
nodejs-whisper
NodeJS Bindings for Whisper - the CPU version of OpenAI's Whisper, as initially crafted in C++ by ggerganov.
Stars: 103
Node.js bindings for OpenAI's Whisper model that automatically converts audio to WAV format with a 16000 Hz frequency to support the whisper model. It outputs transcripts to various formats, is optimized for CPU including Apple Silicon ARM, provides timestamp precision to single word, allows splitting on word rather than token, translation from source language to English, and conversion of audio format to WAV for whisper model support.
README:
Node.js bindings for OpenAI's Whisper model.
- Automatically convert the audio to WAV format with a 16000 Hz frequency to support the whisper model.
- Output transcripts to (.txt .srt .vtt .json .wts .lrc)
- Optimized for CPU (Including Apple Silicon ARM)
- Timestamp precision to single word
- Split on word rather than on token (Optional)
- Translate from source language to english (Optional)
- Convert audio format to wav to support whisper model
- Install make tools
sudo apt update
sudo apt install build-essential- Install nodejs-whisper with npm
npm i nodejs-whisper- Download whisper model
npx nodejs-whisper download- NOTE: user may need to install make tool
-
Install MinGW-w64 or MSYS2 (which includes make tools)
- Option 1: Install MSYS2 from https://www.msys2.org/
- Option 2: Install MinGW-w64 from https://www.mingw-w64.org/
-
Install nodejs-whisper with npm
npm i nodejs-whisper- Download whisper model
npx nodejs-whisper download- Note: Make sure mingw32-make or make is available in your system PATH.
See example/index.ts (can be run with $ npm run test)
import path from 'path'
import { nodewhisper } from 'nodejs-whisper'
// Need to provide exact path to your audio file.
const filePath = path.resolve(__dirname, 'YourAudioFileName')
await nodewhisper(filePath, {
modelName: 'base.en', //Downloaded models name
autoDownloadModelName: 'base.en', // (optional) autodownload a model if model is not present
removeWavFileAfterTranscription: false, // (optional) remove wav file once transcribed
withCuda: false // (optional) use cuda for faster processing
logger: console // (optional) Logging instance, defaults to console
whisperOptions: {
outputInCsv: false, // get output result in csv file
outputInJson: false, // get output result in json file
outputInJsonFull: false, // get output result in json file including more information
outputInLrc: false, // get output result in lrc file
outputInSrt: true, // get output result in srt file
outputInText: false, // get output result in txt file
outputInVtt: false, // get output result in vtt file
outputInWords: false, // get output result in wts file for karaoke
translateToEnglish: false, // translate from source language to english
wordTimestamps: false, // word-level timestamps
timestamps_length: 20, // amount of dialogue per timestamp pair
splitOnWord: true, // split on word rather than on token
},
})
// Model list
const MODELS_LIST = [
'tiny',
'tiny.en',
'base',
'base.en',
'small',
'small.en',
'medium',
'medium.en',
'large-v1',
'large',
'large-v3-turbo',
] interface IOptions {
modelName: string
removeWavFileAfterTranscription?: boolean
withCuda?: boolean
autoDownloadModelName?: string
whisperOptions?: WhisperOptions
logger?: Console
}
interface WhisperOptions {
outputInCsv?: boolean
outputInJson?: boolean
outputInJsonFull?: boolean
outputInLrc?: boolean
outputInSrt?: boolean
outputInText?: boolean
outputInVtt?: boolean
outputInWords?: boolean
translateToEnglish?: boolean
timestamps_length?: number
wordTimestamps?: boolean
splitOnWord?: boolean
}
Clone the project
git clone https://github.com/ChetanXpro/nodejs-whisperGo to the project directory
cd nodejs-whisperInstall dependencies
npm installStart the server
npm run devBuild project
npm run buildIf you have any feedback, please reach out to us at [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for nodejs-whisper
Similar Open Source Tools
nodejs-whisper
Node.js bindings for OpenAI's Whisper model that automatically converts audio to WAV format with a 16000 Hz frequency to support the whisper model. It outputs transcripts to various formats, is optimized for CPU including Apple Silicon ARM, provides timestamp precision to single word, allows splitting on word rather than token, translation from source language to English, and conversion of audio format to WAV for whisper model support.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.
llm-document-ocr
LLM Document OCR is a Node.js tool that utilizes GPT4 and Claude3 for OCR and data extraction. It converts PDFs into PNGs, crops white-space, cleans up JSON strings, and supports various image formats. Users can customize prompts for data extraction. The tool is sponsored by Mercoa, offering API for BillPay and Invoicing.
node-llama-cpp
node-llama-cpp is a tool that allows users to run AI models locally on their machines. It provides pre-built bindings with the option to build from source using cmake. Users can interact with text generation models, chat with models using a chat wrapper, and force models to generate output in a parseable format like JSON. The tool supports Metal and CUDA, offers CLI functionality for chatting with models without coding, and ensures up-to-date compatibility with the latest version of llama.cpp. Installation includes pre-built binaries for macOS, Linux, and Windows, with the option to build from source if binaries are not available for the platform.
genaiscript
GenAIScript is a scripting environment designed to facilitate file ingestion, prompt development, and structured data extraction. Users can define metadata and model configurations, specify data sources, and define tasks to extract specific information. The tool provides a convenient way to analyze files and extract desired content in a structured format. It offers a user-friendly interface for working with data and automating data extraction processes, making it suitable for various data processing tasks.
HuggingFaceModelDownloader
The HuggingFace Model Downloader is a utility tool for downloading models and datasets from the HuggingFace website. It offers multithreaded downloading for LFS files and ensures the integrity of downloaded models with SHA256 checksum verification. The tool provides features such as nested file downloading, filter downloads for specific LFS model files, support for HuggingFace Access Token, and configuration file support. It can be used as a library or a single binary for easy model downloading and inference in projects.
aioconsole
aioconsole is a Python package that provides asynchronous console and interfaces for asyncio. It offers asynchronous equivalents to input, print, exec, and code.interact, an interactive loop running the asynchronous Python console, customization and running of command line interfaces using argparse, stream support to serve interfaces instead of using standard streams, and the apython script to access asyncio code at runtime without modifying the sources. The package requires Python version 3.8 or higher and can be installed from PyPI or GitHub. It allows users to run Python files or modules with a modified asyncio policy, replacing the default event loop with an interactive loop. aioconsole is useful for scenarios where users need to interact with asyncio code in a console environment.
flapi
flAPI is a powerful service that automatically generates read-only APIs for datasets by utilizing SQL templates. Built on top of DuckDB, it offers features like automatic API generation, support for Model Context Protocol (MCP), connecting to multiple data sources, caching, security implementation, and easy deployment. The tool allows users to create APIs without coding and enables the creation of AI tools alongside REST endpoints using SQL templates. It supports unified configuration for REST endpoints and MCP tools/resources, concurrent servers for REST API and MCP server, and automatic tool discovery. The tool also provides DuckLake-backed caching for modern, snapshot-based caching with features like full refresh, incremental sync, retention, compaction, and audit logs.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
text-extract-api
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.
shortest
Shortest is an AI-powered natural language end-to-end testing framework built on Playwright. It provides a seamless testing experience by allowing users to write tests in natural language and execute them using Anthropic Claude API. The framework also offers GitHub integration with 2FA support, making it suitable for testing web applications with complex authentication flows. Shortest simplifies the testing process by enabling users to run tests locally or in CI/CD pipelines, ensuring the reliability and efficiency of web applications.
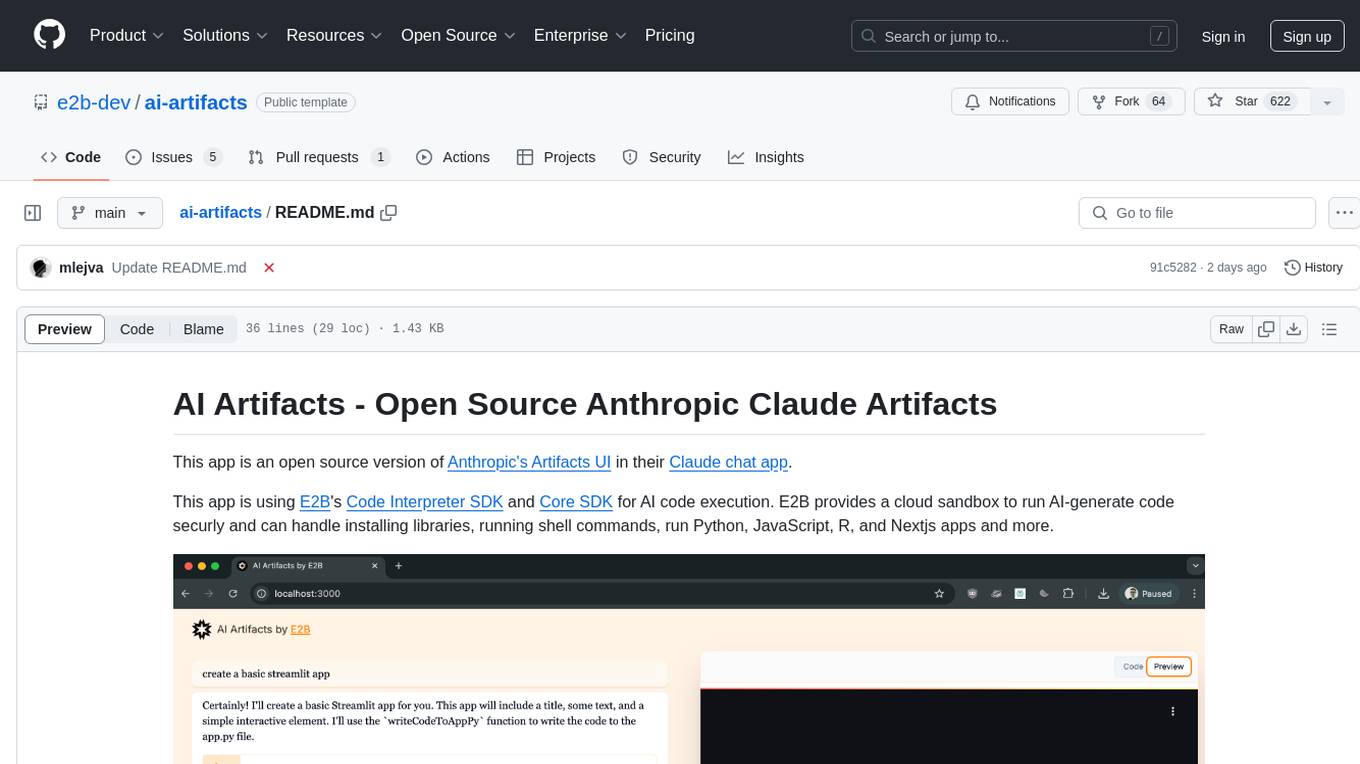
ai-artifacts
AI Artifacts is an open source tool that replicates Anthropic's Artifacts UI in the Claude chat app. It utilizes E2B's Code Interpreter SDK and Core SDK for secure AI code execution in a cloud sandbox environment. Users can run AI-generated code in various languages such as Python, JavaScript, R, and Nextjs apps. The tool also supports running AI-generated Python in Jupyter notebook, Next.js apps, and Streamlit apps. Additionally, it offers integration with Vercel AI SDK for tool calling and streaming responses from the model.
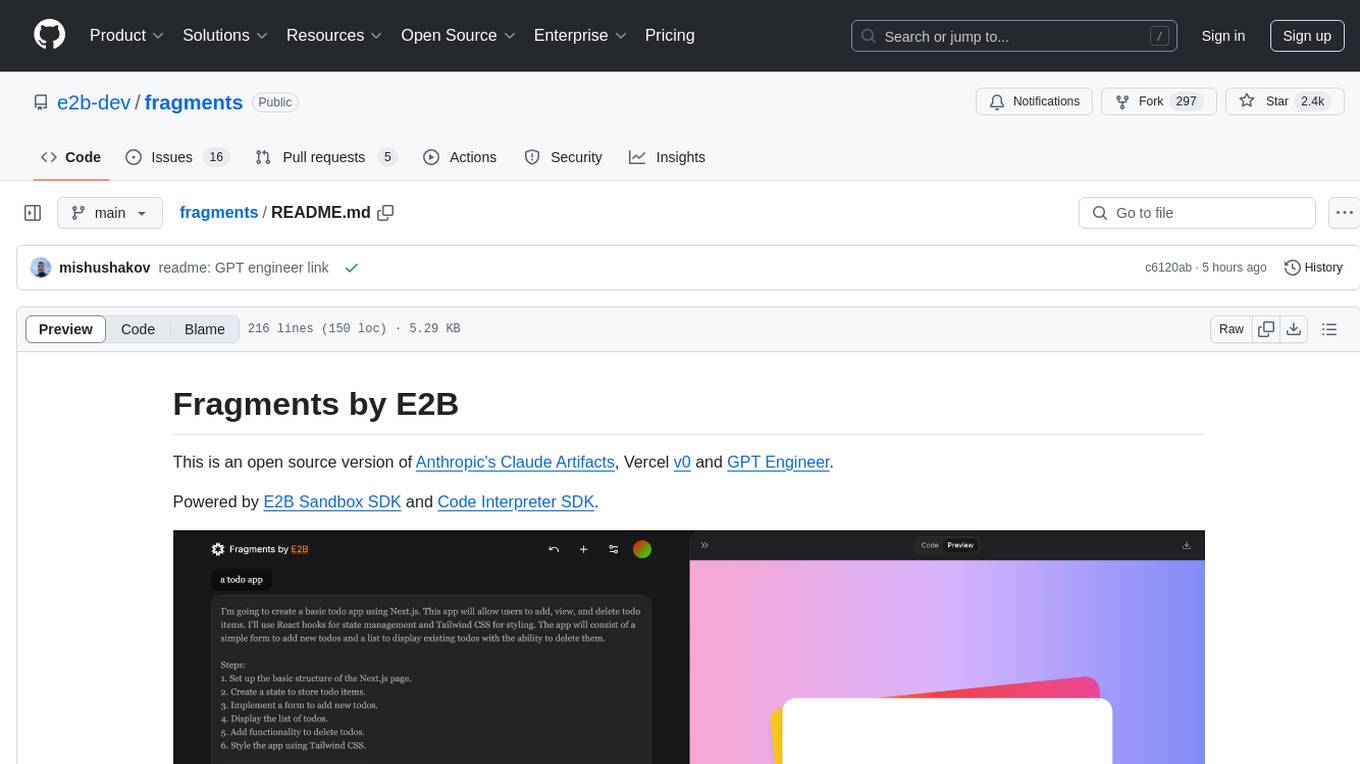
fragments
Fragments is an open-source tool that leverages Anthropic's Claude Artifacts, Vercel v0, and GPT Engineer. It is powered by E2B Sandbox SDK and Code Interpreter SDK, allowing secure execution of AI-generated code. The tool is based on Next.js 14, shadcn/ui, TailwindCSS, and Vercel AI SDK. Users can stream in the UI, install packages from npm and pip, and add custom stacks and LLM providers. Fragments enables users to build web apps with Python interpreter, Next.js, Vue.js, Streamlit, and Gradio, utilizing providers like OpenAI, Anthropic, Google AI, and more.
maclocal-api
MacLocalAPI is a macOS server application that exposes Apple's Foundation Models through OpenAI-compatible API endpoints. It allows users to run Apple Intelligence locally with full OpenAI API compatibility. The tool supports MLX local models, API gateway mode, LoRA adapter support, Vision OCR, built-in WebUI, privacy-first processing, fast and lightweight operation, easy integration with existing OpenAI client libraries, and provides token consumption metrics. Users can install MacLocalAPI using Homebrew or pip, and it requires macOS 26 or later, an Apple Silicon Mac, and Apple Intelligence enabled in System Settings. The tool is designed for easy integration with Python, JavaScript, and open-webui applications.

js-genai
The Google Gen AI JavaScript SDK is an experimental SDK for TypeScript and JavaScript developers to build applications powered by Gemini. It supports both the Gemini Developer API and Vertex AI. The SDK is designed to work with Gemini 2.0 features. Users can access API features through the GoogleGenAI classes, which provide submodules for querying models, managing caches, creating chats, uploading files, and starting live sessions. The SDK also allows for function calling to interact with external systems. Users can find more samples in the GitHub samples directory.

r2ai
r2ai is a tool designed to run a language model locally without internet access. It can be used to entertain users or assist in answering questions related to radare2 or reverse engineering. The tool allows users to prompt the language model, index large codebases, slurp file contents, embed the output of an r2 command, define different system-level assistant roles, set environment variables, and more. It is accessible as an r2lang-python plugin and can be scripted from various languages. Users can use different models, adjust query templates dynamically, load multiple models, and make them communicate with each other.
For similar tasks
nodejs-whisper
Node.js bindings for OpenAI's Whisper model that automatically converts audio to WAV format with a 16000 Hz frequency to support the whisper model. It outputs transcripts to various formats, is optimized for CPU including Apple Silicon ARM, provides timestamp precision to single word, allows splitting on word rather than token, translation from source language to English, and conversion of audio format to WAV for whisper model support.
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.