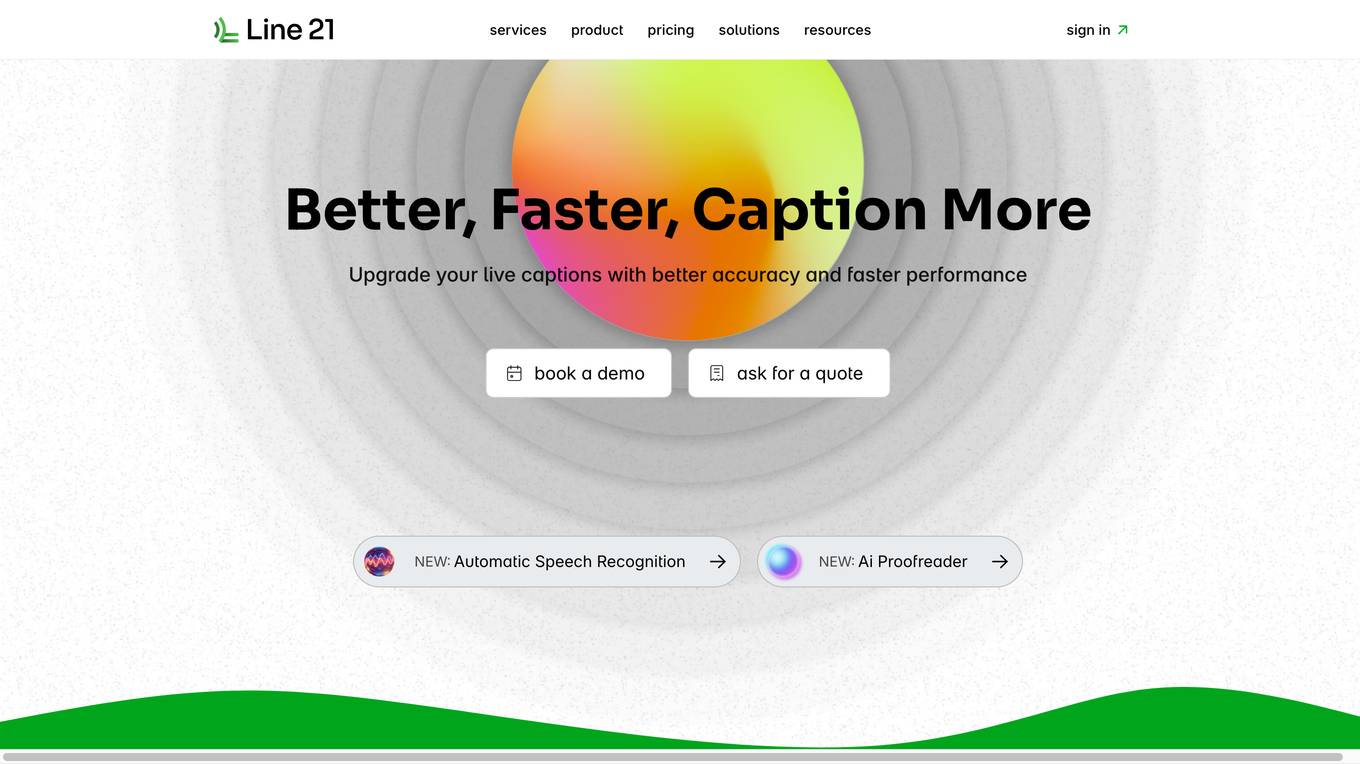
Line 21
Line 21 is an intelligent captioning solution that provides real-time remote captioning services in over a hundred languages. The platform offers a state-of-the-art caption delivery software that combines human expertise with AI services to create, enhance, translate, and deliver live captions to various viewer destinations. Line 21 supports accessible corporations, concerts, societies, and screenings by delivering fast and accurate captions through low-latency delivery methods. The platform also features an Ai Proofreader for real-time caption accuracy, caption encoding, fast caption delivery, and automatic translations in over 100 languages.
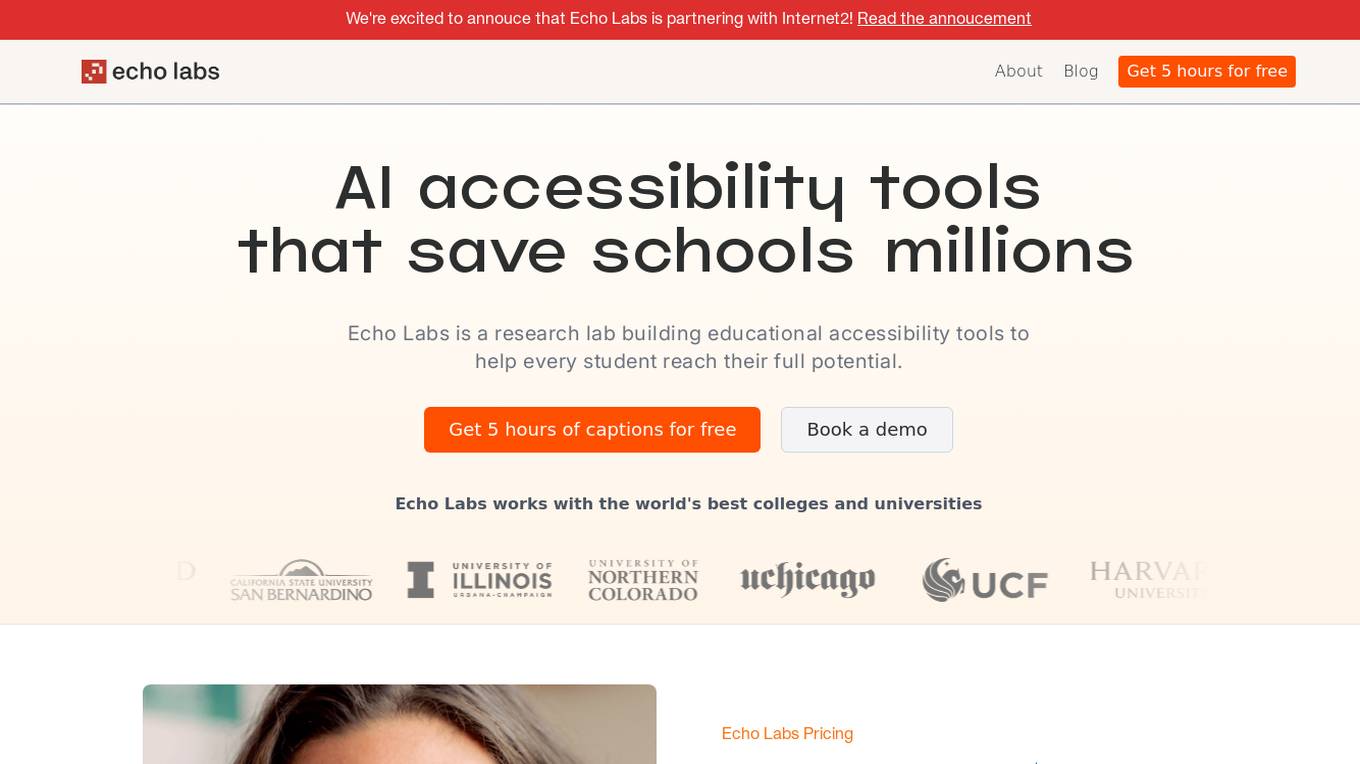
Echo Labs
Echo Labs is an AI-powered platform that provides captioning services for higher education institutions. The platform leverages cutting-edge technology to offer accurate and affordable captioning solutions, helping schools save millions of dollars. Echo Labs aims to make education more accessible by ensuring proactive accessibility measures are in place, starting with lowering the cost of captioning. The platform boasts a high accuracy rate of 99.8% and is backed by industry experts. With seamless integrations and a focus on inclusive learning environments, Echo Labs is revolutionizing accessibility in education.
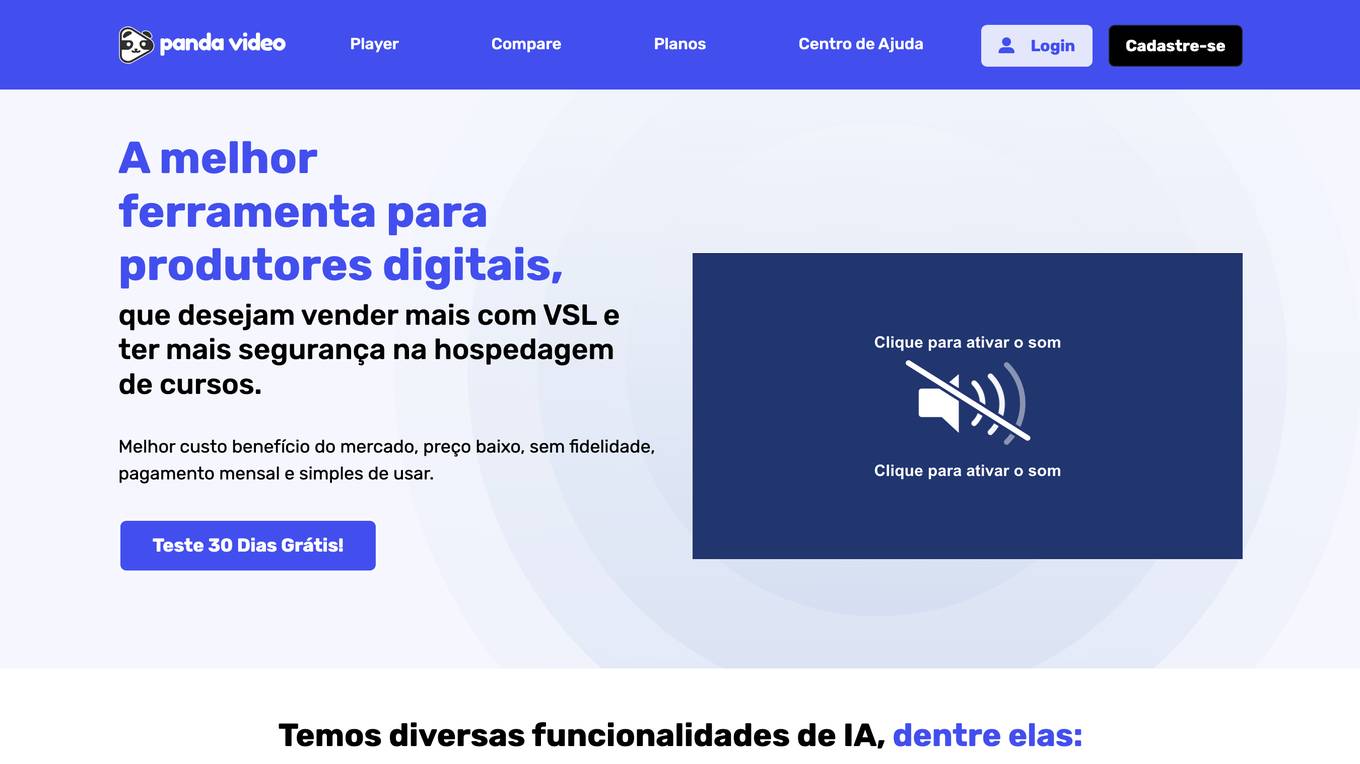
Panda Video
Panda Video is a video hosting platform that offers a variety of AI-powered features to help businesses increase sales and improve security. These features include a mind map tool for visualizing video content, a quiz feature for creating interactive learning experiences, an AI-powered ebook feature for providing supplemental resources, automatic captioning, a search feature for quickly finding specific content within videos, and automatic dubbing for creating videos in multiple languages. Panda Video also offers a variety of other features, such as DRM protection to prevent piracy, smart autoplay to increase engagement, a customizable player appearance, Facebook Pixel integration for retargeting, and analytics to track video performance.
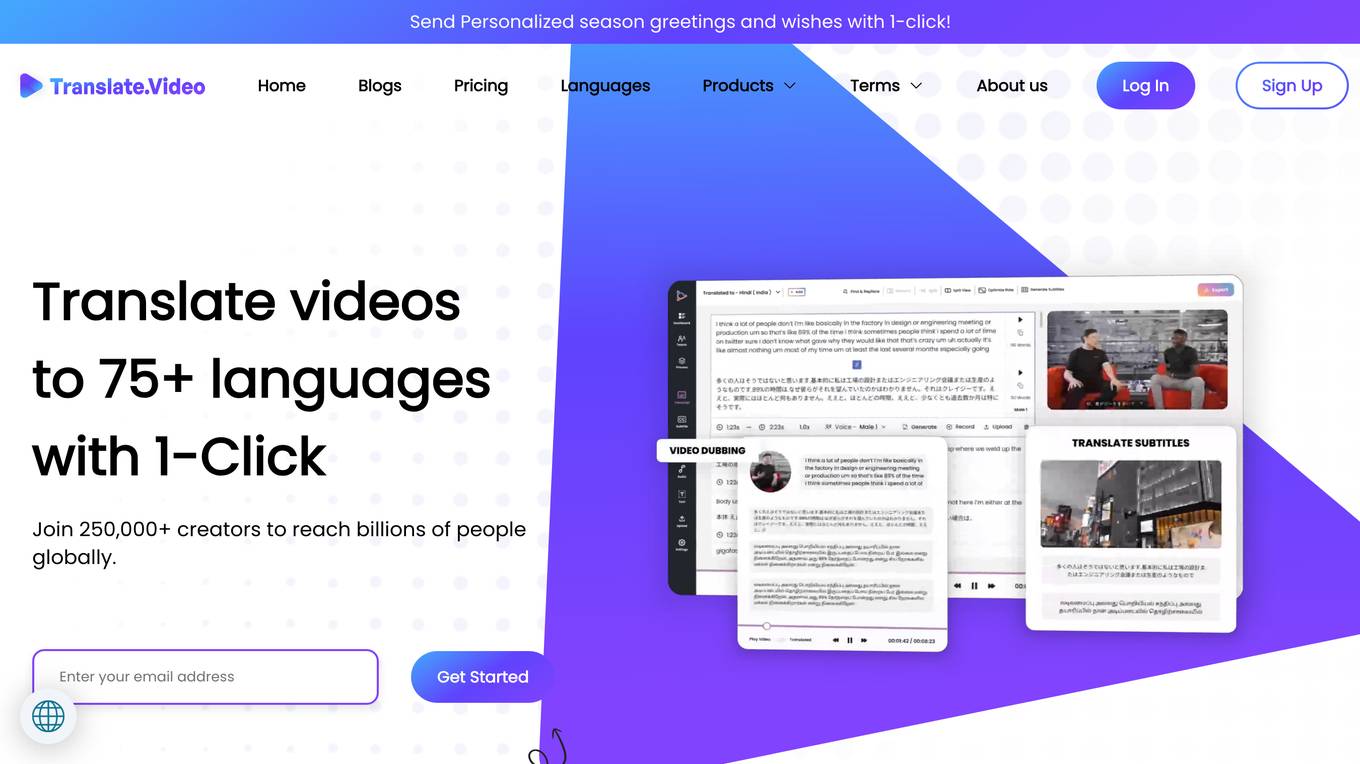
Translate.Video
Translate.Video is an AI multi-speaker video translation tool that offers speaker diarization, voice cloning, text-to-speech, and instant voice cloning features. It allows users to translate videos to over 75 languages with just one click, making content creation and translation efficient and accessible. The tool also provides plugins for popular design software like Photoshop, Illustrator, and Figma, enabling users to accelerate creative translation. Translate.Video is designed to help creators, influencers, and enterprises reach a global audience by simplifying the captioning, subtitling, and dubbing process.
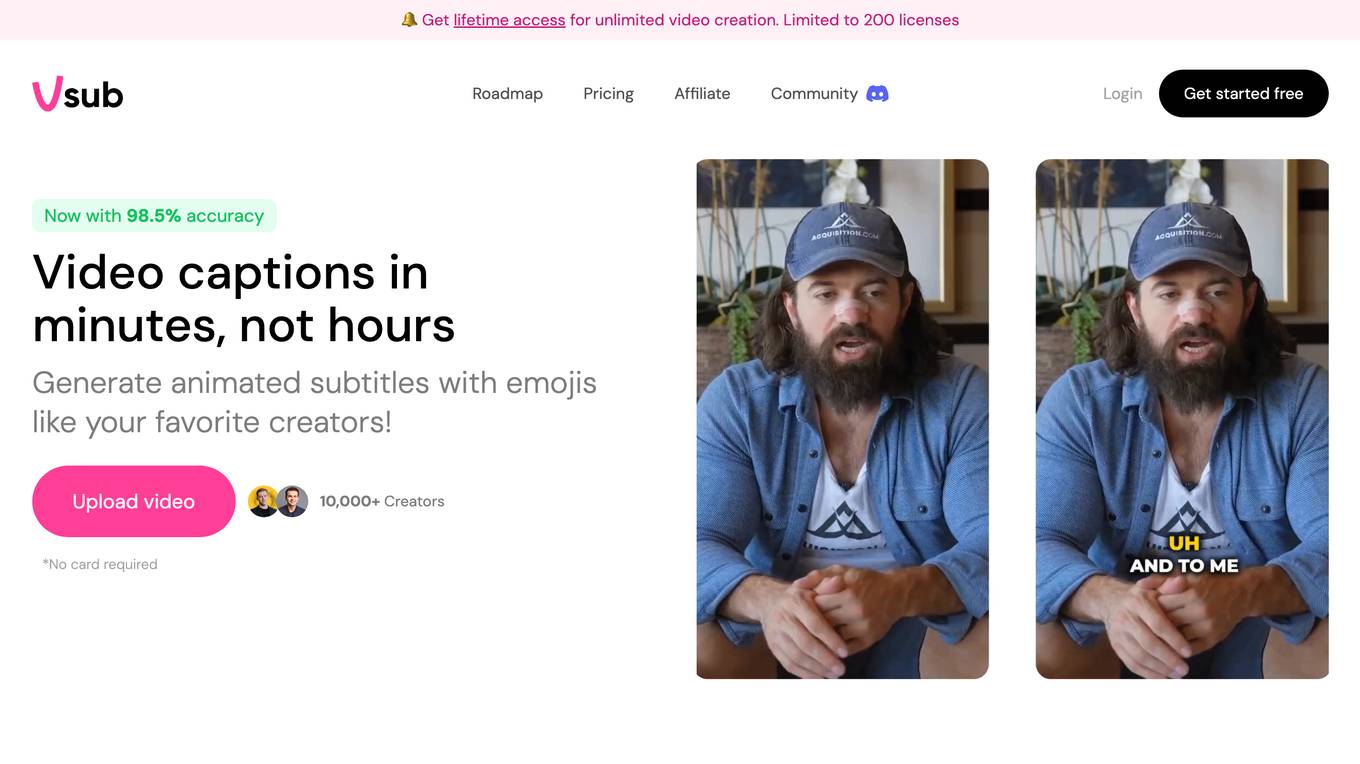
Vsub
Vsub is an AI-powered platform that allows users to create faceless videos quickly and easily. With a focus on video automation, Vsub offers a range of features such as generating AI shorts with one click, multiple templates for various niches, auto captions with animated emojis, and more. The platform aims to streamline the video creation process and help users save time by automating tasks that would otherwise require manual editing. Vsub is designed to cater to content creators, marketers, and individuals looking to create engaging videos without the need for on-camera appearances.
Valossa
Valossa is an AI tool that offers a range of video analysis services, including video-to-text conversion, search capabilities, captions generation, and clips creation. It provides solutions for brand-safe contextual advertising, automatic clip previews, sensitive content identification, and video mood analysis. Valossa Assistant™ allows users to have conversations inside videos, generate transcripts, captions, and insights, and analyze video moods and sentiment. The platform also offers AI solutions for video automation, such as transcribing, captioning, and translating audio-visual content, as well as categorizing video scenes and creating promotional videos automatically.
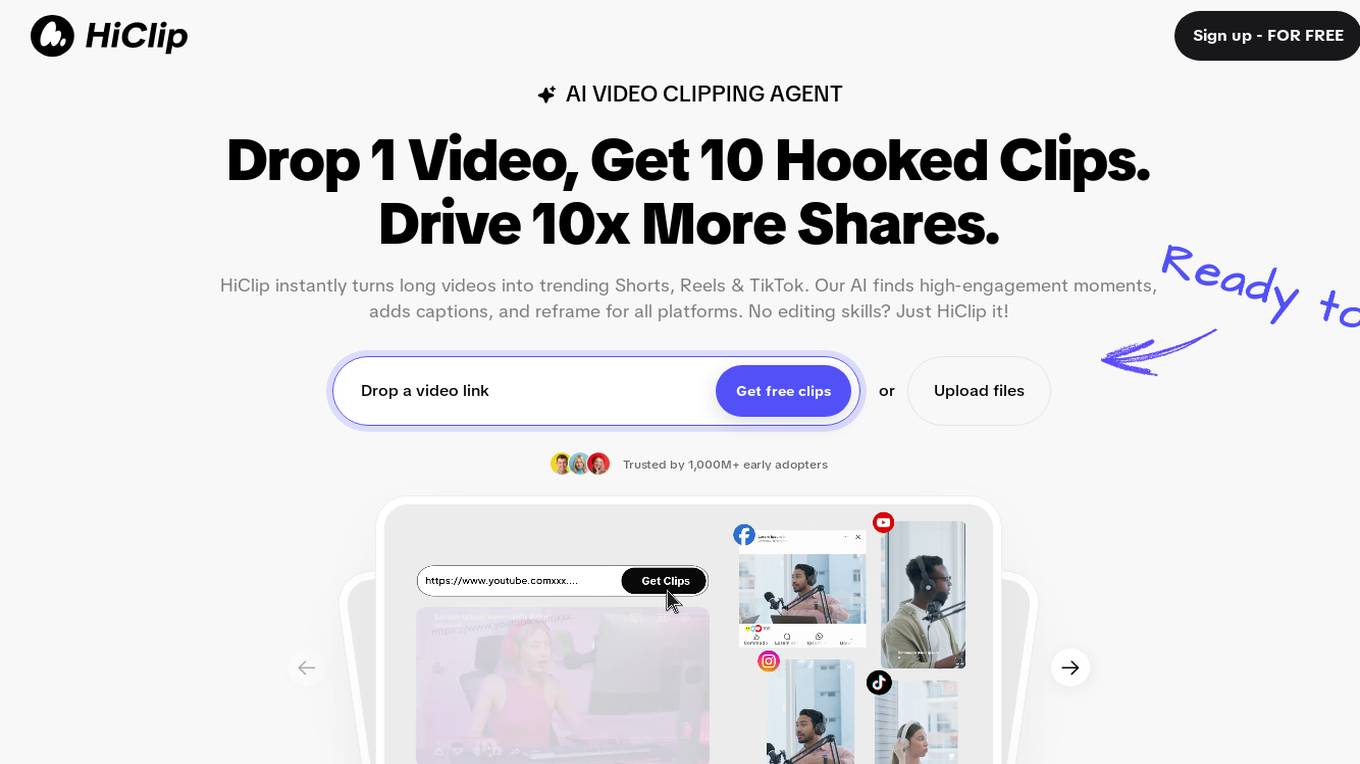
HiClip
HiClip is an AI Video Clipping Agent that helps users turn long videos into trending Shorts, Reels & TikTok clips effortlessly. It automates clipping, editing, and captioning processes using AI technology, making it easy for users to create high-engagement content for various social media platforms. With HiClip, users can save time and effort in video editing tasks, thanks to its advanced AI capabilities.

Felo Subtitles
Felo Subtitles is an AI-powered tool that provides live captions and translated subtitles for various types of content. It uses advanced speech recognition and translation algorithms to generate accurate and real-time subtitles in multiple languages. With Felo Subtitles, users can enjoy seamless communication and accessibility in different scenarios, such as online meetings, webinars, videos, and live events.
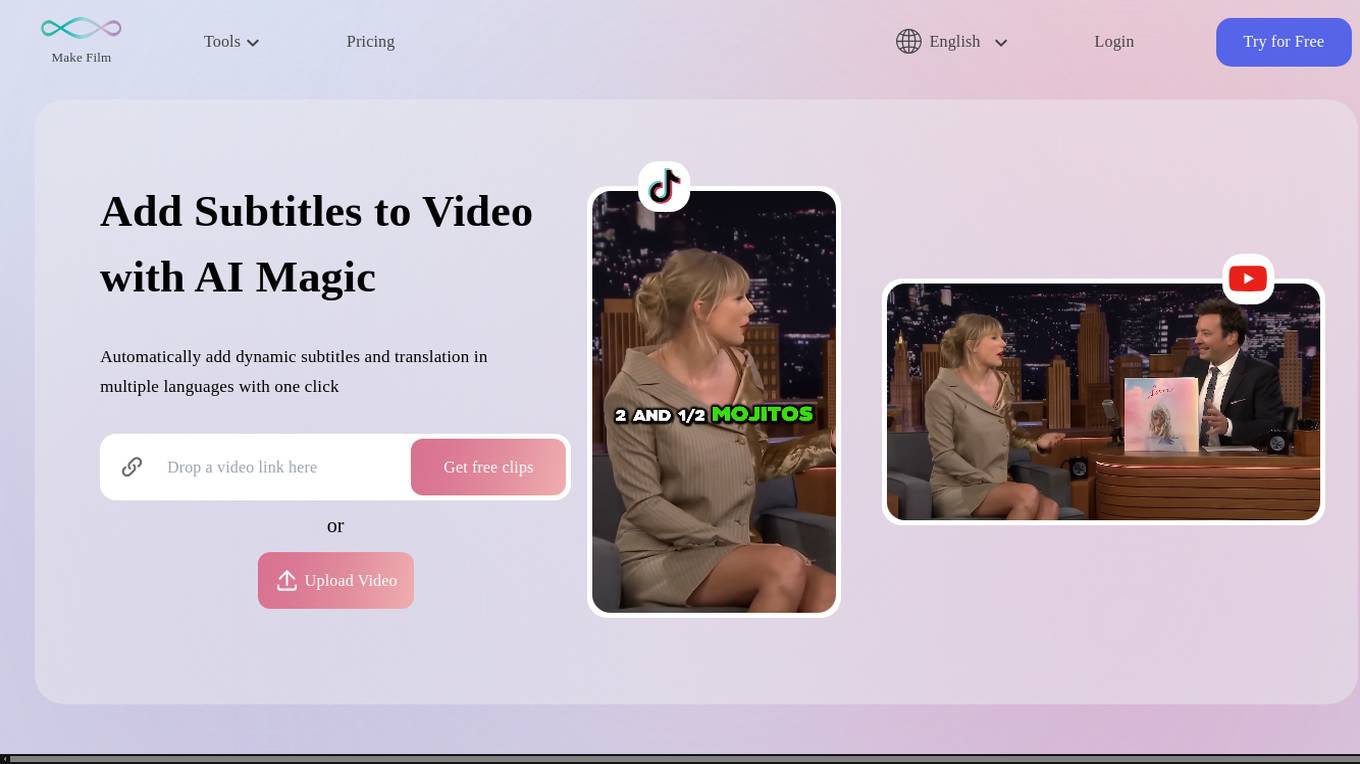
Makefilm.ai
Makefilm.ai is an AI-powered platform that transforms YouTube videos into TikTok and Shorts effortlessly. It offers a range of features such as automatic generation of captions in multiple languages, customizable editing tools, real-time speech captioning, and dynamic effects. The platform aims to make video creation engaging, accessible, and professional for video creators, businesses, educators, and marketers. With Makefilm.ai, users can enhance video accessibility, reach a wider audience, and create high-quality videos with ease.
Maestra AI
Maestra AI is an advanced platform offering transcription, subtitling, and voiceover tools powered by artificial intelligence technology. It allows users to automatically transcribe audio and video files, generate subtitles in multiple languages, and create voiceovers with diverse AI-generated voices. Maestra's services are designed to help users save time and easily reach a global audience by providing accurate and efficient transcription, captioning, and voiceover solutions.
Riverside
Riverside is an online podcast and video studio that makes recording and editing at the highest quality possible, accessible to anyone. It offers features such as separate audio and video tracks, AI-powered transcription and captioning, and a text-based editor for faster post-production. Riverside is designed for individuals and businesses of all sizes, including podcasters, video creators, producers, and marketers.
AudioShake
AudioShake is a cloud-based audio processing platform that uses artificial intelligence (AI) to separate audio into its component parts, such as vocals, music, and effects. This technology can be used for a variety of applications, including mixing and mastering, localization and captioning, interactive audio, and sync licensing.
Evolphin
Evolphin is a leading AI-powered platform for Digital Asset Management (DAM) and Media Asset Management (MAM) that caters to creatives, sports professionals, marketers, and IT teams. It offers advanced AI capabilities for fast search, robust version control, and Adobe plugins. Evolphin's AI automation streamlines video workflows, identifies objects, faces, logos, and scenes in media, generates speech-to-text for search and closed captioning, and enables automations based on AI engine identification. The platform allows for editing videos with AI, creating rough cuts instantly. Evolphin's cloud solutions facilitate remote media production pipelines, ensuring speed, security, and simplicity in managing creative assets.
Captions
Captions is an AI-powered creative studio that offers a wide range of tools to simplify the video creation process. With features like automatic captioning, eye contact correction, video trimming, background noise removal, and more, Captions empowers users to create professional-grade videos effortlessly. Trusted by millions worldwide, Captions leverages the power of AI to enhance storytelling and streamline video production.
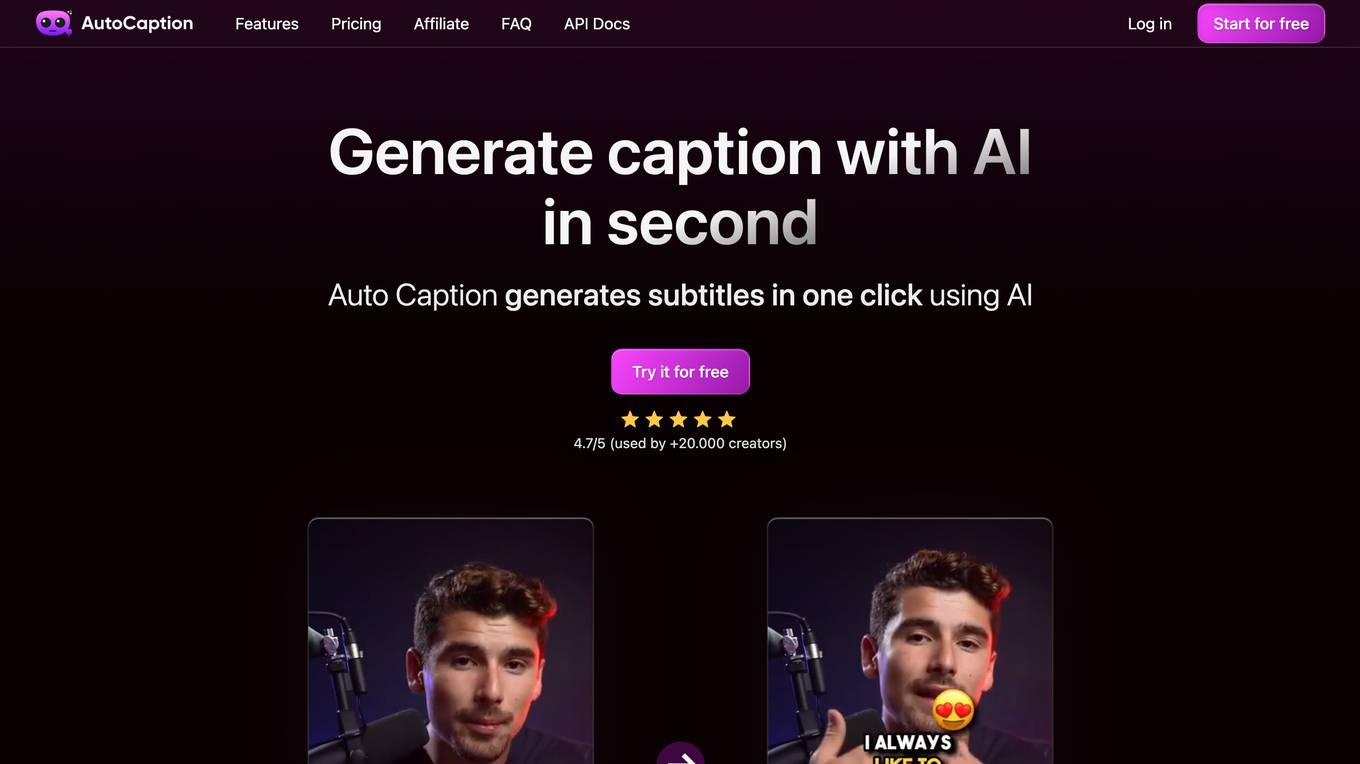
Auto Caption AI
Auto Caption AI is an easy-to-use tool that generates subtitles in one click using AI. It supports over 99 languages, is extremely fast, fully editable, and offers ready-to-use templates and animated emojis. With Auto Caption AI, you can save hours of editing time and create high-quality subtitles for your videos.
1 - Open Source AI Tools
InternGPT
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.
20 - OpenAI Gpts
Video Brief Genius
Transform your brand! Provide brand and product info, and we'll craft a unique, visually stunning 30-45 second video brief. Simple, effective, impactful.
VIDEO GAME versus VIDEO GAME
A fun game of VIDEO GAME versus VIDEO GAME. Get the conversation and debates going!
Video SEO Optimizer - GPT
Optimizes YouTube SEO, crafts engaging Title, Description, Tags, Keywords advises on Thumbnails, and provides JSON.

AI Video Creation
Tech-focused AI on video creation, covering fakes, tools, and best practices.
Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.