
Advanced-RVC-Inference
Advanced RVC Inference for quicker and effortless model downloads
Stars: 66
Advanced RVC Inference is a state-of-the-art web UI tool designed to streamline rapid and effortless inference. It includes a model downloader, a voice splitter, and training functionalities. The tool is stable and mature, focusing on security patches, dependency updates, and occasional feature improvements. Users can perform voice conversion, pitch shifting, batch processing, music separation, and more using the web interface or command line interface. The tool is suitable for tasks like voice conversion, audio processing, and model training.
README:
Advanced RVC Inference presents itself as a state-of-the-art web UI crafted to streamline rapid and effortless inference. This comprehensive toolset encompasses a model downloader, a voice splitter, training and more.
[!NOTE]
Advanced RVC Inference will no longer receive frequent updates. Going forward, development will focus mainly on security patches, dependency updates, and occasional feature improvements. This is because the project is already stable and mature with limited room for further improvements. Pull requests are still welcome and will be reviewed.
pip install git+https://github.com/ArkanDash/Advanced-RVC-Inference.gitFor CUDA-enabled GPUs:
pip install git+https://github.com/ArkanDash/Advanced-RVC-Inference.git#egg=advanced-rvc-inference[gpu]git clone https://github.com/ArkanDash/Advanced-RVC-Inference.git
cd Advanced-RVC-Inference
pip install -e .Launch the Gradio web UI:
rvc-gui# or
python -m advanced_rvc_inference.app.gui
The web interface will be available at http://localhost:7860
see guides more at Wiki!
Run voice conversion on a single audio file:
rvc-cli infer --model path/to/model.pth --input audio.wav --output converted.wavWith pitch shift (one octave up):
rvc-cli infer --model vocals.pth --input audio.wav --pitch 12 --output output.wavProcess multiple audio files at once:
rvc-cli infer-batch --model model.pth --input_dir ./songs --output_dir ./convertedSeparate vocals from instrumental tracks:
rvc-cli separate --input song.mp3 --output_dir ./separatedLaunch the Gradio web UI:
rvc-cli serve --port 7860View help for any command:
rvc-cli --help
rvc-cli infer --help
rvc-cli separate --helpEnsure you have CUDA installed and PyTorch with CUDA support:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Contributions are welcome! Please read our Contributing Guide for details.
This project is licensed under the MIT License - see the LICENSE file for details.
The use of the converted voice for the following purposes is prohibited:
- Criticizing or attacking individuals
- Advocating for or opposing specific political positions, religions, or ideologies
- Publicly displaying strongly stimulating expressions without proper zoning
- Selling of voice models and generated voice clips
- Impersonation of the original owner of the voice with malicious intentions
- Fraudulent purposes that lead to identity theft or fraudulent phone calls
| Repository | Owner |
|---|---|
| Vietnamese-RVC | Phạm Huỳnh Anh |
| Applio | IAHispano |
| python-audio-separator | Nomad Karaoke |
| whisper | OpenAI |
| BigVGAN | Nvidia |
For issues and feature requests, please use the GitHub Issues page.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Advanced-RVC-Inference
Similar Open Source Tools
Advanced-RVC-Inference
Advanced RVC Inference is a state-of-the-art web UI tool designed to streamline rapid and effortless inference. It includes a model downloader, a voice splitter, and training functionalities. The tool is stable and mature, focusing on security patches, dependency updates, and occasional feature improvements. Users can perform voice conversion, pitch shifting, batch processing, music separation, and more using the web interface or command line interface. The tool is suitable for tasks like voice conversion, audio processing, and model training.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.

OmniSteward
OmniSteward is an AI-powered steward system based on large language models that can interact with users through voice or text to help control smart home devices and computer programs. It supports multi-turn dialogue, tool calling for complex tasks, multiple LLM models, voice recognition, smart home control, computer program management, online information retrieval, command line operations, and file management. The system is highly extensible, allowing users to customize and share their own tools.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.
open-assistant-api
Open Assistant API is an open-source, self-hosted AI intelligent assistant API compatible with the official OpenAI interface. It supports integration with more commercial and private models, R2R RAG engine, internet search, custom functions, built-in tools, code interpreter, multimodal support, LLM support, and message streaming output. Users can deploy the service locally and expand existing features. The API provides user isolation based on tokens for SaaS deployment requirements and allows integration of various tools to enhance its capability to connect with the external world.
toolmate
ToolMate AI is an advanced AI companion that integrates agents, tools, and plugins to excel in conversations, generative work, and task execution. It supports multi-step actions, allowing users to customize workflows for tackling complex projects with ease. The tool offers a wide range of AI backends and models, including Ollama, Llama.cpp, Groq Cloud API, OpenAI API, and Google Gemini via Vertex AI. Users can easily switch between backends and leverage AI models like wizardlm2 and mixtral. ToolMate AI stands out for its distinctive features such as tool calling for any LLMs, running multiple tools in one go, highly customizable plugins, and integration with popular AI tools. It also supports quick tool calling using '@' notation and enables the execution of computing tasks on demand. With features like multiple tools in one go, customizable plugins, system command and fabric integration, GPU offloading support, real-time data access, and device information retrieval, ToolMate AI offers a comprehensive solution for various tasks and content creation.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
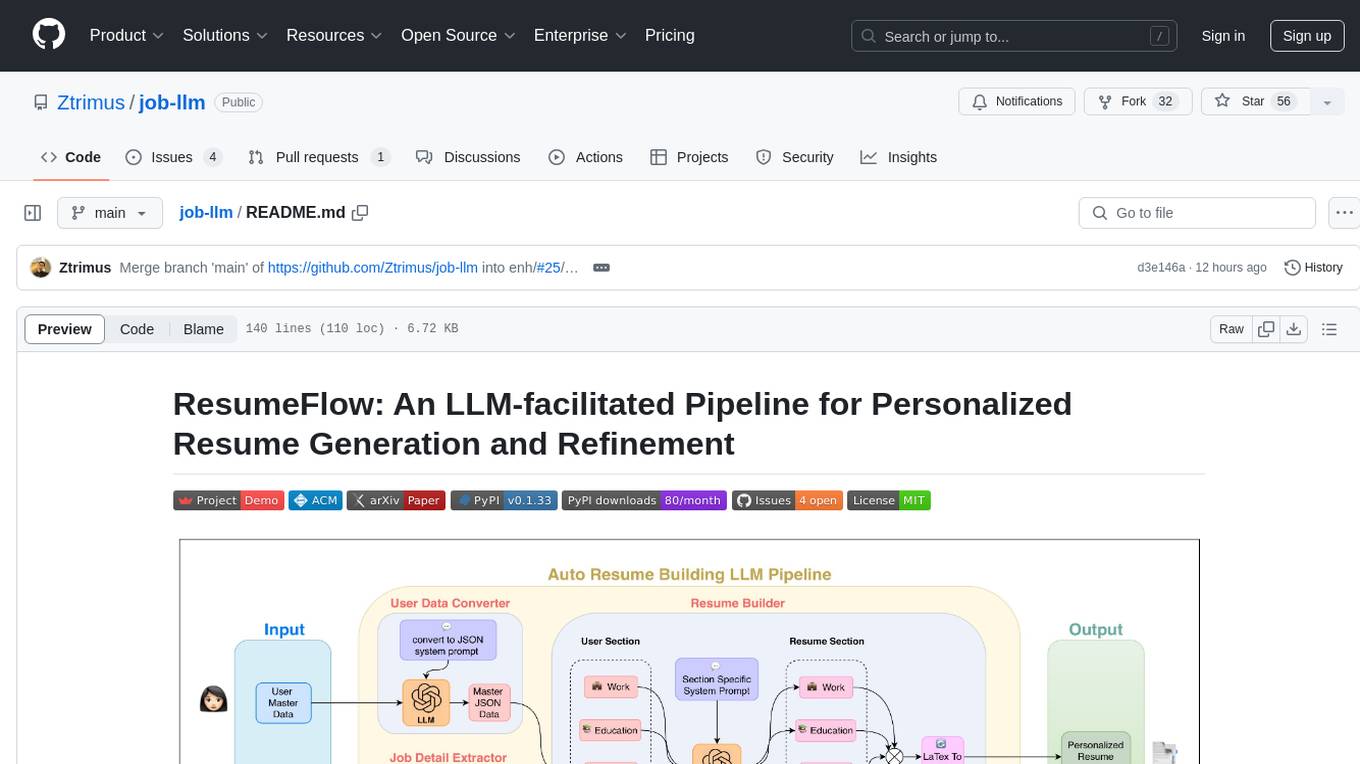
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
srcbook
Srcbook is an open-source interactive programming environment for TypeScript that allows users to create, run, and share reproducible programs and ideas. It features AI capabilities for exploring and iterating on ideas, supports exporting to valid markdown format, and enables diagraming with mermaid for rich annotations. Users can locally execute programs through a web interface, powered by Node.js under the Apache2 license.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
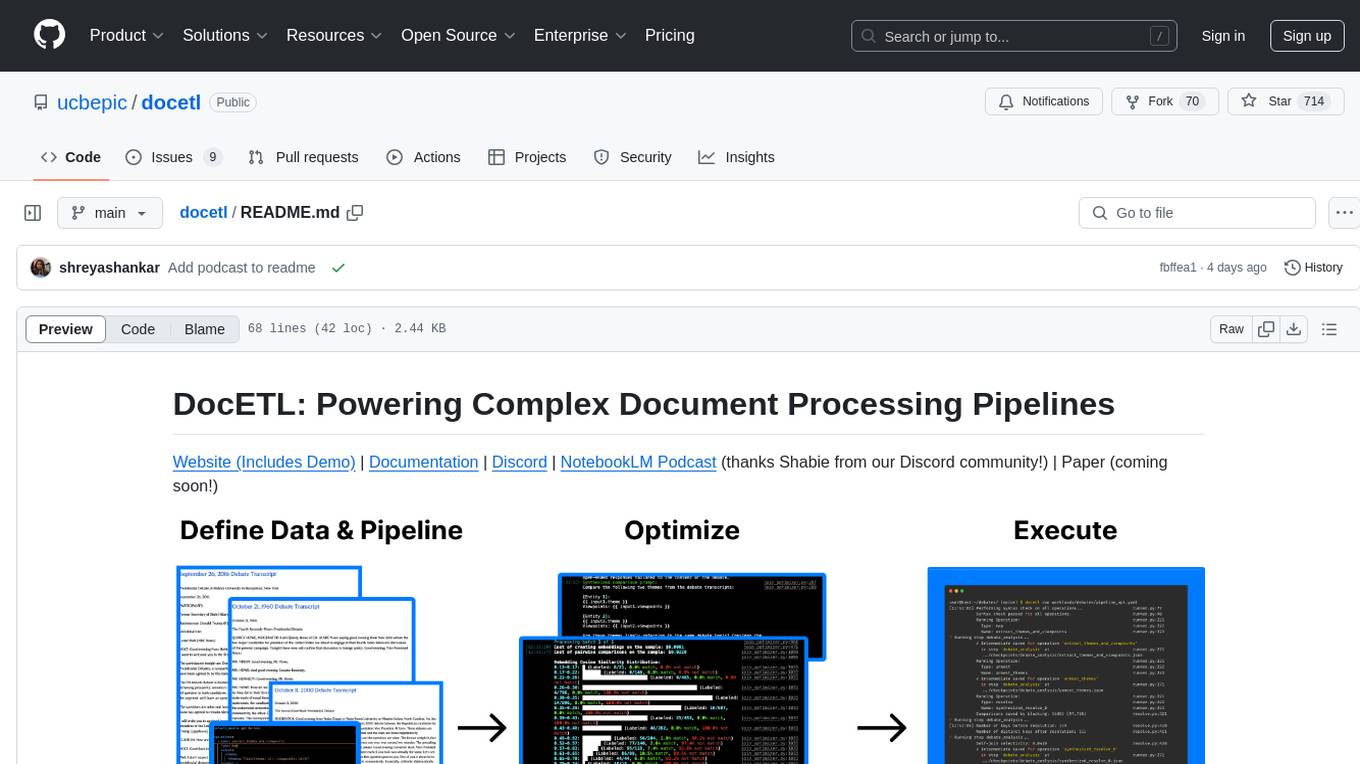
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
Kolo
Kolo is a lightweight tool for fast and efficient data generation, fine-tuning, and testing of Large Language Models (LLMs) on your local machine. It simplifies the fine-tuning and data generation process, runs locally without the need for cloud-based services, and supports popular LLM toolkits. Kolo is built using tools like Unsloth, Torchtune, Llama.cpp, Ollama, Docker, and Open WebUI. It requires Windows 10 OS or higher, Nvidia GPU with CUDA 12.1 capability, and 8GB+ VRAM, and 16GB+ system RAM. Users can join the Discord group for issues or feedback. The tool provides easy setup, training data generation, and integration with major LLM frameworks.
DeepBI
DeepBI is an AI-native data analysis platform that leverages the power of large language models to explore, query, visualize, and share data from any data source. Users can use DeepBI to gain data insight and make data-driven decisions.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
For similar tasks
Advanced-RVC-Inference
Advanced RVC Inference is a state-of-the-art web UI tool designed to streamline rapid and effortless inference. It includes a model downloader, a voice splitter, and training functionalities. The tool is stable and mature, focusing on security patches, dependency updates, and occasional feature improvements. Users can perform voice conversion, pitch shifting, batch processing, music separation, and more using the web interface or command line interface. The tool is suitable for tasks like voice conversion, audio processing, and model training.

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.