
llm
Ruby toolkit for multiple Large Language Models (LLMs)
Stars: 89
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.
README:
Maintenance Notice
Please note that the primary author of llm.rb is pivoting away from Ruby and towards Golang for future projects. Although llm.rb will be maintained for the foreseeable future it is not where my primary interests lie anymore. Thanks for understanding.
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), zAI, DeepSeek, Ollama, and LlamaCpp. The toolkit includes full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema).
This cool demo writes a new llm-shell command
with the help of llm.rb.
Similar-ish to
GitHub Copilot but for the terminal.
Start demo

- An introduction to RAG – a blog post that implements the RAG pattern
- How to estimate the age of a person in a photo – a blog post that implements an age estimation tool
- How to edit an image with Gemini – a blog post that implements image editing with Gemini
- Fast sailing with persistent connections – a blog post that optimizes performance with a thread-safe connection pool
- How to build agents (with llm.rb) – a blog post that implements agentic behavior via tools
- llm-shell – a developer-oriented console for Large Language Model communication
- llm-spell – a utility that can correct spelling mistakes with a Large Language Model
A simple chatbot that maintains a conversation and streams responses in real-time:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
bot = LLM::Bot.new(llm, stream: $stdout)
loop do
print "> "
input = $stdin.gets&.chomp || break
bot.chat(input).flush
print "\n"
end- ✅ A single unified interface for multiple providers
- 📦 Zero dependencies outside Ruby's standard library
- 🚀 Smart API design that minimizes the number of requests made
- ♻️ Optional: per-provider, process-wide connection pool via net-http-persistent
- 🧠 Stateless and stateful chat via completions and responses API
- 🤖 Tool calling and function execution
- 🗂️ JSON Schema support for structured, validated responses
- 📡 Streaming support for real-time response updates
- 🗣️ Text-to-speech, transcription, and translation
- 🖼️ Image generation, editing, and variation support
- 📎 File uploads and prompt-aware file interaction
- 💡 Multimodal prompts (text, documents, audio, images, videos, URLs, etc)
- 🧮 Text embeddings and vector support
- 🧱 Includes support for OpenAI's vector stores API
- 📜 Model management and selection
- 🔧 Includes support for OpenAI's responses, moderations, and vector stores APIs
While the Features section above gives you the high-level picture, the table below breaks things down by provider, so you can see exactly what’s supported where.
| Feature / Provider | OpenAI | Anthropic | Gemini | DeepSeek | xAI (Grok) | zAI | Ollama | LlamaCpp |
|---|---|---|---|---|---|---|---|---|
| Chat Completions | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Streaming | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Tool Calling | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| JSON Schema / Structured Output | ✅ | ❌ | ✅ | ❌ | ✅ | ❌ | ✅* | ✅* |
| Embeddings | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ |
| Multimodal Prompts (text, documents, audio, images, videos, URLs, etc) | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| Files API | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Models API | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| Audio (TTS / Transcribe / Translate) | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Image Generation & Editing | ✅ | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| Local Model Support | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ |
| Vector Stores (RAG) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Responses | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Moderations | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
* JSON Schema support in Ollama/LlamaCpp depends on the model, not the API.
All providers inherit from LLM::Provider – they share a common interface and set of functionality. Each provider can be instantiated using an API key (if required) and an optional set of configuration options via the singleton methods of LLM. For example:
#!/usr/bin/env ruby
require "llm"
##
# remote providers
llm = LLM.openai(key: "yourapikey")
llm = LLM.gemini(key: "yourapikey")
llm = LLM.anthropic(key: "yourapikey")
llm = LLM.xai(key: "yourapikey")
llm = LLM.deepseek(key: "yourapikey")
##
# local providers
llm = LLM.ollama(key: nil)
llm = LLM.llamacpp(key: nil)The llm.rb library can maintain a process-wide connection pool for each provider that is instantiated. This feature can improve performance but it is optional, the implementation depends on net-http-persistent, and the gem should be installed separately:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"], persistent: true)
res1 = llm.responses.create "message 1"
res2 = llm.responses.create "message 2", previous_response_id: res1.response_id
res3 = llm.responses.create "message 3", previous_response_id: res2.response_id
print res3.output_text, "\n"The llm.rb library is thread-safe and can be used in a multi-threaded environments but it is important to keep in mind that the LLM::Provider and LLM::Bot classes should be instantiated once per thread, and not shared between threads. Generally the library tries to avoid global or shared state but where it exists reentrant locks are used to ensure thread-safety.
This example uses the stateless chat completions API that all providers support. A similar example for OpenAI's stateful responses API is available in the docs/ directory.
The following example creates an instance of LLM::Bot and enters into a conversation where messages are buffered and sent to the provider on-demand. The implementation is designed to buffer messages by waiting until an attempt to iterate over LLM::Bot#messages is made before sending a request to the LLM:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
bot = LLM::Bot.new(llm)
url = "https://en.wikipedia.org/wiki/Special:FilePath/Cognac_glass.jpg"
bot.chat "Your task is to answer all user queries", role: :system
bot.chat ["Tell me about this URL", URI(url)], role: :user
bot.chat ["Tell me about this PDF", File.open("handbook.pdf", "rb")], role: :user
bot.chat "Are the URL and PDF similar to each other?", role: :user
# At this point, we execute a single request
bot.messages.each { print "[#{_1.role}] ", _1.content, "\n" }There Is More Than One Way To Do It (TIMTOWTDI) when you are using llm.rb – and this is especially true when it comes to streaming. See the streaming documentation in docs/ for more details.
The following example streams the messages in a conversation
as they are generated in real-time. The stream option can
be set to an IO object, or the value true to enable streaming
– and at the end of the request, bot.chat returns the
same response as the non-streaming version which allows you
to process a response in the same way:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
bot = LLM::Bot.new(llm)
url = "https://en.wikipedia.org/wiki/Special:FilePath/Cognac_glass.jpg"
bot.chat(stream: $stdout) do |prompt|
prompt.system "Your task is to answer all user queries"
prompt.user ["Tell me about this URL", URI(url)]
prompt.user ["Tell me about this PDF", File.open("handbook.pdf", "rb")]
prompt.user "Are the URL and PDF similar to each other?"
end.flushAll LLM providers except Anthropic and DeepSeek allow a client to describe the structure of a response that a LLM emits according to a schema that is described by JSON. The schema lets a client describe what JSON object (or value) an LLM should emit, and the LLM will abide by the schema:
#!/usr/bin/env ruby
require "llm"
##
# Objects
llm = LLM.openai(key: ENV["KEY"])
schema = llm.schema.object(probability: llm.schema.number.required)
bot = LLM::Bot.new(llm, schema:)
bot.chat "Does the earth orbit the sun?", role: :user
bot.messages.find(&:assistant?).content! # => {probability: 1.0}
##
# Enums
schema = llm.schema.object(fruit: llm.schema.string.enum("Apple", "Orange", "Pineapple"))
bot = LLM::Bot.new(llm, schema:)
bot.chat "Your favorite fruit is Pineapple", role: :system
bot.chat "What fruit is your favorite?", role: :user
bot.messages.find(&:assistant?).content! # => {fruit: "Pineapple"}
##
# Arrays
schema = llm.schema.object(answers: llm.schema.array(llm.schema.integer.required))
bot = LLM::Bot.new(llm, schema:)
bot.chat "Answer all of my questions", role: :system
bot.chat "Tell me the answer to ((5 + 5) / 2)", role: :user
bot.chat "Tell me the answer to ((5 + 5) / 2) * 2", role: :user
bot.chat "Tell me the answer to ((5 + 5) / 2) * 2 + 1", role: :user
bot.messages.find(&:assistant?).content! # => {answers: [5, 10, 11]}All providers support a powerful feature known as tool calling, and although it is a little complex to understand at first, it can be powerful for building agents. There are three main interfaces to understand: LLM::Function, LLM::Tool, and LLM::ServerTool.
The following example demonstrates LLM::Function and how it can define a local function (which happens to be a tool), and how a provider (such as OpenAI) can then detect when we should call the function. Its most notable feature is that it can act as a closure and has access to its surrounding scope, which can be useful in some situations.
The LLM::Bot#functions method returns an array of functions that can be called after sending a message and it will only be populated if the LLM detects a function should be called. Each function corresponds to an element in the "tools" array. The array is emptied after a function call, and potentially repopulated on the next message:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
tool = LLM.function(:system) do |fn|
fn.description "Run a shell command"
fn.params do |schema|
schema.object(command: schema.string.required)
end
fn.define do |command:|
ro, wo = IO.pipe
re, we = IO.pipe
Process.wait Process.spawn(command, out: wo, err: we)
[wo,we].each(&:close)
{stderr: re.read, stdout: ro.read}
end
end
bot = LLM::Bot.new(llm, tools: [tool])
bot.chat "Your task is to run shell commands via a tool.", role: :system
bot.chat "What is the current date?", role: :user
bot.chat bot.functions.map(&:call) # report return value to the LLM
bot.chat "What operating system am I running? (short version please!)", role: :user
bot.chat bot.functions.map(&:call) # report return value to the LLM
##
# {stderr: "", stdout: "Thu May 1 10:01:02 UTC 2025"}
# {stderr: "", stdout: "FreeBSD"}The LLM::Tool class can be used to implement a LLM::Function as a class. Under the hood, a subclass of LLM::Tool wraps an instance of LLM::Function and delegates to it.
The choice between LLM::Function and LLM::Tool is often a matter of preference but each carry their own benefits. For example, LLM::Function has the benefit of being a closure that has access to its surrounding context and sometimes that is useful:
#!/usr/bin/env ruby
require "llm"
class System < LLM::Tool
name "system"
description "Run a shell command"
params { |schema| schema.object(command: schema.string.required) }
def call(command:)
ro, wo = IO.pipe
re, we = IO.pipe
Process.wait Process.spawn(command, out: wo, err: we)
[wo,we].each(&:close)
{stderr: re.read, stdout: ro.read}
end
end
bot = LLM::Bot.new(llm, tools: [System])
bot.chat "Your task is to run shell commands via a tool.", role: :system
bot.chat "What is the current date?", role: :user
bot.chat bot.functions.map(&:call) # report return value to the LLM
bot.chat "What operating system am I running? (short version please!)", role: :user
bot.chat bot.functions.map(&:call) # report return value to the LLM
##
# {stderr: "", stdout: "Thu May 1 10:01:02 UTC 2025"}
# {stderr: "", stdout: "FreeBSD"}The LLM::Function and LLM::Tool classes can define a local function or tool that can be called by a provider on your behalf, and the LLM::ServerTool class represents a tool that is defined and implemented by a provider, and we can request that the provider call the tool on our behalf. That's the primary difference between a function implemented locally and a tool implemented by a provider. The available tools depend on the provider, and the following example uses the OpenAI provider to execute Python code on OpenAI's servers:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
res = llm.responses.create "Run: 'print(\"hello world\")'",
tools: [llm.server_tool(:code_interpreter)]
print res.output_text, "\n"A common tool among all providers is the ability to perform a web search, and the following example uses the OpenAI provider to search the web using the Web Search tool. This can also be done with the Anthropic and Gemini providers:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
res = llm.web_search(query: "summarize today's news")
print res.output_text, "\n"The OpenAI and Gemini providers provide a Files API where a client can upload files that can be referenced from a prompt, and with other APIs as well. The following example uses the OpenAI provider to describe the contents of a PDF file after it has been uploaded. The file (a specialized instance of LLM::Response ) is given as part of a prompt that is understood by llm.rb:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
bot = LLM::Bot.new(llm)
file = llm.files.create(file: "/books/goodread.pdf")
bot.chat ["Tell me about this file", file]
bot.messages.select(&:assistant?).each { print "[#{_1.role}] ", _1.content, "\n" }It is generally a given that an LLM will understand text but they can also understand and generate other types of media as well: audio, images, video, and even URLs. The object given as a prompt in llm.rb can be a string to represent text, a URI object to represent a URL, an LLM::Response object to represent a file stored with the LLM, and so on. These are objects you can throw at the prompt and have them be understood automatically.
A prompt can also have multiple parts, and in that case, an array is given as a prompt. Each element is considered to be part of the prompt:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
bot = LLM::Bot.new(llm)
bot.chat ["Tell me about this URL", URI("https://example.com/path/to/image.png")]
[bot.messages.find(&:assistant?)].each { print "[#{_1.role}] ", _1.content, "\n" }
file = llm.files.create(file: "/books/goodread.pdf")
bot.chat ["Tell me about this PDF", file]
[bot.messages.find(&:assistant?)].each { print "[#{_1.role}] ", _1.content, "\n" }
bot.chat ["Tell me about this image", File.open("/images/nemothefish.png", "r")]
[bot.messages.find(&:assistant?)].each { print "[#{_1.role}] ", _1.content, "\n" }Some but not all providers implement audio generation capabilities that
can create speech from text, transcribe audio to text, or translate
audio to text (usually English). The following example uses the OpenAI provider
to create an audio file from a text prompt. The audio is then moved to
${HOME}/hello.mp3 as the final step:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
res = llm.audio.create_speech(input: "Hello world")
IO.copy_stream res.audio, File.join(Dir.home, "hello.mp3")The following example transcribes an audio file to text. The audio file
(${HOME}/hello.mp3) was theoretically created in the previous example,
and the result is printed to the console. The example uses the OpenAI
provider to transcribe the audio file:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
res = llm.audio.create_transcription(
file: File.join(Dir.home, "hello.mp3")
)
print res.text, "\n" # => "Hello world."The following example translates an audio file to text. In this example
the audio file (${HOME}/bomdia.mp3) is theoretically in Portuguese,
and it is translated to English. The example uses the OpenAI provider,
and at the time of writing, it can only translate to English:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
res = llm.audio.create_translation(
file: File.join(Dir.home, "bomdia.mp3")
)
print res.text, "\n" # => "Good morning."Some but not all LLM providers implement image generation capabilities that
can create new images from a prompt, or edit an existing image with a
prompt. The following example uses the OpenAI provider to create an
image of a dog on a rocket to the moon. The image is then moved to
${HOME}/dogonrocket.png as the final step:
#!/usr/bin/env ruby
require "llm"
require "open-uri"
require "fileutils"
llm = LLM.openai(key: ENV["KEY"])
res = llm.images.create(prompt: "a dog on a rocket to the moon")
res.urls.each do |url|
FileUtils.mv OpenURI.open_uri(url).path,
File.join(Dir.home, "dogonrocket.png")
endThe following example is focused on editing a local image with the aid
of a prompt. The image (/images/cat.png) is returned to us with the cat
now wearing a hat. The image is then moved to ${HOME}/catwithhat.png as
the final step:
#!/usr/bin/env ruby
require "llm"
require "open-uri"
require "fileutils"
llm = LLM.openai(key: ENV["KEY"])
res = llm.images.edit(
image: "/images/cat.png",
prompt: "a cat with a hat",
)
res.urls.each do |url|
FileUtils.mv OpenURI.open_uri(url).path,
File.join(Dir.home, "catwithhat.png")
endThe following example is focused on creating variations of a local image.
The image (/images/cat.png) is returned to us with five different variations.
The images are then moved to ${HOME}/catvariation0.png, ${HOME}/catvariation1.png
and so on as the final step:
#!/usr/bin/env ruby
require "llm"
require "open-uri"
require "fileutils"
llm = LLM.openai(key: ENV["KEY"])
res = llm.images.create_variation(
image: "/images/cat.png",
n: 5
)
res.urls.each.with_index do |url, index|
FileUtils.mv OpenURI.open_uri(url).path,
File.join(Dir.home, "catvariation#{index}.png")
endThe
LLM::Provider#embed
method generates a vector representation of one or more chunks
of text. Embeddings capture the semantic meaning of text –
a common use-case for them is to store chunks of text in a
vector database, and then to query the database for semantically
similar text. These chunks of similar text can then support the
generation of a prompt that is used to query a large language model,
which will go on to generate a response:
#!/usr/bin/env ruby
require "llm"
llm = LLM.openai(key: ENV["KEY"])
res = llm.embed(["programming is fun", "ruby is a programming language", "sushi is art"])
print res.class, "\n"
print res.embeddings.size, "\n"
print res.embeddings[0].size, "\n"
##
# LLM::Response
# 3
# 1536Almost all LLM providers provide a models endpoint that allows a client to query the list of models that are available to use. The list is dynamic, maintained by LLM providers, and it is independent of a specific llm.rb release. LLM::Model objects can be used instead of a string that describes a model name (although either works). Let's take a look at an example:
#!/usr/bin/env ruby
require "llm"
##
# List all models
llm = LLM.openai(key: ENV["KEY"])
llm.models.all.each do |model|
print "model: ", model.id, "\n"
end
##
# Select a model
model = llm.models.all.find { |m| m.id == "gpt-3.5-turbo" }
bot = LLM::Bot.new(llm, model: model.id)
bot.chat "Hello #{model.id} :)"
bot.messages.select(&:assistant?).each { print "[#{_1.role}] ", _1.content, "\n" }I supplied both Gemini and DeepSeek with the contents of lib/ and README.md via llm-shell. Their feedback was way more positive than I could have imagined 😅 These are genuine responses though, with no special prompting or engineering. I just provided them with the source code and asked for their opinion.
Review by Gemini

Review by DeepSeek

The README tries to provide a high-level overview of the library. For everything else there's the API reference. It covers classes and methods that the README glances over or doesn't cover at all. The API reference is available at 0x1eef.github.io/x/llm.rb.
llm.rb can be installed via rubygems.org:
gem install llm.rb
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm
Similar Open Source Tools
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output based on a Context-Free Grammar (CFG). It supports various programming languages like Python, Go, SQL, Math, JSON, and more. Users can define custom grammars using EBNF syntax. SynCode offers fast generation, seamless integration with HuggingFace Language Models, and the ability to sample with different decoding strategies.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.
client-python
The Mistral Python Client is a tool inspired by cohere-python that allows users to interact with the Mistral AI API. It provides functionalities to access and utilize the AI capabilities offered by Mistral. Users can easily install the client using pip and manage dependencies using poetry. The client includes examples demonstrating how to use the API for various tasks, such as chat interactions. To get started, users need to obtain a Mistral API Key and set it as an environment variable. Overall, the Mistral Python Client simplifies the integration of Mistral AI services into Python applications.
llm-web-api
LLM Web API is a tool that provides a web page to API interface for ChatGPT, allowing users to bypass Cloudflare challenges, switch models, and dynamically display supported models. It uses Playwright to control a fingerprint browser, simulating user operations to send requests to the OpenAI website and converting the responses into API interfaces. The API currently supports the OpenAI-compatible /v1/chat/completions API, accessible using OpenAI or other compatible clients.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.

LTEngine
LTEngine is a free and open-source local AI machine translation API written in Rust. It is self-hosted and compatible with LibreTranslate. LTEngine utilizes large language models (LLMs) via llama.cpp, offering high-quality translations that rival or surpass DeepL for certain languages. It supports various accelerators like CUDA, Metal, and Vulkan, with the largest model 'gemma3-27b' fitting on a single consumer RTX 3090. LTEngine is actively developed, with a roadmap outlining future enhancements and features.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
mlx-llm
mlx-llm is a library that allows you to run Large Language Models (LLMs) on Apple Silicon devices in real-time using Apple's MLX framework. It provides a simple and easy-to-use API for creating, loading, and using LLM models, as well as a variety of applications such as chatbots, fine-tuning, and retrieval-augmented generation.

comet-llm
CometLLM is a tool to log and visualize your LLM prompts and chains. Use CometLLM to identify effective prompt strategies, streamline your troubleshooting, and ensure reproducible workflows!
PhoGPT
PhoGPT is an open-source 4B-parameter generative model series for Vietnamese, including the base pre-trained monolingual model PhoGPT-4B and its chat variant, PhoGPT-4B-Chat. PhoGPT-4B is pre-trained from scratch on a Vietnamese corpus of 102B tokens, with an 8192 context length and a vocabulary of 20K token types. PhoGPT-4B-Chat is fine-tuned on instructional prompts and conversations, demonstrating superior performance. Users can run the model with inference engines like vLLM and Text Generation Inference, and fine-tune it using llm-foundry. However, PhoGPT has limitations in reasoning, coding, and mathematics tasks, and may generate harmful or biased responses.
claim-ai-phone-bot
AI-powered call center solution with Azure and OpenAI GPT. The bot can answer calls, understand the customer's request, and provide relevant information or assistance. It can also create a todo list of tasks to complete the claim, and send a report after the call. The bot is customizable, and can be used in multiple languages.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.
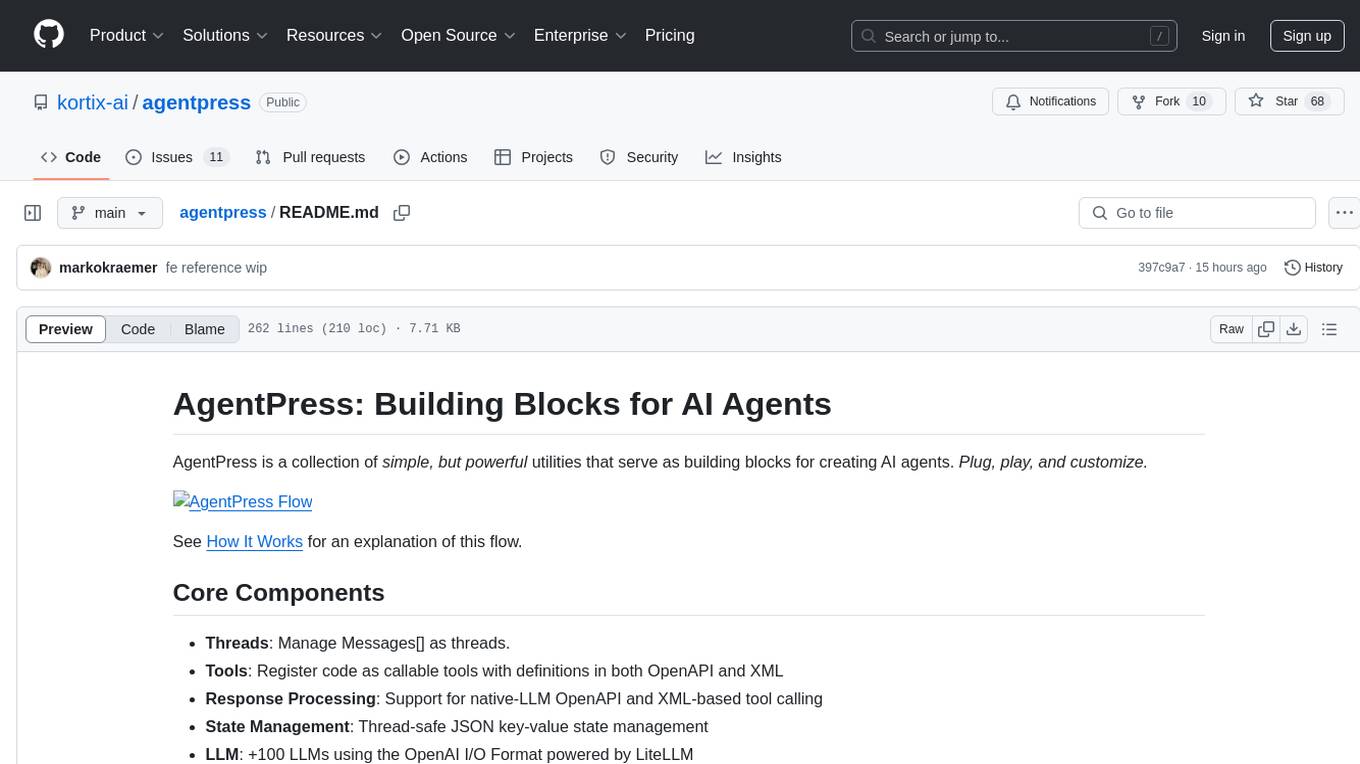
agentpress
AgentPress is a collection of simple but powerful utilities that serve as building blocks for creating AI agents. It includes core components for managing threads, registering tools, processing responses, state management, and utilizing LLMs. The tool provides a modular architecture for handling messages, LLM API calls, response processing, tool execution, and results management. Users can easily set up the environment, create custom tools with OpenAPI or XML schema, and manage conversation threads with real-time interaction. AgentPress aims to be agnostic, simple, and flexible, allowing users to customize and extend functionalities as needed.
wtf.nvim
wtf.nvim is a Neovim plugin that enhances diagnostic debugging by providing explanations and solutions for code issues using ChatGPT. It allows users to search the web for answers directly from Neovim, making the debugging process faster and more efficient. The plugin works with any language that has LSP support in Neovim, offering AI-powered diagnostic assistance and seamless integration with various resources for resolving coding problems.
For similar tasks
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.
stable-diffusion-prompt-reader
A simple standalone viewer for reading prompt from Stable Diffusion generated image outside the webui. The tool supports macOS, Windows, and Linux, providing both GUI and CLI functionalities. Users can interact with the tool through drag and drop, copy prompt to clipboard, remove prompt from image, export prompt to text file, edit or import prompt to images, and more. It supports multiple formats including PNG, JPEG, WEBP, TXT, and various tools like A1111's webUI, Easy Diffusion, StableSwarmUI, Fooocus-MRE, NovelAI, InvokeAI, ComfyUI, Draw Things, and Naifu(4chan). Users can download the tool for different platforms and install it via Homebrew Cask or pip. The tool can be used to read, export, remove, and edit prompts from images, providing various modes and options for different tasks.
InternGPT
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.