
ai-dj
🎧 AI-powered VST plugin for real-time music generation using LLM contextual prompts and Stable Audio Open
Stars: 117
OBSIDIAN-Neural is a real-time AI music generation VST3 plugin designed for live performance. It allows users to type words and instantly receive musical loops, enhancing creative flow. The plugin features an 8-track sampler with MIDI triggering, 4 pages per track for easy variation switching, perfect DAW sync, real-time generation without pre-recorded samples, and stems separation for isolated drums, bass, and vocals. Users can generate music by typing specific keywords and trigger loops with MIDI while jamming. The tool offers different setups for server + GPU, local models for offline use, and a free API option with no setup required. OBSIDIAN-Neural is actively developed and has received over 110 GitHub stars, with ongoing updates and bug fixes. It is dual licensed under GNU Affero General Public License v3.0 and offers a commercial license option for interested parties.
README:
🎵 Real-time AI music generation VST3 plugin for live performance
📄 Late Breaking Paper - AIMLA 2025 - Presented at the first AES International Conference on Artificial Intelligence and Machine Learning for Audio (Queen Mary University London, Sept 8-10, 2025)
🎓 Tutorial - From DAW setup to live performance (French + English subtitles)
Type words → Get musical loops instantly. No stopping your creative flow.
- 8-track sampler with MIDI triggering (C3-B3)
- 4 pages per track (A/B/C/D) - Switch variations instantly by clicking page buttons
- Perfect DAW sync - Auto time-stretch to project tempo
- Real-time generation - No pre-recorded samples
- Stems separation - Isolated drums, bass, vocals
Example: Type "dark techno kick" → AI generates techno loop → Trigger with MIDI while jamming
Best quality for live performance and production.
- Get Stability AI access
- Follow build from source instructions
- Run server interface:
python server_interface.py - Download VST3 from Releases
- Configure VST with server URL and API key
Benefits: Variable duration, STEMS separation, better timing, GPU acceleration
Runs completely offline. No servers, Python, or GPU needed.
- Get Stability AI access
- Download models from innermost47/stable-audio-open-small-tflite
- Copy to
%APPDATA%\OBSIDIAN-Neural\stable-audio\ - Download VST3 from Releases
- Choose "Local Model" in plugin
Requirements: 16GB+ RAM, Windows (macOS/Linux coming soon)
Contact [email protected] for free API key (10 slots available)
🎯 Share your jams! I'm the only one posting OBSIDIAN videos so far. Show me how YOU use it!
📧 Email: [email protected]
💬 Discussions: GitHub Discussions
📺 Examples: Community Sessions

VST3 Plugin:
Install to:
- Windows:
C:\Program Files\Common Files\VST3\ - macOS:
~/Library/Audio/Plug-Ins/VST3/ - Linux:
~/.vst3/
🚀 Active development - Updates pushed regularly
⭐ 110+ GitHub stars - Thanks for the support!
🐛 Issues: Report bugs here
Current limitations (local mode):
- Fixed 10-second generation
- Some timing/quantization issues
- High RAM usage
- No STEMS separation yet
Server mode still provides better quality for live performance.
Dual licensed:
- 🆓 GNU Affero General Public License v3.0 (Open source)
- 💼 Commercial license available (Contact: [email protected])
🎵 YouTube - Original compositions
🎙️ AI Harmony Radio - 24/7 experimental radio
🎛️ Randomizer - Generative music studio
OBSIDIAN-Neural - Where artificial intelligence meets live music performance.
Developed by InnerMost47
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-dj
Similar Open Source Tools
ai-dj
OBSIDIAN-Neural is a real-time AI music generation VST3 plugin designed for live performance. It allows users to type words and instantly receive musical loops, enhancing creative flow. The plugin features an 8-track sampler with MIDI triggering, 4 pages per track for easy variation switching, perfect DAW sync, real-time generation without pre-recorded samples, and stems separation for isolated drums, bass, and vocals. Users can generate music by typing specific keywords and trigger loops with MIDI while jamming. The tool offers different setups for server + GPU, local models for offline use, and a free API option with no setup required. OBSIDIAN-Neural is actively developed and has received over 110 GitHub stars, with ongoing updates and bug fixes. It is dual licensed under GNU Affero General Public License v3.0 and offers a commercial license option for interested parties.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.

AionUi
AionUi is a user interface library for building modern and responsive web applications. It provides a set of customizable components and styles to create visually appealing user interfaces. With AionUi, developers can easily design and implement interactive web interfaces that are both functional and aesthetically pleasing. The library is built using the latest web technologies and follows best practices for performance and accessibility. Whether you are working on a personal project or a professional application, AionUi can help you streamline the UI development process and deliver a seamless user experience.

sokuji
Sokuji is a desktop application that provides live speech translation using advanced AI models from OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI. It aims to bridge language barriers in live conversations by capturing audio input, processing it through AI models, and delivering real-time translated output. The tool goes beyond basic translation by offering audio routing solutions with virtual device management (Linux only) for seamless integration with other applications. It features a modern interface with real-time audio visualization, comprehensive logging, and support for multiple AI providers and models.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
shots-studio
Shots Studio is a screenshot manager that uses on-device AI to intelligently organize and declutter your gallery. It offers AI-driven search, smart tagging, and custom collections for efficient screenshot management. Users can choose between cloud-powered AI or offline Gemma On-Device AI for privacy and speed. The tool allows users to search by content, automatically generate tags, group related screenshots, and process images without an internet connection. Shots Studio is open source, community-driven, and offers customizable AI options for personalized usage.
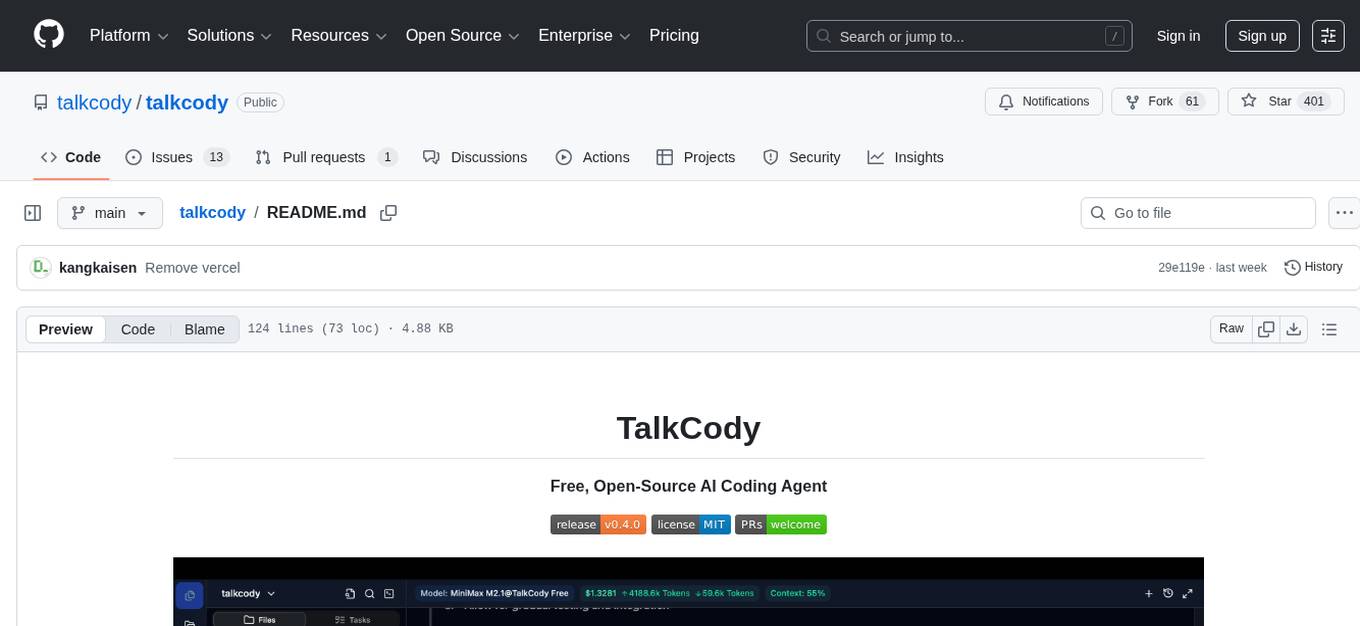
talkcody
TalkCody is a free, open-source AI coding agent designed for developers who value speed, cost, control, and privacy. It offers true freedom to use any AI model without vendor lock-in, maximum speed through unique four-level parallelism, and complete privacy as everything runs locally without leaving the user's machine. With professional-grade features like multimodal input support, MCP server compatibility, and a marketplace for agents and skills, TalkCody aims to enhance development productivity and flexibility.
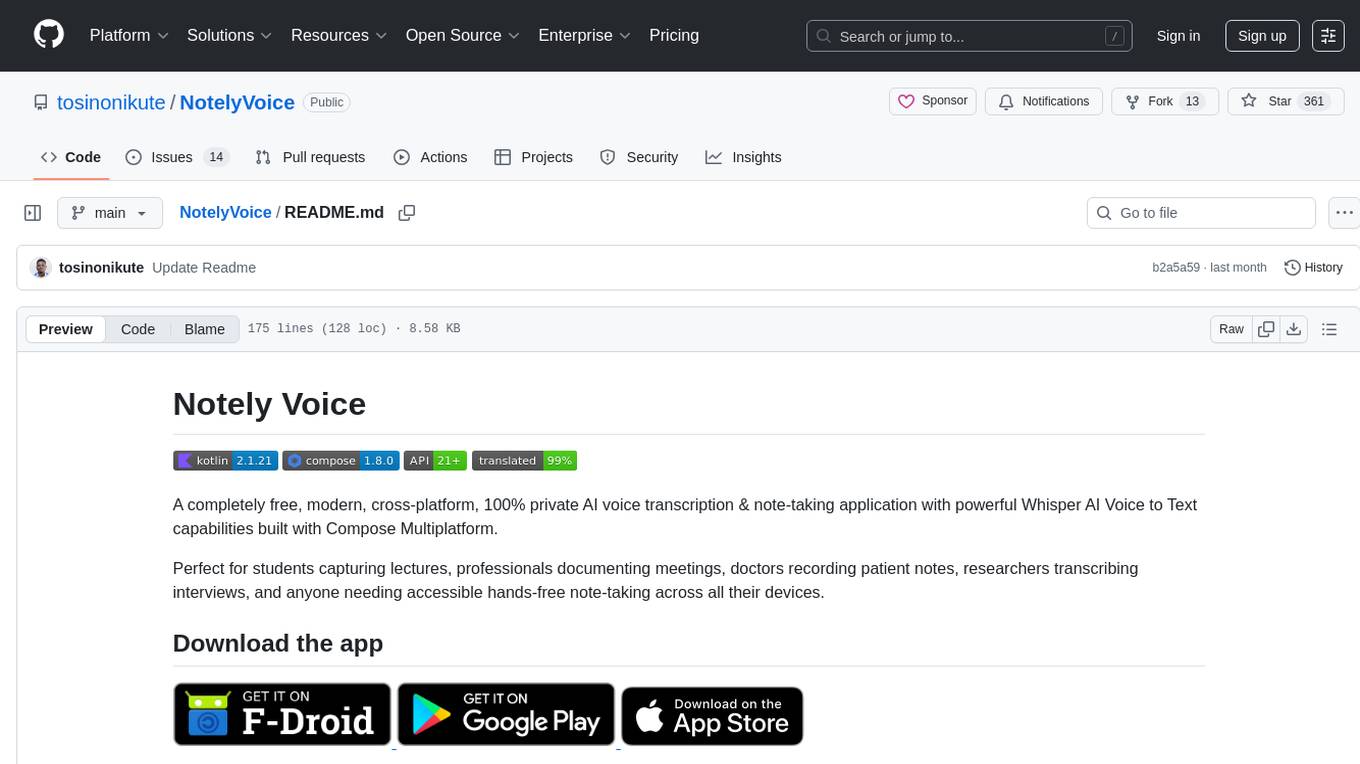
NotelyVoice
Notely Voice is a free, modern, cross-platform AI voice transcription and note-taking application. It offers powerful Whisper AI Voice to Text capabilities, making it ideal for students, professionals, doctors, researchers, and anyone in need of hands-free note-taking. The app features rich text editing, simple search, smart filtering, organization with folders and tags, advanced speech-to-text, offline capability, seamless integration, audio recording, theming, cross-platform support, and sharing functionality. It includes memory-efficient audio processing, chunking configuration, and utilizes OpenAI Whisper for speech recognition technology. Built with Kotlin, Compose Multiplatform, Coroutines, Android Architecture, ViewModel, Koin, Material 3, Whisper AI, and Native Compose Navigation, Notely follows Android Architecture principles with distinct layers for UI, presentation, domain, and data.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
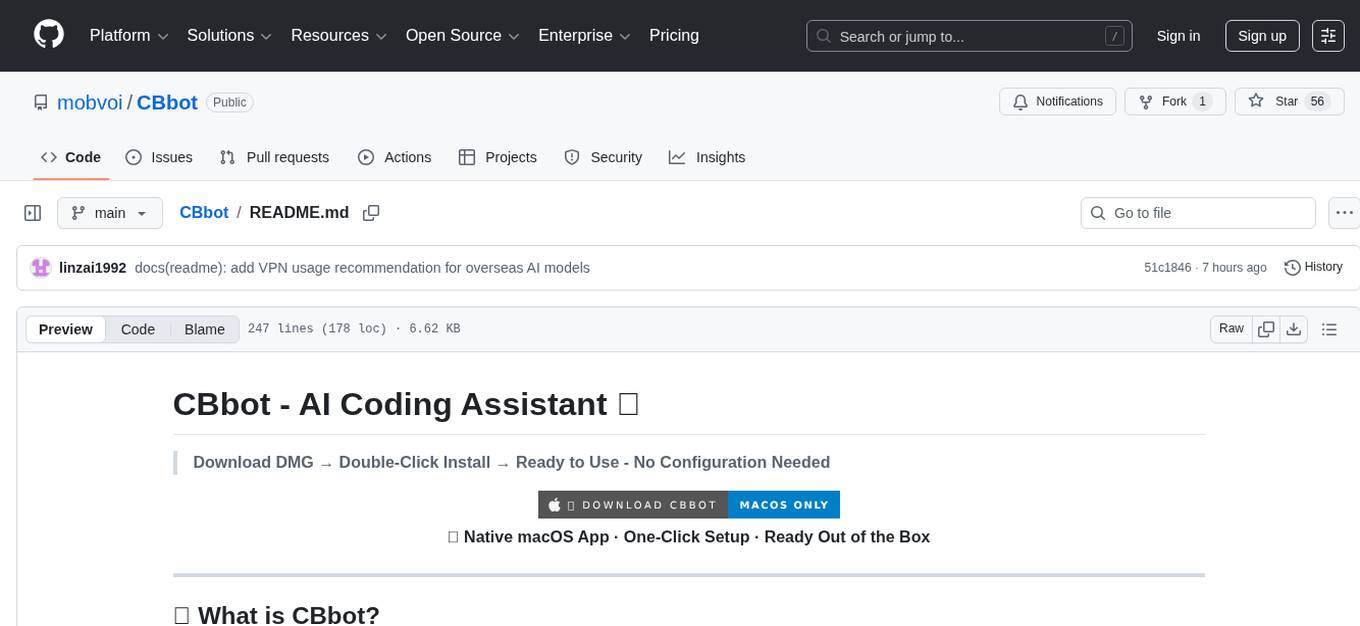
CBbot
CBbot is an AI-powered coding assistant for macOS that helps users write code more efficiently, process documents, and automate tasks. It offers easy installation, built-in AI coding capabilities, auto configuration, and smart tools. Users can download CBbot for macOS 10.15 or higher, with Apple Silicon or Intel chip, and at least 6GB memory and 10GB disk space. The tool requires an internet connection for AI features. CBbot assists users in installing Docker Desktop, binding keys, troubleshooting, and using various skills for document processing and automation tasks. It also provides community support, billing based on usage, and network tips for using overseas AI models.
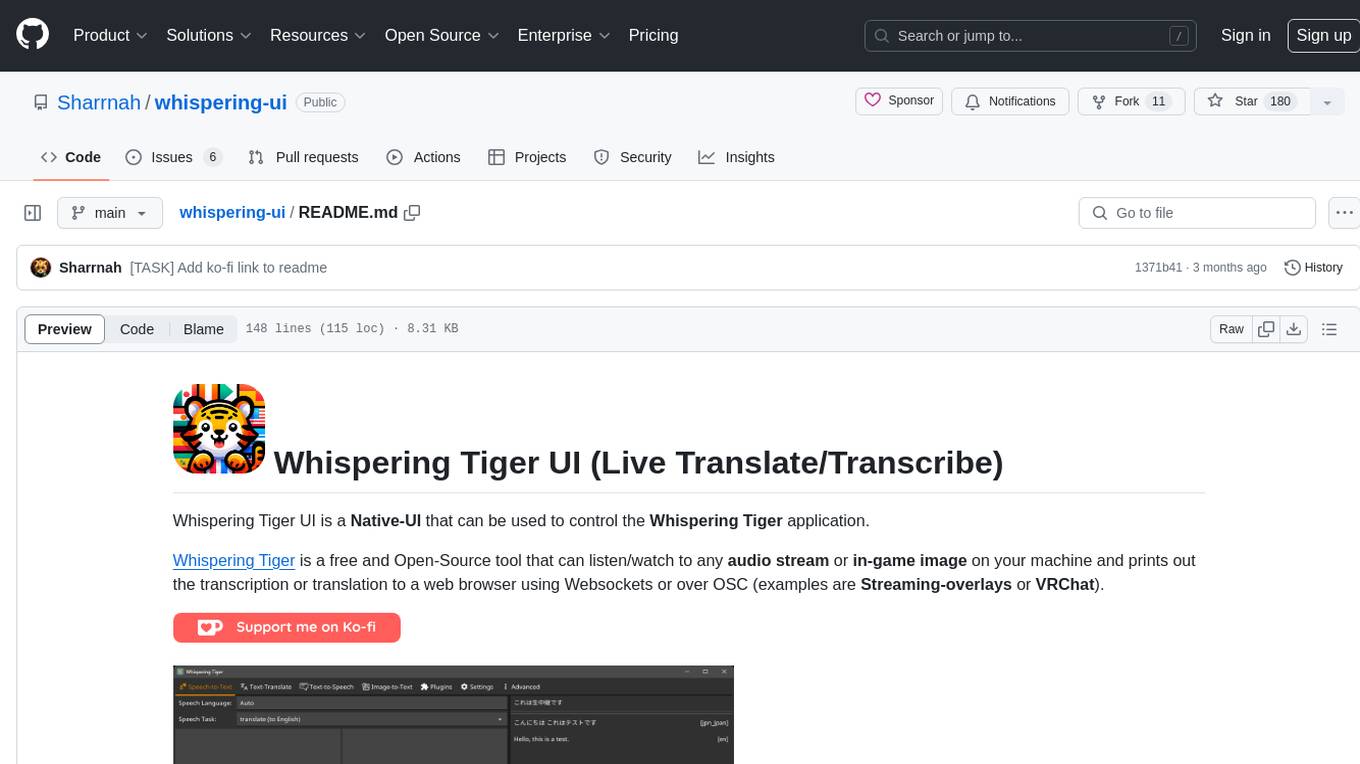
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.
pocketpal-ai
PocketPal AI is a versatile virtual assistant tool designed to streamline daily tasks and enhance productivity. It leverages artificial intelligence technology to provide personalized assistance in managing schedules, organizing information, setting reminders, and more. With its intuitive interface and smart features, PocketPal AI aims to simplify users' lives by automating routine activities and offering proactive suggestions for optimal time management and task prioritization.

natively-cluely-ai-assistant
Natively is a free, open-source, privacy-first AI assistant designed to help users in real time during meetings, interviews, presentations, and conversations. Unlike traditional AI tools that work after the conversation, Natively operates while the conversation is happening. It runs as an invisible, always-on-top desktop overlay, listens when prompted, observes the screen content, and provides instant, context-aware assistance. The tool is fully transparent, customizable, and grants users complete control over local vs cloud AI, data, and credentials.

chipper
Chipper provides a web interface, CLI, and architecture for pipelines, document chunking, web scraping, and query workflows. It is built with Haystack, Ollama, Hugging Face, Docker, Tailwind, and ElasticSearch, running locally or as a Dockerized service. Originally created to assist in creative writing, it now offers features like local Ollama and Hugging Face API, ElasticSearch embeddings, document splitting, web scraping, audio transcription, user-friendly CLI, and Docker deployment. The project aims to be educational, beginner-friendly, and a playground for AI exploration and innovation.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
J.A.R.V.I.S.-Ai-Assistant-V1-
Jarvis Version 3 is a versatile personal assistant application designed to enhance productivity by automating common tasks. It can interact with websites and applications, perform searches, manage device functions, and control music. Users can give commands to open websites, search on Google or YouTube, scroll pages, manage applications, check time, internet speed, battery percentage, battery alerts, charging status, play music, and synchronize clapping with music. The tool offers features for web navigation, search functionality, scrolling, application management, device management, and music control.
For similar tasks
ai-dj
OBSIDIAN-Neural is a real-time AI music generation VST3 plugin designed for live performance. It allows users to type words and instantly receive musical loops, enhancing creative flow. The plugin features an 8-track sampler with MIDI triggering, 4 pages per track for easy variation switching, perfect DAW sync, real-time generation without pre-recorded samples, and stems separation for isolated drums, bass, and vocals. Users can generate music by typing specific keywords and trigger loops with MIDI while jamming. The tool offers different setups for server + GPU, local models for offline use, and a free API option with no setup required. OBSIDIAN-Neural is actively developed and has received over 110 GitHub stars, with ongoing updates and bug fixes. It is dual licensed under GNU Affero General Public License v3.0 and offers a commercial license option for interested parties.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.