
fetcher-mcp
MCP server for fetch web page content using Playwright headless browser.
Stars: 94
Fetcher MCP is a server tool designed for fetching web page content using Playwright headless browser. It supports JavaScript execution, intelligent content extraction, flexible output formats, parallel processing, resource optimization, robust error handling, and configurable parameters. The tool provides features like fetching web page content from a specified URL, batch retrieving content from multiple URLs, and offers fine-grained control over various parameters. Fetcher MCP is ideal for users looking to scrape dynamic web content efficiently and reliably.
README:
MCP server for fetch web page content using Playwright headless browser.
-
JavaScript Support: Unlike traditional web scrapers, Fetcher MCP uses Playwright to execute JavaScript, making it capable of handling dynamic web content and modern web applications.
-
Intelligent Content Extraction: Built-in Readability algorithm automatically extracts the main content from web pages, removing ads, navigation, and other non-essential elements.
-
Flexible Output Format: Supports both HTML and Markdown output formats, making it easy to integrate with various downstream applications.
-
Parallel Processing: The
fetch_urlstool enables concurrent fetching of multiple URLs, significantly improving efficiency for batch operations. -
Resource Optimization: Automatically blocks unnecessary resources (images, stylesheets, fonts, media) to reduce bandwidth usage and improve performance.
-
Robust Error Handling: Comprehensive error handling and logging ensure reliable operation even when dealing with problematic web pages.
-
Configurable Parameters: Fine-grained control over timeouts, content extraction, and output formatting to suit different use cases.
Run directly with npx:
npx -y fetcher-mcpRun with the --debug option to show the browser window for debugging:
npx -y fetcher-mcp --debug-
fetch_url- Retrieve web page content from a specified URL- Uses Playwright headless browser to parse JavaScript
- Supports intelligent extraction of main content and conversion to Markdown
- Supports the following parameters:
-
url: The URL of the web page to fetch (required parameter) -
timeout: Page loading timeout in milliseconds, default is 30000 (30 seconds) -
waitUntil: Specifies when navigation is considered complete, options: 'load', 'domcontentloaded', 'networkidle', 'commit', default is 'load' -
extractContent: Whether to intelligently extract the main content, default is true -
maxLength: Maximum length of returned content (in characters), default is no limit -
returnHtml: Whether to return HTML content instead of Markdown, default is false
-
-
fetch_urls- Batch retrieve web page content from multiple URLs in parallel- Uses multi-tab parallel fetching for improved performance
- Returns combined results with clear separation between webpages
- Supports the following parameters:
-
urls: Array of URLs to fetch (required parameter) -
timeout: Page loading timeout in milliseconds, default is 30000 (30 seconds) -
waitUntil: Specifies when navigation is considered complete, options: 'load', 'domcontentloaded', 'networkidle', 'commit', default is 'load' -
extractContent: Whether to intelligently extract the main content, default is true -
maxLength: Maximum length of returned content (in characters), default is no limit -
returnHtml: Whether to return HTML content instead of Markdown, default is false
-
Configure this MCP server in Claude Desktop:
On MacOS: ~/Library/Application Support/Claude/claude_desktop_config.json
On Windows: %APPDATA%/Claude/claude_desktop_config.json
{
"mcpServers": {
"fetch": {
"command": "npx",
"args": ["-y", "fetcher-mcp"]
}
}
}npm installInstall the browsers needed for Playwright:
npm run install-browsernpm run buildUse MCP Inspector for debugging:
npm run inspectorYou can also enable visible browser mode for debugging:
node build/index.js --debugLicensed under the MIT License
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fetcher-mcp
Similar Open Source Tools
fetcher-mcp
Fetcher MCP is a server tool designed for fetching web page content using Playwright headless browser. It supports JavaScript execution, intelligent content extraction, flexible output formats, parallel processing, resource optimization, robust error handling, and configurable parameters. The tool provides features like fetching web page content from a specified URL, batch retrieving content from multiple URLs, and offers fine-grained control over various parameters. Fetcher MCP is ideal for users looking to scrape dynamic web content efficiently and reliably.
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
action_mcp
Action MCP is a powerful tool for managing and automating your cloud infrastructure. It provides a user-friendly interface to easily create, update, and delete resources on popular cloud platforms. With Action MCP, you can streamline your deployment process, reduce manual errors, and improve overall efficiency. The tool supports various cloud providers and offers a wide range of features to meet your infrastructure management needs. Whether you are a developer, system administrator, or DevOps engineer, Action MCP can help you simplify and optimize your cloud operations.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.
model-compose
model-compose is an open-source, declarative workflow orchestrator inspired by docker-compose. It lets you define and run AI model pipelines using simple YAML files. Effortlessly connect external AI services or run local AI models within powerful, composable workflows. Features include declarative design, multi-workflow support, modular components, flexible I/O routing, streaming mode support, and more. It supports running workflows locally or serving them remotely, Docker deployment, environment variable support, and provides a CLI interface for managing AI workflows.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
askrepo
askrepo is a tool that reads the content of Git-managed text files in a specified directory, sends it to the Google Gemini API, and provides answers to questions based on a specified prompt. It acts as a question-answering tool for source code by using a Google AI model to analyze and provide answers based on the provided source code files. The tool leverages modules for file processing, interaction with the Google AI API, and orchestrating the entire process of extracting information from source code files.
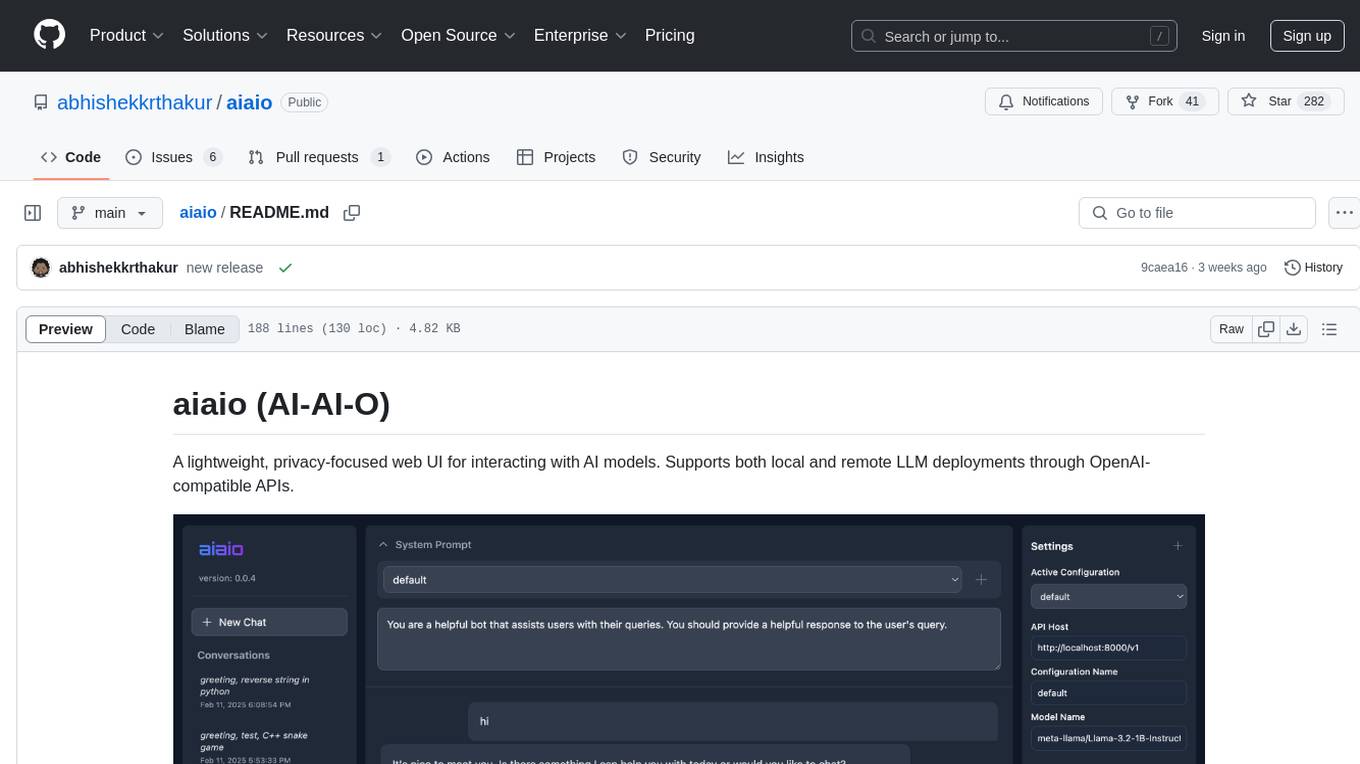
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
any-parser
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.
MCPSharp
MCPSharp is a .NET library that helps build Model Context Protocol (MCP) servers and clients for AI assistants and models. It allows creating MCP-compliant tools, connecting to existing MCP servers, exposing .NET methods as MCP endpoints, and handling MCP protocol details seamlessly. With features like attribute-based API, JSON-RPC support, parameter validation, and type conversion, MCPSharp simplifies the development of AI capabilities in applications through standardized interfaces.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.
mcp-omnisearch
mcp-omnisearch is a Model Context Protocol (MCP) server that acts as a unified gateway to multiple search providers and AI tools. It integrates Tavily, Perplexity, Kagi, Jina AI, Brave, Exa AI, and Firecrawl to offer a wide range of search, AI response, content processing, and enhancement features through a single interface. The server provides powerful search capabilities, AI response generation, content extraction, summarization, web scraping, structured data extraction, and more. It is designed to work flexibly with the API keys available, enabling users to activate only the providers they have keys for and easily add more as needed.
twitter-automation-ai
Advanced Twitter Automation AI is a modular Python-based framework for automating Twitter at scale. It supports multiple accounts, robust Selenium automation with optional undetected Chrome + stealth, per-account proxies and rotation, structured LLM generation/analysis, community posting, and per-account metrics/logs. The tool allows seamless management and automation of multiple Twitter accounts, content scraping, publishing, LLM integration for generating and analyzing tweet content, engagement automation, configurable automation, browser automation using Selenium, modular design for easy extension, comprehensive logging, community posting, stealth mode for reduced fingerprinting, per-account proxies, LLM structured prompts, and per-account JSON summaries and event logs for observability.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
flapi
flAPI is a powerful service that automatically generates read-only APIs for datasets by utilizing SQL templates. Built on top of DuckDB, it offers features like automatic API generation, support for Model Context Protocol (MCP), connecting to multiple data sources, caching, security implementation, and easy deployment. The tool allows users to create APIs without coding and enables the creation of AI tools alongside REST endpoints using SQL templates. It supports unified configuration for REST endpoints and MCP tools/resources, concurrent servers for REST API and MCP server, and automatic tool discovery. The tool also provides DuckLake-backed caching for modern, snapshot-based caching with features like full refresh, incremental sync, retention, compaction, and audit logs.
For similar tasks
fetcher-mcp
Fetcher MCP is a server tool designed for fetching web page content using Playwright headless browser. It supports JavaScript execution, intelligent content extraction, flexible output formats, parallel processing, resource optimization, robust error handling, and configurable parameters. The tool provides features like fetching web page content from a specified URL, batch retrieving content from multiple URLs, and offers fine-grained control over various parameters. Fetcher MCP is ideal for users looking to scrape dynamic web content efficiently and reliably.
For similar jobs

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.