
VisioFirm
VisioFirm: Cross-Platform AI-assisted Annotation Tool for Computer Vision
Stars: 298
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
README:
![]()


[!IMPORTANT] VisioFirm v1 is now available. VisioFirm has now much more support for computer vision annotation, pushing further the boundaries of efficient, fast, and accurate annotation. Here's what’s New in v1.0.1 ✨
- Classification and Preannotation: Predict and pre-suggest image classes using OpenAI CLIP pretrained model, enabling near-automatic labeling.
- Video Support & Label Propagation: New VFTracker auto-labeling with frame-to-frame propagation: choose between: (1) SmartPropagator – Leverages SAM2 + pre/post processing for accurate, cumulative tracking. Annotate the first frame, propagate across the sequence. (2) OpenCV Trackers – Full support (CSRT, KCF, Boosting, MIL, TLD, MedianFlow, MOSSE, GOTURN) and (3) Interpolation – Classic propagation between
[labeled_start]and[labeled_end].- Ultralytics Model Support: Works with YOLOv12 → YOLOv5, including YOLOv8-world for open-vocab pre-annotation.
- Cross-domain annotation: use detection models to pre-generate segmentation masks, or segmentation models to pre-label bounding boxes.
- Memory Management Improvements: Optimized GPU usage with better model load/unload behavior for large-scale pre-annotation and tracking.
- Backend Migration to FastAPI: Faster performance, async support, and smoother UI interactions.
- Python API: Integrate VisioFirm seamlessly into pipelines with the new
visiofirmPython API.
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with a intuitive web interface and powerful backend.
Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
VisioFirm is majoraly focused on AI-model integration easiness for fast CV tasks annotation.
- AI-Driven Pre-Annotation: Automatically detect and segment objects using YOLO, SAM2, and Grounding DINO—saving up to 80% of manual effort.
- Multi-Task Support: Handles classification, bounding boxes, oriented bounding boxes, and polygon segmentation and now even videos in one tool.
- Browser-Based Editing: Interactive canvas for precise adjustments, with real-time SAM-powered segmentation in the browser.
- Offline-Friendly: Models download automatically (or pre-fetch for offline use), with SQLite backend for local projects.
- Extensible & Open-Source: Customize with your own ultralytics models or integrate into pipelines—contributions welcome!
- SAM2-base webgpu: Insta-drawing of annotations via SAM2 with worker offloading and auto-annotation for faster computing!

-
Semi-Automated Labeling Kickstart annotations with AI models like YOLO (v5–v12) for detection, SAM2 for segmentation, Grounding DINO for zero-shot object grounding, and CLIP for automated classification.
-
Flexible Annotation Types
- Axis-aligned bounding boxes for standard detection.
- Oriented bounding boxes for rotated objects (e.g., aerial imagery).
- Polygon segmentation for precise boundaries.
- Image classification with automatic label suggestions.
-
Video Annotation & Label Propagation Annotate videos with frame-to-frame consistency:
- SmartPropagator (SAM2-powered accurate propagation).
- OpenCV trackers (CSRT, KCF, Boosting, MIL, TLD, MedianFlow, MOSSE, GOTURN).
- Interpolation between annotated start/end frames.
-
Cross-Domain Annotation
- Use detection models to auto-generate segmentation masks.
- Use segmentation models to pre-label bounding boxes.
-
Ultralytics Model Support Full support for YOLOv12, v11, v10, v9, v8, v5, plus YOLOv8-world for open-vocab pre-annotations (no GPU required).
-
Interactive Frontend Draw, edit, and refine labels on a responsive canvas.
- Click-to-segment with browser-based SAM2.
- Hotkeys, undo/redo, and zoom for efficient annotation.
-
Project Management Organize datasets with SQLite-backed projects.
- Multi-class support.
- Import/export with minimal setup.
-
Export Formats Export annotations to YOLO, COCO, or custom formats for seamless training.
-
Performance Optimizations
- GPU memory management for efficient model loading/unloading.
- Cluster overlapping detections, simplify contours, and filter by confidence.
- Multi-threaded uploading and optimized image import.
-
Cloud/SSH Integration Download images from cloud storage or SSH servers, save annotations remotely, and manage large-scale projects.
-
Backend Migration to FastAPI Faster response times, async support, and smoother UI performance.
-
VisioFirm Python API Integrate annotation workflows into custom scripts and ML pipelines.
Detection based on pre-trained/zeroshot models:

Video Segmentation using Smart Propagator:
VisioFirm was tested with Python 3.10+.
[!NOTE] VisioFirm v1 introduces a new database management logic.
To avoid conflicts with older versions, you need to rename/remove the old cache folder before running the new release:
- Linux:
~/.cache/visiofirm_cache- macOS:
~/Library/Caches/visiofirm_cache- Windows:
%LOCALAPPDATA%\visiofirm_cacheAfter deleting the folder, restart VisioFirm — it will automatically recreate the cache directory with the new structure.
pip install -U visiofirmFor development or editable install (from a cloned repo):
git clone https://github.com/OschAI/VisioFirm.git
cd VisioFirm
pip install -e .Launch VisioFirm with a single command—it auto-starts a local web server and opens in your browser.
visiofirm- Create a new project and upload images.
- Define classes (e.g., "car", "person").
- For easy-to-detect object run AI pre-annotation (select model: YOLO, Grounding DINO).
- Refine labels in the interactive editor.
- Export your annotated dataset.
The VisioFirm app uses cache directories to store settings locally.
VisioFirm uses advanced models for initial labels:
- YOLO: All ultralytics based YOLO model are now compatible and can be used.
- SAM2: Precise segmentation use in image annotation and video propagation
- Grounding DINO: Zero-shot detection via text prompts.
- Issues: Report bugs or request features here.
- Discord: Coming soon—star the repo for updates!
- Roadmap: Multi-user support, custom model integration.
Apache 2.0 - See LICENSE for details.
This project uses third-party software and models:
-
Ultralytics YOLO
https://github.com/ultralytics/ultralytics
License: AGPL-3.0 -
SAM2 (Segment Anything Model v2)
https://github.com/facebookresearch/sam2
Licenses: Apache 2.0 and BSD 3-Clause -
GroundingDINO
https://github.com/IDEA-Research/GroundingDINO
License: Apache 2.0
Built by Safouane El Ghazouali for the research community. Star the repo if it helps your workflow! 🚀
@misc{ghazouali2025visiofirm,
title={VisioFirm: Cross-Platform AI-assisted Annotation Tool for Computer Vision},
author={Safouane El Ghazouali and Umberto Michelucci},
year={2025},
eprint={2509.04180},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
SOON:
- Documentation website
- Discord community
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VisioFirm
Similar Open Source Tools
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
llmchat
LLMChat is an all-in-one AI chat interface that supports multiple language models, offers a plugin library for enhanced functionality, enables web search capabilities, allows customization of AI assistants, provides text-to-speech conversion, ensures secure local data storage, and facilitates data import/export. It also includes features like knowledge spaces, prompt library, personalization, and can be installed as a Progressive Web App (PWA). The tech stack includes Next.js, TypeScript, Pglite, LangChain, Zustand, React Query, Supabase, Tailwind CSS, Framer Motion, Shadcn, and Tiptap. The roadmap includes upcoming features like speech-to-text and knowledge spaces.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.

AionUi
AionUi is a user interface library for building modern and responsive web applications. It provides a set of customizable components and styles to create visually appealing user interfaces. With AionUi, developers can easily design and implement interactive web interfaces that are both functional and aesthetically pleasing. The library is built using the latest web technologies and follows best practices for performance and accessibility. Whether you are working on a personal project or a professional application, AionUi can help you streamline the UI development process and deliver a seamless user experience.
ComfyUI-Copilot
ComfyUI-Copilot is an intelligent assistant built on the Comfy-UI framework that simplifies and enhances the AI algorithm debugging and deployment process through natural language interactions. It offers intuitive node recommendations, workflow building aids, and model querying services to streamline development processes. With features like interactive Q&A bot, natural language node suggestions, smart workflow assistance, and model querying, ComfyUI-Copilot aims to lower the barriers to entry for beginners, boost development efficiency with AI-driven suggestions, and provide real-time assistance for developers.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.
kitchenai
KitchenAI is an open-source toolkit designed to simplify AI development by serving as an AI backend and LLMOps solution. It aims to empower developers to focus on delivering results without being bogged down by AI infrastructure complexities. With features like simplifying AI integration, providing an AI backend, and empowering developers, KitchenAI streamlines the process of turning AI experiments into production-ready APIs. It offers built-in LLMOps features, is framework-agnostic and extensible, and enables faster time-to-production. KitchenAI is suitable for application developers, AI developers & data scientists, and platform & infra engineers, allowing them to seamlessly integrate AI into apps, deploy custom AI techniques, and optimize AI services with a modular framework. The toolkit eliminates the need to build APIs and infrastructure from scratch, making it easier to deploy AI code as production-ready APIs in minutes. KitchenAI also provides observability, tracing, and evaluation tools, and offers a Docker-first deployment approach for scalability and confidence.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.
Zettelgarden
Zettelgarden is a human-centric, open-source personal knowledge management system that helps users develop and maintain their understanding of the world. It focuses on creating and connecting atomic notes, thoughtful AI integration, and scalability from personal notes to company knowledge bases. The project is actively evolving, with features subject to change based on community feedback and development priorities.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
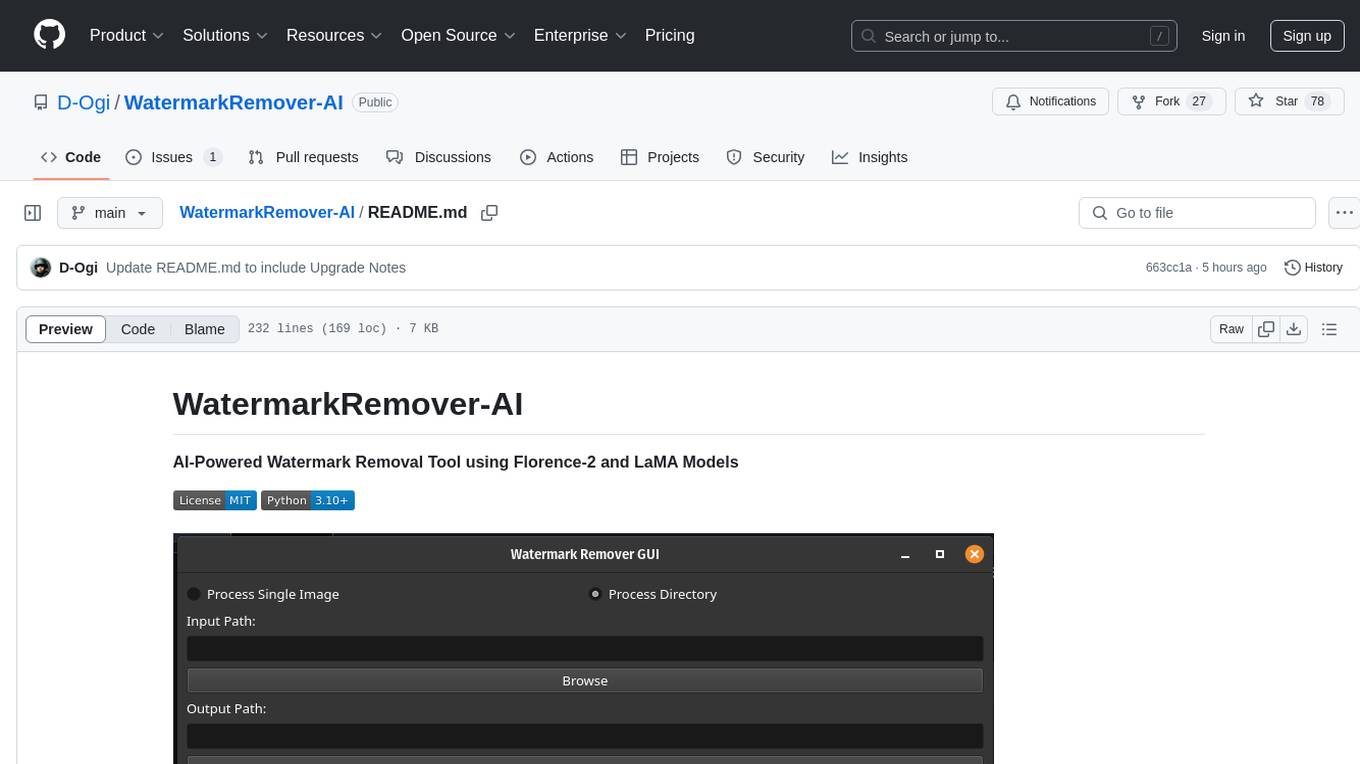
WatermarkRemover-AI
WatermarkRemover-AI is an advanced application that utilizes AI models for precise watermark detection and seamless removal. It leverages Florence-2 for watermark identification and LaMA for inpainting. The tool offers both a command-line interface (CLI) and a PyQt6-based graphical user interface (GUI), making it accessible to users of all levels. It supports dual modes for processing images, advanced watermark detection, seamless inpainting, customizable output settings, real-time progress tracking, dark mode support, and efficient GPU acceleration using CUDA.

chipper
Chipper provides a web interface, CLI, and architecture for pipelines, document chunking, web scraping, and query workflows. It is built with Haystack, Ollama, Hugging Face, Docker, Tailwind, and ElasticSearch, running locally or as a Dockerized service. Originally created to assist in creative writing, it now offers features like local Ollama and Hugging Face API, ElasticSearch embeddings, document splitting, web scraping, audio transcription, user-friendly CLI, and Docker deployment. The project aims to be educational, beginner-friendly, and a playground for AI exploration and innovation.
For similar tasks

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
file-organizer-2000
AI File Organizer 2000 is an Obsidian Plugin that uses AI to transcribe audio, annotate images, and automatically organize files by moving them to the most likely folders. It supports text, audio, and images, with upcoming local-first LLM support. Users can simply place unorganized files into the 'Inbox' folder for automatic organization. The tool renames and moves files quickly, providing a seamless file organization experience. Self-hosting is also possible by running the server and enabling the 'Self-hosted' option in the plugin settings. Join the community Discord server for more information and use the provided iOS shortcut for easy access on mobile devices.
LabelLLM
LabelLLM is an open-source data annotation platform designed to optimize the data annotation process for LLM development. It offers flexible configuration, multimodal data support, comprehensive task management, and AI-assisted annotation. Users can access a suite of annotation tools, enjoy a user-friendly experience, and enhance efficiency. The platform allows real-time monitoring of annotation progress and quality control, ensuring data integrity and timeliness.
awesome-open-data-annotation
At ZenML, we believe in the importance of annotation and labeling workflows in the machine learning lifecycle. This repository showcases a curated list of open-source data annotation and labeling tools that are actively maintained and fit for purpose. The tools cover various domains such as multi-modal, text, images, audio, video, time series, and other data types. Users can contribute to the list and discover tools for tasks like named entity recognition, data annotation for machine learning, image and video annotation, text classification, sequence labeling, object detection, and more. The repository aims to help users enhance their data-centric workflows by leveraging these tools.
anylabeling
AnyLabeling is a tool for effortless data labeling with AI support from YOLO and Segment Anything. It combines features from LabelImg and Labelme with an improved UI and auto-labeling capabilities. Users can annotate images with polygons, rectangles, circles, lines, and points, as well as perform auto-labeling using YOLOv5 and Segment Anything. The tool also supports text detection, recognition, and Key Information Extraction (KIE) labeling, with multiple language options available such as English, Vietnamese, and Chinese.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.

LabelQuick
LabelQuick_V2.0 is a fast image annotation tool designed and developed by the AI Horizon team. This version has been optimized and improved based on the previous version. It provides an intuitive interface and powerful annotation and segmentation functions to efficiently complete dataset annotation work. The tool supports video object tracking annotation, quick annotation by clicking, and various video operations. It introduces the SAM2 model for accurate and efficient object detection in video frames, reducing manual intervention and improving annotation quality. The tool is designed for Windows systems and requires a minimum of 6GB of memory.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.