Best AI tools for< Information Architect >
Infographic
10 - AI tool Sites

AI2Page
AI2Page is an advanced AI tool that allows users to easily convert text into structured JSON objects. With its intuitive interface and powerful algorithms, AI2Page simplifies the process of analyzing and extracting information from text data. Users can simply input text, and AI2Page will automatically generate structured JSON output, making it ideal for data extraction, content analysis, and information retrieval tasks. The tool is designed to be user-friendly and efficient, catering to both beginners and experienced users in the field of data analysis and AI applications.
Booltool
Booltool is a free online tool that helps you to create and manage boolean searches. With Booltool, you can easily combine multiple search terms using the AND, OR, and NOT operators to create more precise and effective searches. Booltool also provides a variety of other features to help you refine your searches, such as the ability to exclude specific terms, search within a specific domain, and limit your search to a specific date range.
Goodlookup
Goodlookup is a smart function for spreadsheet users that gets very close to semantic understanding. It’s a pre-trained model that has the intuition of GPT-3 and the join capabilities of fuzzy matching. Use it like vlookup or index match to speed up your topic clustering work in google sheets!
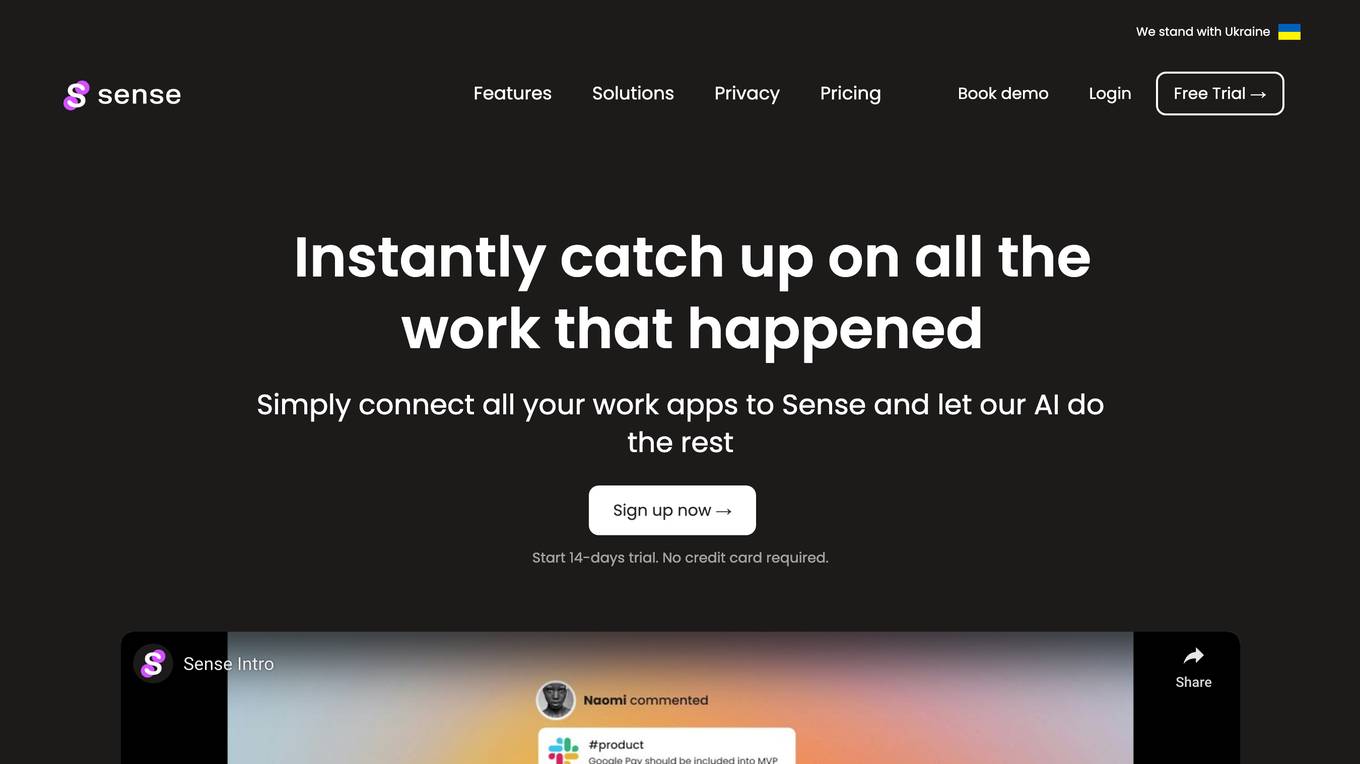
Sense
Sense is an AI-powered tool that helps you organize and search all of your work information in one place. It automatically keeps all documents, links, files, and conversations organized and interrelated, so you can easily find what you need, when you need it. Sense also provides sharing suggestions, so you can never forget to share any piece of information with relevant people. With Sense, you can: * Keep all of your work information organized in one place * Search across all of your apps, websites, and documents * Never forget to share any piece of information with relevant people * Get sharing suggestions * Collaborate with your team more effectively
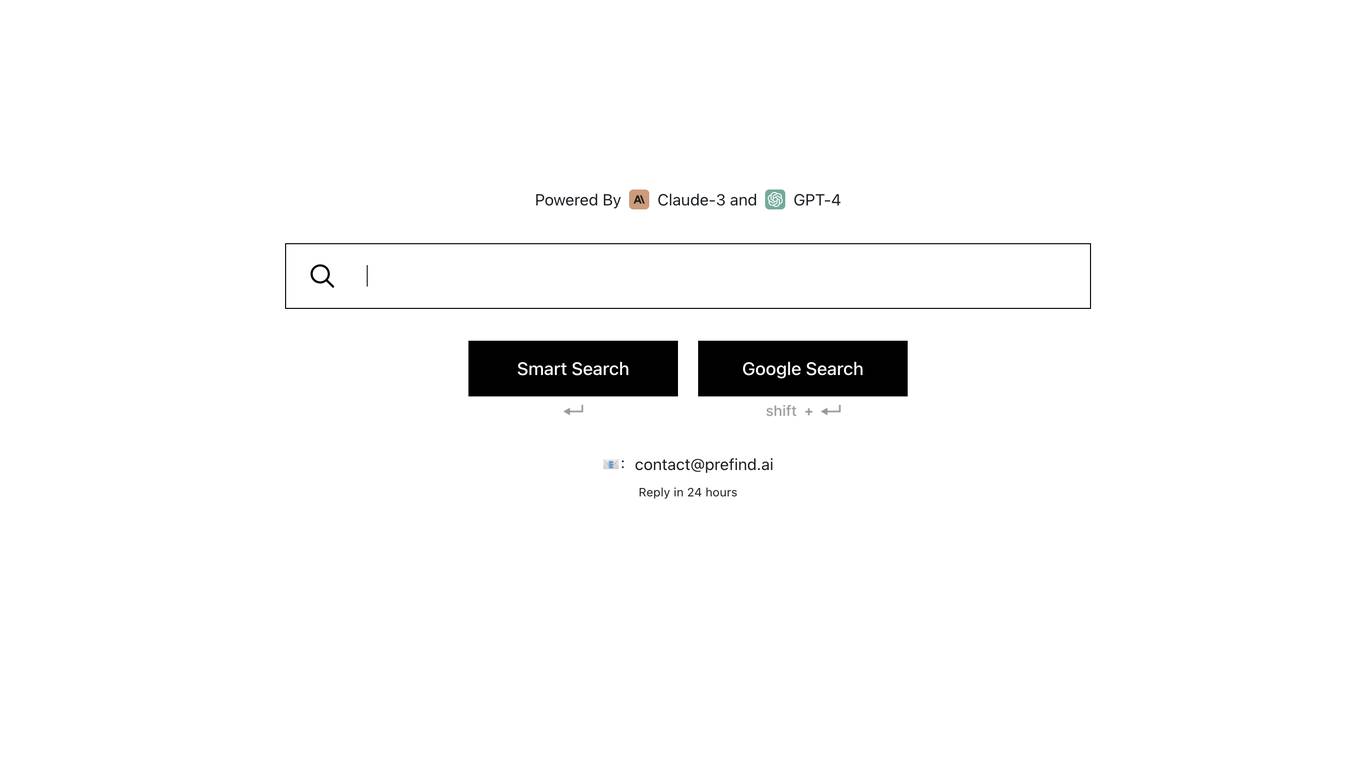
Prefind
Prefind is an AI-powered search engine that utilizes the capabilities of advanced language models like Claude-3 and GPT-4. It aims to provide users with comprehensive and relevant search results, leveraging the power of AI to enhance the search experience.

Motif
Motif is a technical writing platform that uses artificial intelligence to help you create and maintain technical documentation. It provides a suite of tools and APIs that can be used to automate the documentation process, ensuring that your content is always up-to-date and accurate.
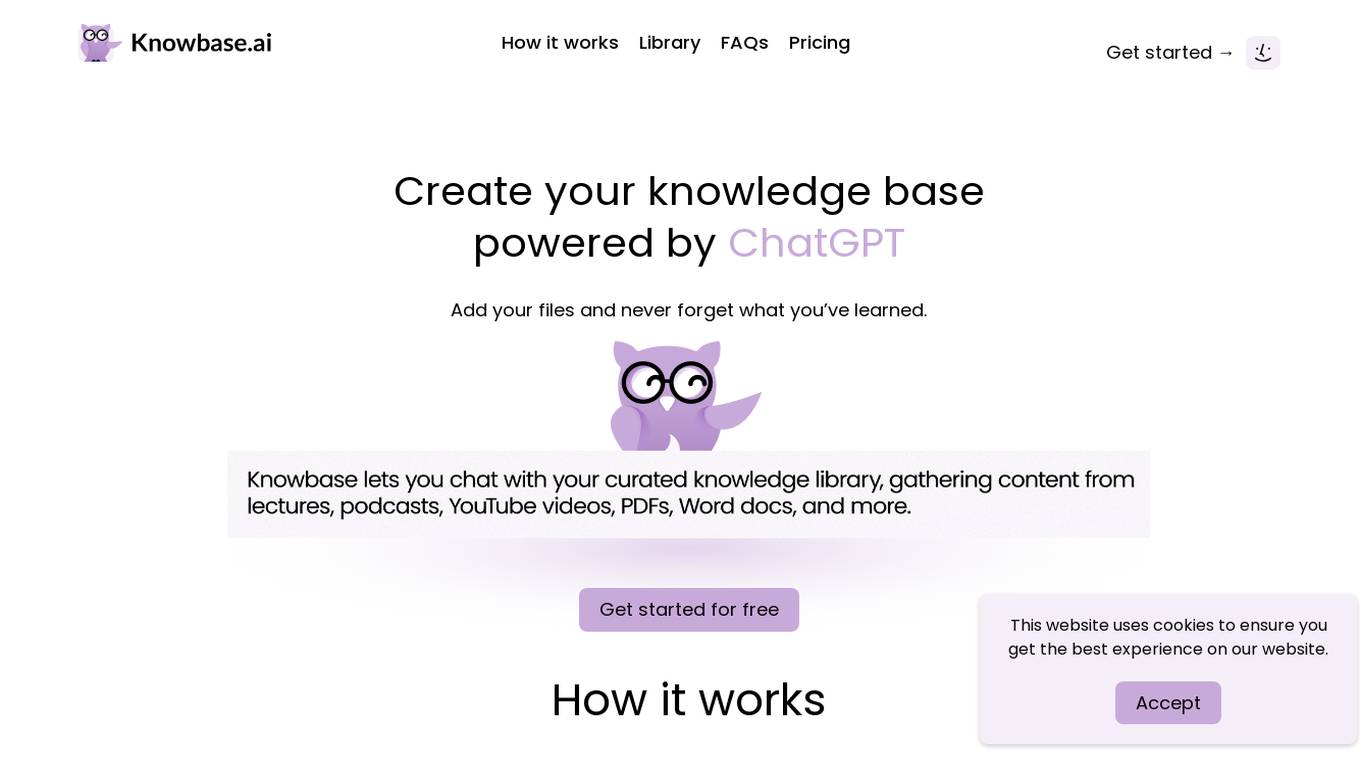
Knowbase.ai
Knowbase.ai is a knowledge management tool that allows users to store, organize, and chat with their knowledge base. It is powered by ChatGPT, which allows users to ask questions about their knowledge base and get answers in a conversational format. Knowbase.ai is designed to help users learn and remember information more effectively.

FranzAI LLM Playground
FranzAI LLM Playground is an AI-powered tool that helps you extract, classify, and analyze unstructured text data. It leverages transformer models to provide accurate and meaningful results, enabling you to build data applications faster and more efficiently. With FranzAI, you can accelerate product and content classification, enhance data interpretation, and advance data extraction processes, unlocking key insights from your textual data.

Casc
Casc is an AI-powered knowledge management tool that helps teams access and share information quickly and easily. It integrates with popular collaboration tools like Slack, Google Drive, and Confluence, allowing users to search and access documents, images, and other content from a central location. Casc also uses natural language processing to understand user queries and deliver precise answers, making it easy for teams to find the information they need without having to spend hours searching through multiple sources.
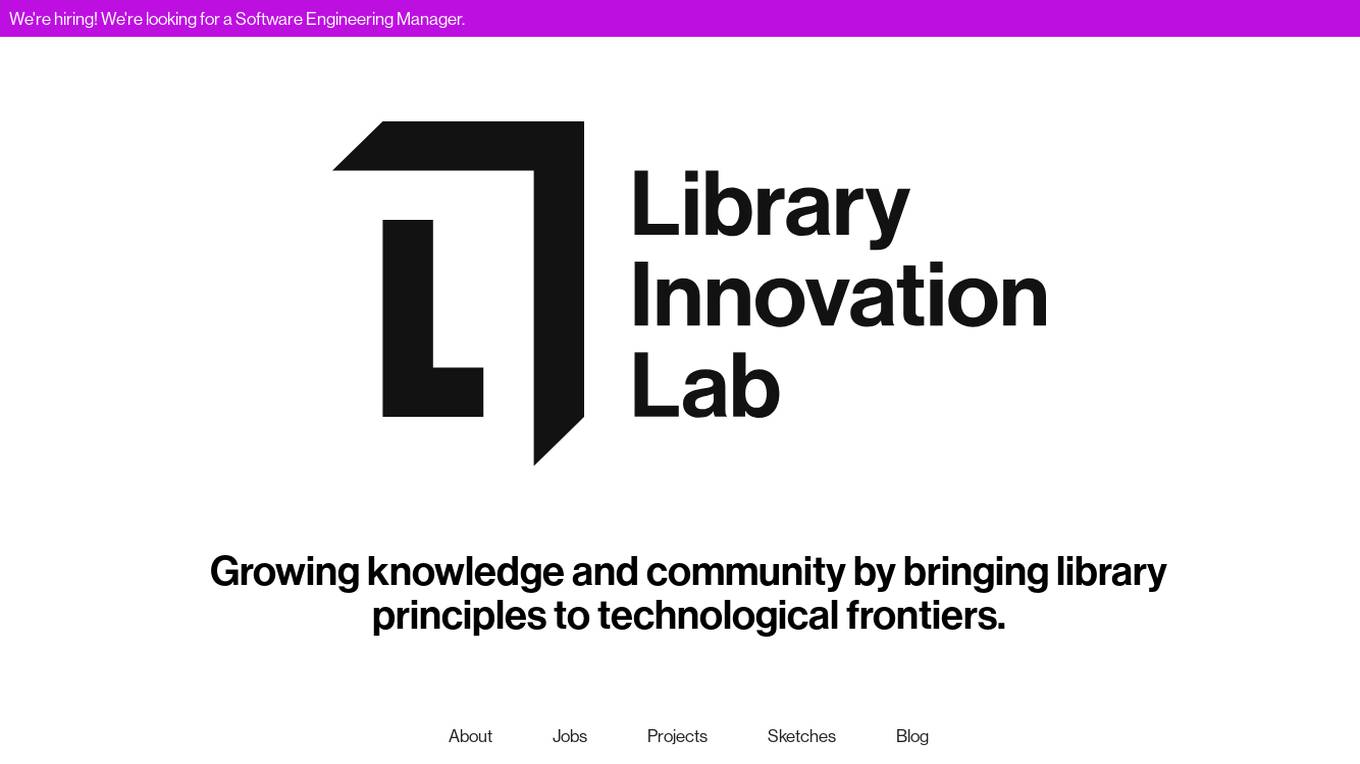
Library Innovation Lab
The Library Innovation Lab at Harvard University is an AI tool that focuses on bringing library principles to technological frontiers. It is a forward-looking group working at the intersection of libraries, technology, and law. The lab aims to democratize open knowledge and explore the use of generative AIs in information access and law. They offer various projects like Caselaw Access Project, H2O, The Nuremberg Project, Perma.cc, Alterspace, and Time Capsule Encryption to achieve their goals.
19 - Open Source Tools

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.
MaxKB
MaxKB is a knowledge base Q&A system based on the LLM large language model. MaxKB = Max Knowledge Base, which aims to become the most powerful brain of the enterprise.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.
ocular
Ocular is a set of modules and tools that allow you to build rich, reliable, and performant Generative AI-Powered Search Platforms without the need to reinvent Search Architecture. We help you build you spin up customized internal search in days not months.
documentation
Vespa documentation is served using GitHub Project pages with Jekyll. To edit documentation, check out and work off the master branch in this repository. Documentation is written in HTML or Markdown. Use a single Jekyll template _layouts/default.html to add header, footer and layout. Install bundler, then $ bundle install $ bundle exec jekyll serve --incremental --drafts --trace to set up a local server at localhost:4000 to see the pages as they will look when served. If you get strange errors on bundle install try $ export PATH=“/usr/local/opt/[email protected]/bin:$PATH” $ export LDFLAGS=“-L/usr/local/opt/[email protected]/lib” $ export CPPFLAGS=“-I/usr/local/opt/[email protected]/include” $ export PKG_CONFIG_PATH=“/usr/local/opt/[email protected]/lib/pkgconfig” The output will highlight rendering/other problems when starting serving. Alternatively, use the docker image `jekyll/jekyll` to run the local server on Mac $ docker run -ti --rm --name doc \ --publish 4000:4000 -e JEKYLL_UID=$UID -v $(pwd):/srv/jekyll \ jekyll/jekyll jekyll serve or RHEL 8 $ podman run -it --rm --name doc -p 4000:4000 -e JEKYLL_ROOTLESS=true \ -v "$PWD":/srv/jekyll:Z docker.io/jekyll/jekyll jekyll serve The layout is written in denali.design, see _layouts/default.html for usage. Please do not add custom style sheets, as it is harder to maintain.

deep-seek
DeepSeek is a new experimental architecture for a large language model (LLM) powered internet-scale retrieval engine. Unlike current research agents designed as answer engines, DeepSeek aims to process a vast amount of sources to collect a comprehensive list of entities and enrich them with additional relevant data. The end result is a table with retrieved entities and enriched columns, providing a comprehensive overview of the topic. DeepSeek utilizes both standard keyword search and neural search to find relevant content, and employs an LLM to extract specific entities and their associated contents. It also includes a smaller answer agent to enrich the retrieved data, ensuring thoroughness. DeepSeek has the potential to revolutionize research and information gathering by providing a comprehensive and structured way to access information from the vastness of the internet.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

Docs2KG
Docs2KG is a tool designed for constructing a unified knowledge graph from heterogeneous documents. It addresses the challenges of digitizing diverse unstructured documents and constructing a high-quality knowledge graph with less effort. The tool combines bottom-up and top-down approaches, utilizing a human-LLM collaborative interface to enhance the generated knowledge graph. It organizes the knowledge graph into MetaKG, LayoutKG, and SemanticKG, providing a comprehensive view of document content. Docs2KG aims to streamline the process of knowledge graph construction and offers metrics for evaluating the quality of automatic construction.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
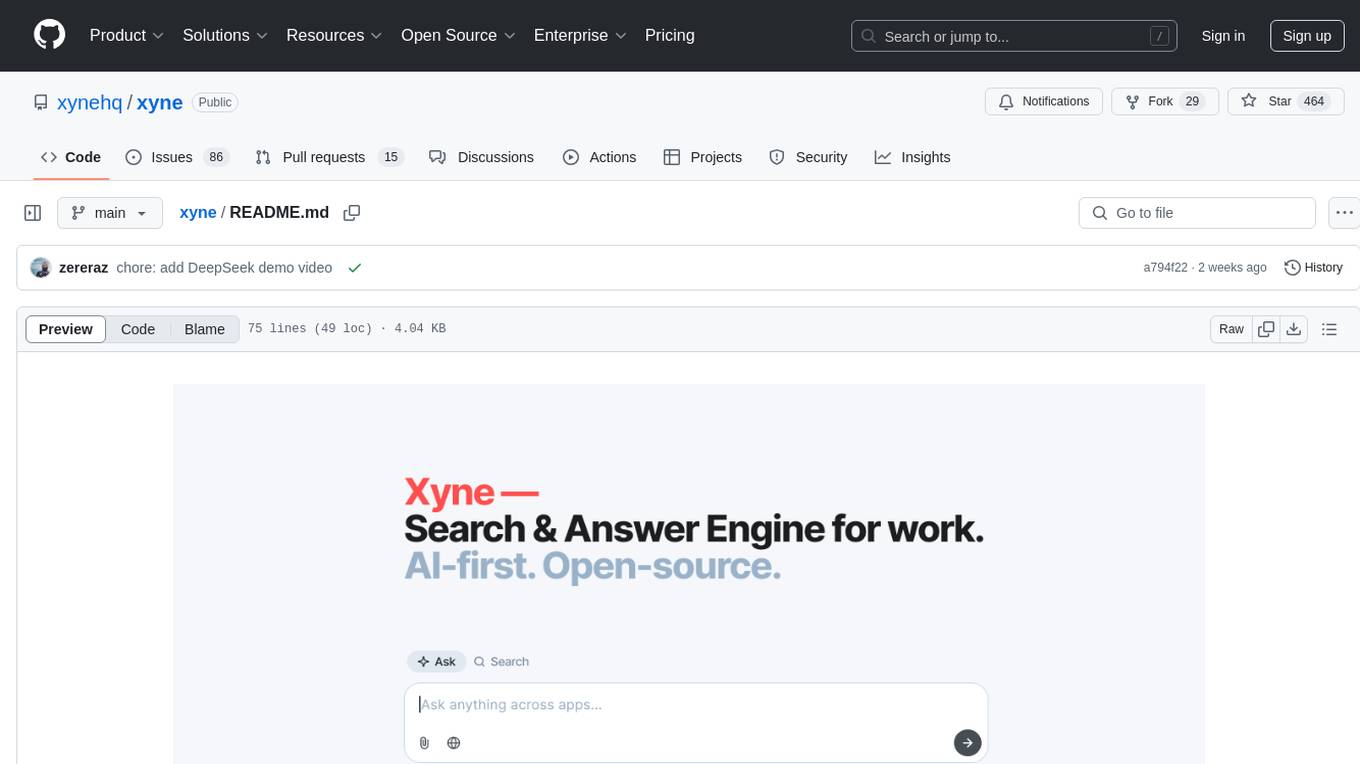
xyne
Xyne is an AI-first Search & Answer Engine for work, serving as an OSS alternative to Glean, Gemini, and MS Copilot. It securely indexes data from various applications like Google Workspace, Atlassian suite, Slack, and Github, providing a Google + ChatGPT-like experience to find information and get up-to-date answers. Users can easily locate files, triage issues, inquire about customers/deals/features/tickets, and discover relevant contacts. Xyne enhances AI models by providing contextual information in a secure, private, and responsible manner, making it the most secure and future-proof solution for integrating AI into work environments.

growi
GROWI is a collaborative wiki platform that allows users to create hierarchical pages with markdown, edit simultaneously with multiple people, and support authentication with LDAP/Active Directory, OAuth, and SAML. It also integrates with Slack/Mattermost, IFTTT, and allows for plugin customization. GROWI is Docker and Docker Compose ready, supports multiple sites, HTTPS with Let's Encrypt proxy integration, and offers migration guides for on-premise installations. The tool is built with Node.js, npm, pnpm, Turborepo, and requires MongoDB, with optional dependencies on Redis and ElasticSearch for full-text search functionality.
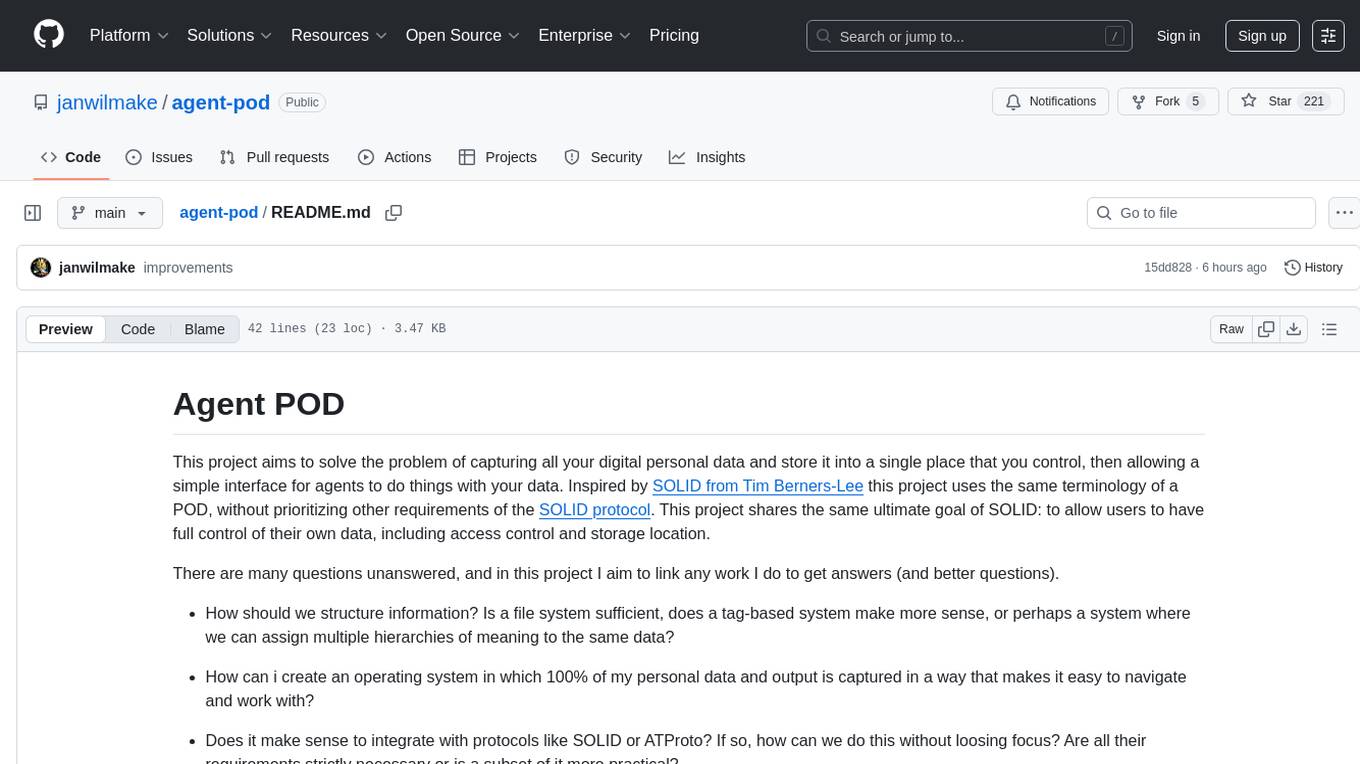
agent-pod
Agent POD is a project focused on capturing and storing personal digital data in a user-controlled environment, with the goal of enabling agents to interact with the data. It explores questions related to structuring information, creating an efficient data capture system, integrating with protocols like SOLID, and enabling data storage for groups. The project aims to transition from traditional data-storing apps to a system where personal data is owned and controlled by the user, facilitating the creation of 'solid-first' apps.
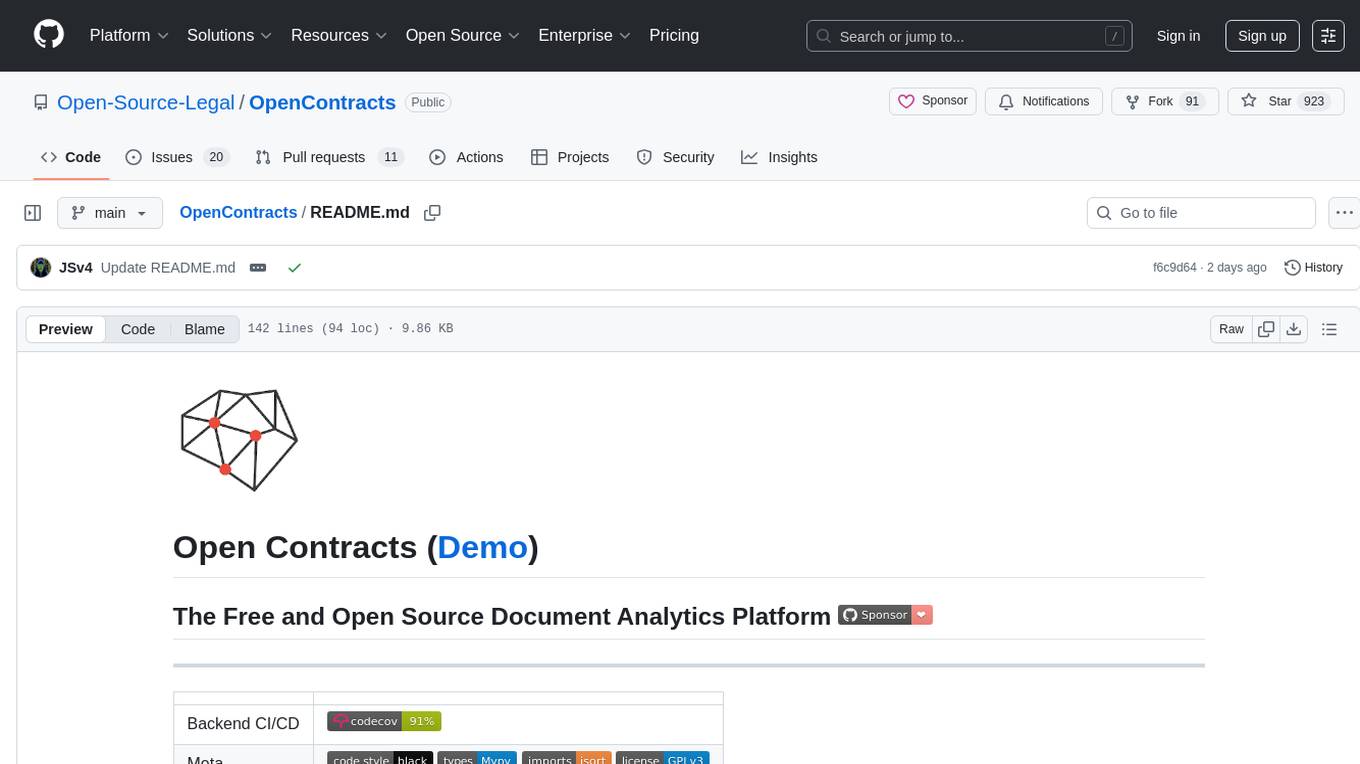
OpenContracts
OpenContracts is a free and open-source document analytics platform designed to empower knowledge owners and subject matter experts. It supports multiple document formats, ingestion pipelines, and custom document analytics tools. Users can manage documents, define metadata schemas, extract layout features, generate vector embeddings, deploy custom analyzers, support new document formats, annotate documents, extract bulk data, and create bespoke data extraction workflows. The tool aims to provide a standardized architecture for analyzing contracts and making data portable, with a focus on PDF and text-based formats. It includes features like document management, layout parsing, pluggable architectures, human annotation interface, and a custom LLM framework for conversation management and real-time streaming.
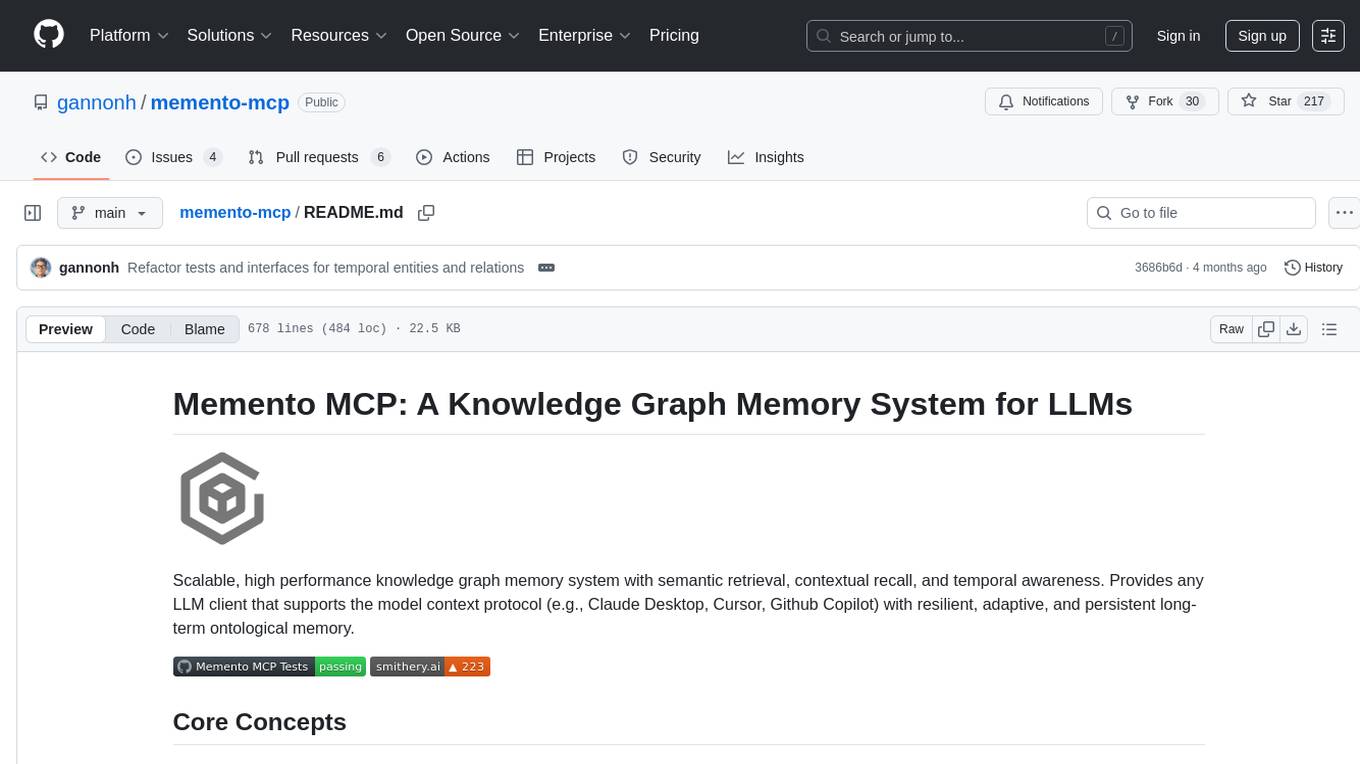
memento-mcp
Memento MCP is a scalable, high-performance knowledge graph memory system designed for LLMs. It offers semantic retrieval, contextual recall, and temporal awareness to any LLM client supporting the model context protocol. The system is built on core concepts like entities and relations, utilizing Neo4j as its storage backend for unified graph and vector search capabilities. With advanced features such as semantic search, temporal awareness, confidence decay, and rich metadata support, Memento MCP provides a robust solution for managing knowledge graphs efficiently and effectively.
61 - OpenAI Gpts
Schema Advisor - Amanda Jordan
Expert in schema.org, guiding precise use of 'additionalType'.

OpenIndex.ai
Chat with all the knowledge, documents and collections contributed to the OpenIndex search engine.

Hierarchy Navigator
If you crave a systematic approach to learning, I'm your Knowledge Architect. I'll navigate you through comprehensive knowledge hierarchies, step by step, in any subject you choose. Share this systematic learning method with your friends to elevate their learning experiences.
Airfleet's Tech B2B Sitemap Architect
Detailed, accurate sitemap and information architecture advice for tech B2B
Knowledge Scanner 知识探测器
这个工具可以帮你从浅入深的掌握一个深奥的知识领域的内容,他可以循序渐进的设计由浅到深的问题让你来回答,等你回答了之后,我可以判断你的知识层次到什么程度,然后再给你提出对应的解释一个详细理论的方案。
GPT Searcher
Specializes in web searches for chat.openai.com using specific query format.
Data Extractor Pro
Expert in data extraction and context-driven analysis. Can read most filetypes including PDFS, XLSX, Word, TXT, CSV, EML, Etc.
KCS Guru
AI assistant for self-service and knowledge management, incorporating insights from the 'Practices Guide' by Consortium for Service Innovation, under CC BY-NC 4.0 (https://bit.ly/3QUvgBm). No adaptations made.
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue
Information Framework Assistant
A SID framework companion for understanding and utilizing the Information Framework.

Procedure Extraction and Formatting
Extracts and formats procedures from manuals into templates
Search Helper with Henk van Ess and Translation
Refines search queries with specific terms and includes Google links

The Master of Insight: Intellectual.AI
Intellectual.AI slices through the complexities of information to deliver sharp, comprehensive insights with a laser focus on logic, structure, and cross-domain analysis
FlexiSearch Guru
I'm FlexiSearch Guru, your go-to for SAP Commerce Cloud's flexible search queries.
QuickSilver AI - Natural Language R.A.G DocuMaster
Easily format and optimize your documents, create NLRAG (Natural Language Retrieval Augmented Generation) indexes and more!
Accurate GPT Live With Code Interpreter
Expert in providing accurate, up-to-date, and validated responses, cross-references information with reliable web sources and informs users about the confidence level of its responses.
TiddlyWiki Guide
A TiddlyWiki expert providing detailed guidance on its usage and features.

Yellowpages Navigator - Find Local Businesses Info
I assist with finding businesses on Yellowpages, providing factual and updated information.
Ask Oracle
Let me guide you with the most effective tools to tackle your how-to questions.
GPT-Info
Extensive guide for ChatGPT models. 🛈 This software is free and open-source; anyone can redistribute it and/or modify it.
AIRZ Search Summarizer
Browse the web for the search term and summarize the results from sources
Topic Explorer
Expert in breaking down a topic into subtopics, and providing in-depth analysis on the subtopics.

Smart Sorter
A versatile, user-friendly Sorting Bot for diverse data types, prioritizing privacy and adaptability.

Mindy
I help with inquiries about Mindflow, ensuring clear and informative responses. All requests are anonymous and hidden to us.

Complex Knowledge Atomizer
I refine complex knowledge into granular, integrated solutions.

GPT Search & Finderr
Optimized with advanced search operators for refined results. Specializing in finding and linking top custom GPTs from builders around the world. Version 0.3.0
Open Data Italia bot
Fornisce informazioni sulla normativa italiana in materia di open data, con un tono professionale e divulgativo. In modo che sia più facile chiederne e/o pretenderne la pubblicazione.
No Web Browser GPT
No web browser. Doesn't try to use the web to look up events. Nor can it.
Summary of articles by density chain
This prompt is structured to provide an effective methodology in generating progressively more detailed and specific summaries, focused on key entities.