
java-genai
Google Gen AI Java SDK provides an interface for developers to integrate Google's generative models into their Java applications.
Stars: 202
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
README:
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs.

If you're using Maven, add the following to your dependencies: //: # ({x-version-update-start:google-genai:released})
<dependencies>
<dependency>
<groupId>com.google.genai</groupId>
<artifactId>google-genai</artifactId>
<version>1.16.0</version>
</dependency>
</dependencies>Follow the instructions in this section to get started using the Google Gen AI SDK for Java.
The Google Gen AI Java SDK provides a Client class, simplifying interaction with both the Gemini API and Vertex AI API. With minimal configuration, you can seamlessly switch between the 2 backends without rewriting your code.
import com.google.genai.Client;
// Use Builder class for instantiation. Explicitly set the API key to use Gemini
// Developer backend.
Client client = Client.builder().apiKey("your-api-key").build();import com.google.genai.Client;
// Use Builder class for instantiation. Explicitly set the project and location,
// and set `vertexAI(true)` to use Vertex AI backend.
Client client = Client.builder()
.project("your-project")
.location("your-location")
.vertexAI(true)
.build();import com.google.genai.Client;
// Explicitly set the `apiKey` and `vertexAI(true)` to use Vertex AI backend
// in express mode.
Client client = Client.builder()
.apiKey("your-api-key")
.vertexAI(true)
.build();You can create a client by configuring the necessary environment variables. Configuration setup instructions depends on whether you're using the Gemini Developer API or the Gemini API in Vertex AI.
Gemini Developer API: Set the GOOGLE_API_KEY. It will automatically be
picked up by the client. Note that GEMINI_API_KEY is a legacy environment
variable, it's recommended to use GOOGLE_API_KEY only. But if both are set,
GOOGLE_API_KEY takes precedence.
export GOOGLE_API_KEY='your-api-key'Gemini API on Vertex AI: Set GOOGLE_GENAI_USE_VERTEXAI,
GOOGLE_CLOUD_PROJECT and GOOGLE_CLOUD_LOCATION, or GOOGLE_API_KEY for
Vertex AI express mode. It's recommended that you set only project & location,
or API key. But if both are set, project & location takes precedence.
export GOOGLE_GENAI_USE_VERTEXAI=true
// Set project and location for Vertex AI authentication
export GOOGLE_CLOUD_PROJECT='your-project-id'
export GOOGLE_CLOUD_LOCATION='us-central1'
// or API key for express mode
export GOOGLE_API_KEY='your-api-key'After configuring the environment variables, you can instantiate a client without passing any variables.
import com.google.genai.Client;
Client client = new Client();By default, the SDK uses the beta API endpoints provided by Google to support
preview features in the APIs. The stable API endpoints can be selected by
setting the API version to v1.
To set the API version use HttpOptions. For example, to set the API version to
v1 for Vertex AI:
import com.google.genai.Client;
import com.google.genai.types.HttpOptions;
Client client = Client.builder()
.project("your-project")
.location("your-location")
.vertexAI(true)
.httpOptions(HttpOptions.builder().apiVersion("v1"))
.build();To set the API version to v1alpha for the Gemini Developer API:
import com.google.genai.Client;
import com.google.genai.types.HttpOptions;
Client client = Client.builder()
.apiKey("your-api-key")
.httpOptions(HttpOptions.builder().apiVersion("v1alpha"))
.build();Besides apiVersion, HttpOptions
also allows for flexible customization of HTTP request parameters such as
baseUrl, headers, and timeout:
HttpOptions httpOptions = HttpOptions.builder()
.baseUrl("your-own-endpoint.com")
.headers(ImmutableMap.of("key", "value"))
.timeout(600)
.build();Beyond client-level configuration, HttpOptions can also be set on a
per-request basis, providing maximum flexibility for diverse API call settings.
See this example
for more details.
ClientOptions
enables you to customize the behavior of the HTTP client. It currently supports
configuring the connection pool via maxConnections (total maximum connections)
and maxConnectionsPerHost (maximum connections to a single host).
import com.google.genai.Client;
import com.google.genai.types.ClientOptions;
Client client = Client.builder()
.apiKey("your-api-key")
.clientOptions(ClientOptions.builder().maxConnections(64).maxConnectionsPerHost(16))
.build();The Google Gen AI Java SDK allows you to access the service programmatically. The following code snippets are some basic usages of model inferencing.
Use generateContent method for the most basic content generation.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.GenerateContentResponse;
public class GenerateContentWithTextInput {
public static void main(String[] args) {
// Instantiate the client. The client by default uses the Gemini API. It
// gets the API key from the environment variable `GOOGLE_API_KEY`.
Client client = new Client();
GenerateContentResponse response =
client.models.generateContent("gemini-2.5-flash", "What is your name?", null);
// Gets the text string from the response by the quick accessor method `text()`.
System.out.println("Unary response: " + response.text());
// Gets the http headers from the response.
response
.sdkHttpResponse()
.ifPresent(
httpResponse ->
System.out.println("Response headers: " + httpResponse.headers().orElse(null)));
}
}package <your package name>;
import com.google.common.collect.ImmutableList;
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
public class GenerateContentWithImageInput {
public static void main(String[] args) {
// Instantiate the client using Vertex API. The client gets the project and
// location from the environment variables `GOOGLE_CLOUD_PROJECT` and
// `GOOGLE_CLOUD_LOCATION`.
Client client = Client.builder().vertexAI(true).build();
// Construct a multimodal content with quick constructors
Content content =
Content.fromParts(
Part.fromText("describe the image"),
Part.fromUri("gs://path/to/image.jpg", "image/jpeg"));
GenerateContentResponse response =
client.models.generateContent("gemini-2.5-flash", content, null);
System.out.println("Response: " + response.text());
}
}To set configurations like System Instructions and Safety Settings, you can pass
a GenerateContentConfig to the GenerateContent method.
package <your package name>;
import com.google.common.collect.ImmutableList;
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.HarmBlockThreshold;
import com.google.genai.types.HarmCategory;
import com.google.genai.types.Part;
import com.google.genai.types.SafetySetting;
import com.google.genai.types.ThinkingConfig;
import com.google.genai.types.Tool;
public class GenerateContentWithConfigs {
public static void main(String[] args) {
Client client = new Client();
// Sets the safety settings in the config.
ImmutableList<SafetySetting> safetySettings =
ImmutableList.of(
SafetySetting.builder()
.category(HarmCategory.Known.HARM_CATEGORY_HATE_SPEECH)
.threshold(HarmBlockThreshold.Known.BLOCK_ONLY_HIGH)
.build(),
SafetySetting.builder()
.category(HarmCategory.Known.HARM_CATEGORY_DANGEROUS_CONTENT)
.threshold(HarmBlockThreshold.Known.BLOCK_LOW_AND_ABOVE)
.build());
// Sets the system instruction in the config.
Content systemInstruction = Content.fromParts(Part.fromText("You are a history teacher."));
// Sets the Google Search tool in the config.
Tool googleSearchTool = Tool.builder().googleSearch(GoogleSearch.builder()).build();
GenerateContentConfig config =
GenerateContentConfig.builder()
// Sets the thinking budget to 0 to disable thinking mode
.thinkingConfig(ThinkingConfig.builder().thinkingBudget(0))
.candidateCount(1)
.maxOutputTokens(1024)
.safetySettings(safetySettings)
.systemInstruction(systemInstruction)
.tools(googleSearchTool)
.build();
GenerateContentResponse response =
client.models.generateContent("gemini-2.5-flash", "Tell me the history of LLM", config);
System.out.println("Response: " + response.text());
}
}The Models.generateContent methods supports automatic function calling (AFC). If the user passes in a list of public static method in the tool list of the GenerateContentConfig, by default AFC will be enabled with maximum remote calls to be 10 times. Follow the following steps to experience this feature.
Step 1: enable the compiler to parse parameter name of your methods. In your
pom.xml, include the following compiler configuration.
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.14.0</version>
<configuration>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
Step 2: see the following code example to use AFC, pay special attention to
the code line where the java.lang.reflect.Method instance was extracted.
import com.google.common.collect.ImmutableList;
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Tool;
import java.lang.reflect.Method;
public class GenerateContentWithFunctionCall {
public static String getCurrentWeather(String location, String unit) {
return "The weather in " + location + " is " + "very nice.";
}
public static void main(String[] args) throws NoSuchMethodException {
Client client = new Client();
// Load the method as a reflected Method object so that it can be
// automatically executed on the client side.
Method method =
GenerateContentWithFunctionCall.class.getMethod(
"getCurrentWeather", String.class, String.class);
GenerateContentConfig config =
GenerateContentConfig.builder()
.tools(Tool.builder().functions(method))
.build();
GenerateContentResponse response =
client.models.generateContent(
"gemini-2.5-flash",
"What is the weather in Vancouver?",
config);
System.out.println("The response is: " + response.text());
System.out.println(
"The automatic function calling history is: "
+ response.automaticFunctionCallingHistory().get());
}
}To get a streamed response, you can use the generateContentStream method:
package <your package name>;
import com.google.genai.Client;
import com.google.genai.ResponseStream;
import com.google.genai.types.GenerateContentResponse;
public class StreamGeneration {
public static void main(String[] args) {
Client client = new Client();
ResponseStream<GenerateContentResponse> responseStream =
client.models.generateContentStream(
"gemini-2.5-flash", "Tell me a story in 300 words.", null);
System.out.println("Streaming response: ");
for (GenerateContentResponse res : responseStream) {
System.out.print(res.text());
}
// To save resources and avoid connection leaks, it is recommended to close the response
// stream after consumption (or using try block to get the response stream).
responseStream.close();
}
}To get a response asynchronously, you can use the generateContent method from
the client.async.models namespace.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.GenerateContentResponse;
import java.util.concurrent.CompletableFuture;
public class GenerateContentAsync {
public static void main(String[] args) {
Client client = new Client();
CompletableFuture<GenerateContentResponse> responseFuture =
client.async.models.generateContent(
"gemini-2.5-flash", "Introduce Google AI Studio.", null);
responseFuture
.thenAccept(
response -> {
System.out.println("Async response: " + response.text());
})
.join();
}
}To get a response in JSON by passing in a response schema to the
GenerateContent API.
package <your package name>;
import com.google.common.collect.ImmutableList;
import com.google.common.collect.ImmutableMap;
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Schema;
import com.google.genai.types.Type;
public class GenerateContentWithSchema {
public static void main(String[] args) {
Client client = new Client();
// Define the schema for the response, in Json format.
ImmutableMap<String, Object> schema = ImmutableMap.of(
"type", "object",
"properties", ImmutableMap.of(
"recipe_name", ImmutableMap.of("type", "string"),
"ingredients", ImmutableMap.of(
"type", "array",
"items", ImmutableMap.of("type", "string")
)
),
"required", ImmutableList.of("recipe_name", "ingredients")
);
// Set the response schema in GenerateContentConfig
GenerateContentConfig config =
GenerateContentConfig.builder()
.responseMimeType("application/json")
.candidateCount(1)
.responseSchema(schema)
.build();
GenerateContentResponse response =
client.models.generateContent("gemini-2.5-flash", "Tell me your name", config);
System.out.println("Response: " + response.text());
}
}The countTokens method allows you to calculate the number of tokens your
prompt will use before sending it to the model, helping you manage costs and
stay within the context window.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.CountTokensResponse;
public class CountTokens {
public static void main(String[] args) {
Client client = new Client();
CountTokensResponse response =
client.models.countTokens("gemini-2.5-flash", "What is your name?", null);
System.out.println("Count tokens response: " + response);
}
}The computeTokens method returns the Tokens Info that contains tokens and
token IDs given your prompt. This method is only supported in Vertex AI.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.ComputeTokensResponse;
public class ComputeTokens {
public static void main(String[] args) {
Client client = Client.builder().vertexAI(true).build();
ComputeTokensResponse response =
client.models.computeTokens("gemini-2.5-flash", "What is your name?", null);
System.out.println("Compute tokens response: " + response);
}
}The embedContent method allows you to generate embeddings for words, phrases,
sentences, and code. Note that only text embedding is supported in this method.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.EmbedContentResponse;
public class EmbedContent {
public static void main(String[] args) {
Client client = new Client();
EmbedContentResponse response =
client.models.embedContent("gemini-embedding-001", "why is the sky blue?", null);
System.out.println("Embedding response: " + response);
}
}Imagen is a text-to-image GenAI service.
The generateImages method helps you create high-quality, unique images given a
text prompt.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.GenerateImagesConfig;
import com.google.genai.types.GenerateImagesResponse;
import com.google.genai.types.Image;
public class GenerateImages {
public static void main(String[] args) {
Client client = new Client();
GenerateImagesConfig config =
GenerateImagesConfig.builder()
.numberOfImages(1)
.outputMimeType("image/jpeg")
.includeSafetyAttributes(true)
.build();
GenerateImagesResponse response =
client.models.generateImages(
"imagen-3.0-generate-002", "Robot holding a red skateboard", config);
response.generatedImages().ifPresent(
images -> {
System.out.println("Generated " + images.size() + " images.");
Image image = images.get(0).image().orElse(null);
// Do something with the image.
}
);
}
}The upscaleImage method allows you to upscale an image. This feature is only
supported in Vertex AI.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.Image;
import com.google.genai.types.UpscaleImageConfig;
import com.google.genai.types.UpscaleImageResponse;
public class UpscaleImage {
public static void main(String[] args) {
Client client = Client.builder().vertexAI(true).build();
Image image = Image.fromFile("path/to/your/image");
UpscaleImageConfig config =
UpscaleImageConfig.builder()
.outputMimeType("image/jpeg")
.enhanceInputImage(true)
.imagePreservationFactor(0.6f)
.build();
UpscaleImageResponse response =
client.models.upscaleImage("imagen-3.0-generate-002", image, "x2", config);
response.generatedImages().ifPresent(
images -> {
Image upscaledImage = images.get(0).image().orElse(null);
// Do something with the upscaled image.
}
);
}
}The editImage method lets you edit an image. You can input reference images
(ex. mask reference for inpainting, or style reference for style transfer) in
addition to a text prompt to guide the editing.
This feature uses a different model than generateImages and upscaleImage. It
is only supported in Vertex AI.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.EditImageConfig;
import com.google.genai.types.EditImageResponse;
import com.google.genai.types.EditMode;
import com.google.genai.types.Image;
import com.google.genai.types.MaskReferenceConfig;
import com.google.genai.types.MaskReferenceImage;
import com.google.genai.types.MaskReferenceMode;
import com.google.genai.types.RawReferenceImage;
import com.google.genai.types.ReferenceImage;
import java.util.ArrayList;
public class EditImage {
public static void main(String[] args) {
Client client = Client.builder().vertexAI(true).build();
Image image = Image.fromFile("path/to/your/image");
// Edit image with a mask.
EditImageConfig config =
EditImageConfig.builder()
.editMode(EditMode.Known.EDIT_MODE_INPAINT_INSERTION)
.numberOfImages(1)
.outputMimeType("image/jpeg")
.build();
ArrayList<ReferenceImage> referenceImages = new ArrayList<>();
RawReferenceImage rawReferenceImage =
RawReferenceImage.builder().referenceImage(image).referenceId(1).build();
referenceImages.add(rawReferenceImage);
MaskReferenceImage maskReferenceImage =
MaskReferenceImage.builder()
.referenceId(2)
.config(
MaskReferenceConfig.builder()
.maskMode(MaskReferenceMode.Known.MASK_MODE_BACKGROUND)
.maskDilation(0.0f))
.build();
referenceImages.add(maskReferenceImage);
EditImageResponse response =
client.models.editImage(
"imagen-3.0-capability-001", "Sunlight and clear sky", referenceImages, config);
response.generatedImages().ifPresent(
images -> {
Image editedImage = images.get(0).image().orElse(null);
// Do something with the edited image.
}
);
}
}Veo is a video generation GenAI service.
package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.GenerateVideosConfig;
import com.google.genai.types.GenerateVideosOperation;
import com.google.genai.types.Video;
public class GenerateVideosWithText {
public static void main(String[] args) {
Client client = new Client();
GenerateVideosConfig config =
GenerateVideosConfig.builder()
.numberOfVideos(1)
.enhancePrompt(true)
.durationSeconds(5)
.build();
// generateVideos returns an operation
GenerateVideosOperation operation =
client.models.generateVideos(
"veo-2.0-generate-001", "A neon hologram of a cat driving at top speed", null, config);
// When the operation hasn't been finished, operation.done() is empty
while (!operation.done().isPresent()) {
try {
System.out.println("Waiting for operation to complete...");
Thread.sleep(10000);
// Sleep for 10 seconds and check the operation again
operation = client.operations.getVideosOperation(operation, null);
} catch (InterruptedException e) {
System.out.println("Thread was interrupted while sleeping.");
Thread.currentThread().interrupt();
}
}
operation.response().ifPresent(
response -> {
response.generatedVideos().ifPresent(
videos -> {
System.out.println("Generated " + videos.size() + " videos.");
Video video = videos.get(0).video().orElse(null);
// Do something with the generated video
}
);
}
);
}
}package <your package name>;
import com.google.genai.Client;
import com.google.genai.types.GenerateVideosConfig;
import com.google.genai.types.GenerateVideosOperation;
import com.google.genai.types.Image;
import com.google.genai.types.Video;
public class GenerateVideosWithImage {
public static void main(String[] args) {
Client client = new Client();
Image image = Image.fromFile("path/to/your/image");
GenerateVideosConfig config =
GenerateVideosConfig.builder()
.numberOfVideos(1)
.enhancePrompt(true)
.durationSeconds(5)
.build();
// generateVideos returns an operation
GenerateVideosOperation operation =
client.models.generateVideos(
"veo-2.0-generate-001",
"Night sky",
image,
config);
// When the operation hasn't been finished, operation.done() is empty
while (!operation.done().isPresent()) {
try {
System.out.println("Waiting for operation to complete...");
Thread.sleep(10000);
// Sleep for 10 seconds and check the operation again
operation = client.operations.getVideosOperation(operation, null);
} catch (InterruptedException e) {
System.out.println("Thread was interrupted while sleeping.");
Thread.currentThread().interrupt();
}
}
operation.response().ifPresent(
response -> {
response.generatedVideos().ifPresent(
videos -> {
System.out.println("Generated " + videos.size() + " videos.");
Video video = videos.get(0).video().orElse(null);
// Do something with the generated video
}
);
}
);
}
}This library follows Semantic Versioning.
The Google Gen AI Java SDK will accept contributions in the future.
Apache 2.0 - See LICENSE for more information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for java-genai
Similar Open Source Tools
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
OpenAI-DotNet
OpenAI-DotNet is a simple C# .NET client library for OpenAI to use through their RESTful API. It is independently developed and not an official library affiliated with OpenAI. Users need an OpenAI API account to utilize this library. The library targets .NET 6.0 and above, working across various platforms like console apps, winforms, wpf, asp.net, etc., and on Windows, Linux, and Mac. It provides functionalities for authentication, interacting with models, assistants, threads, chat, audio, images, files, fine-tuning, embeddings, and moderations.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.
UniChat
UniChat is a pipeline tool for creating online and offline chat-bots in Unity. It leverages Unity.Sentis and text vector embedding technology to enable offline mode text content search based on vector databases. The tool includes a chain toolkit for embedding LLM and Agent in games, along with middleware components for Text to Speech, Speech to Text, and Sub-classifier functionalities. UniChat also offers a tool for invoking tools based on ReActAgent workflow, allowing users to create personalized chat scenarios and character cards. The tool provides a comprehensive solution for designing flexible conversations in games while maintaining developer's ideas.
dashscope-sdk
DashScope SDK for .NET is an unofficial SDK maintained by Cnblogs, providing various APIs for text embedding, generation, multimodal generation, image synthesis, and more. Users can interact with the SDK to perform tasks such as text completion, chat generation, function calls, file operations, and more. The project is under active development, and users are advised to check the Release Notes before upgrading.
ElevenLabs-DotNet
ElevenLabs-DotNet is a non-official Eleven Labs voice synthesis RESTful client that allows users to convert text to speech. The library targets .NET 8.0 and above, working across various platforms like console apps, winforms, wpf, and asp.net, and across Windows, Linux, and Mac. Users can authenticate using API keys directly, from a configuration file, or system environment variables. The tool provides functionalities for text to speech conversion, streaming text to speech, accessing voices, dubbing audio or video files, generating sound effects, managing history of synthesized audio clips, and accessing user information and subscription status.

js-genai
The Google Gen AI JavaScript SDK is an experimental SDK for TypeScript and JavaScript developers to build applications powered by Gemini. It supports both the Gemini Developer API and Vertex AI. The SDK is designed to work with Gemini 2.0 features. Users can access API features through the GoogleGenAI classes, which provide submodules for querying models, managing caches, creating chats, uploading files, and starting live sessions. The SDK also allows for function calling to interact with external systems. Users can find more samples in the GitHub samples directory.
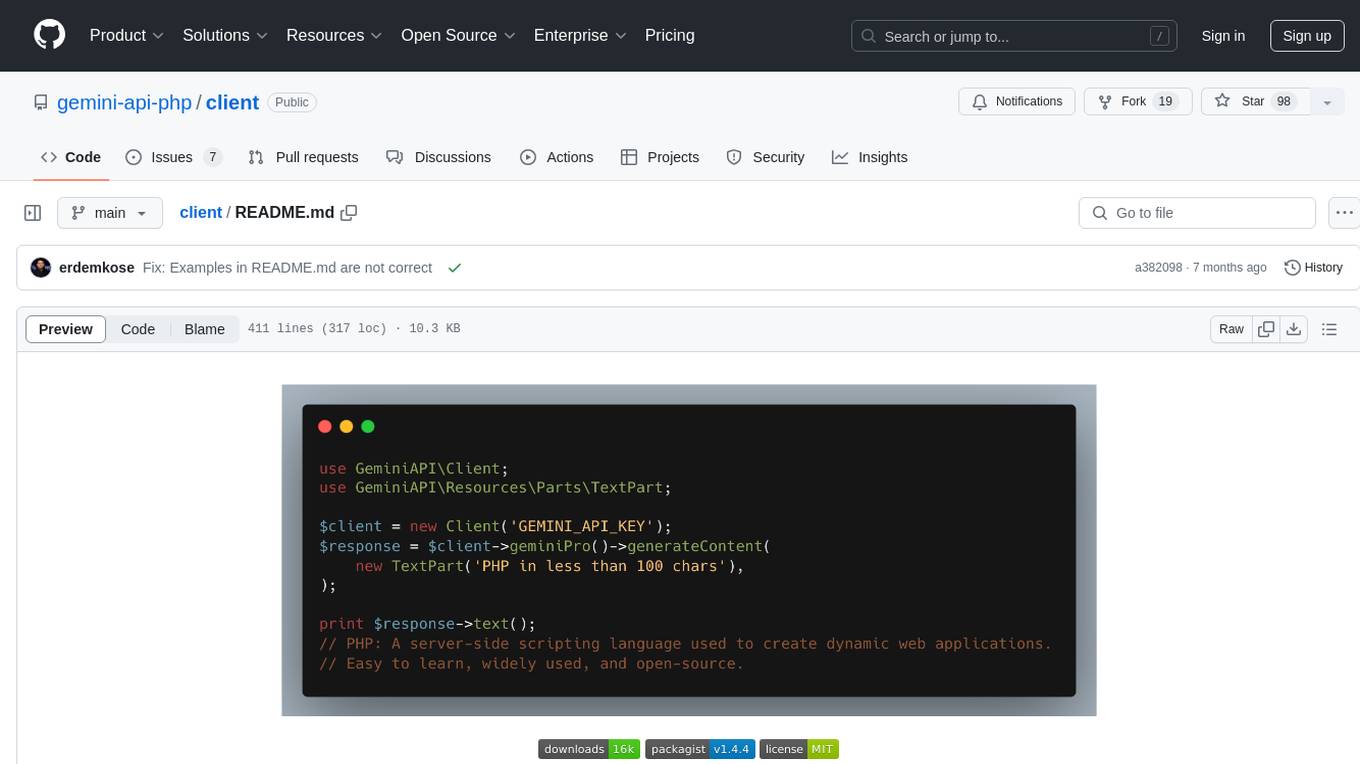
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
whetstone.chatgpt
Whetstone.ChatGPT is a simple light-weight library that wraps the Open AI API with support for dependency injection. It supports features like GPT 4, GPT 3.5 Turbo, chat completions, audio transcription and translation, vision completions, files, fine tunes, images, embeddings, moderations, and response streaming. The library provides a video walkthrough of a Blazor web app built on it and includes examples such as a command line bot. It offers quickstarts for dependency injection, chat completions, completions, file handling, fine tuning, image generation, and audio transcription.

generative-ai-python
The Google AI Python SDK is the easiest way for Python developers to build with the Gemini API. The Gemini API gives you access to Gemini models created by Google DeepMind. Gemini models are built from the ground up to be multimodal, so you can reason seamlessly across text, images, and code.
bellman
Bellman is a unified interface to interact with language and embedding models, supporting various vendors like VertexAI/Gemini, OpenAI, Anthropic, VoyageAI, and Ollama. It consists of a library for direct interaction with models and a service 'bellmand' for proxying requests with one API key. Bellman simplifies switching between models, vendors, and common tasks like chat, structured data, tools, and binary input. It addresses the lack of official SDKs for major players and differences in APIs, providing a single proxy for handling different models. The library offers clients for different vendors implementing common interfaces for generating and embedding text, enabling easy interchangeability between models.
Ollama
Ollama SDK for .NET is a fully generated C# SDK based on OpenAPI specification using OpenApiGenerator. It supports automatic releases of new preview versions, source generator for defining tools natively through C# interfaces, and all modern .NET features. The SDK provides support for all Ollama API endpoints including chats, embeddings, listing models, pulling and creating new models, and more. It also offers tools for interacting with weather data and providing weather-related information to users.
mcpdotnet
mcpdotnet is a .NET implementation of the Model Context Protocol (MCP), facilitating connections and interactions between .NET applications and MCP clients and servers. It aims to provide a clean, specification-compliant implementation with support for various MCP capabilities and transport types. The library includes features such as async/await pattern, logging support, and compatibility with .NET 8.0 and later. Users can create clients to use tools from configured servers and also create servers to register tools and interact with clients. The project roadmap includes expanding documentation, increasing test coverage, adding samples, performance optimization, SSE server support, and authentication.
openrouter-kit
OpenRouter Kit is a powerful TypeScript/JavaScript library for interacting with the OpenRouter API. It simplifies working with LLMs by providing a high-level API for chats, dialogue history management, tool calls with error handling, security module, and cost tracking. Ideal for building chatbots, AI agents, and integrating LLMs into applications.

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
For similar tasks
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.
stable-diffusion-prompt-reader
A simple standalone viewer for reading prompt from Stable Diffusion generated image outside the webui. The tool supports macOS, Windows, and Linux, providing both GUI and CLI functionalities. Users can interact with the tool through drag and drop, copy prompt to clipboard, remove prompt from image, export prompt to text file, edit or import prompt to images, and more. It supports multiple formats including PNG, JPEG, WEBP, TXT, and various tools like A1111's webUI, Easy Diffusion, StableSwarmUI, Fooocus-MRE, NovelAI, InvokeAI, ComfyUI, Draw Things, and Naifu(4chan). Users can download the tool for different platforms and install it via Homebrew Cask or pip. The tool can be used to read, export, remove, and edit prompts from images, providing various modes and options for different tasks.
InternGPT
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.