
layra
LAYRA—an enterprise-ready, out-of-the-box solution—unlocks next-generation intelligent systems powered by visual RAG and limitless visual multi-step agent workflow orchestration.
Stars: 817

LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
README:



📢 Click to Expand WeChat Groups
🚀 User Discussion Group 1

💡 Official WeChat Account

🚀 New Jina-Embeddings-v4 API support eliminates local GPU requirements
LAYRA is the world’s first “visual-native” AI automation engine. It sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. From vision-driven Retrieval-Augmented Generation (RAG) to multi-step agent workflow orchestration, LAYRA empowers you to build next-generation intelligent systems—no limits, no compromises.
Built for Enterprise-Grade deployment, LAYRA features:
- 🧑💻 Modern Frontend: Built with Next.js 15 (TypeScript) & TailwindCSS 4.0 for a snappy, developer-friendly UI.
- ⚡ High-Performance Backend: FastAPI-powered with async integration for Redis, MySQL, MongoDB, Kafka & MinIO – engineered for high concurrency.
- 🔩 Decoupled Service Architecture: Independent services deployed in dedicated containers, enabling scaling on demand and fault isolation.
- 🎯 Visual-Native Multimodal Document Understanding: Leverages ColQwen 2.5/Jina-Embeddings-v4 to transform documents into semantic vectors stored in Milvus.
- 🚀 Powerful Workflow Engine: Construct complex, loop-nested, and debuggable workflows with full Python execution and human-in-the-loop capabilities.
- 🖼️ Screenshots
- 🚀 Quick Start
- 📖 Tutorial Guide
- ❓ Why LAYRA?
- ⚡️ Core Superpowers
- 🚀 Latest Updates
- 🧠 System Architecture
- 🧰 Tech Stack
- ⚙️ Deployment
- 📦 Roadmap
- 🤝 Contributing
- 📫 Contact
- 🌟 Star History
- 📄 License
Explore LAYRA's powerful interface and capabilities through these visuals:
-
Homepage - Your Gateway to LAYRA

-
Knowledge Base - Centralized Document Hub

-
Interactive Dialogue - Layout-Preserving Answers

-
Workflow Builder - Drag-and-Drop Agent Creation

-
Workflow Builder - MCP Example


Before starting, ensure your system meets these requirements:
- Docker and Docker Compose installed
- NVIDIA Container Toolkit configured (Ignore if not deploying ColQwen locally)
# Clone the repository
git clone https://github.com/liweiphys/layra.git
cd layra
# Edit configuration file (modify server IP/parameters as needed)
vim .env
# Key configuration options include:
# - SERVER_IP (server IP)
# - MODEL_BASE_URL (model download source)For Jina (cloud API) Embeddings v4 users:
vim .env
EMBEDDING_IMAGE_DPI=100 # DPI for document-to-image conversion. Recommended: 100 - 200 (12.5k - 50k tokens/img)
EMBEDDING_MODEL=jina_embeddings_v4
JINA_API_KEY=your_jina_api_key
JINA_EMBEDDINGS_V4_URL=https://api.jina.ai/v1/embeddings Option A: Local ColQwen deployment (recommended for GPUs with >16GB VRAM)
# Initial startup will download ~15GB model weights (be patient)
docker compose up -d --build
# Monitor logs in real-time (replace <container_name> with actual name)
docker compose logs -f <container_name>Option B: Jina-embeddings-v4 API service (for limited/no GPU resources)
# Initial startup will not download any model weights (fast!)
docker compose -f docker-compose-no-local-embedding.yml up -d --build
# Monitor logs in real-time (replace <container_name> with actual name)
docker compose logs -f <container_name>Note: If you encounter issues with
docker compose, try usingdocker-compose(with the dash) instead. Also, ensure that you're using Docker Compose v2, as older versions may not support all features. You can check your version withdocker compose versionordocker-compose version.
Your deployment is complete! Start creating with Layra now. 🚀✨
For detailed options, see the Deployment section.
📘 Essential Learning: We strongly recommend spending just 60 minutes with the tutorial before starting with LAYRA - this small investment will help you master its full potential and unlock advanced capabilities.
For step-by-step instructions and visual guides, visit our tutorial on GitHub Pages:
Tutorial Guide
While LAYRA's Visual RAG Engine revolutionizes document understanding, its true power lies in the Agent Workflow Engine - a visual-native platform for building complex AI agents that see, reason, and act. Unlike traditional RAG/Workflow systems limited to retrieval, LAYRA enables full-stack automation through:
-
🔄 Cyclic & Nested Structures
Build recursive workflows with loop nesting, conditional branching, and custom Python logic - no structural limitations. -
🐞 Node-Level Debugging
Inspect variables, pause/resume execution, and modify state mid-workflow with visual breakpoint debugging. -
👤 Human-in-the-Loop Integration
Inject user approvals at critical nodes for collaborative AI-human decision making. -
🧠 Chat Memory & MCP Integration
Maintain context across nodes with chat memory and access live information via Model Context Protocol (MCP). -
🐍 Full Python Execution
Run arbitrary Python code withpipinstalls, HTTP requests, and custom libraries in sandboxed environments. -
🎭 Multimodal I/O Orchestration
Process and generate hybrid text/image outputs across workflow stages.
Traditional RAG systems fail because they:
- ❌ Lose layout fidelity (columns, tables, hierarchy collapse)
- ❌ Struggle with non-text visuals (charts, diagrams, figures)
- ❌ Break semantic continuity due to poor OCR segmentation
LAYRA changes this with pure visual embeddings:
🔍 It sees each page as a whole - just like a human reader - preserving:
- ✅ Layout structure (headers, lists, sections)
- ✅ Tabular integrity (rows, columns, merged cells)
- ✅ Embedded visuals (plots, graphs, stamps, handwriting)
- ✅ Multi-modal consistency between layout and content
Together, these engines form the first complete visual-native agent platform - where AI doesn't just retrieve information, but executes complex vision-driven workflows end-to-end.
Code Without Limits, Build Without Boundaries Our Agent Workflow Engine thinks in LLM, sees in visuals, and builds your logic in Python — no limits, just intelligence.
-
🔄 Unlimited Workflow Creation
Design complex custom workflows without structural constraints. Handle unique business logic, branching, loops, and conditions through an intuitive interface. -
⚡ Real-Time Streaming Execution (SSE)
Observe execution results streamed live – eliminate waiting times entirely. -
👥 Human-in-the-Loop Integration
Integrate user input at critical decision points to review, adjust, or direct model reasoning. Enables collaborative AI workflows with dynamic human oversight. -
👁️ Visual-First Multimodal RAG
Features LAYRA’s proprietary pure visual embedding system, delivering lossless document understanding across 100+ formats (PDF, DOCX, XLSX, PPTX, etc.). The AI actively "sees" your content. -
🧠 Chat Memory & MCP Integration
- MCP Integration Access and interact with live, evolving information beyond native context windows – enhancing adaptability for long-term tasks.
- ChatFlow Memory Maintain contextual continuity through chat memory, enabling personalized interactions and intelligent workflow evolution.
-
🐍 Full-Stack Python Control
- Drive logic with arbitrary Python expressions – conditions, loops, and more
- Execute unrestricted Python code in nodes (HTTP, AI calls, math, etc.)
- Sandboxed environments with secure pip installs and persistent runtime snapshots
-
🎨 Flexible Multimodal I/O
Process and generate text, images, or hybrid outputs – ideal for cross-modal applications. -
🔧 Advanced Development Suite
- Breakpoint Debugging: Inspect workflow states mid-execution
- Reusable Components: Import/export workflows and save custom nodes
- Nested Logic: Construct deeply dynamic task chains with loops and conditionals
-
🧩 Intelligent Data Utilities
- Extract variables from LLM outputs
- Parse JSON dynamically
- Template rendering engine
Essential tools for advanced AI reasoning and automation.
Forget tokenization. Forget layout loss.
With pure visual embeddings, LAYRA understands documents like a human — page by page, structure and all.
LAYRA uses next-generation Retrieval-Augmented Generation (RAG) technology powered by pure visual embeddings. It treats documents not as sequences of tokens but as visually structured artifacts — preserving layout, semantics, and graphical elements like tables, figures, and charts.
(2025.8.4) ✨ Expanded Embedding Model Support:
-
More Embedding Model Support:
-
colqwen(Local GPU - high performance) -
jina-embeddings-v4(Cloud API - zero GPU requirements)
-
- New Chinese language support
(2025.6.2) Workflow Engine Now Available:
- Breakpoint Debugging: Debug workflows interactively with pause/resume functionality.
-
Unrestricted Python Customization: Execute arbitrary Python code, including external
pipdependency installation, HTTP requests viarequests, and advanced logic. - Nested Loops & Python-Powered Conditions: Build complex workflows with loop nesting and Python-based conditional logic.
-
LLM Integration:
- Automatic JSON output parsing for structured responses.
- Persistent conversation memory across nodes.
- File uploads and knowledge-base retrieve with multi-modal RAG supporting 100+ formats (PDF, DOCX, XLSX, PPTX, etc.).
(2025.4.6) First Trial Version Now Available:
The first testable version of LAYRA has been released! Users can now upload PDF documents, ask questions, and receive layout-aware answers. We’re excited to see how this feature can help with real-world document understanding.
-
Current Features:
- PDF batch upload and parsing functionality
- Visual-first retrieval-augmented generation (RAG) for querying document content
- Backend fully optimized for scalable data flow with FastAPI, Milvus, Redis, MongoDB, and MinIO
Stay tuned for future updates and feature releases!
LAYRA’s pipeline is designed for async-first, visual-native, and scalable document retrieval and generation.
The query goes through embedding → vector retrieval → anser generation:

PDFs are parsed into images and embedded visually via ColQwen2.5/Jina-Embeddings-v4, with metadata and files stored in appropriate databases:

The workflow execution follows an event-driven, stateful debugging pattern with granular control:
-
Trigger & Debug Control
- Web UI submits workflow with configurable breakpoints for real-time inspection
- Backend validates workflow DAG before executing codes
-
Asynchronous Orchestration
- Kafka checks predefined breakpoints and triggers pause notifications
- Scanner performs AST-based code analysis with vulnerability detection
-
Secure Execution
- Sandbox spins up ephemeral containers with file system isolation
- Runtime state snapshots persisted to Redis/MongoDB for recovery
-
Observability
- Execution metrics streamed via Server-Sent Events (SSE)
- Users inject test inputs/resume execution through debug consoles

Frontend:
-
Next.js,TypeScript,TailwindCSS,Zustand,xyflow
Backend & Infrastructure:
-
FastAPI,Kafka,Redis,MySQL,MongoDB,MinIO,Milvus,Docker
Models & RAG:
- Embedding:
colqwen2.5-v0.2jina-embeddings-v4 - LLM Serving:
Qwen2.5-VL series (or any OpenAI-compatible model)LOCAL DEPLOYMENT NOTE
Before starting, ensure your system meets these requirements:
- Docker and Docker Compose installed
- NVIDIA Container Toolkit configured (Ignore if not deploying ColQwen locally)
# Clone the repository
git clone https://github.com/liweiphys/layra.git
cd layra
# Edit configuration file (modify server IP/parameters as needed)
vim .env
# Key configuration options include:
# - SERVER_IP (public server IP)
# - MODEL_BASE_URL (model download source)For Jina (cloud API) Embeddings v4 users:
vim .env
EMBEDDING_IMAGE_DPI=100 # DPI for document-to-image conversion. Recommended: 100 - 200 (12.5k - 50k tokens/img)
EMBEDDING_MODEL=jina_embeddings_v4
JINA_API_KEY=your_jina_api_key
JINA_EMBEDDINGS_V4_URL=https://api.jina.ai/v1/embeddings Option A: Local ColQwen deployment (recommended for GPUs with >16GB VRAM)
# Initial startup will download ~15GB model weights (be patient)
docker compose up -d --build
# Monitor logs in real-time (replace <container_name> with actual name)
docker compose logs -f <container_name>Option B: Jina-embeddings-v4 API service (for limited/no GPU resources)
# Initial startup will download ~15GB model weights (be patient)
docker compose -f docker-compose-no-local-embedding.yml up -d --build
# Monitor logs in real-time (replace <container_name> with actual name)
docker compose logs -f <container_name>Note: If you encounter issues with
docker compose, try usingdocker-compose(with the dash) instead. Also, ensure that you're using Docker Compose v2, as older versions may not support all features. You can check your version withdocker compose versionordocker-compose version.
If services fail to start:
# Check container logs:
docker compose logs <container name>Common fixes:
nvidia-smi # Verify GPU detection
docker compose down && docker compose up --build # preserve data to rebuild
docker compose down -v && docker compose up --build # ⚠️ Caution: delete all data to full rebuildChoose the operation you need:
| Scenario | Command | Effect |
|---|---|---|
|
Stop services (preserve data) |
docker compose stop |
Stops containers but keeps them intact |
| Restart after stop | docker compose start |
Restarts stopped containers |
| Rebuild after code changes | docker compose up -d --build |
Rebuilds images and recreates containers |
|
Recreate containers (preserve data) |
docker compose downdocker compose up -d
|
Destroys then recreates containers |
|
Full cleanup (delete all data) |
docker compose down -v |
-
Initial model download may take significant time (~15GB). Monitor progress:
docker compose logs -f model-weights-init
-
After modifying
.envor code, always rebuild:docker compose up -d --build
-
Verify NVIDIA toolkit installation:
nvidia-container-toolkit --version
-
For network issues:
- Manually download model weights
- Copy to Docker volume: (typically at)
/var/lib/docker/volumes/layra_model_weights/_data/ - Create empty
complete.layrafile in both:-
colqwen2.5-basefolder -
colqwen2.5-v0.2folder
-
- 🚨 Critical: Verify downloaded weights integrity!
-
docker compose down -vpermanently deletes databases and model weights -
After code/config changes, always use
--buildflag -
GPU requirements:
- Latest NVIDIA drivers
- Working
nvidia-container-toolkit
-
Monitoring tools:
# Container status docker compose ps -a # Resource usage docker stats
🧪 Technical Note: All components run exclusively via Docker containers.
Now that everything is running smoothly, happy building with Layra! 🚀✨
In the future, we will support multiple deployment methods including Kubernetes (K8s), and other environments. More details will be provided when these deployment options are available.
Short-term:
- Add API Support (coming soon)
Long-term:
- Our evolving roadmap adapts to user needs and AI breakthroughs. New technologies and features will be deployed continuously.
Contributions are welcome! Feel free to open an issue or pull request if you’d like to contribute.
We are in the process of creating a CONTRIBUTING.md file, which will provide guidelines for code contributions, issue reporting, and best practices. Stay tuned!
liweiphys
📧 [email protected]
🐙 github.com/liweiphys/layra
📺 bilibili: Biggestbiaoge
🔍 Wechat Official Account:LAYRA 项目
💡 Wechat group: see below the title at the top
💼 Exploring Impactful Opportunities - Feel Free To Contact Me!
This project is licensed under the Apache License 2.0. See the LICENSE file for more details.
Endlessly Customizable Agent Workflow Engine - Code Without Limits, Build Without Boundaries.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for layra
Similar Open Source Tools
layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
evi-run
evi-run is a powerful, production-ready multi-agent AI system built on Python using the OpenAI Agents SDK. It offers instant deployment, ultimate flexibility, built-in analytics, Telegram integration, and scalable architecture. The system features memory management, knowledge integration, task scheduling, multi-agent orchestration, custom agent creation, deep research, web intelligence, document processing, image generation, DEX analytics, and Solana token swap. It supports flexible usage modes like private, free, and pay mode, with upcoming features including NSFW mode, task scheduler, and automatic limit orders. The technology stack includes Python 3.11, OpenAI Agents SDK, Telegram Bot API, PostgreSQL, Redis, and Docker & Docker Compose for deployment.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.
retrace
Retrace is a local-first screen recording and search application for macOS, inspired by Rewind AI. It captures screen activity, extracts text via OCR, and makes everything searchable locally on-device. The project is in very early development, offering features like continuous screen capture, OCR text extraction, full-text search, timeline viewer, dashboard analytics, Rewind AI import, settings panel, global hotkeys, HEVC video encoding, search highlighting, privacy controls, and more. Built with a modular architecture, Retrace uses Swift 5.9+, SwiftUI, Vision framework, SQLite with FTS5, HEVC video encoding, CryptoKit for encryption, and more. Future releases will include features like audio transcription and semantic search. Retrace requires macOS 13.0+ (Apple Silicon required) and Xcode 15.0+ for building from source, with permissions for screen recording and accessibility. Contributions are welcome, and the project is licensed under the MIT License.
sandboxed.sh
sandboxed.sh is a self-hosted cloud orchestrator for AI coding agents that provides isolated Linux workspaces with Claude Code, OpenCode & Amp runtimes. It allows users to hand off entire development cycles, run multi-day operations unattended, and keep sensitive data local by analyzing data against scientific literature. The tool features dual runtime support, mission control for remote agent management, isolated workspaces, a git-backed library, MCP registry, and multi-platform support with a web dashboard and iOS app.
llxprt-code
LLxprt Code is an AI-powered coding assistant that works with any LLM provider, offering a command-line interface for querying and editing codebases, generating applications, and automating development workflows. It supports various subscriptions, provider flexibility, top open models, local model support, and a privacy-first approach. Users can interact with LLxprt Code in both interactive and non-interactive modes, leveraging features like subscription OAuth, multi-account failover, load balancer profiles, and extensive provider support. The tool also allows for the creation of advanced subagents for specialized tasks and integrates with the Zed editor for in-editor chat and code selection.
vibesdk
Cloudflare VibeSDK is an open source full-stack AI webapp generator built on Cloudflare's developer platform. It allows companies to build AI-powered platforms, enables internal development for non-technical teams, and supports SaaS platforms to extend product functionality. The platform features AI code generation, live previews, interactive chat, modern stack generation, one-click deploy, and GitHub integration. It is built on Cloudflare's platform with frontend in React + Vite, backend in Workers with Durable Objects, database in D1 (SQLite) with Drizzle ORM, AI integration via multiple LLM providers, sandboxed app previews and execution in containers, and deployment to Workers for Platforms with dispatch namespaces. The platform also offers an SDK for programmatic access to build apps programmatically using TypeScript SDK.
llmchat
LLMChat is an all-in-one AI chat interface that supports multiple language models, offers a plugin library for enhanced functionality, enables web search capabilities, allows customization of AI assistants, provides text-to-speech conversion, ensures secure local data storage, and facilitates data import/export. It also includes features like knowledge spaces, prompt library, personalization, and can be installed as a Progressive Web App (PWA). The tech stack includes Next.js, TypeScript, Pglite, LangChain, Zustand, React Query, Supabase, Tailwind CSS, Framer Motion, Shadcn, and Tiptap. The roadmap includes upcoming features like speech-to-text and knowledge spaces.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
specs.md
AI-native development framework with pluggable flows for every use case. Choose from Simple for quick specs, FIRE for adaptive execution, or AI-DLC for full methodology with DDD. Features include flow switcher, active run tracking, intent visualization, and click-to-open spec files. Three flows optimized for different scenarios: Simple for spec generation, prototypes; FIRE for adaptive execution, brownfield, monorepos; AI-DLC for full traceability, DDD, regulated environments. Installable as a VS Code extension for progress tracking. Supported by various AI coding tools like Claude Code, Cursor, GitHub Copilot, and Google Antigravity. Tool agnostic with portable markdown files for agents and specs.
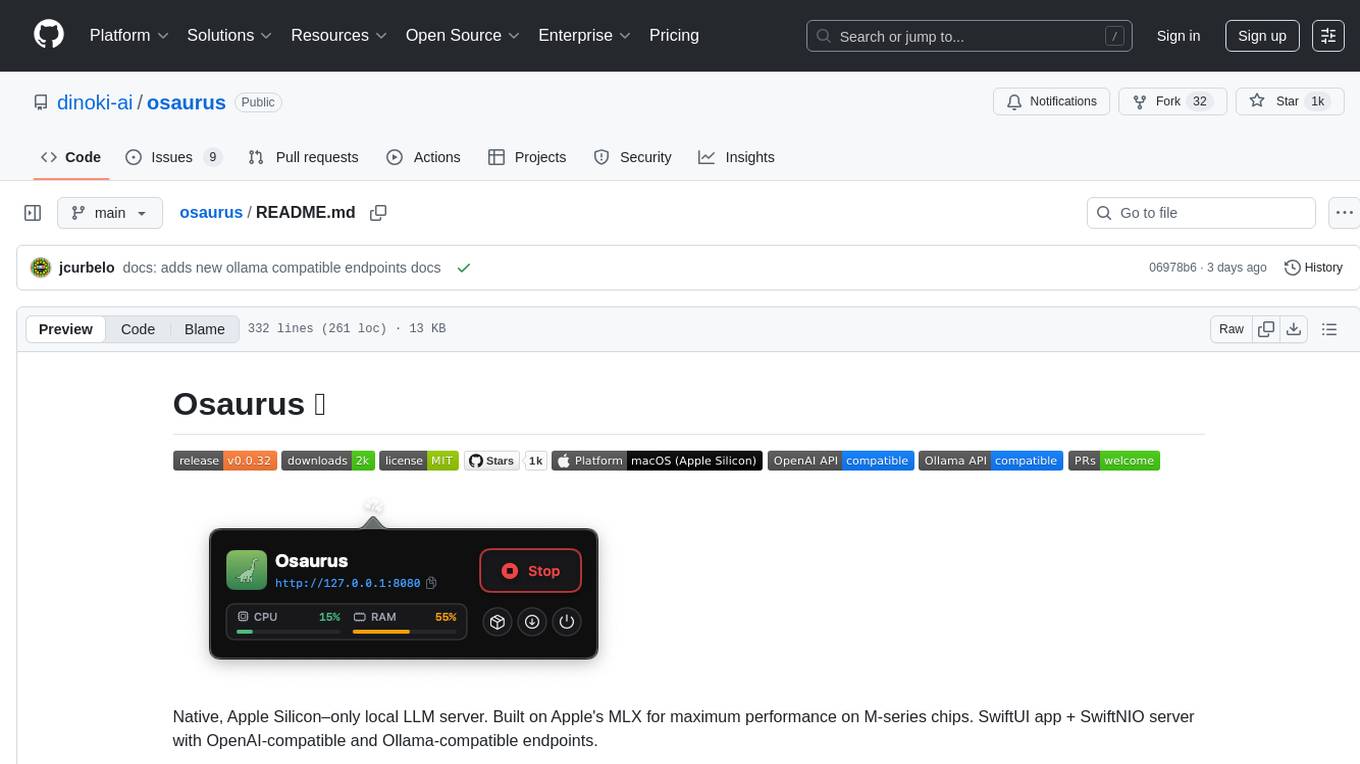
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
opcode
opcode is a powerful desktop application built with Tauri 2 that serves as a command center for interacting with Claude Code. It offers a visual GUI for managing Claude Code sessions, creating custom agents, tracking usage, and more. Users can navigate projects, create specialized AI agents, monitor usage analytics, manage MCP servers, create session checkpoints, edit CLAUDE.md files, and more. The tool bridges the gap between command-line tools and visual experiences, making AI-assisted development more intuitive and productive.
obsidian-ai-tagger-universe
AI Tagger Universe is a plugin for Obsidian that automatically generates intelligent tags for notes using AI. It offers flexible AI integration with various services, smart tagging system with multiple modes, tag network visualization, advanced management features, and support for multiple languages. Users can easily install the plugin, configure AI providers, generate tags, and visualize tag relationships. The plugin also supports nested tags, hierarchical tag generation, and tag format options. It includes bug fixes, major features, improvements, and language support for English and Chinese interfaces.
For similar tasks

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide
bee-agent-framework
The Bee Agent Framework is an open-source tool for building, deploying, and serving powerful agentic workflows at scale. It provides AI agents, tools for creating workflows in Javascript/Python, a code interpreter, memory optimization strategies, serialization for pausing/resuming workflows, traceability features, production-level control, and upcoming features like model-agnostic support and a chat UI. The framework offers various modules for agents, llms, memory, tools, caching, errors, adapters, logging, serialization, and more, with a roadmap including MLFlow integration, JSON support, structured outputs, chat client, base agent improvements, guardrails, and evaluation.
mastra
Mastra is an opinionated Typescript framework designed to help users quickly build AI applications and features. It provides primitives such as workflows, agents, RAG, integrations, syncs, and evals. Users can run Mastra locally or deploy it to a serverless cloud. The framework supports various LLM providers, offers tools for building language models, workflows, and accessing knowledge bases. It includes features like durable graph-based state machines, retrieval-augmented generation, integrations, syncs, and automated tests for evaluating LLM outputs.

otto-m8
otto-m8 is a flowchart based automation platform designed to run deep learning workloads with minimal to no code. It provides a user-friendly interface to spin up a wide range of AI models, including traditional deep learning models and large language models. The tool deploys Docker containers of workflows as APIs for integration with existing workflows, building AI chatbots, or standalone applications. Otto-m8 operates on an Input, Process, Output paradigm, simplifying the process of running AI models into a flowchart-like UI.
flows-ai
Flows AI is a lightweight, type-safe AI workflow orchestrator inspired by Anthropic's agent patterns and built on top of Vercel AI SDK. It provides a simple and deterministic way to build AI workflows by connecting different input/outputs together, either explicitly defining workflows or dynamically breaking down complex tasks using an orchestrator agent. The library is designed without classes or state, focusing on flexible input/output contracts for nodes.
LangGraph-learn
LangGraph-learn is a community-driven project focused on mastering LangGraph and other AI-related topics. It provides hands-on examples and resources to help users learn how to create and manage language model workflows using LangGraph and related tools. The project aims to foster a collaborative learning environment for individuals interested in AI and machine learning by offering practical examples and tutorials on building efficient and reusable workflows involving language models.
xorq
Xorq (formerly LETSQL) is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It provides a flexible and powerful tool for processing and analyzing data from various sources, enabling users to create complex data pipelines and perform advanced data transformations.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.