
aideml
AIDE: the Machine Learning CodeGen Agent
Stars: 270
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
README:


AIDE is an LLM agent that generates solutions for machine learning tasks just from natural language descriptions of the task. In a benchmark composed of over 60 Kaggle data science competitions, AIDE demonstrated impressive performance, surpassing 50% of Kaggle participants on average (see our technical report for details). More specifically, AIDE has the following features:
- Instruct with Natural Language: Describe your problem or additional requirements and expert insights, all in natural language.
- Deliver Solution in Source Code: AIDE will generate Python scripts for the tested machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code!
- Iterative Optimization: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself.
- Visualization: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't.
Make sure you have Python>=3.10 installed and run:
pip install -U aidemlAlso install unzip to allow the agent to autonomously extract your data.
Set up your OpenAI (or Anthropic) API key:
export OPENAI_API_KEY=<your API key>
# or
export ANTHROPIC_API_KEY=<your API key>To run AIDE:
aide data_dir="<path to your data directory>" goal="<describe the agent's goal for your task>" eval="<(optional) describe the evaluation metric the agent should use>"For example, to run AIDE on the example house price prediction task:
aide data_dir="example_tasks/house_prices" goal="Predict the sales price for each house" eval="Use the RMSE metric between the logarithm of the predicted and observed values."Options:
-
data_dir(required): a directory containing all the data relevant for your task (.csvfiles, images, etc.). -
goal: describe what you want the models to predict in your task, for example, "Build a timeseries forcasting model for bitcoin close price" or "Predict sales price for houses". -
eval: the evaluation metric used to evaluate the ML models for the task (e.g., accuracy, F1, Root-Mean-Squared-Error, etc.)
Alternatively, you can provide the entire task description as a desc_str string, or write it in a plaintext file and pass its path as desc_file (example file).
aide data_dir="my_data_dir" desc_file="my_task_description.txt"The result of the run will be stored in the logs directory.
-
logs/<experiment-id>/best_solution.py: Python code of best solution according to the validation metric -
logs/<experiment-id>/journal.json: a JSON file containing the metadata of the experiment runs, including all the code generated in intermediate steps, plan, evaluation results, etc. -
logs/<experiment-id>/tree_plot.html: you can open it in your browser. It contains visualization of solution tree, which details the experimentation process of finding and optimizing ML code. You can explore and interact with the tree visualization to view what plan and code AIDE comes up with in each step.
The workspaces directory will contain all the files and data that the agent generated.
To further customize the behaviour of AIDE, some useful options might be:
-
agent.code.model=...to configure which model the agent should use for coding (default isgpt-4-turbo) -
agent.steps=...to configure how many improvement iterations the agent should run (default is 20) -
agent.search.num_drafts=...to configure the number of initial drafts the agent should generate (default is 5)
You can check the config.yaml file for more options.
Using AIDE within your Python script/project is easy. Follow the setup steps above, and then create an AIDE experiment like below and start running:
import aide
exp = aide.Experiment(
data_dir="example_tasks/bitcoin_price", # replace this with your own directory
goal="Build a timeseries forcasting model for bitcoin close price.", # replace with your own goal description
eval="RMSLE" # replace with your own evaluation metric
)
best_solution = exp.run(steps=10)
print(f"Best solution has validation metric: {best_solution.valid_metric}")
print(f"Best solution code: {best_solution.code}")To install AIDE for development, clone this repository and install it locally.
git clone https://github.com/WecoAI/aideml.git
cd aideml
pip install -e .Contribution guide will be available soon.
AIDE's problem-solving approach is inspired by how human data scientists tackle challenges. It starts by generating a set of initial solution drafts and then iteratively refines and improves them based on performance feedback. This process is driven by a technique we call Solution Space Tree Search.
At its core, Solution Space Tree Search consists of three main components:
- Solution Generator: This component proposes new solutions by either creating novel drafts or making changes to existing solutions, such as fixing bugs or introducing improvements.
- Evaluator: The evaluator assesses the quality of each proposed solution by running it and comparing its performance against the objective. This is implemented by instructing the LLM to include statements that print the evaluation metric and by having another LLM parse the printed logs to extract the evaluation metric.
- Base Solution Selector: The solution selector picks the most promising solution from the explored options to serve as the starting point for the next iteration of refinement.
By repeatedly applying these steps, AIDE navigates the vast space of possible solutions, progressively refining its approach until it converges on the optimal solution for the given data science problem.
| Domain | Task | Top% | Solution Link | Competition Link |
|---|---|---|---|---|
| Urban Planning | Forecast city bikeshare system usage | 5% | link | link |
| Physics | Predicting Critical Heat Flux | 56% | link | link |
| Genomics | Classify bacteria species from genomic data | 0% | link | link |
| Agriculture | Predict blueberry yield | 58% | link | link |
| Healthcare | Predict disease prognosis | 0% | link | link |
| Economics | Predict monthly microbusiness density in a given area | 35% | link | link |
| Cryptography | Decrypt shakespearean text | 91% | link | link |
| Data Science Education | Predict passenger survival on Titanic | 78% | link | link |
| Software Engineering | Predict defects in c programs given various attributes about the code | 0% | link | link |
| Real Estate | Predict the final price of homes | 5% | link | link |
| Real Estate | Predict house sale price | 36% | link | link |
| Entertainment Analytics | Predict movie worldwide box office revenue | 62% | link | link |
| Entertainment Analytics | Predict scoring probability in next 10 seconds of a rocket league match | 21% | link | link |
| Environmental Science | Predict air pollution levels | 12% | link | link |
| Environmental Science | Classify forest categories using cartographic variables | 55% | link | link |
| Computer Vision | Predict the probability of machine failure | 32% | link | link |
| Computer Vision | Identify handwritten digits | 14% | link | link |
| Manufacturing | Predict missing values in dataset | 70% | link | link |
| Manufacturing | Predict product failures | 48% | link | link |
| Manufacturing | Cluster control data into different control states | 96% | link | link |
| Natural Language Processing | Classify toxic online comments | 78% | link | link |
| Natural Language Processing | Predict passenger transport to an alternate dimension | 59% | link | link |
| Natural Language Processing | Classify sentence sentiment | 42% | link | link |
| Natural Language Processing | Predict whether a tweet is about a real disaster | 48% | link | link |
| Business Analytics | Predict total sales for each product and store in the next month | 87% | link | link |
| Business Analytics | Predict book sales for 2021 | 66% | link | link |
| Business Analytics | Predict insurance claim amount | 80% | link | link |
| Business Analytics | Minimize penalty cost in scheduling families to santa's workshop | 100% | link | link |
| Business Analytics | Predict yearly sales for learning modules | 26% | link | link |
| Business Analytics | Binary classification of manufacturing machine state | 60% | link | link |
| Business Analytics | Forecast retail store sales | 36% | link | link |
| Business Analytics | Predict reservation cancellation | 54% | link | link |
| Finance | Predict the probability of an insurance claim | 13% | link | link |
| Finance | Predict loan loss | 0% | link | link |
| Finance | Predict a continuous target | 42% | link | link |
| Finance | Predict customer churn | 24% | link | link |
| Finance | Predict median house value | 58% | link | link |
| Finance | Predict closing price movements for nasdaq listed stocks | 99% | link | link |
| Finance | Predict taxi fare | 100% | link | link |
| Finance | Predict insurance claim probability | 62% | link | link |
| Biotech | Predict cat in dat | 66% | link | link |
| Biotech | Predict the biological response of molecules | 62% | link | link |
| Biotech | Predict medical conditions | 92% | link | link |
| Biotech | Predict wine quality | 61% | link | link |
| Biotech | Predict binary target without overfitting | 98% | link | link |
| Biotech | Predict concrete strength | 86% | link | link |
| Biotech | Predict crab age | 46% | link | link |
| Biotech | Predict enzyme characteristics | 10% | link | link |
| Biotech | Classify activity state from sensor data | 51% | link | link |
| Biotech | Predict horse health outcomes | 86% | link | link |
| Biotech | Predict the mohs hardness of a mineral | 64% | link | link |
| Biotech | Predict cirrhosis patient outcomes | 51% | link | link |
| Biotech | Predict obesity risk | 62% | link | link |
| Biotech | Classify presence of feature in data | 66% | link | link |
| Biotech | Predict patient's smoking status | 40% | link | link |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aideml
Similar Open Source Tools
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.
ai-dial-core
AI DIAL Core is an HTTP Proxy that provides a unified API to different chat completion and embedding models, assistants, and applications. It is written in Java 17 and built on Eclipse Vert.x. The core functionality includes handling static and dynamic settings, deployment on Kubernetes using Helm charts, and storing user data in Blob Storage and Redis. It supports various identity providers, storage providers like AWS S3, Google Cloud Storage, and Azure Blob Store, and features like AI DIAL Addons, Interceptors, Assistants, Applications, and Models with customizable parameters and configurations.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.
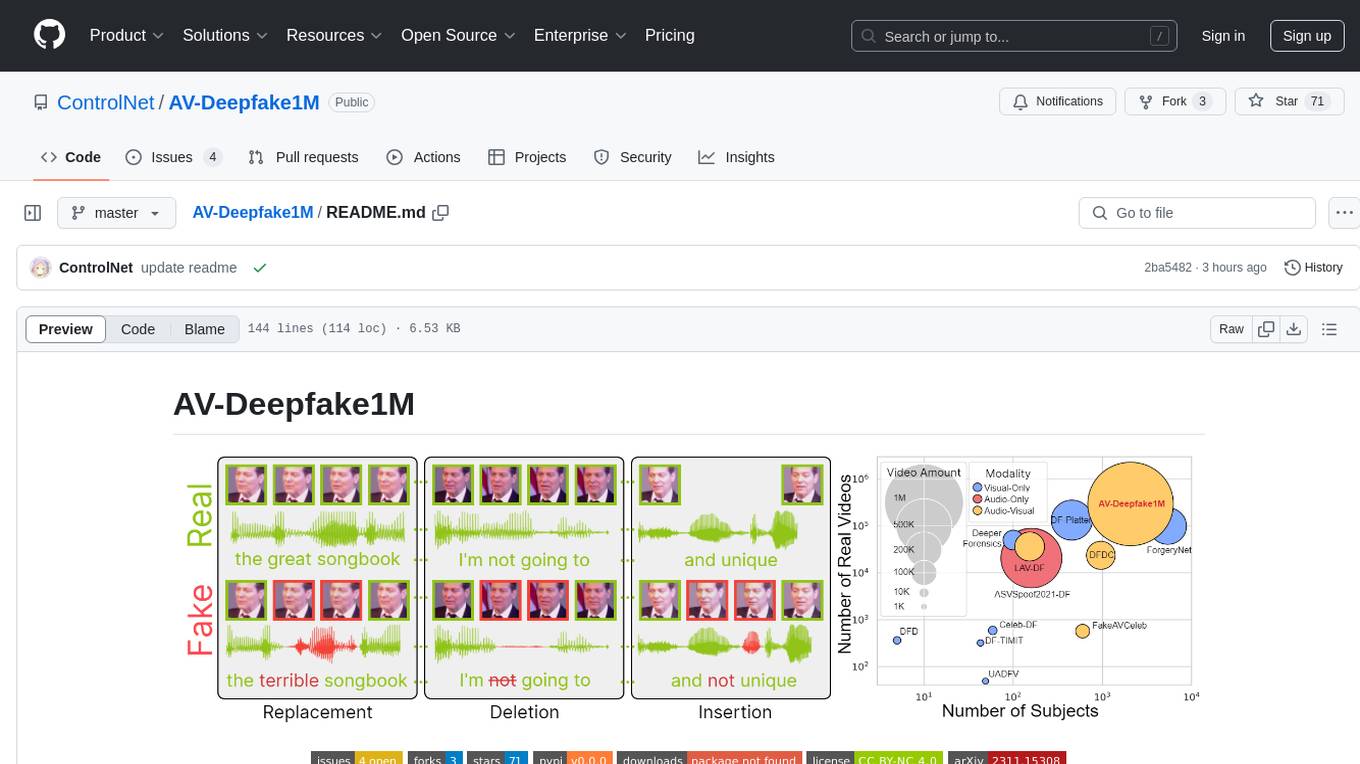
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.
recommenders
Recommenders is a project under the Linux Foundation of AI and Data that assists researchers, developers, and enthusiasts in prototyping, experimenting with, and bringing to production a range of classic and state-of-the-art recommendation systems. The repository contains examples and best practices for building recommendation systems, provided as Jupyter notebooks. It covers tasks such as preparing data, building models using various recommendation algorithms, evaluating algorithms, tuning hyperparameters, and operationalizing models in a production environment on Azure. The project provides utilities to support common tasks like loading datasets, evaluating model outputs, and splitting training/test data. It includes implementations of state-of-the-art algorithms for self-study and customization in applications.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.
For similar tasks

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
auto-dev
AutoDev is an AI-powered coding wizard that supports multiple languages, including Java, Kotlin, JavaScript/TypeScript, Rust, Python, Golang, C/C++/OC, and more. It offers a range of features, including auto development mode, copilot mode, chat with AI, customization options, SDLC support, custom AI agent integration, and language features such as language support, extensions, and a DevIns language for AI agent development. AutoDev is designed to assist developers with tasks such as auto code generation, bug detection, code explanation, exception tracing, commit message generation, code review content generation, smart refactoring, Dockerfile generation, CI/CD config file generation, and custom shell/command generation. It also provides a built-in LLM fine-tune model and supports UnitEval for LLM result evaluation and UnitGen for code-LLM fine-tune data generation.

LLM4SE
The collection is actively updated with the help of an internal literature search engine.
Awesome-Code-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, in lowercase letters: 'description' (detailed description of the repo, must be less than 400 words,Ensure that no line breaks and quotation marks.),'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,user may use those keyword to find the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in lowercase letters), 'answer' (in english languages)

crewAI
crewAI is a cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It provides a flexible and structured approach to AI collaboration, enabling users to define agents with specific roles, goals, and tools, and assign them tasks within a customizable process. crewAI supports integration with various LLMs, including OpenAI, and offers features such as autonomous task delegation, flexible task management, and output parsing. It is open-source and welcomes contributions, with a focus on improving the library based on usage data collected through anonymous telemetry.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.