
sokuji
Live speech translation application built with Electron 34 and React, using OpenAI's Realtime API.
Stars: 288

Sokuji is a desktop application that provides live speech translation using advanced AI models from OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI. It aims to bridge language barriers in live conversations by capturing audio input, processing it through AI models, and delivering real-time translated output. The tool goes beyond basic translation by offering audio routing solutions with virtual device management (Linux only) for seamless integration with other applications. It features a modern interface with real-time audio visualization, comprehensive logging, and support for multiple AI providers and models.
README:
![]()
Live speech translation powered by OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI
![]()
English | 日本語
Sokuji is a desktop application designed to provide live speech translation using OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI APIs. It bridges language barriers in live conversations by capturing audio input, processing it through advanced AI models, and delivering translated output in real-time.
https://github.com/user-attachments/assets/1eaaa333-a7ce-4412-a295-16b7eb2310de
Prefer not to install a desktop application? Try our browser extension for Chrome, Edge, and other Chromium-based browsers. It offers the same powerful live speech translation features directly in your browser, with special integration for Google Meet and Microsoft Teams.
![]()
![]()

If you want to install the latest version of the browser extension:
- Download the latest
sokuji-extension.zipfrom the releases page - Extract the zip file to a folder
- Open Chrome/Chromium and go to
chrome://extensions/ - Enable "Developer mode" in the top right corner
- Click "Load unpacked" and select the extracted folder
- The Sokuji extension will be installed and ready to use
Sokuji goes beyond basic translation by offering a complete audio routing solution with virtual device management (Linux only), allowing for seamless integration with other applications. It provides a modern, intuitive interface with real-time audio visualization and comprehensive logging.
- Real-time speech translation using OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI APIs
-
Simple Mode Interface: Streamlined 6-section configuration for non-technical users:
- Interface language selection
- Translation language pairs (source/target)
- API key management with validation
- Microphone selection with "Off" option
- Speaker selection with "Off" option
- Real-time session duration display
- Multi-Provider Support: Seamlessly switch between OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI.
-
Supported Models:
-
OpenAI:
gpt-4o-realtime-preview,gpt-4o-mini-realtime-preview -
Google Gemini:
gemini-2.0-flash-live-001,gemini-2.5-flash-preview-native-audio-dialog - CometAPI: OpenAI-compatible models with custom endpoints
- Palabra.ai: Real-time speech-to-speech translation via WebRTC
- Kizuna AI: OpenAI-compatible models with backend-managed authentication
-
OpenAI:
- Automatic turn detection with multiple modes (Normal, Semantic, Disabled) for OpenAI
- Audio visualization with waveform display
-
Advanced Virtual Microphone (Linux only) with dual-queue audio mixing system:
- Regular audio tracks: Queued and played sequentially
- Immediate audio tracks: Separate queue for real-time audio mixing
- Simultaneous playback: Mix both track types for enhanced audio experience
- Chunked audio support: Efficient handling of large audio streams
- Real-time Voice Passthrough: Live audio monitoring during recording sessions
- Virtual audio device creation and management on Linux (using PulseAudio/PipeWire)
- Automatic audio routing between virtual devices (Linux only)
- Automatic device switching and configuration persistence
- Audio input and output device selection
- Comprehensive logs for tracking API interactions
- Customizable model settings (temperature, max tokens)
-
User transcript model selection (for OpenAI:
gpt-4o-mini-transcribe,gpt-4o-transcribe,whisper-1) - Noise reduction options (for OpenAI: None, Near field, Far field)
- API key validation with real-time feedback
- Configuration persistence in user's home directory
- Optimized AI Client Performance: Enhanced conversation management with consistent ID generation
- Enhanced Tooltips: Interactive help tooltips powered by @floating-ui for better user guidance
- Multi-language Support: Complete internationalization with 35+ languages and English fallback
Sokuji uses a modern audio processing pipeline built on Web Audio API, with additional virtual device capabilities on Linux:
- ModernAudioRecorder: Captures input with advanced echo cancellation
- ModernAudioPlayer: Handles playback with queue-based audio management
- Real-time Processing: Low-latency audio streaming with chunked playback
- Virtual Device Support: On Linux, creates virtual audio devices for application integration
The audio flow in Sokuji:
- Input Capture: Microphone audio is captured with echo cancellation enabled
- AI Processing: Audio is sent to the selected AI provider for translation
- Playback: Translated audio is played through the selected monitor device
- Virtual Device Output (Linux only): Audio is also routed to virtual microphone for other applications
- Optional Passthrough: Original voice can be monitored in real-time
This architecture provides:
- Better echo cancellation using modern browser APIs
- Lower latency through optimized audio pipelines
- Virtual device integration on Linux for seamless app-to-app audio routing
- Cross-platform compatibility with graceful degradation
Modern Audio Service Architecture:
-
ModernAudioRecorder: Web Audio API-based recording with echo cancellation -
ModernAudioPlayer: Queue-based playback with event-driven processing - Unified audio service for both Electron and browser extension platforms
Optimized Client Management:
-
GeminiClient: Improved conversation item management with consistent instance IDs - Reduced method calls and improved performance
- Better memory management for long-running sessions
Audio Processing Implementation:
- Queue-based audio chunk management for smooth playback
- Real-time passthrough with configurable volume control
- Event-driven playback to reduce CPU usage
- Automatic device switching and reconnection
- (required) An OpenAI, Google Gemini, CometAPI, or Palabra.ai API key, OR a Kizuna AI account. For Palabra.ai, you will need a Client ID and Client Secret. For CometAPI, you'll need to configure the custom endpoint URL. For Kizuna AI, sign in to your account to automatically access backend-managed API keys.
- (optional) Linux with PulseAudio or PipeWire for virtual audio device features (desktop app only)
- Node.js (latest LTS version recommended)
- npm
- Audio support works on all platforms (Windows, macOS, Linux)
- Virtual audio devices require Linux with PulseAudio or PipeWire
-
Clone the repository
git clone https://github.com/kizuna-ai-lab/sokuji.git cd sokuji -
Install dependencies
npm install
-
Launch the application in development mode
npm run electron:dev
-
Build the application for production
npm run electron:build
Download the latest Debian package from the releases page and install it:
sudo dpkg -i sokuji_*.deb-
Setup your API key:

- Click the Settings button in the top-right corner
- Select your desired provider (OpenAI, Gemini, CometAPI, Palabra, or Kizuna AI).
- For user-managed providers: Enter your API key and click "Validate". For Palabra, you will need to enter a Client ID and Client Secret. For CometAPI, configure both the API key and custom endpoint URL.
- For Kizuna AI: Sign in to your account to automatically access backend-managed API keys.
- Click "Save" to store your configuration securely.
-
Configure audio devices:

- Click the Audio button to open the Audio panel
- Select your input device (microphone)
- Select your output device (speakers/headphones)
-
Start a session:
- Click "Start Session" to begin
- Speak into your microphone
- View real-time transcription and translation
-
Monitor and control audio:
- Toggle monitor device to hear translated output
- Enable real voice passthrough for live monitoring
- Adjust passthrough volume as needed
-
Use with other applications (Linux only):
- Select "Sokuji_Virtual_Mic" as the microphone input in your target application
- Translated audio will be sent to that application with advanced mixing support
Redesigned user interface for improved accessibility:
- Streamlined Configuration: 6-section unified layout replacing complex tabbed interface
- Enhanced Tooltips: Interactive help using @floating-ui library for better user guidance
- Session Duration Display: Real-time tracking of conversation length
- Unified Styling: Consistent UI design with improved visual hierarchy
- Multi-language Support: Complete i18n with 35+ languages and English fallback
The audio system now features improved echo cancellation and processing:
- Echo Cancellation: Advanced echo suppression using modern Web Audio APIs
- Queue-Based Playback: Smooth audio streaming with intelligent buffering
- Real-time Passthrough: Monitor your voice with adjustable volume control
- Event-Driven Architecture: Reduced CPU usage through efficient event handling
- Cross-Platform Support: Unified audio handling across all platforms
Enhanced Google Gemini client performance:
- Consistent ID Generation: Optimized conversation item management with fixed instance IDs
- Improved Memory Usage: Reduced redundant ID generation calls
- Better Performance: Streamlined conversation handling for faster response times
Live audio monitoring capabilities:
- Real-time Feedback: Hear your voice while recording for better user experience
- Volume Control: Adjustable passthrough volume for optimal monitoring
- Low Latency: Immediate audio feedback using optimized audio processing
Sokuji features a simplified architecture focused on core functionality:
- Simplified User System: Only users and usage_logs tables
- Real-time Usage Tracking: Relay server directly writes usage data to database
- Clerk Authentication: Handles all user authentication and session management
- Streamlined API: Only essential endpoints maintained (/quota, /check, /reset)
- Service Factory Pattern: Platform-specific implementations (Electron/Browser Extension)
- Modern Audio Processing: AudioWorklet with ScriptProcessor fallback
- Unified Components: SimpleConfigPanel and SimpleMainPanel for streamlined UX
- Context-Based State: React Context API without external state management
-- Core user table
users (id, clerk_id, email, subscription, token_quota)
-- Simplified usage tracking (written by relay)
usage_logs (id, user_id, session_id, model, total_tokens, input_tokens, output_tokens, created_at)- Runtime: Electron 34+ / Chrome Extension Manifest V3
- Frontend: React 18 + TypeScript
- Backend: Cloudflare Workers + Hono + D1 Database
- Authentication: Clerk
- AI Providers: OpenAI, Google Gemini, CometAPI, Palabra.ai, Kizuna AI
-
Advanced Audio Processing:
- Web Audio API for real-time audio processing
- MediaRecorder API for reliable audio capture
- ScriptProcessor for real-time audio analysis
- Queue-based playback system for smooth streaming
-
UI Libraries:
- @floating-ui/react for advanced tooltip positioning
- SASS for styling
- Lucide React for icons
-
Internationalization:
- i18next for multi-language support
- 35+ language translations
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sokuji
Similar Open Source Tools
sokuji
Sokuji is a desktop application that provides live speech translation using advanced AI models from OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI. It aims to bridge language barriers in live conversations by capturing audio input, processing it through AI models, and delivering real-time translated output. The tool goes beyond basic translation by offering audio routing solutions with virtual device management (Linux only) for seamless integration with other applications. It features a modern interface with real-time audio visualization, comprehensive logging, and support for multiple AI providers and models.
NotelyVoice
Notely Voice is a free, modern, cross-platform AI voice transcription and note-taking application. It offers powerful Whisper AI Voice to Text capabilities, making it ideal for students, professionals, doctors, researchers, and anyone in need of hands-free note-taking. The app features rich text editing, simple search, smart filtering, organization with folders and tags, advanced speech-to-text, offline capability, seamless integration, audio recording, theming, cross-platform support, and sharing functionality. It includes memory-efficient audio processing, chunking configuration, and utilizes OpenAI Whisper for speech recognition technology. Built with Kotlin, Compose Multiplatform, Coroutines, Android Architecture, ViewModel, Koin, Material 3, Whisper AI, and Native Compose Navigation, Notely follows Android Architecture principles with distinct layers for UI, presentation, domain, and data.

mcp-pointer
MCP Pointer is a local tool that combines an MCP Server with a Chrome Extension to allow users to visually select DOM elements in the browser and make textual context available to agentic coding tools like Claude Code. It bridges between the browser and AI tools via the Model Context Protocol, enabling real-time communication and compatibility with various AI tools. The tool extracts detailed information about selected elements, including text content, CSS properties, React component detection, and more, making it a valuable asset for developers working with AI-powered web development.
ai-dj
OBSIDIAN-Neural is a real-time AI music generation VST3 plugin designed for live performance. It allows users to type words and instantly receive musical loops, enhancing creative flow. The plugin features an 8-track sampler with MIDI triggering, 4 pages per track for easy variation switching, perfect DAW sync, real-time generation without pre-recorded samples, and stems separation for isolated drums, bass, and vocals. Users can generate music by typing specific keywords and trigger loops with MIDI while jamming. The tool offers different setups for server + GPU, local models for offline use, and a free API option with no setup required. OBSIDIAN-Neural is actively developed and has received over 110 GitHub stars, with ongoing updates and bug fixes. It is dual licensed under GNU Affero General Public License v3.0 and offers a commercial license option for interested parties.
PageTalk
PageTalk is a browser extension that enhances web browsing by integrating Google's Gemini API. It allows users to select text on any webpage for AI analysis, translation, contextual chat, and customization. The tool supports multi-agent system, image input, rich content rendering, PDF parsing, URL context extraction, personalized settings, chat export, text selection helper, and proxy support. Users can interact with web pages, chat contextually, manage AI agents, and perform various tasks seamlessly.
ComfyUI-fal-API
ComfyUI-fal-API is a repository containing custom nodes for using Flux models with fal API in ComfyUI. It provides nodes for image generation, video generation, language models, and vision language models. Users can easily install and configure the repository to access various nodes for different tasks such as generating images, creating videos, processing text, and understanding images. The repository also includes troubleshooting steps and is licensed under the Apache License 2.0.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
DeepSeekAI
DeepSeekAI is a browser extension plugin that allows users to interact with AI by selecting text on web pages and invoking the DeepSeek large model to provide AI responses. The extension enhances browsing experience by enabling users to get summaries or answers for selected text directly on the webpage. It features context text selection, API key integration, draggable and resizable window, AI streaming replies, Markdown rendering, one-click copy, re-answer option, code copy functionality, language switching, and multi-turn dialogue support. Users can install the extension from Chrome Web Store or Edge Add-ons, or manually clone the repository, install dependencies, and build the extension. Configuration involves entering the DeepSeek API key in the extension popup window to start using the AI-driven responses.
ComfyUI-Copilot
ComfyUI-Copilot is an intelligent assistant built on the Comfy-UI framework that simplifies and enhances the AI algorithm debugging and deployment process through natural language interactions. It offers intuitive node recommendations, workflow building aids, and model querying services to streamline development processes. With features like interactive Q&A bot, natural language node suggestions, smart workflow assistance, and model querying, ComfyUI-Copilot aims to lower the barriers to entry for beginners, boost development efficiency with AI-driven suggestions, and provide real-time assistance for developers.

chunkhound
ChunkHound is a tool that transforms your codebase into a searchable knowledge base for AI assistants using semantic and regex search. It integrates with AI assistants via the Model Context Protocol (MCP) and offers features such as cAST algorithm for semantic code chunking, multi-hop semantic search, natural language queries, regex search without API keys, support for 22 languages, and local-first architecture. It provides intelligent code discovery by following semantic relationships and discovering related implementations. ChunkHound is built on the cAST algorithm from Carnegie Mellon University, ensuring structure-aware chunking that preserves code meaning. It supports universal language parsing and offers efficient updates for large codebases.

chunkhound
ChunkHound is a modern tool for transforming your codebase into a searchable knowledge base for AI assistants. It utilizes semantic search via the cAST algorithm and regex search, integrating with AI assistants through the Model Context Protocol (MCP). With features like cAST Algorithm, Multi-Hop Semantic Search, Regex search, and support for 22 languages, ChunkHound offers a local-first approach to code analysis and discovery. It provides intelligent code discovery, universal language support, and real-time indexing capabilities, making it a powerful tool for developers looking to enhance their coding experience.
llmchat
LLMChat is an all-in-one AI chat interface that supports multiple language models, offers a plugin library for enhanced functionality, enables web search capabilities, allows customization of AI assistants, provides text-to-speech conversion, ensures secure local data storage, and facilitates data import/export. It also includes features like knowledge spaces, prompt library, personalization, and can be installed as a Progressive Web App (PWA). The tech stack includes Next.js, TypeScript, Pglite, LangChain, Zustand, React Query, Supabase, Tailwind CSS, Framer Motion, Shadcn, and Tiptap. The roadmap includes upcoming features like speech-to-text and knowledge spaces.
aigne-hub
AIGNE Hub is a unified AI gateway that manages connections to multiple LLM and AIGC providers, eliminating the complexity of handling API keys, usage tracking, and billing across different AI services. It provides self-hosting capabilities, multi-provider management, unified security, usage analytics, flexible billing, and seamless integration with the AIGNE framework. The tool supports various AI providers and deployment scenarios, catering to both enterprise self-hosting and service provider modes. Users can easily deploy and configure AI providers, enable billing, and utilize core capabilities such as chat completions, image generation, embeddings, and RESTful APIs. AIGNE Hub ensures secure access, encrypted API key management, user permissions, and audit logging. Built with modern technologies like AIGNE Framework, Node.js, TypeScript, React, SQLite, and Blocklet for cloud-native deployment.

OpenChat
OS Chat is a free, open-source AI personal assistant that combines 40+ language models with powerful automation capabilities. It allows users to deploy background agents, connect services like Gmail, Calendar, Notion, GitHub, and Slack, and get things done through natural conversation. With features like smart automation, service connectors, AI models, chat management, interface customization, and premium features, OS Chat offers a comprehensive solution for managing digital life and workflows. It prioritizes privacy by being open source and self-hostable, with encrypted API key storage.
astrsk
astrsk is a tool that pushes the boundaries of AI storytelling by offering advanced AI agents, customizable response formatting, and flexible prompt editing for immersive roleplaying experiences. It provides complete AI agent control, a visual flow editor for conversation flows, and ensures 100% local-first data storage. The tool is true cross-platform with support for various AI providers and modern technologies like React, TypeScript, and Tailwind CSS. Coming soon features include cross-device sync, enhanced session customization, and community features.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.
For similar tasks
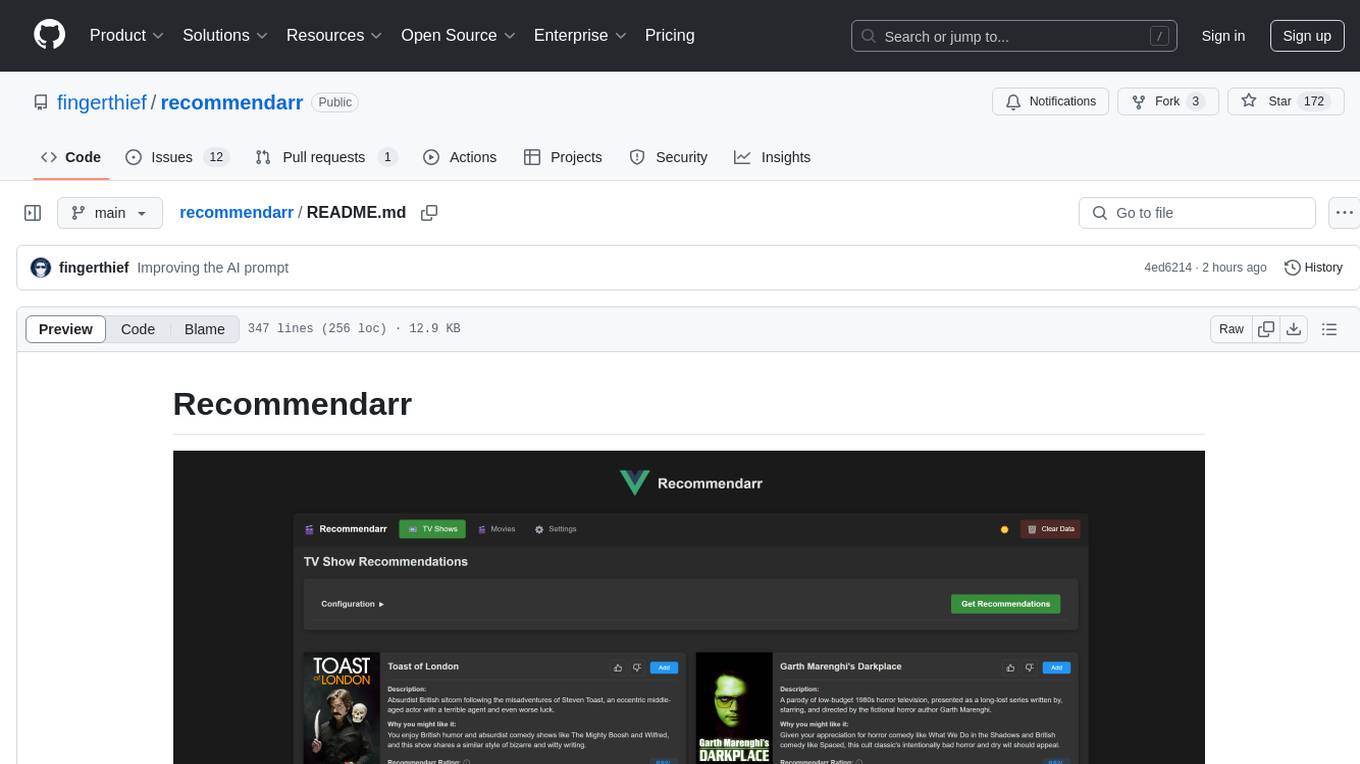
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
sokuji
Sokuji is a desktop application that provides live speech translation using advanced AI models from OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI. It aims to bridge language barriers in live conversations by capturing audio input, processing it through AI models, and delivering real-time translated output. The tool goes beyond basic translation by offering audio routing solutions with virtual device management (Linux only) for seamless integration with other applications. It features a modern interface with real-time audio visualization, comprehensive logging, and support for multiple AI providers and models.
RTranslator
RTranslator is an almost open-source, free, and offline real-time translation app for Android. It offers Conversation mode for multi-user translations, WalkieTalkie mode for quick conversations, and Text translation mode. It uses Meta's NLLB for translation and OpenAi's Whisper for speech recognition, ensuring privacy. The app is optimized for performance and supports multiple languages. It is ad-free and donation-supported.
ten_framework
TEN Framework, short for Transformative Extensions Network, is the world's first real-time multimodal AI agent framework. It offers native support for high-performance, real-time multimodal interactions, supports multiple languages and platforms, enables edge-cloud integration, provides flexibility beyond model limitations, and allows for real-time agent state management. The framework facilitates the development of complex AI applications that transcend the limitations of large models by offering a drag-and-drop programming approach. It is suitable for scenarios like simultaneous interpretation, speech-to-text conversion, multilingual chat rooms, audio interaction, and audio-visual interaction.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.