
NL2SQL_Handbook
[TKDE'25] This is a continuously updated handbook for readers to easily track the latest Text-to-SQL techniques in the literature and provide practical guidance for researchers and practitioners. Official repo for A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going?
Stars: 952
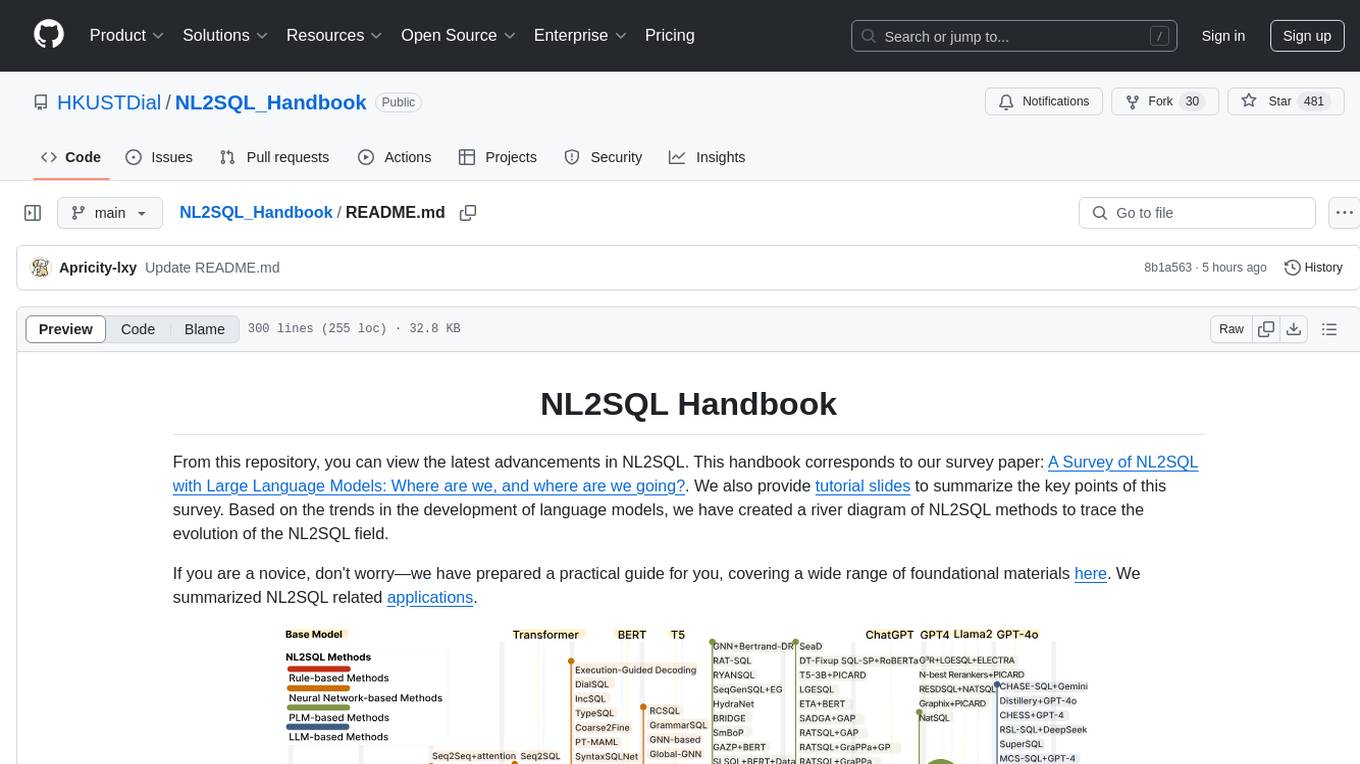
NL2SQL Handbook provides a comprehensive overview of Natural Language to SQL (NL2SQL) advancements, including survey papers, tutorial slides, and a river diagram of NL2SQL methods. It covers the evolution of NL2SQL solutions, module-based methods, benchmark development, and future directions. The repository also offers practical guides for beginners, access to high-performance language models, and evaluation metrics for NL2SQL models.
README:
From this repository, you can view the 📚latest advancements in Text-to-SQL (a.k.a NL2SQL). This handbook corresponds to our survey paper[TKDE'2025]: 📖A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going?. We also provide tutorial slides for VLDB'2025 Tutorial and summarize the key points of this survey. Based on language model trends, we've created a river diagram of Text-to-SQL methods to trace the field's evolution.
If you are a novice, don't worry—we have prepared a practical guide for you, covering a wide range of foundational materials and related applications. 📧If we missed any interesting work, connect with us.

@article{liu2025survey,
title={A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going?},
author={Liu, Xinyu and Shen, Shuyu and Li, Boyan and Ma, Peixian and Jiang, Runzhi and Zhang, Yuxin and Fan, Ju and Li, Guoliang and Tang, Nan and Luo, Yuyu},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2025},
publisher={IEEE}
}Translating users' natural language queries (NL) into SQL queries can significantly reduce barriers to accessing relational databases and support various commercial applications. The performance of Text-to-SQL has been greatly improved with the emergence of language models (LMs). In this context, it is crucial to assess our current position, determine the Text-to-SQL solutions that should be adopted for specific scenarios by practitioners, and identify the research topics that researchers should explore next.


-
Model: Text-to-SQL translation techniques that tackle not only NL ambiguity and under-specification, but also properly map NL with database schema and instances;
-
Data: From the collection of training data, data synthesis due to training data scarcity, to Text-to-SQL benchmarks;
-
Evaluation: Evaluating Text-to-SQL methods from multiple angles using different metrics and granularities;
-
Error Analysis: analyzing Text-to-SQL errors to find the root cause and guiding Text-to-SQL models to evolve.
We categorize the challenges of Text-to-SQL into five levels, each addressing specific hurdles. The first three levels cover challenges that have been or are currently being addressed, reflecting the progressive development of Text-to-SQL. The fourth level represents the challenges we aim to tackle in the LLMs stage, while the fifth level outlines our vision for Text-to-SQL system in the next five years.
We describe the evolution of Text-to-SQL solutions from the perspective of language models, categorizing it into four stages. For each stage of Text-to-SQL, we analyze the changes in target users and the extent to which challenges are addressed.

We summarize the key modules of Text-to-SQL solutions utilizing the language model.
- Pre-processing serves as an enhancement to the model’s inputs in the Text-to-SQL parsing process. You can get more details from this chapter: Pre-Processing
- Text-to-SQL translation methods constitute the core of the Text-to-SQL solution, responsible for converting input natural language queries into SQL queries. You can get more details from this chapter: Text-to-SQL Translation Methods
- Post-processing is a crucial step to refine the generated SQL queries, ensuring they meet user expectations more accurately. You can get more details from this chapter: Post-Processing

- A Survey of Text-to-SQL in the Era of LLMs:
Where are we, and where are we going?
- Natural Language to SQL: State of the Art and Open Problems.
- A Survey on Employing Large Language Models for Text-to-SQL Tasks.
- Next-generation database interfaces: A survey of LLM-based Text-to-SQL.
- Large Language Model Enhanced Text-to-SQL Generation: A Survey.
- From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems.
- Natural language interfaces for tabular data querying and visualization: A survey.
- Natural Language Interfaces for Databases with Deep Learning.
- A survey on deep learning approaches for text-to-SQL.
- Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect.
- A Deep Dive into Deep Learning Approaches for Text-to-SQL Systems.
- State of the Art and Open Challenges in Natural Language Interfaces to Data.
- Natural language to SQL: Where are we today?
- Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search
- NL2SQL-BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation.
- EllieSQL: Cost-Efficient Text-to-SQL with Complexity-Aware Routing.
- Structure-Guided Large Language Models for Text-to-SQL Generation.
- Sphinteract: Resolving Ambiguities in NL2SQL Through User Interaction.
- OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.
- EVOSCHEMA: TOWARDS TEXT-TO-SQL ROBUSTNESS AGAINST SCHEMA EVOLUTION.
- Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL.
- The Power of Constraints in Natural Language to SQL Translation.
- OpenSearch-SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Alignment.
- Reliable Text-to-SQL with Adaptive Abstention.
- SNAILS: Schema Naming Assessments for Improved LLM-Based SQL Inference.
- Automated Validating and Fixing of Text-to-SQL Translation with Execution Consistency.
- Grounding Natural Language to SQL Translation with Data-Based Self-Explanations.
- AID-SQL: Adaptive In-Context Learning of Text-to-SQL with Difficulty-Aware Instruction and Retrieval-Augmented Generation.
- CLEAR: A Parser-Independent Disambiguation Framework for NL2SQL.
- CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL.
- Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows.
- ROUTE: Robust Multitask Tuning and Collaboration for Text-to-SQL.
- SHARE: An SLM-based Hierarchical Action CorREction Assistant for Text-to-SQL.
- DCG-SQL: Enhancing In-Context Learning for Text-to-SQL with Deep Contextual Schema Link Graph.
- Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL.
- STaR-SQL: Self-Taught Reasoner for Text-to-SQL.
- SQLGenie: A Practical LLM based System for Reliable and Efficient SQL Generation
- Confidence Estimation for Error Detection in Text-to-SQL Systems.
- SQLord: A Robust Enterprise Text-to-SQL Solution via Reverse Data Generation and Workflow Decomposition.
- DBCopilot: Scaling Natural Language Querying to Massive Databases.
- Boosting Text-to-SQL through Multi-grained Error Identification.
- Gen-SQL: Efficient Text-to-SQL By Bridging Natural Language Question And Database Schema With Pseudo-Schema.
- Utilising Large Language Models for Adversarial Attacks in Text-to-SQL: A Perpetrator and Victim Approach.
- You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL.
- PARSQL: Enhancing Text-to-SQL through SQL Parsing and Reasoning.
- UCS-SQL: Uniting Content and Structure for Enhanced Semantic Bridging In Text-to-SQL.
- SQLForge: Synthesizing Reliable and Diverse Data to Enhance Text-to-SQL Reasoning in LLMs.
- Optimizing Reasoning for Text-to-SQL with Execution Feedback.
- Knowledge Base Construction for Knowledge-Augmented Text-to-SQL.
- SQLong: Enhanced NL2SQL for Longer Contexts with LLMs.
- Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL.
- Automatic Metadata Extraction for Text-to-SQL.
- CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning.
- Cheaper, Better, Faster, Stronger: Robust Text-to-SQL without Chain-of-Thought or Fine-Tuning.
- Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards.
- SQL-R1: Training Natural Language to SQL Reasoning Model By Reinforcement Learning.
- Arctic-Text2SQL-R1: Simple Rewards, Strong Reasoning in Text-to-SQL.
- Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning.
- SQLForge: Synthesizing Reliable and Diverse Data to Enhance
Text-to-SQL Reasoning in LLMs.
- Think2SQL: Reinforce LLM Reasoning Capabilities for Text2SQL.
- Distill-C: Enhanced NL2SQL via Distilled Customization with LLMs.
- OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.
- SQL-Factory: A Multi-Agent Framework for High-Quality and Large-Scale SQL Generation.
- Text2SQL is Not Enough: Unifying AI and Databases with TAG.
- Automatic database description generation for Text-to-SQL.
- MCTS-SQL: An Effective Framework for Text-to-SQL with Monte Carlo Tree Search.
- SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL.
- FEATHER-SQL: A Lightweight NL2SQL Framework with Dual-Model Collaboration Paradigm for Small Language Models.
- FI-NL2PY2SQL: Financial Industry NL2SQL Innovation Model Based on Python and Large Language Model.
- FGCSQL: A Three-Stage Pipeline for Large Language Model-Driven Chinese Text-to-SQL.
- Transforming Medical Data Access: The Role and Challenges of Recent Language Models in SQL Query Automation.
- The Dawn of Natural Language to SQL: Are We Fully Ready?
- Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.
- Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation.
- Generating Succinct Descriptions of Database Schemata for Cost-Efficient Prompting of Large Language Models.
- ScienceBenchmark: A Complex Real-World Benchmark for Evaluating Natural Language to SQL Systems.
- CodeS: Towards Building Open-source Language Models for Text-to-SQL.
- FinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis.
- PURPLE: Making a Large Language Model a Better SQL Writer.
- METASQL: A Generate-then-Rank Framework for Natural Language to SQL Translation.
- Archer: A Human-Labeled Text-to-SQL Dataset with Arithmetic, Commonsense and Hypothetical Reasoning.
- Synthesizing Text-to-SQL Data from Weak and Strong LLMs.
- Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark.
- I Need Help! Evaluating LLM’s Ability to Ask for Users’ Support: A Case Study on Text-to-SQL Generation.
- PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL.
- Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning.
- Data-Centric Text-to-SQL with Large Language Models.
- Research and Practice on Database Interaction Based on Natural Language Processing
- XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL.
- Structure Guided Large Language Model for SQL Generation.
- A Plug-and-Play Natural Language Rewriter for Natural Language to SQL.
- RSL-SQL: Robust Schema Linking in Text-to-SQL Generation.
- In-Context Reinforcement Learning based Retrieval-Augmented Generation for Text-to-SQL.
- TrustSQL: Benchmarking Text-to-SQL Reliability with Penalty-Based Scoring.
- LAIA-SQL: Enhancing Natural Language to SQL Generation in Multi-Table QA via Task Decomposition and Keyword Extraction
- Research on Large Model Text-to-SQL Optimization Method for Intelligent Interaction in the Field of Construction Safety.
- SQLh-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging.
- Grounding Natural Language to SQL Translation with Data-Based Self-Explanations.
- Towards Optimizing SQL Generation via LLM Routing.
- E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL.
- DB-GPT: Empowering Database Interactions with Private Large Language Models.
- The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models.
- CHESS: Contextual Harnessing for Efficient SQL Synthesis.
- PET-SQL: A Prompt-Enhanced Two-Round Refinement of Text-to-SQL with Cross-consistency.
- CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions.
- AMBROSIA: A Benchmark for Parsing Ambiguous Questions into Database Queries.
- Text-to-SQL Calibration: No Need to Ask—Just Rescale Model Probabilities.
- Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning.
- CatSQL: Towards Real World Natural Language to SQL Applications.
- DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction.
- Data Ambiguity Strikes Back: How Documentation Improves GPT's Text-to-SQL.
- ACT-SQL: In-Context Learning for Text-to-SQL with Automatically-Generated Chain-of-Thought.
- Selective Demonstrations for Cross-domain Text-to-SQL.
- RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL.
- Graphix-T5: Mixing Pre-trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing.
- Improving Generalization in Language Model-based Text-to-SQL Semantic Parsing: Two Simple Semantic Boundary-based Techniques.
- G3R: A Graph-Guided Generate-and-Rerank Framework for Complex and Cross-domain Text-to-SQL Generation.
- Importance of Synthesizing High-quality Data for Text-to-SQL Parsing.
- Know What I don’t Know: Handling Ambiguous and Unknown Questions for Text-to-SQL.
- C3: Zero-shot Text-to-SQL with ChatGPT
- MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL.
- SQLformer: Deep Auto-Regressive Query Graph Generation for Text-to-SQL Translation.
We create a timeline of the benchmark's development and mark relevant milestones. You can get more details from this chapter: 📊 Benchmark

- 🎯Solve Open Text-to-SQL Problem
- 🎯Develop Cost-effective Text-to-SQL Methods
- 🎯Make Text-to-SQL Solutions Trustworthy
- 🎯Text-to-SQL with Ambiguous and Unspecified NL Queries
- 🎯Adaptive Training Data Synthesis
You can get more information from our subsection. We introduce representative papers on related concepts:
- We collect Text-to-SQL benchmark features and download links for you. You can get more details from this chapter: Benchmark
- The analysis code for benchmarks is available in the
src/dataset_analysisdirectory. Benchmark analysis reports can be found in thereport/directory.
-
Litgpt Repository Link
This repository offers access to over 20 high-performance large language models (LLMs) with comprehensive guides for pretraining, fine-tuning, and deploying at scale. It is designed to be beginner-friendly with from-scratch implementations and no complex abstractions.
-
LLaMA-Factory Repository Link Unified Efficient Fine-Tuning of 100+ LLMs. Integrating various models with scalable training resources, advanced algorithms, practical tricks, and comprehensive experiment monitoring tools, this setup enables efficient and faster inference through optimized APIs and UIs.
-
Fine-tuning and In-Context learning for BIRD-SQL benchmark Repository Link
A tutorial for both Fine-tuning and In-Context Learning is provided by the BIRD-SQL benchmark.
We collect NL2SQL evaluation metrics for you. You can get more details from this chapter: Evaluation
-
NLSQL360 Repository Link
NL2SQL360 is a testbed for fine-grained evaluation of NL2SQL solutions. Our testbed integrates existing NL2SQL benchmarks, a repository of NL2SQL models, and various evaluation metrics, which aims to provide an intuitive and user-friendly platform to enable both standard and customized performance evaluations.
-
Test-suite-sql-eval Repository Link
This repo contains a test suite evaluation metric for 11 text-to-SQL tasks. It is now the official metric of Spider, SParC, and CoSQL, and is also now available for Academic, ATIS, Advising, Geography, IMDB, Restaurants, Scholar, and Yelp (building on the amazing work by Catherine and Jonathan).
-
BIRD-SQL-Official Repository Link
It is now the official tool of BIRD-SQL. It is the first tool to propose VES and give an official test suite.
You can get some inspiration from the Roadmap and Decision Flow.

- Chat2DB: AI-driven database tool and SQL client, The hottest GUI client, supporting MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, ClickHouse, and more.
- DB-GPT: AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents.
- Postgres.new: In-browser Postgres sandbox with AI assistance.
- QueryGPT – Natural Language to SQL Using Generative AI. [
Please feel free to contact us if we missed any interesting work.
📧 xliu371[at]connect.hkust-gz.edu.cn
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for NL2SQL_Handbook
Similar Open Source Tools
NL2SQL_Handbook
NL2SQL Handbook provides a comprehensive overview of Natural Language to SQL (NL2SQL) advancements, including survey papers, tutorial slides, and a river diagram of NL2SQL methods. It covers the evolution of NL2SQL solutions, module-based methods, benchmark development, and future directions. The repository also offers practical guides for beginners, access to high-performance language models, and evaluation metrics for NL2SQL models.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Cyberion-Spark-X
Cyberion-Spark-X is a powerful open-source tool designed for cybersecurity professionals and data analysts. It provides advanced capabilities for analyzing and visualizing large datasets to detect security threats and anomalies. The tool integrates with popular data sources and supports various machine learning algorithms for predictive analytics and anomaly detection. Cyberion-Spark-X is user-friendly and highly customizable, making it suitable for both beginners and experienced professionals in the field of cybersecurity and data analysis.
Awesome-System2-Reasoning-LLM
The Awesome-System2-Reasoning-LLM repository is dedicated to a survey paper titled 'From System 1 to System 2: A Survey of Reasoning Large Language Models'. It explores the development of reasoning Large Language Models (LLMs), their foundational technologies, benchmarks, and future directions. The repository provides resources and updates related to the research, tracking the latest developments in the field of reasoning LLMs.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.
awesome-LLM-AIOps
The 'awesome-LLM-AIOps' repository is a curated list of academic research and industrial materials related to Large Language Models (LLM) and Artificial Intelligence for IT Operations (AIOps). It covers various topics such as incident management, log analysis, root cause analysis, incident mitigation, and incident postmortem analysis. The repository provides a comprehensive collection of papers, projects, and tools related to the application of LLM and AI in IT operations, offering valuable insights and resources for researchers and practitioners in the field.
innoshop
InnoShop is an innovative open-source e-commerce system based on Laravel 12. It supports multiple languages, multiple currencies, and is integrated with OpenAI. The system features plugin mechanisms and theme template development for enhanced user experience and system extensibility. It is globally oriented, user-friendly, and based on the latest technology with deep AI integration.
Awesome-LLM-Ensemble
Awesome-LLM-Ensemble is a collection of papers on LLM Ensemble, focusing on the comprehensive use of multiple large language models to benefit from their individual strengths. It provides a systematic review of recent developments in LLM Ensemble, including taxonomy, methods for ensemble before, during, and after inference, benchmarks, applications, and related surveys.
LLM-IR-Bias-Fairness-Survey
LLM-IR-Bias-Fairness-Survey is a collection of papers related to bias and fairness in Information Retrieval (IR) with Large Language Models (LLMs). The repository organizes papers according to a survey paper titled 'Bias and Unfairness in Information Retrieval Systems: New Challenges in the LLM Era'. The survey provides a comprehensive review of emerging issues related to bias and unfairness in the integration of LLMs into IR systems, categorizing mitigation strategies into data sampling and distribution reconstruction approaches.
LLM-for-misinformation-research
LLM-for-misinformation-research is a curated paper list of misinformation research using large language models (LLMs). The repository covers methods for detection and verification, tools for fact-checking complex claims, decision-making and explanation, claim matching, post-hoc explanation generation, and other tasks related to combating misinformation. It includes papers on fake news detection, rumor detection, fact verification, and more, showcasing the application of LLMs in various aspects of misinformation research.
lobe-cli-toolbox
Lobe CLI Toolbox is an AI CLI Toolbox designed to enhance git commit and i18n workflow efficiency. It includes tools like Lobe Commit for generating Gitmoji-based commit messages and Lobe i18n for automating the i18n translation process. The toolbox also features Lobe label for automatically copying issues labels from a template repo. It supports features such as automatic splitting of large files, incremental updates, and customization options for the OpenAI model, API proxy, and temperature.
ExplainableAI.jl
ExplainableAI.jl is a Julia package that implements interpretability methods for black-box classifiers, focusing on local explanations and attribution maps in input space. The package requires models to be differentiable with Zygote.jl. It is similar to Captum and Zennit for PyTorch and iNNvestigate for Keras models. Users can analyze and visualize explanations for model predictions, with support for different XAI methods and customization. The package aims to provide transparency and insights into model decision-making processes, making it a valuable tool for understanding and validating machine learning models.

pro-chat
ProChat is a components library focused on quickly building large language model chat interfaces. It empowers developers to create rich, dynamic, and intuitive chat interfaces with features like automatic chat caching, streamlined conversations, message editing tools, auto-rendered Markdown, and programmatic controls. The tool also includes design evolution plans such as customized dialogue rendering, enhanced request parameters, personalized error handling, expanded documentation, and atomic component design.
Awesome-LM-SSP
Awesome-LM-SSP is a repository that focuses on resources related to the trustworthiness of large models (LMs) across multiple dimensions such as safety, security, and privacy, with a special emphasis on multi-modal LMs like vision-language models and diffusion models. The repository is a work in progress, manually collected, and includes badges for different types of models and comments. It provides resources related to various venues, encourages community contributions, and offers guidelines for updating and adding information about papers. The repository also celebrates milestones and includes collections of books, competitions, leaderboards, toolkits, surveys, and papers categorized under safety, security, and privacy.
chatgpt-auto-refresh
ChatGPT Auto Refresh is a userscript that keeps ChatGPT sessions fresh by eliminating network errors and Cloudflare checks. It removes the 10-minute time limit from conversations when Chat History is disabled, ensuring a seamless experience. The tool is safe, lightweight, and a time-saver, allowing users to keep their sessions alive without constant copy/paste/refresh actions. It works even in background tabs, providing convenience and efficiency for users interacting with ChatGPT. The tool relies on the chatgpt.js library and is compatible with various browsers using Tampermonkey, making it accessible to a wide range of users.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.