Best AI tools for< Data Preprocessing >
20 - AI tool Sites

DVC
DVC is an open-source platform for managing machine learning data and experiments. It provides a unified interface for working with data from various sources, including local files, cloud storage, and databases. DVC also includes tools for versioning data and experiments, tracking metrics, and automating compute resources. DVC is designed to make it easy for data scientists and machine learning engineers to collaborate on projects and share their work with others.
ML Clever
ML Clever is a no-code machine learning platform that empowers users to build powerful ML models with one click, explore what-if scenarios to guide decisions, and create interactive dashboards to explain results. It combines automated machine learning, interactive dashboards, and flexible prediction tools in one platform, allowing users to transform data into business insights without the need for data scientists or coding skills.
Plat.AI
Plat.AI is an automated predictive analytics software that offers model building solutions for various industries such as finance, insurance, and marketing. It provides a real-time decision-making engine that allows users to build and maintain AI models without any coding experience. The platform offers features like automated model building, data preprocessing tools, codeless modeling, and personalized approach to data analysis. Plat.AI aims to make predictive analytics easy and accessible for users of all experience levels, ensuring transparency, security, and compliance in decision-making processes.

HappyML
HappyML is an AI tool designed to assist users in machine learning tasks. It provides a user-friendly interface for running machine learning algorithms without the need for complex coding. With HappyML, users can easily build, train, and deploy machine learning models for various applications. The tool offers a range of features such as data preprocessing, model evaluation, hyperparameter tuning, and model deployment. HappyML simplifies the machine learning process, making it accessible to users with varying levels of expertise.
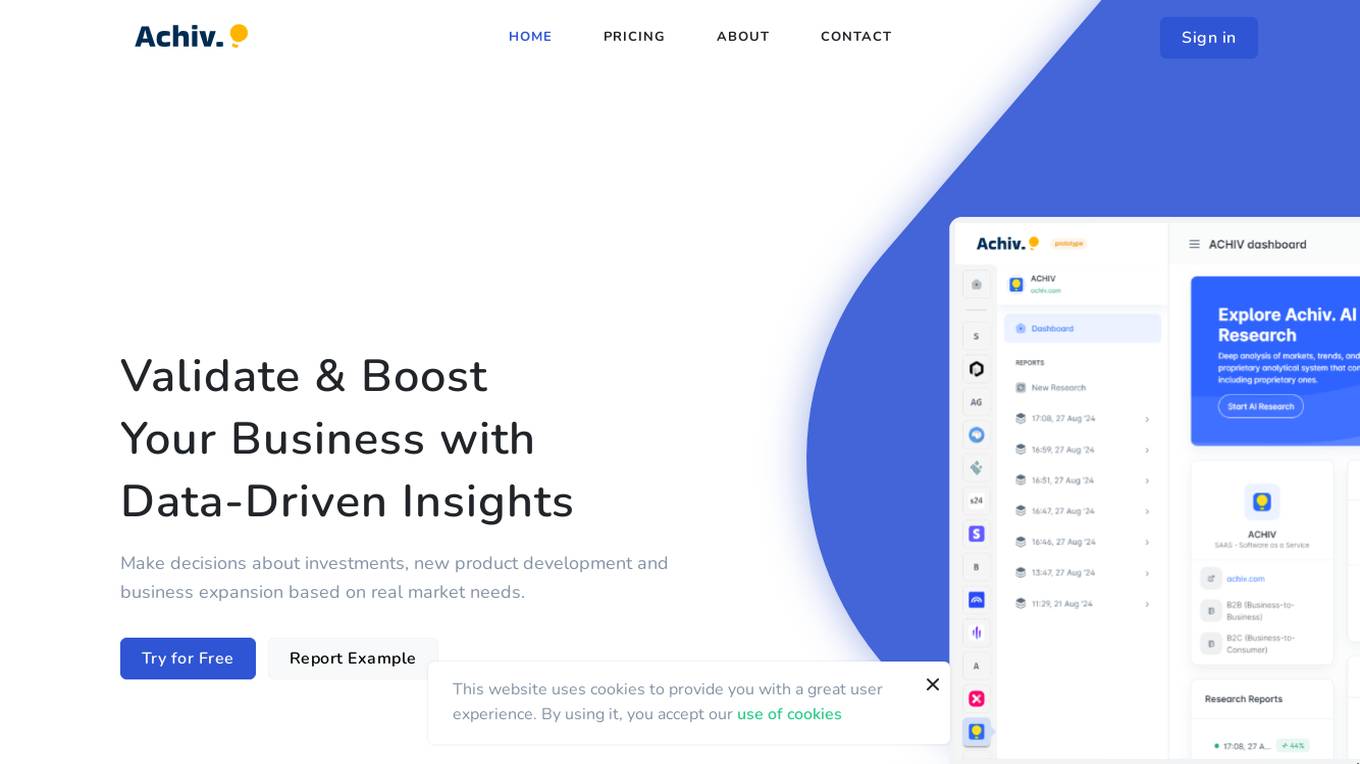
ACHIV
ACHIV is an AI tool for ideas validation and market research. It helps businesses make informed decisions based on real market needs by providing data-driven insights. The tool streamlines the market validation process, allowing quick adaptation and refinement of product development strategies. ACHIV offers a revolutionary approach to data collection and preprocessing, along with proprietary AI models for smart analysis and predictive forecasting. It is designed to assist entrepreneurs in understanding market gaps, exploring competitors, and enhancing investment decisions with real-time data.
Eigen Technologies
Eigen Technologies is an AI-powered data extraction platform designed for business users to automate the extraction of data from various documents. The platform offers solutions for intelligent document processing and automation, enabling users to streamline business processes, make informed decisions, and achieve significant efficiency gains. Eigen's platform is purpose-built to deliver real ROI by reducing manual processes, improving data accuracy, and accelerating decision-making across industries such as corporates, banks, financial services, insurance, law, and manufacturing. With features like generative insights, table extraction, pre-processing hub, and model governance, Eigen empowers users to automate data extraction workflows efficiently. The platform is known for its unmatched accuracy, speed, and capability, providing customers with a flexible and scalable solution that integrates seamlessly with existing systems.
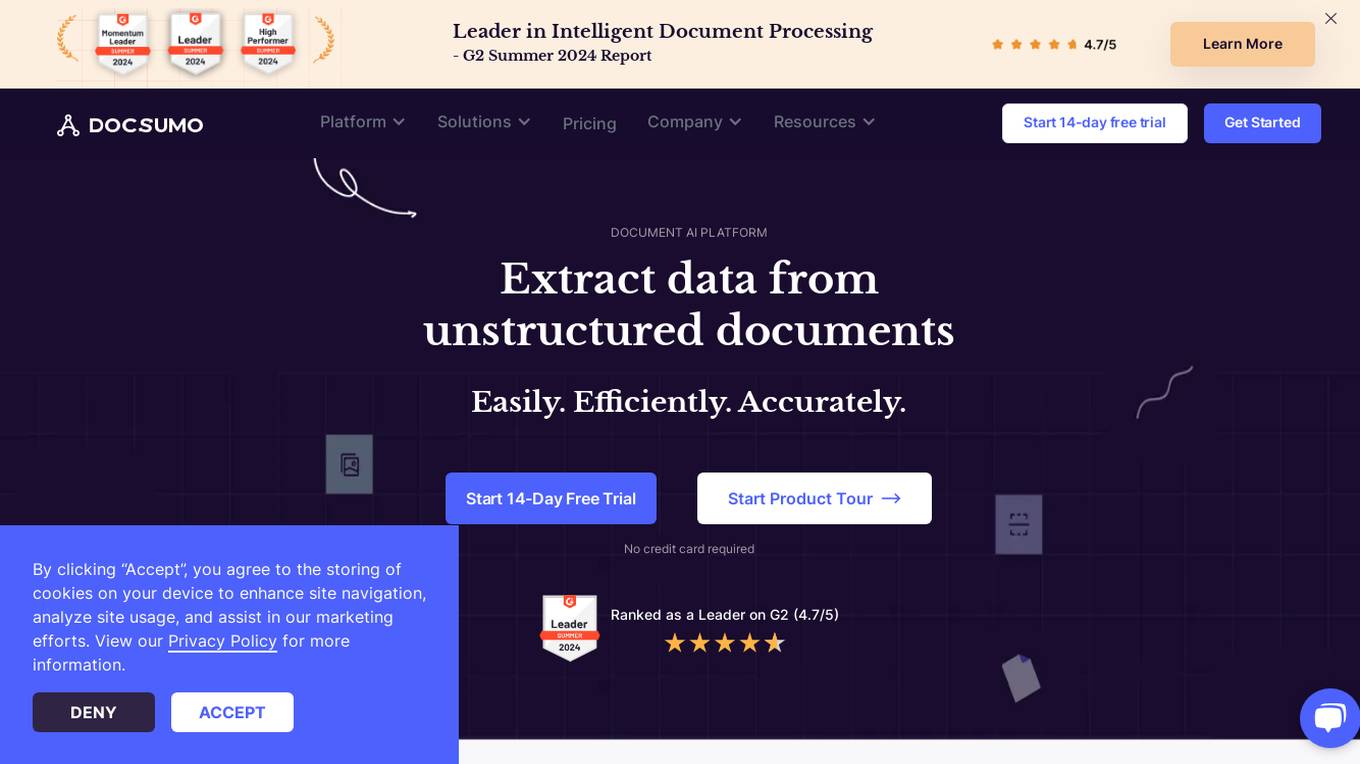
Docsumo
Docsumo is an advanced Document AI platform designed for scalability and efficiency. It offers a wide range of capabilities such as pre-processing documents, extracting data, reviewing and analyzing documents. The platform provides features like document classification, touchless processing, ready-to-use AI models, auto-split functionality, and smart table extraction. Docsumo is a leader in intelligent document processing and is trusted by various industries for its accurate data extraction capabilities. The platform enables enterprises to digitize their document processing workflows, reduce manual efforts, and maximize data accuracy through its AI-powered solutions.
Towards Data Science
Towards Data Science is a Medium publication dedicated to sharing concepts, ideas, and codes in the field of data science. It provides a platform for data scientists, researchers, and practitioners to connect, learn, and contribute to the advancement of the field.
What's The Big Data
What's The Big Data is an AI tool directory that helps users unleash their potential by providing a comprehensive source for AI tools, data, and ChatGPT. The platform is updated daily and caters to every need, offering a wide range of AI assistants across various categories. Users can easily find their perfect AI assistant with just a click, making it a valuable resource for those seeking AI solutions.
Data Science Dojo
Data Science Dojo is a globally recognized e-learning platform that offers programs in data science, data analytics, machine learning, and more. They provide comprehensive and hands-on training in various formats such as in-person, virtual instructor-led, and self-paced training. The focus is on helping students develop a think-business-first mindset to apply their data science skills effectively in real-world scenarios. With over 2500 enterprises trained, Data Science Dojo aims to make data science accessible to everyone.
Domino Data Lab
Domino Data Lab is an enterprise AI platform that enables data scientists and IT leaders to build, deploy, and manage AI models at scale. It provides a unified platform for accessing data, tools, compute, models, and projects across any environment. Domino also fosters collaboration, establishes best practices, and tracks models in production to accelerate and scale AI while ensuring governance and reducing costs.

Open Data Science
Open Data Science (ODS) is a community website offering a platform for data science enthusiasts to engage in tracks, competitions, hacks, tasks, events, and projects. The website serves as a hub for job opportunities and provides a space for privacy policy, service agreements, and public offers. ODS.AI, established in 2015, focuses on various data science topics such as machine learning, computer vision, natural language processing, and more. The platform hosts online and offline events, conferences, and educational courses to foster learning and networking within the data science community.
Domino Data Lab
Domino Data Lab is an enterprise AI platform that enables users to build, deploy, and manage AI models across any environment. It fosters collaboration, establishes best practices, and ensures governance while reducing costs. The platform provides access to a broad ecosystem of open source and commercial tools, and infrastructure, allowing users to accelerate and scale AI impact. Domino serves as a central hub for AI operations and knowledge, offering integrated workflows, automation, and hybrid multicloud capabilities. It helps users optimize compute utilization, enforce compliance, and centralize knowledge across teams.
Association of Data Scientists
The Association of Data Scientists (ADaSci) is a global professional body of AI professionals that accredits and elevates professionals with recognized certifications and transformative corporate training. They offer memberships for individuals and corporations interested in the AI field, as well as accreditations like Chartered Data Scientist (CDS) and Certified Generative AI Engineer. The organization provides continuous learning opportunities through courses and corporate training programs on topics such as generative AI and knowledge graph solutions. ADaSci aims to shape the future of AI talent by advancing expertise and achieving global recognition as certified professionals.

Research Center Trustworthy Data Science and Security
The Research Center Trustworthy Data Science and Security is a hub for interdisciplinary research focusing on building trust in artificial intelligence, machine learning, and cyber security. The center aims to develop trustworthy intelligent systems through research in trustworthy data analytics, explainable machine learning, and privacy-aware algorithms. By addressing the intersection of technological progress and social acceptance, the center seeks to enable private citizens to understand and trust technology in safety-critical applications.
Aya Data
Aya Data is an AI tool that offers services such as data annotation, computer vision, natural language annotation, 3D annotation, AI data acquisition, and AI consulting. They provide cutting-edge tools to transform raw data into training datasets for AI models, deliver bespoke AI solutions for various industries, and offer AI-powered products like AyaGrow for crop management and AyaSpeech for speech-to-speech translation. Aya Data focuses on exceptional accuracy, rapid development cycles, and high performance in real-world scenarios.

ThirdEye Data
ThirdEye Data is a data and AI services & solutions provider that enables enterprises to improve operational efficiencies, increase production accuracies, and make informed business decisions by leveraging the latest Data & AI technologies. They offer services in data engineering, data science, generative AI, computer vision, NLP, and more. ThirdEye Data develops bespoke AI applications using the latest data science technologies to address real-world industry challenges and assists enterprises in leveraging generative AI models to develop custom applications. They also provide AI consulting services to explore potential opportunities for AI implementation. The company has a strong focus on customer success and has received positive reviews and awards for their expertise in AI, ML, and big data solutions.
Crayon Data
Crayon Data offers B2B AI solutions for enterprises through their platform maya.ai. The platform provides flexible building blocks to help businesses launch and scale quickly. With a cloud-agnostic full-stack solution, maya.ai enables real-world applications for data, customer management, and more. Crayon Data focuses on AI-led solutions to enhance customer experiences, turn raw data into valuable insights, and drive engagement through AI marketplaces. The platform also offers tools for travel planning, payment optimization, offer management, data analytics, influencer management, and more. Industries served include consumer banking, digital payments, travel, and consumer products.
Kenniscentrum Data & Maatschappij
Kenniscentrum Data & Maatschappij is a website dedicated to legal, ethical, and societal aspects of artificial intelligence and data applications. It provides insights, guidelines, and practical tools for individuals and organizations interested in AI governance and innovation. The platform offers resources such as policy documents, training programs, and collaboration cards to facilitate human-AI interaction and promote responsible AI use.
Dot Group Data Advisory
Dot Group is an AI-powered data advisory and solutions platform that specializes in effective data management. They offer services to help businesses maximize the potential of their data estate, turning complex challenges into profitable opportunities using AI technologies. With a focus on data strategy, data engineering, and data transport, Dot Group provides innovative solutions to drive better profitability for their clients.
2 - Open Source AI Tools

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
20 - OpenAI Gpts
Your Business Data Optimizer Pro
A chatbot expert in business data analysis and optimization.
Data Dynamo
A friendly data science coach offering practical, useful, and accurate advice.


DataKitchen DataOps and Data Observability GPT
A specialist in DataOps and Data Observability, aiding in data management and monitoring.

Alas Data Analytics Student Mentor
Salam mən Alas Academy-nin Data Analitika üzrə Süni İntellekt mentoruyam. Mənə istənilən sualı verə bilərsiniz :)

CannaIndustry Data Expert
Data trend analysis expert in cannabis, also skilled in image and data analysis, document generation, and web search.

Data Extractor Pro
Expert in data extraction and context-driven analysis. Can read most filetypes including PDFS, XLSX, Word, TXT, CSV, EML, Etc.