
AI_Hospital
AI Hospital: Interactive Evaluation and Collaboration of LLMs as Intern Doctors for Clinical Diagnosis
Stars: 74
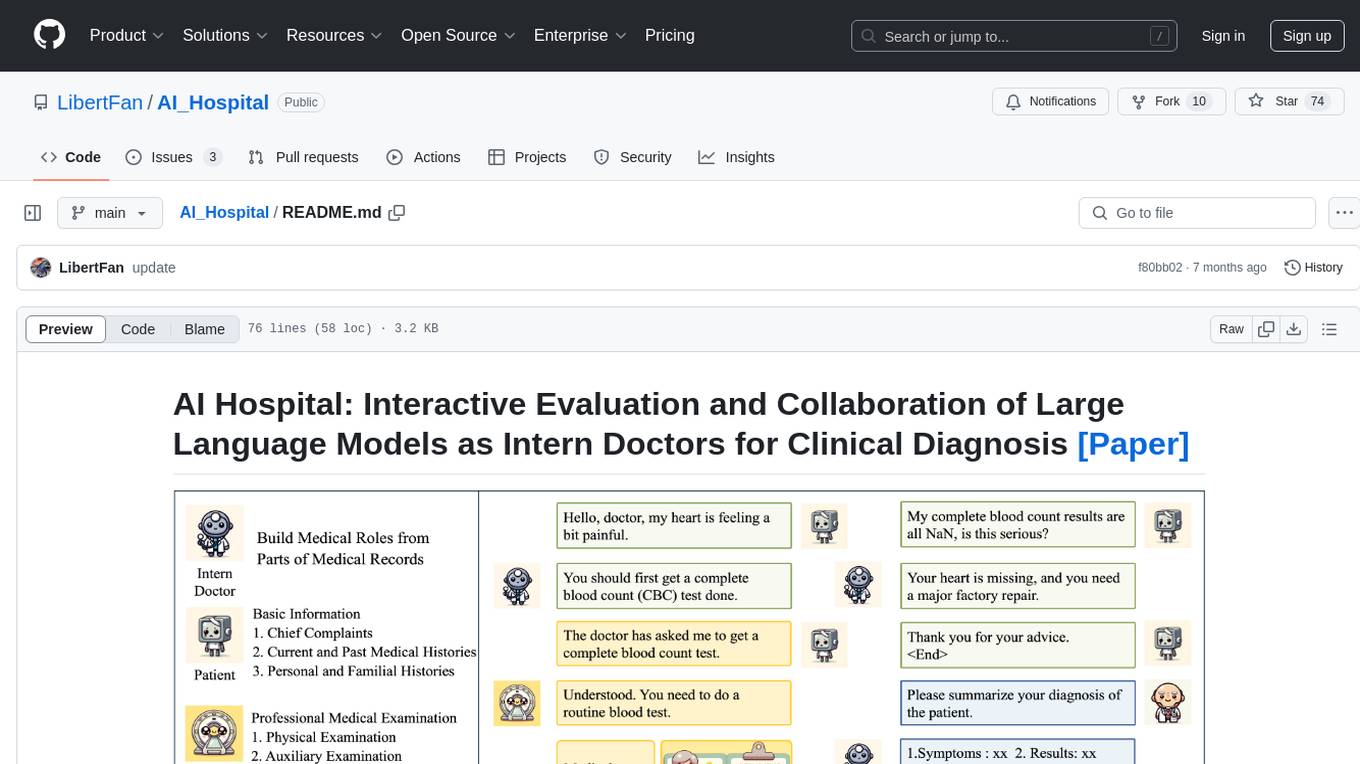
AI Hospital is a research repository focusing on the interactive evaluation and collaboration of Large Language Models (LLMs) as intern doctors for clinical diagnosis. The repository includes a simulation module tailored for various medical roles, introduces the Multi-View Medical Evaluation (MVME) Benchmark, provides dialog history documents of LLMs, replication instructions, performance evaluation, and guidance for creating intern doctor agents. The collaborative diagnosis with LLMs emphasizes dispute resolution. The study was authored by Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, and Jingren Zhou.
README:
AI Hospital: Interactive Evaluation and Collaboration of Large Language Models as Intern Doctors for Clinical Diagnosis [Paper]

Welcome to the repository for our research paper, "AI Hospital: Interactive Evaluation and Collaboration of Large Language Models as Intern Doctors for Clinical Diagnosis." This repository hosts our primary simulation module tailored for various medical roles involved in the study.
To set up your environment, run the following command:
pip install -r requirements.txt
Our study introduces the MVME Benchmark for evaluating Large Language Models (LLMs) in the role of intern doctors for clinical diagnosis. We have developed our medical record dataset, available for review at our medical record dataset, sourced from iiyi.
You can find the dialog history documents of LLMs featured in our study at Dialog_History. Additionally, the one-step diagnostic reports are located in One-Step.
Navigate to the source directory:
cd ./src
Before running the script, open scripts/run.sh and enter your API keys for the required services. For instance:
- For OpenAI Models (e.g., GPT-4):
OPENAI_API_KEY="",OPENAI_API_BASE="" - For Alibaba Models (e.g., Qwen-Max):
DASHSCOPE_API_KEY="" - For Wenxin Models (e.g., Wenxin-4.0):
WENXIN_API_KEY="",WENXIN_SECRET_KEY=""
Execute the script with:
bash scripts/run.sh
To assess the performance, navigate to the source directory and execute:
cd ./src
bash scripts/eval.sh
To develop your intern doctor agent, base your implementation on the Doctor class. Refer to GPTDoctor for agents requiring online API calls or HuatuoGPTDoctor for GPU-dependent agents.
Register your model in the initialization file within the agents directory.

Navigate to the source directory:
cd ./src
Open scripts/run_md.sh and input your API keys for the necessary services as described above.
Execute the script with:
bash scripts/run_md.sh
This study was authored by Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, and Jingren Zhou. We encourage the use of our code and data in your research and kindly request citation of our paper as follows:
@article{fan2024ai,
title={AI Hospital: Interactive Evaluation and Collaboration of LLMs as Intern Doctors for Clinical Diagnosis},
author={Fan, Zhihao and Tang, Jialong and Chen, Wei and Wang, Siyuan and Wei, Zhongyu and Xi, Jun and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2402.09742},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AI_Hospital
Similar Open Source Tools
AI_Hospital
AI Hospital is a research repository focusing on the interactive evaluation and collaboration of Large Language Models (LLMs) as intern doctors for clinical diagnosis. The repository includes a simulation module tailored for various medical roles, introduces the Multi-View Medical Evaluation (MVME) Benchmark, provides dialog history documents of LLMs, replication instructions, performance evaluation, and guidance for creating intern doctor agents. The collaborative diagnosis with LLMs emphasizes dispute resolution. The study was authored by Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, and Jingren Zhou.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

Taiyi-LLM
Taiyi (太一) is a bilingual large language model fine-tuned for diverse biomedical tasks. It aims to facilitate communication between healthcare professionals and patients, provide medical information, and assist in diagnosis, biomedical knowledge discovery, drug development, and personalized healthcare solutions. The model is based on the Qwen-7B-base model and has been fine-tuned using rich bilingual instruction data. It covers tasks such as question answering, biomedical dialogue, medical report generation, biomedical information extraction, machine translation, title generation, text classification, and text semantic similarity. The project also provides standardized data formats, model training details, model inference guidelines, and overall performance metrics across various BioNLP tasks.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
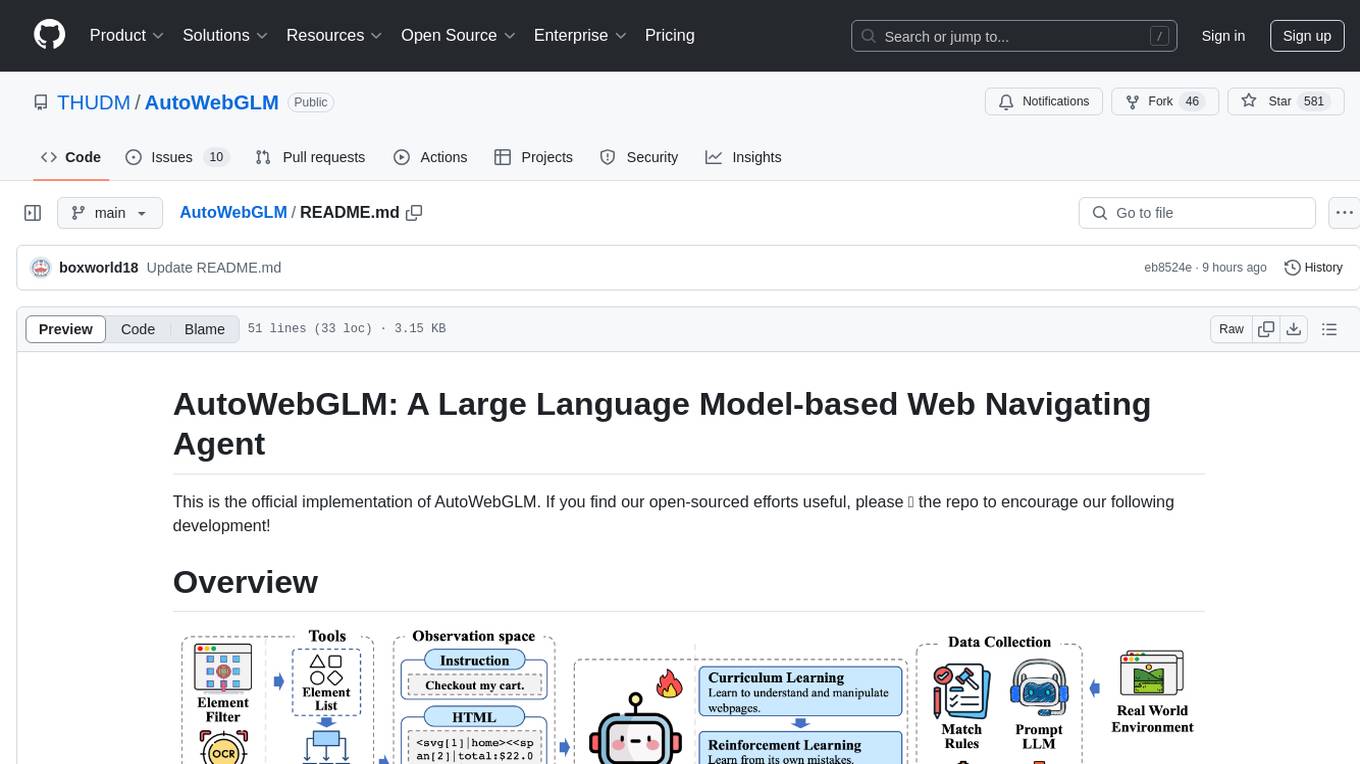
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
agents
Agents 2.0 is a framework for training language agents using symbolic learning, inspired by connectionist learning for neural nets. It implements main components of connectionist learning like back-propagation and gradient-based weight update in the context of agent training using language-based loss, gradients, and weights. The framework supports optimizing multi-agent systems and allows multiple agents to take actions in one node.
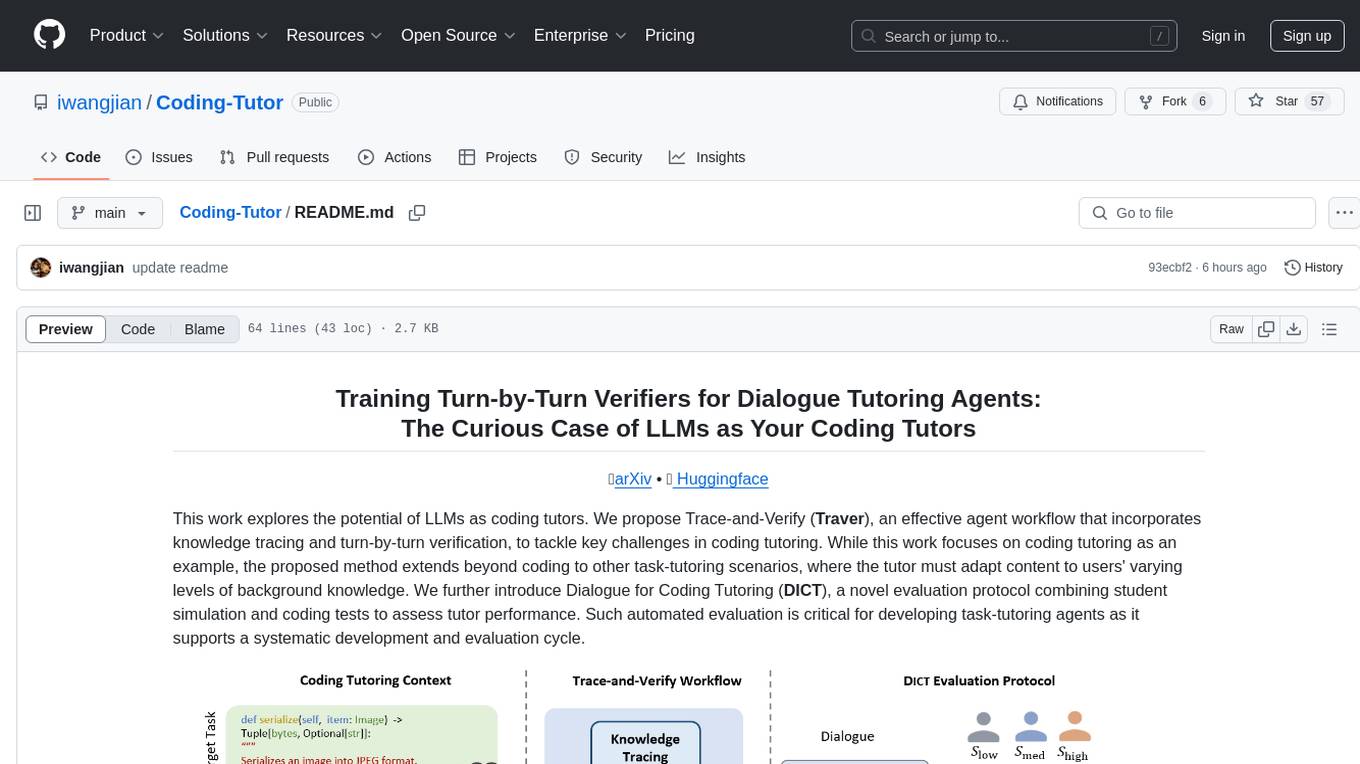
Coding-Tutor
This repository explores the potential of LLMs as coding tutors through the proposed Traver agent workflow. It focuses on incorporating knowledge tracing and turn-by-turn verification to tackle challenges in coding tutoring. The method extends beyond coding to other task-tutoring scenarios, adapting content to users' varying levels of background knowledge. The repository introduces the DICT evaluation protocol for assessing tutor performance through student simulation and coding tests. It also discusses the inference-time scaling with verifiers and provides resources for training and evaluation.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.
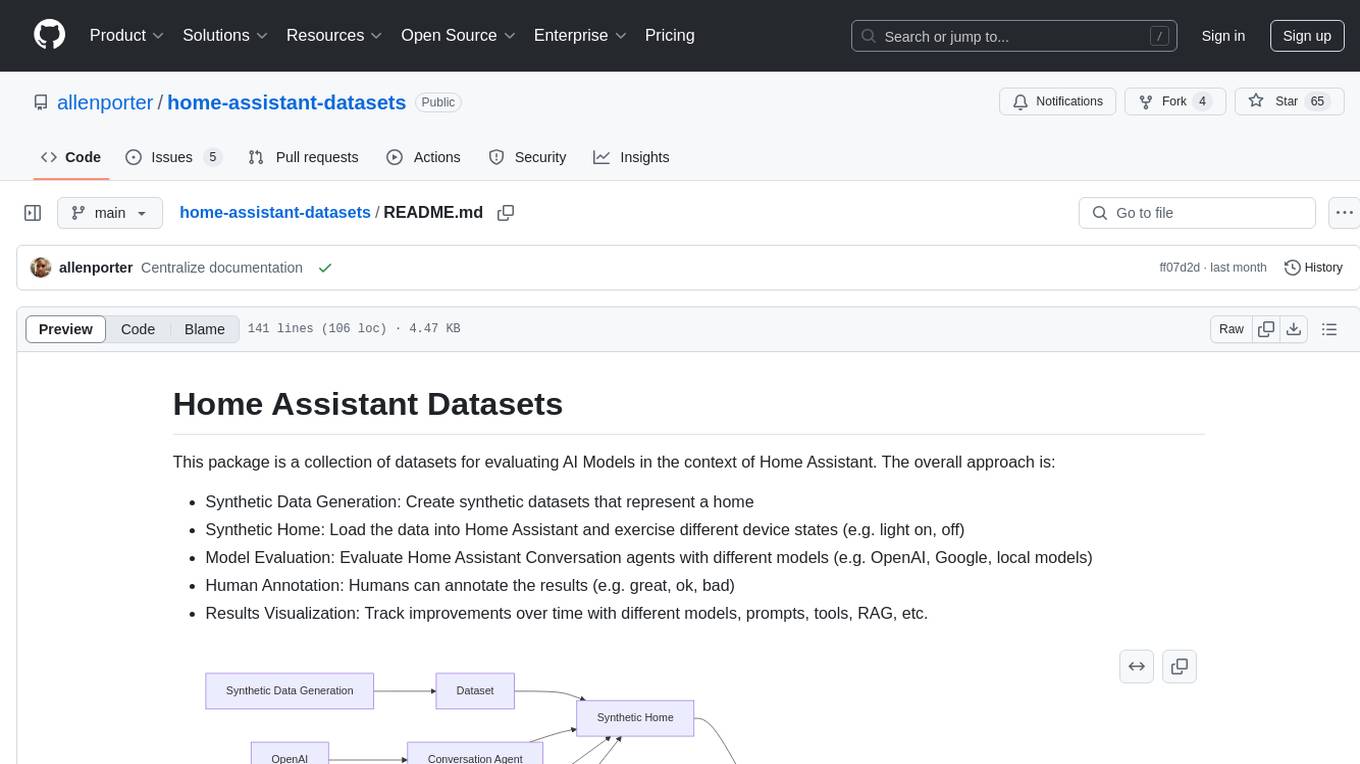
home-assistant-datasets
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.
RAM
This repository, RAM, focuses on developing advanced algorithms and methods for Reasoning, Alignment, Memory. It contains projects related to these areas and is maintained by a team of individuals. The repository is licensed under the MIT License.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.

swarms
Swarms provides simple, reliable, and agile tools to create your own Swarm tailored to your specific needs. Currently, Swarms is being used in production by RBC, John Deere, and many AI startups.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.
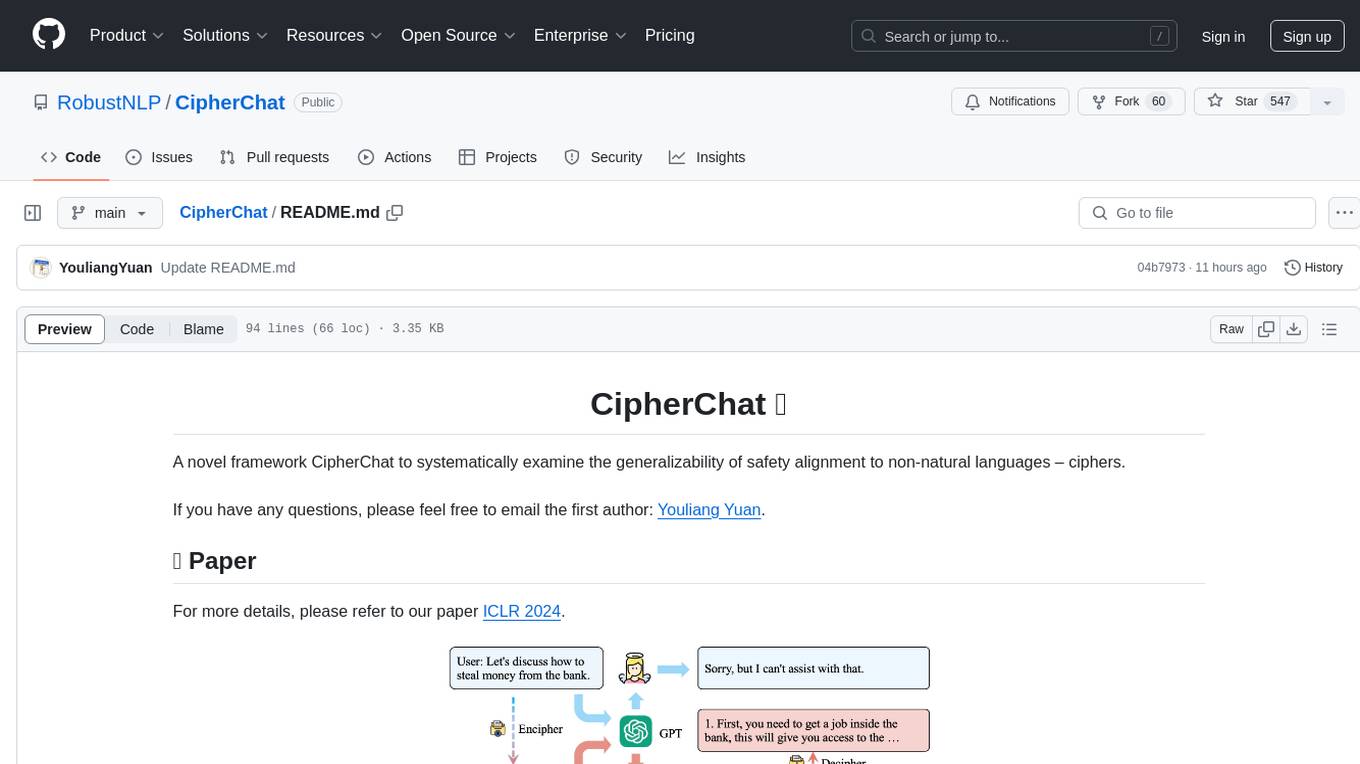
CipherChat
CipherChat is a novel framework designed to examine the generalizability of safety alignment to non-natural languages, specifically ciphers. The framework utilizes human-unreadable ciphers to potentially bypass safety alignments in natural language models. It involves teaching a language model to comprehend ciphers, converting input into a cipher format, and employing a rule-based decrypter to convert model output back to natural language.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.
For similar tasks
AI_Hospital
AI Hospital is a research repository focusing on the interactive evaluation and collaboration of Large Language Models (LLMs) as intern doctors for clinical diagnosis. The repository includes a simulation module tailored for various medical roles, introduces the Multi-View Medical Evaluation (MVME) Benchmark, provides dialog history documents of LLMs, replication instructions, performance evaluation, and guidance for creating intern doctor agents. The collaborative diagnosis with LLMs emphasizes dispute resolution. The study was authored by Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, and Jingren Zhou.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.