
FastFlowLM
Run LLMs on AMD Ryzen™ AI NPUs in minutes. Just like Ollama - but purpose-built and deeply optimized for the AMD NPUs.
Stars: 746
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
README:
![]()
Run large language models — now with Vision, Audio, Embedding and MoE support — on AMD Ryzen™ AI NPUs in minutes.
No GPU required. Faster and over 10× more power-efficient. Supports context lengths up to 256k tokens. Ultra-Lightweight (16 MB). Installs within 20 seconds.
📦 The only out-of-box, NPU-first runtime built exclusively for Ryzen™ AI.
🤝 Think Ollama — but deeply optimized for NPUs.
✨ From Idle Silicon to Instant Power — FastFlowLM Makes Ryzen™ AI Shine.
FastFlowLM (FLM) supports all Ryzen™ AI Series chips with XDNA2 NPUs (Strix, Strix Halo, and Kraken).
🔽 Download | 📊 Benchmarks | 📦 Model List
📖 Docs | 📺 Demos | 🧪 Test Drive | 💬 Discord
A packaged FLM Windows installer is available here: flm-setup.exe. For more details, see the release notes.
[!IMPORTANT]
⚠️ Ensure NPU driver version is >= 32.0.203.304 (.304is the minimum requirement but.311is recommended; check via Task Manager→Performance→NPU or Device Manager).
⚙️ Tip:
- RECOMMENDED: Try running Windows Update or Driver Download.
- Official AMD Install Doc (AMD account required).
- Unofficial forum downloads (CAUTION, we do not hold responsible for what you download here).
After installation, open PowerShell (Win + X → I). To run a model in terminal (CLI Mode):
flm run llama3.2:1bNotes:
- Internet access to HuggingFace is required to download the optimized model kernels.
- Sometimes downloads from HuggingFace may get corrupted. If this happens, run
flm pull <model_tag> --force(e.g.flm pull llama3.2:1b --force) to re-download and fix them.- By default, models are stored in:
- Windows:
C:\Users\<USER>\Documents\flm\models\- Linux:
~/.config/flm/- During installation on Windows, you can select a different base folder (e.g., if you choose
C:\Users\<USER>\flm, models will be saved underC:\Users\<USER>\flm\models\).- On Linux, you can override the default location by setting the
FLM_MODEL_PATHenvironment variable.⚠️ If HuggingFace is not accessible in your region, manually download the model (check this issue) and place it in the chosen directory.
🎉🚀 FastFlowLM (FLM) is ready — your NPU is unlocked and you can start chatting with models right away!
Open Task Manager (Ctrl + Shift + Esc). Go to the Performance tab → click NPU to monitor usage.
⚡ Quick Tips:
- Use
/verboseduring a session to turn on performance reporting (toggle off with/verboseagain).- Type
/byeto exit a conversation.- Run
flm listin PowerShell to show all available models.
To start the local server (Server Mode):
flm serve llama3.2:1bThe model tag (e.g.,
llama3.2:1b) sets the initial model, which is optional. If another model is requested, FastFlowLM will automatically switch to it. Local server is on port 52625 (default).
- 10/01/2025 🎉 FLM was integrated into AMD's Lemonade Server 🍋. Watch this short demo about using FLM in Lemonade.
FLM makes it easy to run cutting-edge LLMs (and now VLMs) locally with:
- ⚡ Fast and low power
- 🧰 Simple CLI and API (REST and OpenAI API)
- 🔐 Fully private and offline
No model rewrites, no tuning — it just works.
- Runs fully on AMD Ryzen™ AI NPU — no GPU or CPU load
- Lightweight runtime (16 MB) — installs within 20 seconds, easy to integrate
- Developer-first flow — like Ollama, but optimized for NPU
- Support for long context windows — up to 256k tokens (e.g., Qwen3-4B-Thinking-2507)
- No low-level tuning required — You focus on your app, we handle the rest
- All orchestration code and CLI tools are open-source under the MIT License.
- NPU-accelerated kernels are proprietary binaries, free for commercial use up to USD 10 million in annual company revenue.
- Companies exceeding this threshold (USD 10 million) must obtain a commercial license. See LICENSE_BINARY.txt and TERMS.md for full details.
-
Free-tier users: Please acknowledge FastFlowLM in your README/project page (or product) as follows:
Powered by [FastFlowLM](https://github.com/FastFlowLM/FastFlowLM)
For commercial licensing inquiries, email us: [email protected]
💬 Have feedback/issues or want early access to our new releases? Open an issue or Join our Discord community
- Powered by the advanced AMD Ryzen™ AI NPU architecture
- Inspired by the widely adopted llama.cpp and Ollama
- Tokenization accelerated with MLC-ai/tokenizers-cpp
- Chat formatting via Google/minja
- Low-level kernels optimized using the powerful IRON+AIE-MLIR
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FastFlowLM
Similar Open Source Tools
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
LLM-Project
LLM-Project is a machine learning model for sentiment analysis. It is designed to analyze text data and classify it into positive, negative, or neutral sentiments. The model uses natural language processing techniques to extract features from the text and train a classifier to make predictions. LLM-Project is suitable for researchers, developers, and data scientists who are working on sentiment analysis tasks. It provides a pre-trained model that can be easily integrated into existing projects or used for experimentation and research purposes. The codebase is well-documented and easy to understand, making it accessible to users with varying levels of expertise in machine learning and natural language processing.
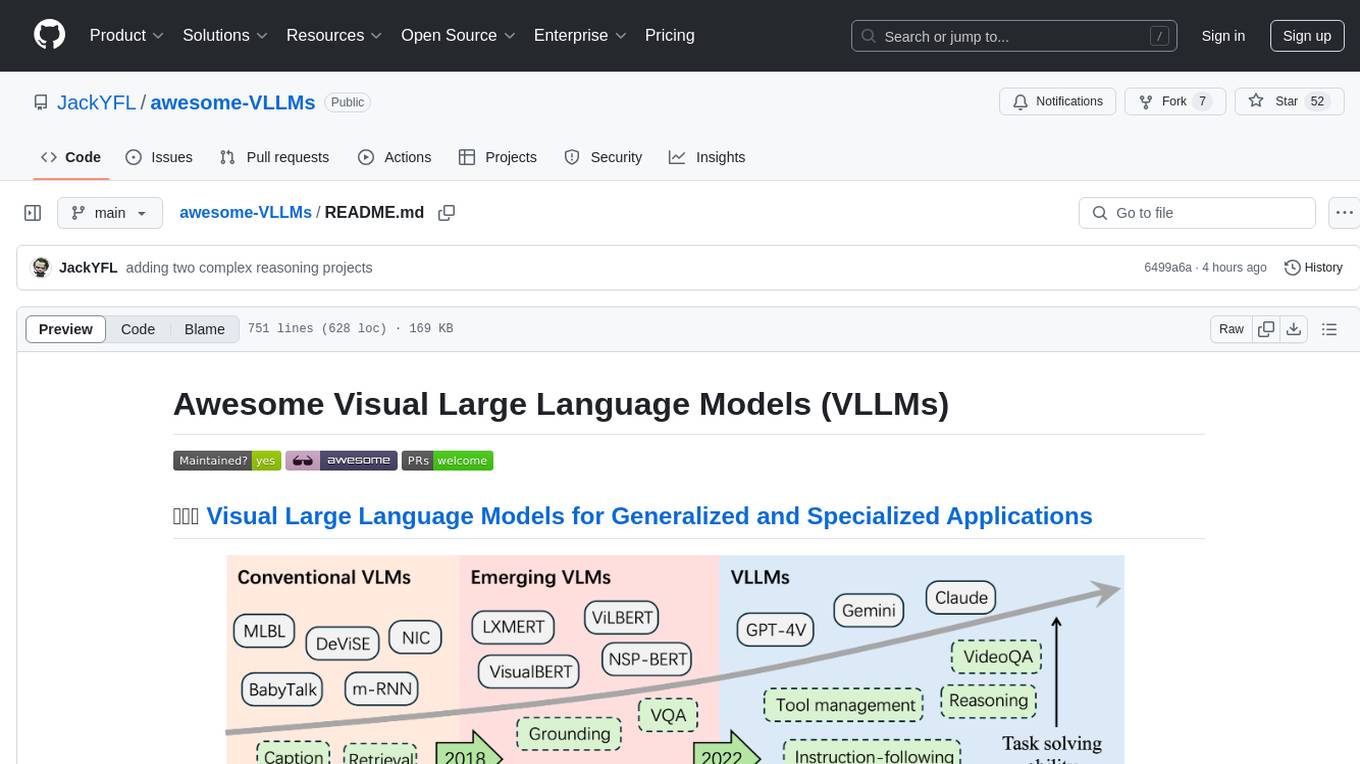
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.
intro-llm.github.io
Large Language Models (LLM) are language models built by deep neural networks containing hundreds of billions of weights, trained on a large amount of unlabeled text using self-supervised learning methods. Since 2018, companies and research institutions including Google, OpenAI, Meta, Baidu, and Huawei have released various models such as BERT, GPT, etc., which have performed well in almost all natural language processing tasks. Starting in 2021, large models have shown explosive growth, especially after the release of ChatGPT in November 2022, attracting worldwide attention. Users can interact with systems using natural language to achieve various tasks from understanding to generation, including question answering, classification, summarization, translation, and chat. Large language models demonstrate powerful knowledge of the world and understanding of language. This repository introduces the basic theory of large language models including language models, distributed model training, and reinforcement learning, and uses the Deepspeed-Chat framework as an example to introduce the implementation of large language models and ChatGPT-like systems.
simple-ai
Simple AI is a lightweight Python library for implementing basic artificial intelligence algorithms. It provides easy-to-use functions and classes for tasks such as machine learning, natural language processing, and computer vision. With Simple AI, users can quickly prototype and deploy AI solutions without the complexity of larger frameworks.
osaurus
Osaurus is a versatile open-source tool designed for data scientists and machine learning engineers. It provides a wide range of functionalities for data preprocessing, feature engineering, model training, and evaluation. With Osaurus, users can easily clean and transform raw data, extract relevant features, build and tune machine learning models, and analyze model performance. The tool supports various machine learning algorithms and techniques, making it suitable for both beginners and experienced practitioners in the field. Osaurus is actively maintained and updated to incorporate the latest advancements in the machine learning domain, ensuring users have access to state-of-the-art tools and methodologies for their projects.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
GEN-AI
GEN-AI is a versatile Python library for implementing various artificial intelligence algorithms and models. It provides a wide range of tools and functionalities to support machine learning, deep learning, natural language processing, computer vision, and reinforcement learning tasks. With GEN-AI, users can easily build, train, and deploy AI models for diverse applications such as image recognition, text classification, sentiment analysis, object detection, and game playing. The library is designed to be user-friendly, efficient, and scalable, making it suitable for both beginners and experienced AI practitioners.
ai-inference
AI Inference is a Python library that provides tools for deploying and running machine learning models in production environments. It simplifies the process of integrating AI models into applications by offering a high-level API for inference tasks. With AI Inference, developers can easily load pre-trained models, perform inference on new data, and deploy models as RESTful APIs. The library supports various deep learning frameworks such as TensorFlow and PyTorch, making it versatile for a wide range of AI applications.

LLMs-playground
LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.
Complete-LLM-Finetuning
Complete-LLM-Finetuning is a tool designed for fine-tuning large language models for various natural language processing tasks. It provides a comprehensive guide and resources for users to effectively fine-tune language models for specific applications. The tool aims to simplify the process of adapting pre-trained language models to new tasks by offering step-by-step instructions and best practices. Users can leverage the tool to enhance the performance of language models on specific datasets and tasks, enabling them to achieve better results in natural language processing projects.
llm_recipes
This repository showcases the author's experiments with Large Language Models (LLMs) for text generation tasks. It includes dataset preparation, preprocessing, model fine-tuning using libraries such as Axolotl and HuggingFace, and model evaluation.
For similar tasks

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.