
LLM_MultiAgents_Survey_Papers
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Stars: 225
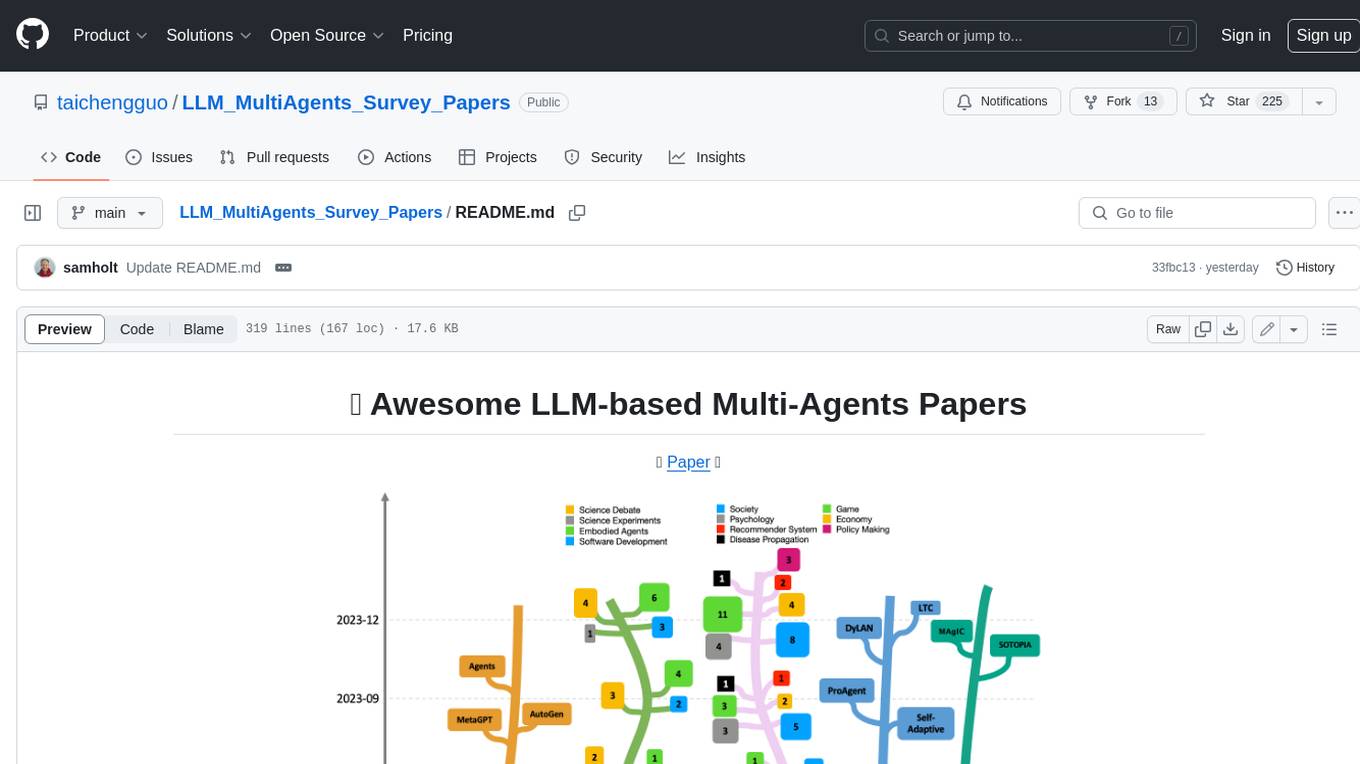
This repository maintains a list of research papers on LLM-based Multi-Agents, categorized into five main streams: Multi-Agents Framework, Multi-Agents Orchestration and Efficiency, Multi-Agents for Problem Solving, Multi-Agents for World Simulation, and Multi-Agents Datasets and Benchmarks. The repository also includes a survey paper on LLM-based Multi-Agents and a table summarizing the key findings of the survey.
README:
🔥 Paper 🔥

Our survey about LLM based Multi-Agents is available at: https://arxiv.org/abs/2402.01680
Our summarized LLM-based Multi-Agents architecture is:

The Overview table is as follows. More details can be seen in our paper. Very appreciate any suggestions.

[2024/02] We will update our paper list every two weeks and include all the following papers in the next version of our paper. Please Feel free to contact me in case we have missed any papers!
[2024/01] This repo is created to maintain LLM-based Multi-Agents papers. We categorized these papers into five main streams:
- Multi-Agents Framework
- Multi-Agents Orchestration and Efficiency
- Multi-Agents for Problem Solving
- Multi-Agents for World Simulation
- Multi-Agents Datasets and Benchmarks
- Multi-Agents Framework
- Multi-Agents Orchestration and Efficiency
- Multi-Agents for Problem Solving
- Multi-Agents for World Simulation
- Multi-Agents Datasets and Benchmarks
- Contributing
- Contact
[2024/03] Are More LLM Calls All You Need? Towards Scaling Laws of Compound Inference Systems. Lingjiao Chen et al. [paper]
[2024/02] Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key?. Qineng Wang et al. [paper]
[2024/02] AgentLite: A Lightweight Library for Building and Advancing Task-Oriented LLM Agent System. Zhiwei Liu et al. [paper]
[2023/12] Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia. Alexander Sasha Vezhnevets et al. [paper]
[2023/10] L2MAC: Large Language Model Automatic Computer for Extensive Code Generation. Samuel Holt et al. [paper]
[2023/10] OpenAgents: An Open Platform for Language Agents in the Wild. Tianbao Xie et al. [paper]
[2023/10] MetaAgents: Simulating Interactions of Human Behaviors for LLM-based Task-oriented Coordination via Collaborative Generative Agents. Yuan Li et al. [paper]
[2023/09] AutoAgents: A Framework for Automatic Agent Generation. Guangyao Chen et al. [paper]
[2023/09] Agents: An Open-source Framework for Autonomous Language Agents. Wangchunshu Zhou et al. [paper]
[2023/08] AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. Weize Chen et al. [paper]
[2023/08] AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. Qingyun Wu et al. [paper]
[2023/08] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. Sirui Hong et al. [paper]
[2023/03] CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society. Guohao Li et al. [paper]
[2024/02] Language Agents as Optimizable Graphs. Mingchen Zhuge et al. [paper]
[2024/02] More Agents Is All You Need. Junyou Li et al. [paper]
[2023/11] Controlling Large Language Model-based Agents for Large-Scale Decision-Making: An Actor-Critic Approach. Bin Zhang et al. [paper]
[2023/11] crewAI. joaomdmoura et al. [repo]
[2023/10] Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization. Zijun Liu et al. [paper]
[2023/10] Adapting LLM Agents Through Communication. Kuan Wang et al. [paper]
[2023/08] ProAgent: Building Proactive Cooperative AI with Large Language Models. Ceyao Zhang et al. [paper]
[2023/07] Self-Adaptive Large Language Model (LLM)-Based Multiagent Systems. Nathalia Nascimento et al. [paper]
[2023/07] Unleashing Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration. Zhenhailong Wang et al. [paper]
[2023/05] Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. Tian Liang et al. [paper]
[2024/02] Can Large Language Models Serve as Data Analysts? A Multi-Agent Assisted Approach for Qualitative Data Analysis. Zeeshan Rasheed et al. [paper]
[2024/01] XUAT-Copilot: Multi-Agent Collaborative System for Automated User Acceptance Testing with Large Language Model. Zhitao Wang et al. [paper]
[2023/12] AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation. Dong Huang et al. [paper]
[2023/10] L2MAC: Large Language Model Automatic Computer for Extensive Code Generation. Samuel Holt et al. [paper]
[2023/08] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. Sirui Hong et al. [paper]
[2023/07] Communicative agents for software development. Chen Qian et al. [paper]
[2023/04] Self-collaboration Code Generation via ChatGPT. Yihong Dong et al. [paper]
[2023/10] Multi-Agent Consensus Seeking via Large Language Models. Huaben Chen et al. [paper]
[2023/10] Co-NavGPT: Multi-Robot Cooperative Visual Semantic Navigation using Large Language Models. Bangguo Yu et al. [paper]
[2023/09] Scalable Multi-Robot Collaboration with Large Language Models: Centralized or Decentralized Systems?. Yongchao Chen et al. [paper]
[2023/07] RoCo: Dialectic Multi-Robot Collaboration with Large Language Models. Zhao Mandi et al. [paper]
[2023/07] Building Cooperative Embodied Agents Modularly with Large Language Models. Hongxin Zhang et al. [paper]
[2023/02] Collaborating with language models for embodied reasoning. Ishita Dasgupta et al. [paper]
[2024/01] ProtAgents: Protein discovery via large language model multi-agent collaborations combining physics and machine learning. A. Ghafarollahi et al. [paper]
[2023/11] ChatGPT Research Group for Optimizing the Crystallinity of MOFs and COFs. Zhiling Zheng et al. [paper]
[2023/04] ChemCrow: Augmenting large-language models with chemistry tools. Andres M Bran et al. [paper]
[2023/04] Emergent autonomous scientific research capabilities of large language models. Daniil A. Boiko et al. [paper]
[2024/01] Enhancing Diagnostic Accuracy through Multi-Agent Conversations: Using Large Language Models to Mitigate Cognitive Bias. Yu He Ke et al. [paper]
[2023/11] MechAgents: Large language model multi-agent collaborations can solve mechanics problems, generate new data, and integrate knowledge. Bo Ni et al. [paper]
[2023/11] MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. Xiangru Tang et al. [paper]
[2023/08] ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. Chi-Min Chan et al. [paper]
[2023/05] Improving Factuality and Reasoning in Language Models through Multiagent Debate. Yilun Du et al. [paper]
[2023/05] Examining Inter-Consistency of Large Language Models Collaboration: An In-depth Analysis via Debate. Kai Xiong et al. [paper]
[2023/12] D-Bot: Database Diagnosis System using Large Language Models. et al. [paper]
[2023/08] LLM As DBA. et al. [paper]
[2024/02] Can Large Language Model Agents Simulate Human Trust Behaviors? Chengxing Xie et al. [paper]
[2023/12] Large Language Model Enhanced Multi-Agent Systems for 6G Communications. Feibo Jiang et al. [paper]
[2023/10] Multi-Agent Consensus Seeking via Large Language Models. Huaben Chen et al. [paper]
[2023/10] Lyfe Agents: Generative agents for low-cost real-time social interactions. Zhao Kaiya et al. [paper]
[2023/08] Quantifying the Impact of Large Language Models on Collective Opinion Dynamics. Chao Li et al. [paper]
[2023/07] S3 Social-network Simulation System with Large Language Model-Empowered Agents. Chen Gao et al. [paper]
[2023/07] Are you in a Masquerade? Exploring the Behavior and Impact of Large Language Model Driven Social Bots in Online Social Networks. Siyu Li et al. [paper]
[2023/06] User Behavior Simulation with Large Language Model based Agents. Lei Wang et al. [paper]
[2023/05] Can Large Language Models Transform Computational Social Science?. Caleb Ziems et al. [paper]
[2023/04] Generative Agents- Interactive Simulacra of Human Behavior. Joon Sung Park et al. [paper]
[2022/10] Social simulacra: Creating populated prototypes for social computing systems. Joon Sung Park et al. [paper]
[2023/12] Deciphering Digital Detectives: Understanding LLM Behaviors and Capabilities in Multi-Agent Mystery Games. Dekun Wu et al. [paper]
[2023/12] Can Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis. Caoyun Fan et al. [paper]
[2023/11] ALYMPICS: Language Agents Meet Game Theory. Shaoguang Mao et al. [paper]
[2023/10] Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game. Zelai Xu et al. [paper]
[2023/10] Theory of Mind for Multi-Agent Collaboration via Large Language Models. Huao Li et al. [paper]
[2023/10] Welfare Diplomacy: Benchmarking Language Model Cooperation. Gabriel Mukobi et al. [paper]
[2023/10] GameGPT: Multi-agent Collaborative Framework for Game Development. Dake Chen et al. [paper]
[2023/10] AVALONBENCH: Evaluating LLMs Playing the Game of Avalon. Jonathan Light et al. [paper]
[2023/10] Avalon’s Game of Thoughts: Battle Against Deception through Recursive Contemplation. Shenzhi Wang et al. [paper]
[2023/09] MindAgent: Emergent Gaming Interaction. Ran Gong et al. [paper]
[2023/09] Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf. Yuzhuang Xu et al. [paper]
[2023/05] Playing repeated games with Large Language Models. Elif Akata et al. [paper]
[2023/07] Understanding the Benefits and Challenges of Using Large Language Model-based Conversational Agents for Mental Well-being Support. Zilin Ma et al. [paper]
[2023/07] The SocialAI School: Insights from Developmental Psychology Towards Artificial Socio-Cultural Agents. Grgur Kovač et al. [paper]
[2022/10] Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View. Jintian Zhang et al. [paper]
[2022/08] Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. Gati Aher et al. [paper]
[2023/10] CompeteAI: Understanding the Competition Behaviors in Large Language Model-based Agents. Qinlin Zhao et al. [paper]
[2023/10] Large Language Model-Empowered Agents for Simulating Macroeconomic Activities. Nian Li et al. [paper]
[2023/09] Rethinking the Buyer’s Inspection Paradox in Information Markets with Language Agents. et al. [paper]
[2023/09] TradingGPT: Multi-Agent System with Layered Memory and Distinct Characters for Enhanced Financial Trading Performance. Yang Li et al. [paper]
[2023/01] Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus?. John J. Horton et al. [paper]
[2023/10] On Generative Agents in Recommendation. An Zhang et al. [paper]
[2023/10] AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems. Junjie Zhang et al. [paper]
[2023/11] War and Peace (WarAgent): Large Language Model-based Multi-Agent Simulation of World Wars. Wenyue Hua et al. [paper]
[2023/11] Simulating Public Administration Crisis: A Novel Generative Agent-Based Simulation System to Lower Technology Barriers in Social Science Research. Bushi Xiao et al. [paper]
[2023/10] Multi-Agent Consensus Seeking via Large Language Models. Huaben Chen et al. [paper]
[2023/09] Generative Agent-Based Modeling: Unveiling Social System Dynamics through Coupling Mechanistic Models with Generative Artificial Intelligence. Navid Ghaffarzadegan et al. [paper]
[2023/07] Epidemic modeling with generative agents. Ross Williams et al. [paper]
[2024/02] LLMArena: Assessing Capabilities of Large Language Models in Dynamic Multi-Agent Environments. Junzhe Chen et al. [paper]
[2023/11] Towards Reasoning in Large Language Models via Multi-Agent Peer Review Collaboration. Zhenran Xu et al. [paper]
[2023/11] MAgIC: Investigation of Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration. Lin Xu et al. [paper]
[2023/10] SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents. Xuhui Zhou et al. [paper]
[2023/10] Evaluating Multi-Agent Coordination Abilities in Large Language Models. Saaket Agashe et al. [paper]
[2023/09] LLM-Deliberation: Evaluating LLMs with Interactive Multi-Agent Negotiation Games. Sahar Abdelnabi et al. [paper]
Because the LLM-based Multi-Agents is a fast-growing research field, we may miss some important related papers. Very welcome contributions to this repository! Please feel free to submit a pull request or open an issue if you have anything to add or comment.
Thanks!
Taicheng Guo
- Email: [email protected]
- Twitter: https://twitter.com/taioooorange
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM_MultiAgents_Survey_Papers
Similar Open Source Tools
LLM_MultiAgents_Survey_Papers
This repository maintains a list of research papers on LLM-based Multi-Agents, categorized into five main streams: Multi-Agents Framework, Multi-Agents Orchestration and Efficiency, Multi-Agents for Problem Solving, Multi-Agents for World Simulation, and Multi-Agents Datasets and Benchmarks. The repository also includes a survey paper on LLM-based Multi-Agents and a table summarizing the key findings of the survey.
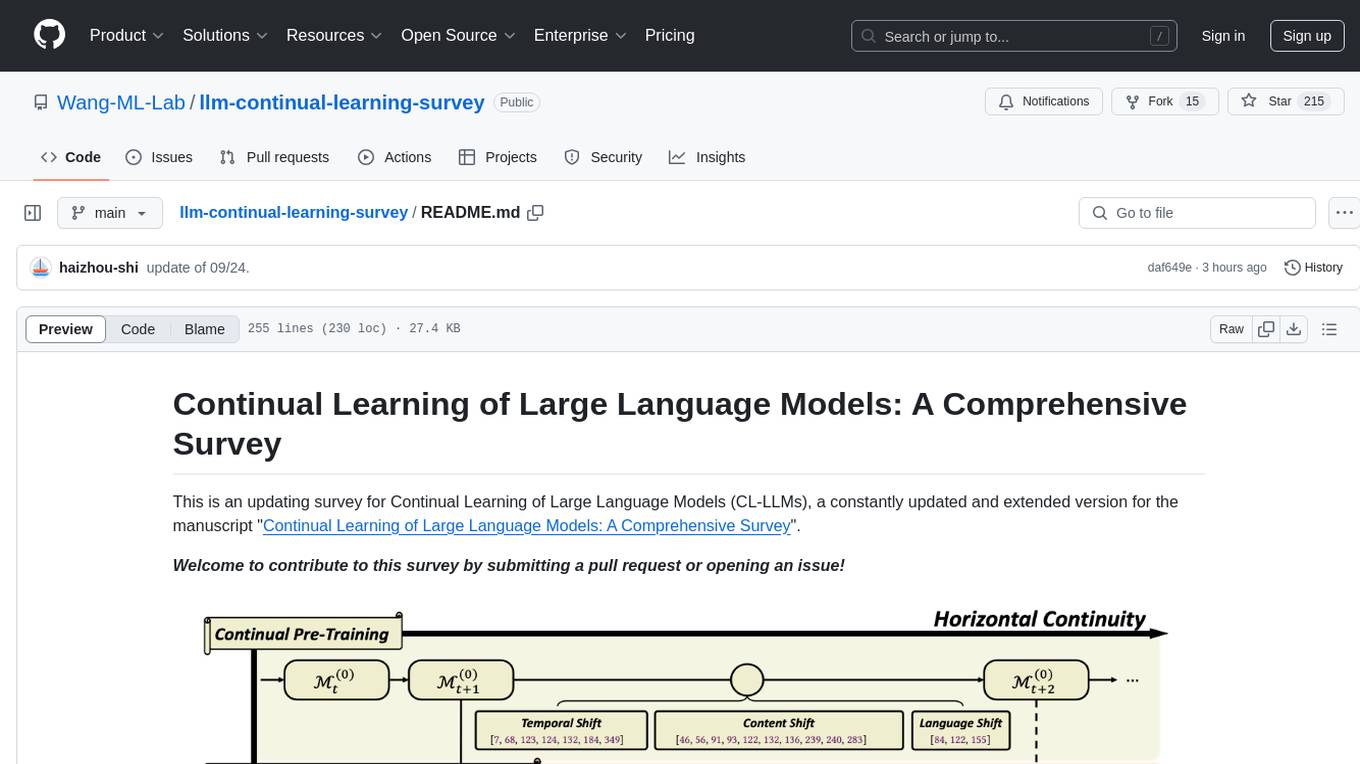
llm-continual-learning-survey
This repository is an updating survey for Continual Learning of Large Language Models (CL-LLMs), providing a comprehensive overview of various aspects related to the continual learning of large language models. It covers topics such as continual pre-training, domain-adaptive pre-training, continual fine-tuning, model refinement, model alignment, multimodal LLMs, and miscellaneous aspects. The survey includes a collection of relevant papers, each focusing on different areas within the field of continual learning of large language models.
LLM-and-Law
This repository is dedicated to summarizing papers related to large language models with the field of law. It includes applications of large language models in legal tasks, legal agents, legal problems of large language models, data resources for large language models in law, law LLMs, and evaluation of large language models in the legal domain.
Recommendation-Systems-without-Explicit-ID-Features-A-Literature-Review
This repository is a collection of papers and resources related to recommendation systems, focusing on foundation models, transferable recommender systems, large language models, and multimodal recommender systems. It explores questions such as the necessity of ID embeddings, the shift from matching to generating paradigms, and the future of multimodal recommender systems. The papers cover various aspects of recommendation systems, including pretraining, user representation, dataset benchmarks, and evaluation methods. The repository aims to provide insights and advancements in the field of recommendation systems through literature reviews, surveys, and empirical studies.
Awesome-LLM4RS-Papers
This paper list is about Large Language Model-enhanced Recommender System. It also contains some related works. Keywords: recommendation system, large language models
Awesome-LLM-Survey
This repository, Awesome-LLM-Survey, serves as a comprehensive collection of surveys related to Large Language Models (LLM). It covers various aspects of LLM, including instruction tuning, human alignment, LLM agents, hallucination, multi-modal capabilities, and more. Researchers are encouraged to contribute by updating information on their papers to benefit the LLM survey community.
Awesome-LLM-in-Social-Science
This repository compiles a list of academic papers that evaluate, align, simulate, and provide surveys or perspectives on the use of Large Language Models (LLMs) in the field of Social Science. The papers cover various aspects of LLM research, including assessing their alignment with human values, evaluating their capabilities in tasks such as opinion formation and moral reasoning, and exploring their potential for simulating social interactions and addressing issues in diverse fields of Social Science. The repository aims to provide a comprehensive resource for researchers and practitioners interested in the intersection of LLMs and Social Science.
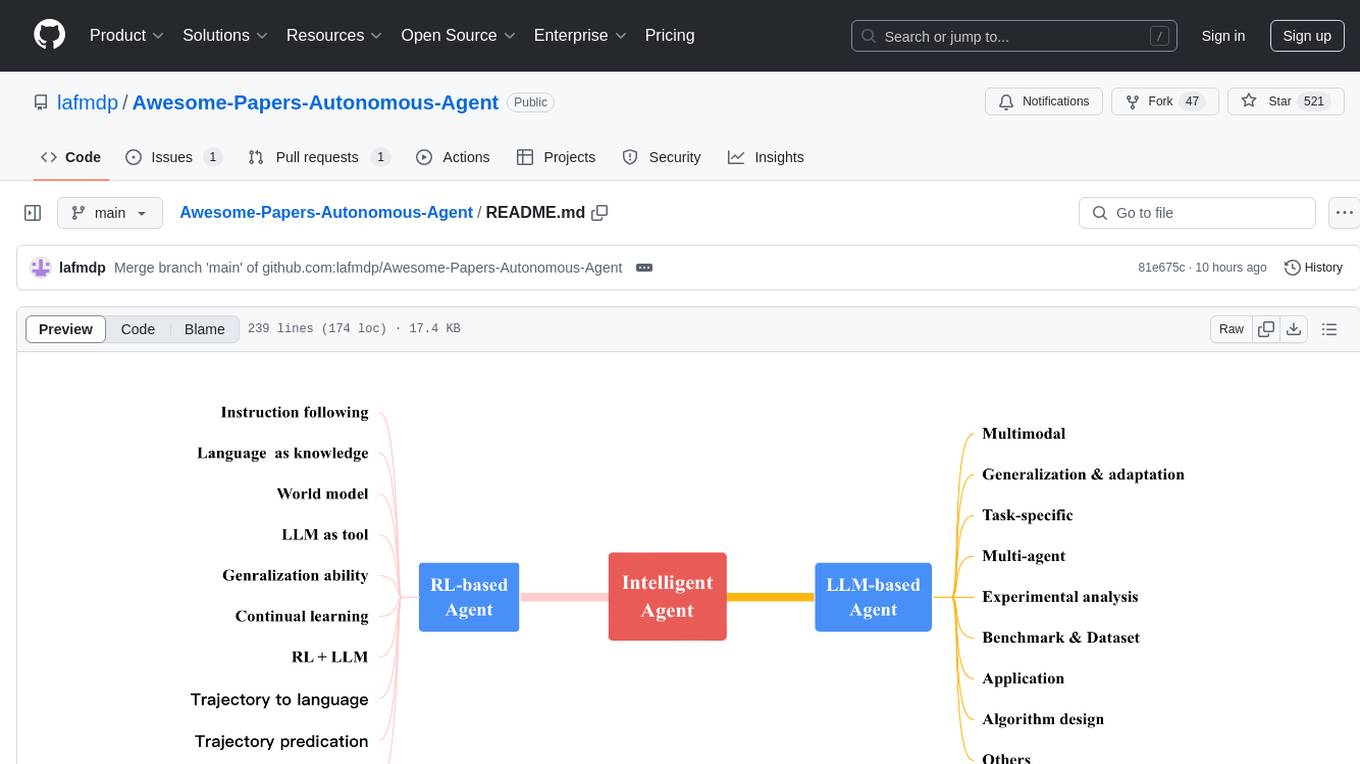
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.
Medical_Image_Analysis
The Medical_Image_Analysis repository focuses on X-ray image-based medical report generation using large language models. It provides pre-trained models and benchmarks for CheXpert Plus dataset, context sample retrieval for X-ray report generation, and pre-training on high-definition X-ray images. The goal is to enhance diagnostic accuracy and reduce patient wait times by improving X-ray report generation through advanced AI techniques.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
ChatLaw
ChatLaw is an open-source legal large language model tailored for Chinese legal scenarios. It aims to combine LLM and knowledge bases to provide solutions for legal scenarios. The models include ChatLaw-13B and ChatLaw-33B, trained on various legal texts to construct dialogue data. The project focuses on improving logical reasoning abilities and plans to train models with parameters exceeding 30B for better performance. The dataset consists of forum posts, news, legal texts, judicial interpretations, legal consultations, exam questions, and court judgments, cleaned and enhanced to create dialogue data. The tool is designed to assist in legal tasks requiring complex logical reasoning, with a focus on accuracy and reliability.
interpret
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. With this package, you can train interpretable glassbox models and explain blackbox systems. InterpretML helps you understand your model's global behavior, or understand the reasons behind individual predictions. Interpretability is essential for: - Model debugging - Why did my model make this mistake? - Feature Engineering - How can I improve my model? - Detecting fairness issues - Does my model discriminate? - Human-AI cooperation - How can I understand and trust the model's decisions? - Regulatory compliance - Does my model satisfy legal requirements? - High-risk applications - Healthcare, finance, judicial, ...
ai-agents
The 'ai-agents' repository is a collection of books and resources focused on developing AI agents, including topics such as GPT models, building AI agents from scratch, machine learning theory and practice, and basic methods and tools for data analysis. The repository provides detailed explanations and guidance for individuals interested in learning about and working with AI agents.
For similar tasks

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
auto-dev
AutoDev is an AI-powered coding wizard that supports multiple languages, including Java, Kotlin, JavaScript/TypeScript, Rust, Python, Golang, C/C++/OC, and more. It offers a range of features, including auto development mode, copilot mode, chat with AI, customization options, SDLC support, custom AI agent integration, and language features such as language support, extensions, and a DevIns language for AI agent development. AutoDev is designed to assist developers with tasks such as auto code generation, bug detection, code explanation, exception tracing, commit message generation, code review content generation, smart refactoring, Dockerfile generation, CI/CD config file generation, and custom shell/command generation. It also provides a built-in LLM fine-tune model and supports UnitEval for LLM result evaluation and UnitGen for code-LLM fine-tune data generation.

LLM4SE
The collection is actively updated with the help of an internal literature search engine.
Awesome-Code-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, in lowercase letters: 'description' (detailed description of the repo, must be less than 400 words,Ensure that no line breaks and quotation marks.),'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,user may use those keyword to find the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in lowercase letters), 'answer' (in english languages)

crewAI
crewAI is a cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It provides a flexible and structured approach to AI collaboration, enabling users to define agents with specific roles, goals, and tools, and assign them tasks within a customizable process. crewAI supports integration with various LLMs, including OpenAI, and offers features such as autonomous task delegation, flexible task management, and output parsing. It is open-source and welcomes contributions, with a focus on improving the library based on usage data collected through anonymous telemetry.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.